VIGC:自问自答,高质量视觉指令微调数据获取新思路
从今年四月份开始,随着MiniGPT-4, LLaVA,
InstructBLIP等多模态大模型项目的开源,大模型的火从NLP领域烧到了计算机视觉及多模态领域。多模态大模型需要高质量的图文对话数据进行指令微调,而当前多模态指令微调数据多基于纯文本GPT-4构建,其数据质量及多样性相对受限。为此,我们提出了视觉指令生成及修正模型VIGC,可以基于多模态模型自动生成多样性的指令数据,并基于指令修正模块减少幻觉,保证数据质量。这些指令数据加入模型微调,可以进一步提升模型性能。

VIGC能做什么?
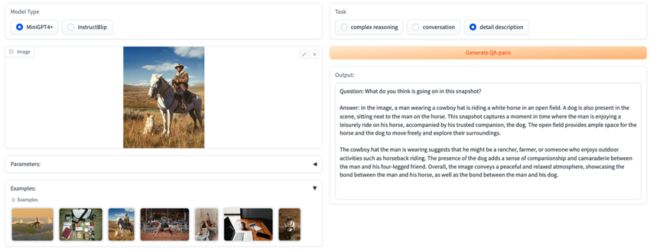
图1. VIGC示例:输入图像,模型自动生成相关问题及对应答案
如图所示,用户提供(1)任意图像;(2)所需数据类型,VIGC可以生成该图像对应的问题和答案。相比于当前图文多模态大模型给定图像和问题,获取对应问题的答案,VIGC可以实现自问自答,而这些问答对本身可以作为高质量的指令微调数据,用于多模态大模型的训练,进一步提升模型性能。
VIGC有什么优势?
要回答这个问题,我们首先看一下当前指令微调数据的获取方案。

图2:纯文本GPT-4用于指令微调数据生成
当前获取图文指令微调数据多基于Language-only GPT-4,结合提供的图像、图像相关标注及人工标注问题,由GPT-4来生成对应的答案。这种方式存在两个缺陷:
● 标注成本高: 由于GPT-4无法看到真实图像,需要人工标注对应的图像信息(如图像中的目标类别,定位信息,描述信息)基于跟图像相关的问题。
● 答案质量受限于标注: 一张图像中包含的信息量远远大于标注信息,所以GPT-4在回答问题时,直接依赖于受限的标注信息,容易丢失图像中的细节信息。

相比之下,VIGC通过初始的指令微调数据训练模型,引导模型基于图像自动生成合适的问题及回答。这种方式相比于纯文本GPT-4生成指令微调数据的优势在于:
● 包含更多细节内容: VIGC生成的答案是模型真正看到图像内容进行回答,包含了更多的细节信息;
● 无需额外表述: VIGC能够针对没见过的图像内容依然生成高质量的问答数据,得益于VIGC模型能够通过视觉模型提取到图像的视觉信息,并依赖于后续的语言模型自动生成答案。这里的关键点在于:视觉模型和大语言模型本身就看过海量的图文、纯文本数据,本身集成了大量的知识,VIGC更像是从这些大模型中蒸馏出跟图像相关的知识。
如何训练和使用VIGC?

图3. VIGC框架图。左侧对应VIGC训练流程,右侧对应VIGC推理流程。
01 训练流程
为了获取给定图像,自动生成图文的内容,需构造初始的指令微调数据,包含图像、问题类型,对应图像相关的问题及正确答案。视觉指令生成VIG训练阶段的
● 输入信息: 图像及对应的问题类型(如对话类型、详细描述类型、逻辑推理类型)
● 输出信息: 该类型的问题和答案。
然而仅利用上述的方式,模型在输出详细描述类信息时,经常会出现严重的幻觉问题,这一现象在当前主流多模态大模型中普遍存在,本质上是当训练数据存在某些重复的模式时,生成模型很容易过拟合到这种数据分布。例如在训练图像中,问答对中出现人和桌子的描述时,后续经常会出现椅子的描述。推理阶段,模型会倾向于看到人和桌子,就提及椅子(即便推理图像中没有椅子)。
为此,VIGC通过使用迭代Q-Former的方式及时更新输入到模型的特征信息,让模型在回答问题时结合问题本文关注的内容以及当前已有部分回答,完成后续的回答。所以在训练阶段,我们同时加入视觉指令修正模块VIC,该阶段的:
● 输入信息: 图像、对应问题类型、问题
● 输出信息: 答案
02 推理阶段
为了获取高质量的指令微调数据,推理阶段的流程如下:
a. 给定图像及问题类型,VIG生成对应问题和答案;
b. 将图像及VIG生成问题输入VIC,经Q-Former提取问题相关的图像特征后生成新的答案 ;
c. 将上述答案拆分,将第一句回答和图像、问题再次输入VIC,生成更新后的第二句答案 A2;
d. 整个过程迭代执行,直到模型遇到结束符。
VIGC数据对模型帮助?
基于VIGC生成的数据,重新加入模型训练后,我们发现模型的性能可以进一步提升。

表1. 加入VIGC数据模型性能提升
如上表所示,在基于MMBench的评测上,加入VIGC生成的额外数据,指标可以从24.4%提升至27.5%。在LLaVA评测集上,指标从84.7%提升到87%。
总结
VIGC提出了一种新的多模态指令数据构造方式,可以基于无标注的图像自动生成多样性的高质量数据,且基于生成数据可以进一步提升当前模型的性能,可以作为指令数据获取及模型性能提升的新思路。
VIGC相关资料
论文地址:https://arxiv.org/pdf/2308.12714.pdf
代码:https://github.com/opendatalab/VIGC
Demo:https://opendatalab.github.io/VIGC
VIGC模型已开源,欢迎star!
更多精彩内容,请访问 OpenDataLab:https://opendatalab.org.cn/