Isaac Gym环境安装和四足机器人模型的训练
一、Isaac Gym介绍
NVIDIA Isaac Gym是英伟达提供的强化学习研究的高性能仿真环境。通过并行多个模型的方法在GPU上快速训练控制模型。
如论文所述:Isaac Gym: High Performance GPU Based Physics Simulation For Robot Learning。
介绍网站:Isaac Gym - Preview Release
Gihub:Isaac Gym Benchmark Environments
二、环境安装
1. IsaacGym安装
安装环境:
Ubuntu 18.04 或是 20.04.我使用的20.04.
Python版本3.6, 3.7 or 3.8.
最低显卡驱动版本:Linux: 470
我的cuda版本:11.6
1.在官网下载最新的文件包Isaac Gym - Preview Release,注意需要登陆。
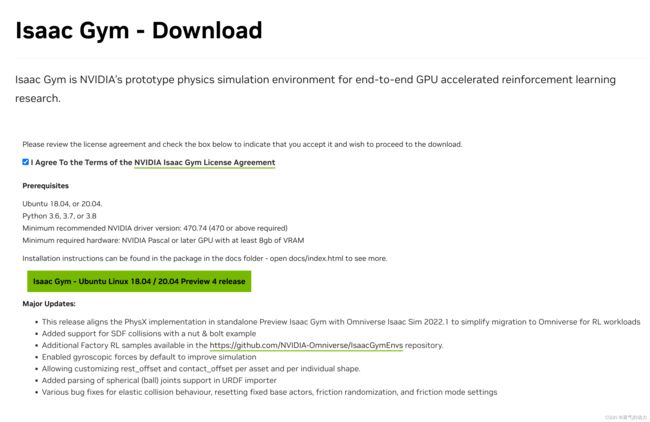
2.下载解压后的文件样式

其中assets是模型材料位置
其中docs是说明网站位置
其中python是演示程序位置
可以根据说明文档安装方式安装
这里只介绍其中conda安装的方法
# 在文件根目录里运行
./create_conda_env_rlgpu.sh
# 激活环境
conda activate rlgpu
# 正常情况下这时候可以运行实例程序/isaacgym/python/examples/joint_monkey.py
python joint_monkey.py
# 可以通过--asset_id命令控制显示的模型
python joint_monkey.py --asset_id=6
到这里IsaacGym就安装好了
1.1 可能出现的问题
# 出现这样的报错
ImportError: libpython3.7m.so.1.0: cannot open shared object file: No such file or directory
这样的报错是是因为没有对应的包,通过下面命令安装
sudo apt install libpython3.7
如果是Ubuntu20.04的系统需要运行
export LD_LIBRARY_PATH=/home/你电脑中环境的位置/anaconda3/envs/rlgpu/lib
如果报以下错误是因为模型文件URDF文件中mesh文件的地址出错,找不到模型文件导致的。建议可以直接写绝对地址。
[Error] [carb.gym.plugin] Failed to resolve visual mesh '/isaacgym/Quadruped/legged_gym-master/resources/robots/meshes/anymal/trunk.stl'
2. IsaacGym基础训练环境安装
环境的介绍地址: NVIDIA-Omniverse/IsaacGymEnvs
首先clone下项目,cd进项目,激活conda环境里运行
git clone https://github.com/NVIDIA-Omniverse/IsaacGymEnvs.git
conda activate rlgpu
pip install -e .
