多线程高并发(五)线程池
目录
day7
一,调整线程池大小
二,线程池几个常用类的拓展
(一),Executor
(二),ExecutorService
(三),Executors
为什么不能使用Executors创建线城池?
(四),Callable
(五),Future 存储执行将来的结果
FutureTask Future+Runnable
CompletableFuture 管理多个Future结果
day8
三,ThreadPoolExecutor
(一),定义线程池的7个参数
(二),源码解析
1,常用变量解释
2,execute 提交执行task的过程
3,addworker源码解析
4,worker
5,核心线程执行逻辑-runworker
(三)实例
1,SingleThreadPool 单个线程的线程池 保证线程顺序执行
2,CachedThreadPool 确保任务不会堆积时使用
3,FixedThreadPool 固定数量的线程池,不回收
4,ScheduledThreadPool 专门执行定时任务的
四,ForkJoinPool
1,特性
2, 原理:
3,实例
4,WorkStealingPoll 分叉组合
五,两种线城池对比
day7
一,调整线程池大小
要预估线程池的线程数量
如果线程过多:会浪费大量时间在上线文切换上
如果线程过少:处理器的性能无法充分使用
W/C wait/compute
线程执行的时候时有多长时间时让出/使用CPU的?
计算特别多的,没有什么IO操作的,wait时间就非常短接近0
IO网络操作,接收发送, wait时间就长
实际中很难计算,很难估算W/C,
一般情况下,使用经验值,然后压测(性能测试)
可以使用计算预估,但是还是需要通过压测来评估准确

二,线程池几个常用类的拓展

(一),Executor
执行者,执行一个线程
任务的定义,运行可以分开。
跟之前的固定写法new Thread() 不同,运行执行的方式可以自己定义。
(二),ExecutorService
在Executor的基础上,完善了整个执行器的生命周期
shutdown 结束
shutdownNow 马上结束
isShutdown 是不是结束了
isTerminated 终止
awaitTermination 等待结束,可以添加等待时间,过期未结束返回false
submit 往线程池里添加任务
invokeAll 拿出所有的线程执行,并产生批量结果
invokeAny拿出任意一个线程执行,并产生结果
(三),Executors
线程池的工厂,产生各种各样的线程池
为什么不能使用Executors创建线城池?
线程池不允许使用Executors去创建,而是使用ThreadPoolExecutor,目的是明确线程池的运行规则,避免资源耗尽的风险。
Executors返回线程池对象的弊端如下:
1) FixedThreadPool和SingleThreadPool
允许请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。
2) CachedThreadPool
允许的创建线程数量为Integer.MAX_VALUE,可能会创建大量得多线程,从而导致OOM。
面试题:加入提供一个闹钟,订阅这个服务的人特别多,10亿人,怎么优化?
整体分而治之:把任务分发到很多边缘的服务器上去,
单个服务器 :用队列存储,然后消费。
不能百分百保证完全的准确性,除非一人一个手机(服务器),还得考虑时间的同步,这是资源。
面试题:并行和并发的区别
parallel并行是任务同时执行,concurrent 并发是任务同时的提交
并行是并发的子集
并行多个CPU同时处理执行
并发在是CPU轮子上切换执行
(四),Callable
带返回值的线程运行声明方式,
call 相当于 Runnable的run,区别在于前者有返回值
public abstract void run();
V call() throws Exception;类似于Runnable,但有返回值
(五),Future 存储执行将来的结果
存储未来执行完的结果
FutureTask Future+Runnable
Future和Runnable的结合
CompletableFuture 管理多个Future结果
比较灵活,关于结果的组合,各种任务的结果组合。
1,异步比较好用方法;
2,多个任务的管理
场景 :查询各大电商网站同一类产品的价格并汇总展示
比如说,小米手机,用爬虫等手段获取多个平台 某宝,某东,某多多对应产品的价格;
最后汇总下,让你挑选。
day8
三,ThreadPoolExecutor
普通类型的线程池,管理这两个集合:线程和任务的集合

