Pytorch-YOLOv4梳理——原理和复现
yolov1到yolov3的梳理:YOLO总结,从YOLOv1到YOLOv3_追忆苔上雪的博客-CSDN博客
首先说一点,就是yolov4的分支有点多,先梳理一下出现的顺序。
Alexey Bochkovskiy提出了YOLOv4
然后针对YOLOv4的模型缩放(model scale),提出了Scaled-YOLOv4
Scaled-YOLOv4针对低端、一般、高端GPU分别设计了3个模型,
分别是:YOLOv4-CSP 、 YOLOV4 -tiny、YOLOv4-large

再说一点,论文给的网站,要拖到下面才能找到pytorch版本的代码
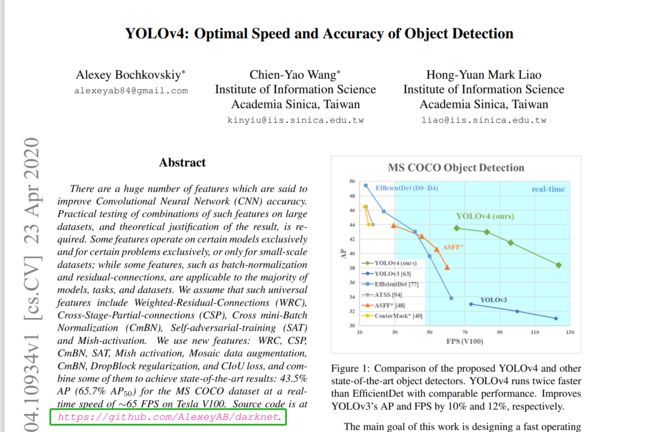

yolov4论文:https://arxiv.org/abs/2004.10934
scale-yolov4论文:https://arxiv.org/abs/2011.08036
后续用下面这个版本的做例子:GitHub - WongKinYiu/PyTorch_YOLOv4: PyTorch implementation of YOLOv4,这就是论文的二作复现的
yolov4-csp:GitHub - WongKinYiu/ScaledYOLOv4 at yolov4-csp
yolov4-large:GitHub - WongKinYiu/ScaledYOLOv4: Scaled-YOLOv4: Scaling Cross Stage Partial Network
yolov4-tiny:GitHub - WongKinYiu/ScaledYOLOv4 at yolov4-tiny
(1)yolov4相比yolov3的改善
YOLOv4是YOLOv3的加强版,其主要在YOLOv3的基础上添加了一系列的小改进。因此YOLOV4与YOLOV3整体的预测思路是没有差别的!解码的过程甚至一模一样。
YOLOv4的小改进遍布方方面面,主要有以下几点:
(1)主干特征提取网络的改进
由Darknet53改成了CSPDarknet53
(2)加强特征提取网络的改进
使用了SPP和PANet结构
(3)数据增强方面的改进
使用了Mosaic数据增强
(4)LOSS方面的改进
使用了CIOU作为回归LOSS
(5)使用了MISH激活函数

(2)利用coco128复现pytorch版本yolov4
yolov4-pytorch下载:GitHub - WongKinYiu/PyTorch_YOLOv4: PyTorch implementation of YOLOv4,这就是论文的二作复现的
关于环境的配置这里省去
(1)权重文件的下载
权重文件网上有资源

(2)数据集处理
这里使用coco128数据集复现,该数据集小,对电脑或者服务器处理压力比较友善
打开train.py文件,注意到这里使用了yaml文件对数据集的信息进行处理
![]()
打开coco.yaml文件,可以看到数据集信息都放这里面了,根据注释,我们将coco128的图片路径放进去,这个路径自己改,我是用的绝对路径,由于coco128只有train2017,训练集验证集测试集我们就用这一个
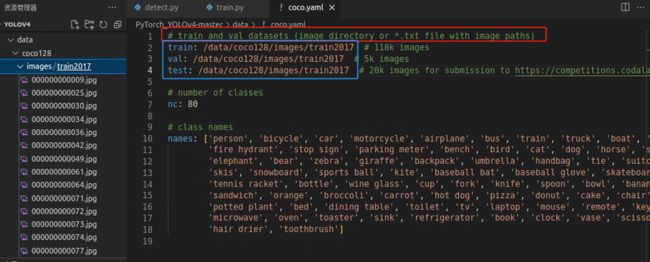
(3)train.py训练报错
如果出现相关报错,可以参考一下下面的,下面没有就自己查一下。
1.BrokenPipeError:[Errno 32] Broken pipe
将works数值改成0
![]()
2.RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)

这个错误的意思就是部分在GPU上运行,部分在CPU上运行;
定位到loss.py的报错之处

在上图的红框处加一行代码

3.RuntimeError: result type Float can‘t be cast to the desired output type long int
这个版本的torch不支持float直接转换为long int 型数据,所以这需要我们手动转换数据类
![]()
定位到错的地方