因为后面项目的需求最好把Pytorch版本安装到1.10以上。
可提前安装好,使用命令
一切安装正常就可以训练模型了
#cuda11.6 安装pytorch1.13
pip install torch==1.13.0+cu116 torchvision==0.14.0+cu116 torchaudio==0.13.0 --extra-index-url https://download.pytorch.org/whl/cu116
# 更换国内源
pip install torch==1.13.0+cu116 torchvision==0.14.0+cu116 torchaudio==0.13.0 --extra-index-url https://pypi.tuna.tsinghua.edu.cn/simple
训练模型命令
python train.py task=Ant
# 不显示动画只训练
python train.py task=Ant headless=True
# 测试训练模型的效果,num_envs是同时进行训练的模型数量
python train.py task=Ant checkpoint=runs/Ant/nn/Ant.pth test=True num_envs=64
3. Isaac Gym Environments for Legged Robots基础训练环境安装
3.1 Legged Robots介绍
该方法提出一种训练模式,该模式通过在单个GPU工作站上使用大规模并行的方法来实现现实世界机器人任务的快速控制策略的生成。
网站地址: https://leggedrobotics.github.io/legged_gym/论文地址: 链接: Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning
3.2 环境安装
环境要求
Python:3.6, 3.7 or 3.8 (3.8 推荐)
Pytorch: 1.10 with cuda-11.3 (本人使用:Pytorch 1.13 with cuda-11.6)
本人测试如果pytorch环境低于1.10会报错。如果已经安装了不匹配的torch环境,使用以下命令重新安装
根据你安装torch 方法卸载,pip或是conda。
# pip卸载torch
pip uninstall torch
# conda卸载torch
conda uninstall torch
# 安装pytorch cuda11.6 pytorch1.13
pip install torch==1.13.0+cu116 torchvision==0.14.0+cu116 torchaudio==0.13.0 --extra-index-url https://download.pytorch.org/whl/cu116
上面都安装好了之后需要安装rsl_rl(PPO的应用库)
Clone链接:leggedrobotics/rsl_rl
git clone https://github.com/leggedrobotics/rsl_rl.git
cd rsl_rl && pip install -e .
最后Clone链接:leggedrobotics/legged_gym
git clone https://github.com/leggedrobotics/legged_gym.git
cd legged_gym && pip install -e .
上面运行完成可以运行测试
# 训来模型
python issacgym_anymal/scripts/train.py --task=anymal_c_flat
# 测试模型
python issacgym_anymal/scripts/play.py --task=anymal_c_flat
三、项目文件解析
1. Isaac Gym Benchmark Environments文件解析
项目的文件目录构成

1.1 项目架构
assets:放置模型文件,官方文件显示目前支持加载URDF和MJCF文件格式。
docs:说明文档
isaacgymenvs:代码主目录
cfg:参数文件
learing:训练的算法文件
pbt:Population-Based Training 说明文档
run:训练的统计文件和模型文件
tasks:不同任务对用的训练方法文件
utils:通用工具文件
1.2 环境创建
import isaacgym
import isaacgymenvs
import torch
# 环境中并行模型数量
num_envs = 2000
# 创建环境
envs = isaacgymenvs.make(
seed=0,
task="Ant",
num_envs=num_envs,
sim_device="cuda:0",
rl_device="cuda:0",
)
print("Observation space is", envs.observation_space)
print("Action space is", envs.action_space)
obs = envs.reset()
for _ in range(20):
# 产生随机动作
random_actions = 2.0 * torch.rand((num_envs,) + envs.action_space.shape, device = 'cuda:0') - 1.0
# 与环境交互
envs.step(random_actions)
1.3 修改模型文件
首先把要更换的模型文件方到assets文件夹下相应位置。
然后修该task文件夹下对应任务的文件。
以anymal为例。则修改IsaacGymEnvs-main/isaacgymenvs/tasks/anymal.py文件中下面代码
def _create_envs(self, num_envs, spacing, num_per_row):
asset_root = os.path.join(os.path.dirname(os.path.abspath(__file__)), '../../assets')
asset_file = "/urdf/anymal_b_simple_description/urdf/anymal.urdf"
1.4 修改奖励
以anymal为例。则修改IsaacGymEnvs-main/isaacgymenvs/tasks/anymal.py文件中下面代码
def compute_anymal_reward(
# tensors
root_states,
commands,
torques,
contact_forces,
knee_indices,
episode_lengths,
# Dict
rew_scales,
# other
base_index,
max_episode_length
):
# (reward, reset, feet_in air, feet_air_time, episode sums)
# type: (Tensor, Tensor, Tensor, Tensor, Tensor, Tensor, Dict[str, float], int, int) -> Tuple[Tensor, Tensor]
# Retrieves buffer for Actor root states. The buffer has shape (num_actors, 13). State for each actor root contains position([0:3]), rotation([3:7]), linear velocity([7:10]), and angular velocity([10:13]).