(一),定义线程池的7个参数
int corePoolSize :核心线程数 (池中要保留的线程数,偶数)
int maximumPoolSize :最大线程数
long keepAliveTime:生存时间(当线程数大于核心,这是多余空闲线程的最长时间将在终止前等待新任务)
TimeUnit unit:生存时间的单位(参数的时间单位)
BlockingQueue workQueue:任务队列
ThreadFactory threadFactory:线程工厂,可以自定义的线程工厂(线程名称的自定义设置的意义在于,快速回溯问题)
RejectedExecutionHandler handler 阻止策略(线程忙并且任务队列满情况下实行拒绝策略,默认提供了四种并可以自定义)
| Abort | 抛出异常 |
| Discard | 扔掉,不抛出异常 |
| DiscardOldest | 扔掉排队时间最久的的 |
| CallerRuns | 调用者处理任务(谁提交的谁执行) |
(二),源码解析
1,常用变量解释
AtomicInteger ctl : int类型32位 高的到三位记录的是线程状态,低29位代表线程池中的线程。
为什么不使用俩值?是为了提高效率,因为都需要线程同步。
线程池有5种状态,按大小排序如下:RUNNING < SHUTDOWN < STOP < TIDYING < TERMINATED
RUNNING :正常运行
SHUTDOWN :调用了shutdown (结束)方法
STOP :调用了shutdownNow (马上结束)
TIDYING :调用了shutdown 方法,线程也执行完了,现在在整理的状态
TERMINATED:整个线程结束
2,execute 提交执行task的过程
先启动核心线程;
核心线程满了往队列里扔;
没有可执行的线程了,添加非核心线程。
如果线程池不是运行状态,或者任务进入队列失败,则尝试创建worker执行任务。
这儿有3点需要注意:
1). 线程池不是运行状态时,addWorker内部会判断线程池状态
2). addWorker第2个参数表示是否创建核心线程
3). addWorker返回false,则说明任务执行失败,需要执行reject操作
3,addworker源码解析
双重自旋在多线程的情况下works.size+1,go跳出;
lock往works添加work,并且start
4,worker
是Runnable的同时,又是一把锁
多线程访问时,无需再次声明lock,
5,核心线程执行逻辑-runworker
worker.lock f独占
worker.run启动
(三)实例
1,SingleThreadPool 单个线程的线程池 保证线程顺序执行

使用的LinkedBlockingQueue,无界队列,size int.Max_VALUE
为什么要有单线程的线程池?
任务队列,生命周期管理
2,CachedThreadPool 确保任务不会堆积时使用
场景:任务量忽高忽低,但是得保证任务来的时候必须有人处理,重要是任务不会堆积

新来的线程,如果线城池里有存活的线程就用存活的线程,如果没有启动新的线程,SynchronousQueue ,手递手的Queue来一个线程必须拿走,不然就阻塞。
线程过多,cpu会频繁的切换线程导致系统资源耗空。
3,FixedThreadPool 固定数量的线程池,不回收
场景:任务量平稳

要意识到LinkedBlockingQueue会出现堆积问题导致OOM,但是一般情况下不会出现,看场景。
阿里是都不用,自己估算,自定义
4,ScheduledThreadPool 专门执行定时任务的