打开还是loss.py里的错,但不是改上面那一行
找到下面这一行

改成这样

4.torch.cuda.OutofMemoryError:CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 15.77 GiB total capacity; 14.44 GiBalready allocated; 10.69 MiB free; 14.69 6iB reserved in total by PyTorch) If reserved memory is >> allocated memory trysetting max_split_size_mb to avoid fragmentation.See documentation for Memory Management and PYTORCH CUDA ALLOC CONF
显存爆了,换个小点的batch_size=1,还是报错

于是注意到了报错中的这一句
If reserved memory is >> allocated memory trysetting max_split_size_mb to avoid fragmentation
代表目前可分配的显存足够,但是因为碎片化无法分配,需要整理碎片化显存,释放出能够用于运行的容量。
咱们代码的开头加这么一行代码,将小于128Mb大小的空闲显存block重新分配

开始训练的地方也加这么两行,清理缓存

5.TypeError: list indices must be integers or slices, not float

定位到报错位置

改成下面这个
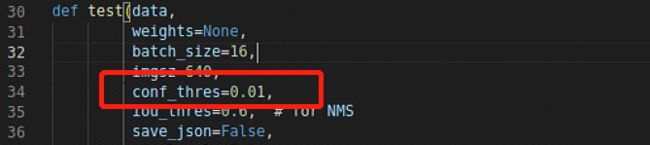
6.RuntimeError: Trying to create tensor with negative dimension -1919062876: [-1919062876)

找到test.py置信度阈值

改成0.01,见下图
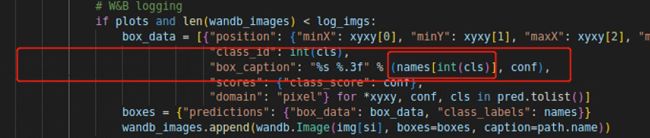
7.AttributeError: 'list' object has no attribute 'items'
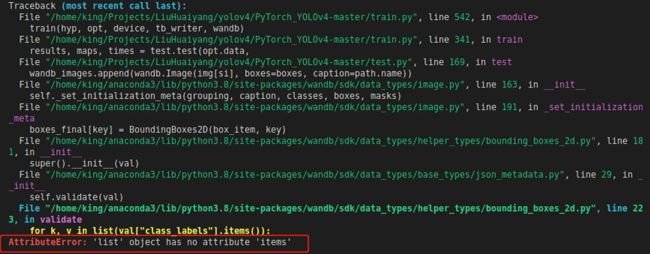
定位到错误之处,又是这个地方,人都麻了

改成下列代码
# W&B logging
if plots and len(wandb_images) < log_imgs:
box_data = [{"position": {"minX": xyxy[0], "minY": xyxy[1], "maxX": xyxy[2], "maxY": xyxy[3]},
"class_id": int(cls),
"box_caption": "%s %.3f" % (names[int(cls)], conf),
"scores": {"class_score": conf},
"domain": "pixel"} for *xyxy, conf, cls in pred.tolist()]
# if necessary, create a dict using list indices as keys, so it can be queried almost exactly like a list
if type(names) == type([]):
names_dict = {idx:val for idx, val in enumerate(names)}
boxes = {"predictions": {"box_data": box_data, "class_labels": names_dict}}
else:
boxes = {"predictions": {"box_data": box_data, "class_labels": names}}
wandb_images.append(wandb.Image(img[si], boxes=boxes, caption=path.name))8.TypeError: can’t convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.

定位到plots.py找到下图红框中的位置

加一行代码

(4)train.py跑通
解决了上述问题后,用五个epochs实验代码能否跑通,发现能完整跑通了
然后我把batch_size改成4,然后epoch改成300,完整跑完了代码


(5)test.py报错
把上面训练得到的权重放进路径,然后注意一些参数的路径和设置
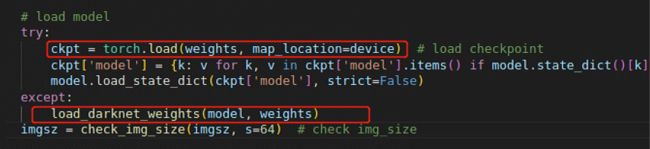
1.IsADirectoryError: [Errno 21] Is a directory: '/'

定位到报错处
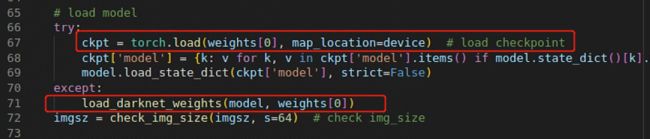
改成下面这样
2.Error: You must call wandb.init() before wandb.log()

定位到报错处

加一行代码

3.IndexError: list index out of range

定位到错误的地方,发现代码用的原coco数据集的标签

而我们用的是coco128数据集测试效果的,coco128没有json文件而且只有train2017部分数据于是我把下列代码注释了,然后跑完了测试代码


(6)test.py跑通
解决了上述问题就能跑通了
(7)detect.py报错
1.FileNotFoundError: [Errno 2] No such file or directory:'w'

定位到错误的地方

改成下面这样

(8)detect.py跑通
改改路径就能跑通