# prepare quantities (TODO: return from obs ?)
base_quat = root_states[:, 3:7]
# 获取线性速度
base_lin_vel = quat_rotate_inverse(base_quat, root_states[:, 7:10])
# 获取角速度
base_ang_vel = quat_rotate_inverse(base_quat, root_states[:, 10:13])
# velocity tracking reward 计算误差当前状态减去上一个状态的平方
lin_vel_error = torch.sum(torch.square(commands[:, :2] - base_lin_vel[:, :2]), dim=1)
ang_vel_error = torch.square(commands[:, 2] - base_ang_vel[:, 2])
# rew_scales["lin_vel_xy"]和rew_scales["ang_vel_z"] 是奖励系数在/cfg/task/Anymal.yaml中设置
rew_lin_vel_xy = torch.exp(-lin_vel_error/0.25) * rew_scales["lin_vel_xy"]
rew_ang_vel_z = torch.exp(-ang_vel_error/0.25) * rew_scales["ang_vel_z"]
# torque penalty 惩罚系数
rew_torque = torch.sum(torch.square(torques), dim=1) * rew_scales["torque"]
# 总奖励
total_reward = rew_lin_vel_xy + rew_ang_vel_z + rew_torque
total_reward = torch.clip(total_reward, 0., None)
# reset agents重置机器人参数
reset = torch.norm(contact_forces[:, base_index, :], dim=1) > 1.
reset = reset | torch.any(torch.norm(contact_forces[:, knee_indices, :], dim=2) > 1., dim=1)
time_out = episode_lengths >= max_episode_length - 1 # no terminal reward for time-outs
reset = reset | time_out
return total_reward.detach(), reset
2. Isaac Gym Environments for Legged Robots文件解析
项目的文件目录构成
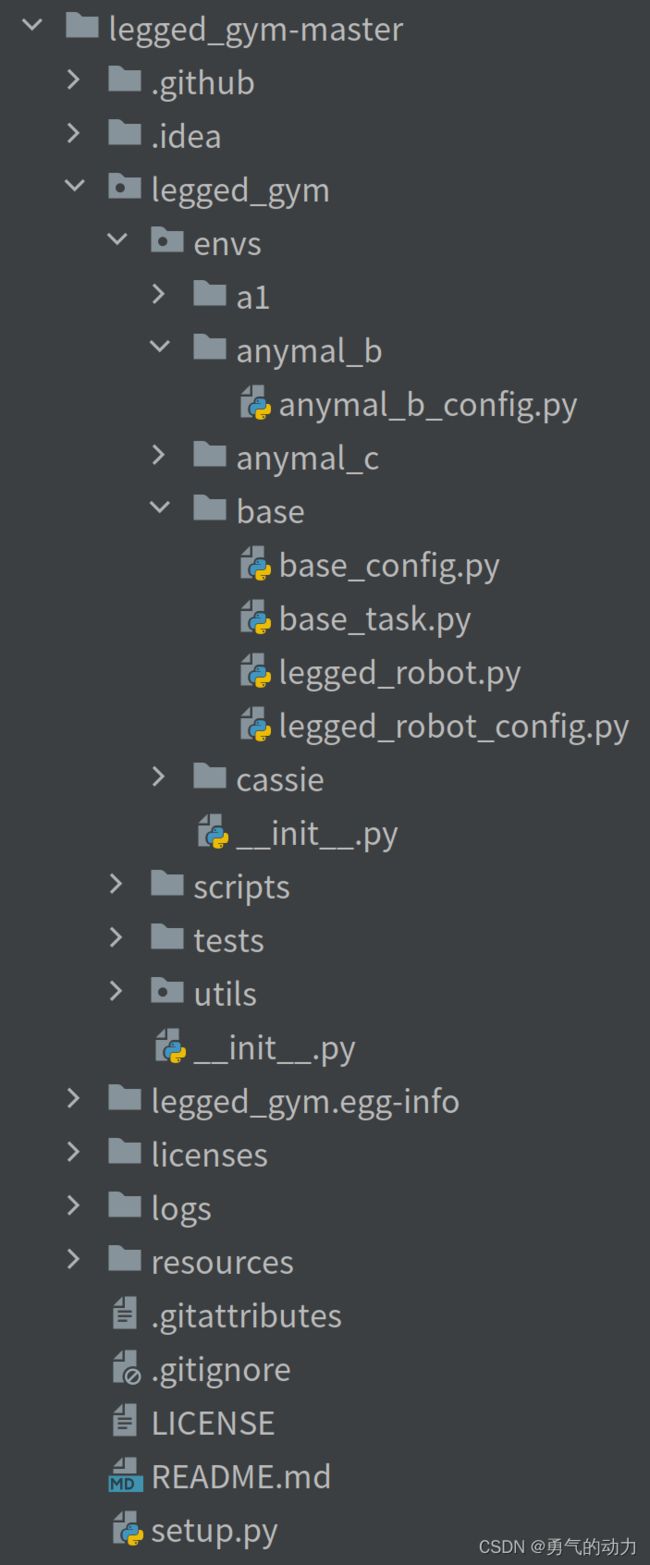
1.1 项目架构