点进去super, 实际上仍然是用的ThreadPoolExecutor,DelayWorkQueue 可以指定间隔时间运行。
实际运用并不多,简单的使用Timer,复杂的使用定时器框架(例如:Quartz,Cron使用费劲涉及到shell脚本)。
四,ForkJoinPool
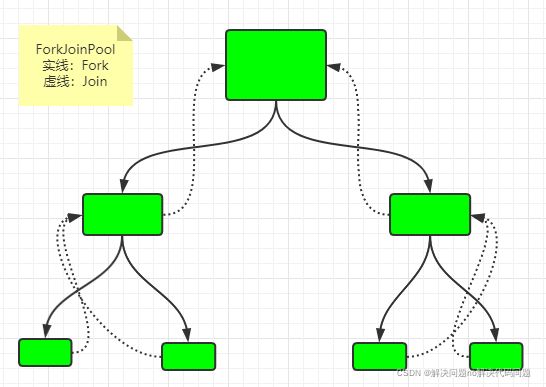
1,特性
1),分解汇总的任务
fork 一个任务分解为多个任务
join 多个任务合并成一个任务
2),用很少的线程可以执行很多的任务(子任务有) TPE左不到先执行子任务
3),CPU密集型
每个线程都有自己单独的队列,当A消费完自己队列时,回去B的队列中消费。
2, 原理:
1)多个woirk queue
2)次啊用work-stealing算法 (工作窃取算法是指某个线程从其他队列里窃取任务来执行)
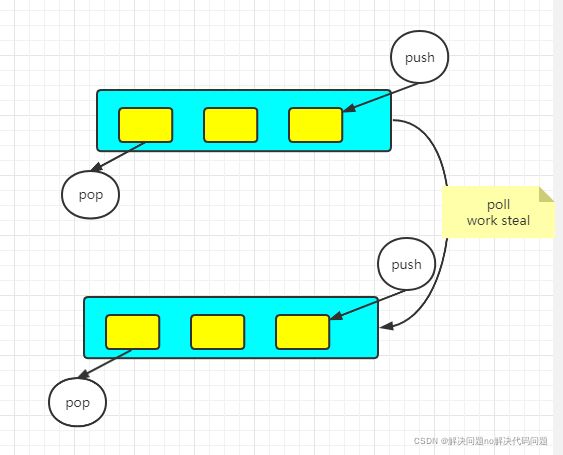
单线程调用 pop pus不会用锁,而poll work steal 是多个线程来投任务会用到锁/自旋
四个参数
int parallelism, 平行度 通常来说是硬件线程数
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode
3,实例
定义ForkJoinPool需要特定的类型,必须能进行分叉的任务ForkJoinTask,但由于比较原始,实际中使用RecursiveAction
RecursiveAction 递归,不带返回值
RecursiveTask 带返回值
package com.example.demo.thread.t8_threadPoll;
import java.io.IOException;
import java.util.Arrays;
import java.util.Random;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
import java.util.concurrent.RecursiveTask;
public class T12_ForkJoinPool {
static int[] nums = new int[1000000];
static final int MAX_NUM = 500000;//小于5W就不切分任务了
static Random r = new Random();
static {
for(int i=0; i
4,WorkStealingPoll 分叉组合

看源码也是用的ForkJoinPool,系统提供的简单调用。
场景:合适切分任务,计算,递归
想要测试出效果,添加的任务数量需要大于硬件线程(Runtime.getRuntime().availableProcessors())
public static void main(String[] args) throws IOException {
ExecutorService service = Executors.newWorkStealingPool();
int availableProcessors = Runtime.getRuntime().availableProcessors();
System.out.println(availableProcessors);
//任务数量需要大于硬件线程
for (int i = 0; i < availableProcessors+5; i++) {
service.execute(new Thread(()->{
Random r = new Random();
int time = r.nextInt(2000);
try {
TimeUnit.MILLISECONDS.sleep(time);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(time + " " + Thread.currentThread().getName());
}));
}
//由于产生的是精灵线程(守护线程、后台线程),主线程不阻塞的话,看不到输出
System.in.read();
}
Console:
8
99 ForkJoinPool-1-worker-5
138 ForkJoinPool-1-worker-3
620 ForkJoinPool-1-worker-3
5 ForkJoinPool-1-worker-3
797 ForkJoinPool-1-worker-1
1215 ForkJoinPool-1-worker-0
871 ForkJoinPool-1-worker-1
1682 ForkJoinPool-1-worker-2
1782 ForkJoinPool-1-worker-4
1804 ForkJoinPool-1-worker-6
1805 ForkJoinPool-1-worker-7
1713 ForkJoinPool-1-worker-5
1560 ForkJoinPool-1-worker-3
可以看出执行快的线程执行了更多次数的任务。
五,两种线城池对比
| 结构 | 场景
ForkJoinPool | 多个woirk 多个queue | 常用阻塞场景
ThreadPool | 多个woirk 同一个queue | 需要分而治之的场景