resourses:放置模型文件,官方文件显示目前支持加载URDF和MJCF文件格式。
logs:训练后的记录文件
legged_gym:代码主目录
envs:参数文件
a1、anymal_b、anymal_c、cassie:是包含针对不同的机器模型的不同参数设置
base/legged_robot.py:主要代码文件,包含了创建仿真、计算reward、计算obs和step代码
base/legged_robot_config.py:主要包含的训练和模型的参数
scripts:训练和测试启动文件
tests:测试环境
tasks:不同任务对用的训练方法文件
utils:通用工具文件
1.2修改模型文件
首先把要更换的模型文件方到assets文件夹下相应位置。
然后修该task文件夹下对应任务的文件。
以anymal_b为例。则修改legged_gym-master/legged_gym/envs/anymal_c/mixed_terrains/anymal_c_rough_config.py文件中下面代码
class asset( LeggedRobotCfg.asset ):
file = "{LEGGED_GYM_ROOT_DIR}/resources/robots/anymal_c/urdf/anymal_c.urdf"
name = "anymal_c"
foot_name = "FOOT"
penalize_contacts_on = ["SHANK", "THIGH"]
terminate_after_contacts_on = ["base"]
self_collisions = 1 # 1 to disable, 0 to enable...bitwise filter
1.3 修改奖励
修改奖励计算,则修改/legged_gym-master/legged_gym/envs/base/legged_robot.py文件中下面代码
def compute_reward(self):
""" Compute rewards
Calls each reward function which had a non-zero scale (processed in self._prepare_reward_function())
adds each terms to the episode sums and to the total reward
"""
self.rew_buf[:] = 0.
for i in range(len(self.reward_functions)):
name = self.reward_names[i]
rew = self.reward_functions[i]() * self.reward_scales[name]
self.rew_buf += rew
self.episode_sums[name] += rew
if self.cfg.rewards.only_positive_rewards:
self.rew_buf[:] = torch.clip(self.rew_buf[:], min=0.)
# add termination reward after clipping
if "f" in self.reward_scales:
rew = self._reward_termination() * self.reward_scales["termination"]
self.rew_buf += rew
self.episode_sums["termination"] += rew
奖励计算系数设置位置:legged_gym-master/legged_gym/envs/base/legged_robot_config.py
class rewards:
class scales:
termination = -0.0
tracking_lin_vel = 1.0
tracking_ang_vel = 0.5
lin_vel_z = -2.0
ang_vel_xy = -0.05
orientation = -0.
torques = -0.00001
dof_vel = -0.
dof_acc = -2.5e-7
base_height = -0.
feet_air_time = 1.0
collision = -1.
feet_stumble = -0.0
action_rate = -0.01
stand_still = -0.
only_positive_rewards = True # if true negative total rewards are clipped at zero (avoids early termination problems)
tracking_sigma = 0.25 # tracking reward = exp(-error^2/sigma)
soft_dof_pos_limit = 1. # percentage of urdf limits, values above this limit are penalized
soft_dof_vel_limit = 1.
soft_torque_limit = 1.
base_height_target = 1.
max_contact_force = 100. # forces above this value are penalized
3. RL_Game包解析
用来构建强化学习模型和实际训练代码,是使用 rl_game包完成的。

1.1 项目架构
algos_torch:是强化模型构建代码包
common:是训练训法和测试算法的通用代码包
configs:是存储不同模型的参数信息
torch_runner.py是整合
1.2获取模型测试action的输出
common.player.py中run方法获取
def run(self):
n_games = self.games_num
render = self.render_env
n_game_life = self.n_game_life
is_deterministic = self.is_deterministic
sum_rewards = 0
sum_steps = 0
sum_game_res = 0
n_games = n_games * n_game_life
games_played = 0
has_masks = False
has_masks_func = getattr(self.env, "has_action_mask", None) is not None
op_agent = getattr(self.env, "create_agent", None)
if has_masks_func:
has_masks = self.env.has_action_mask()
need_init_rnn = self.is_rnn
for _ in range(n_games):
if games_played >= n_games:
break
obses = self.env_reset(self.env)
batch_size = 1
batch_size = self.get_batch_size(obses, batch_size)
if need_init_rnn:
self.init_rnn()
need_init_rnn = False
cr = torch.zeros(batch_size, dtype=torch.float32)
steps = torch.zeros(batch_size, dtype=torch.float32)
print_game_res = False
for n in range(self.max_steps):
if has_masks:
masks = self.env.get_action_mask()
action = self.get_masked_action(
obses, masks, is_deterministic)
else:
action = self.get_action(obses, is_deterministic)
print("rl_game action:", action)
# 获取的action动作,机器人用于执行。
obses, r, done, info = self.env_step(self.env, action)
cr += r
steps += 1
if render:
self.env.render(mode='human')
time.sleep(self.render_sleep)
all_done_indices = done.nonzero(as_tuple=False)
done_indices = all_done_indices[::self.num_agents]
done_count = len(done_indices)
games_played += done_count
if done_count > 0:
if self.is_rnn:
for s in self.states:
s[:, all_done_indices, :] = s[:,
all_done_indices, :] * 0.0
cur_rewards = cr[done_indices].sum().item()
cur_steps = steps[done_indices].sum().item()
cr = cr * (1.0 - done.float())
steps = steps * (1.0 - done.float())
sum_rewards += cur_rewards
sum_steps += cur_steps
game_res = 0.0
if isinstance(info, dict):
if 'battle_won' in info:
print_game_res = True
game_res = info.get('battle_won', 0.5)
if 'scores' in info:
print_game_res = True
game_res = info.get('scores', 0.5)
if self.print_stats:
cur_rewards_done = cur_rewards/done_count
cur_steps_done = cur_steps/done_count
if print_game_res:
print(f'reward: {cur_rewards_done:.1f} steps: {cur_steps_done:.1} w: {game_res:.1}')
else:
print(f'reward: {cur_rewards_done:.1f} steps: {cur_steps_done:.1f}')
sum_game_res += game_res
if batch_size//self.num_agents == 1 or games_played >= n_games:
break
print(sum_rewards)
if print_game_res:
print('av reward:', sum_rewards / games_played * n_game_life, 'av steps:', sum_steps /
games_played * n_game_life, 'winrate:', sum_game_res / games_played * n_game_life)
else:
print('av reward:', sum_rewards / games_played * n_game_life,
'av steps:', sum_steps / games_played * n_game_life)