JDK1.8新特性——Stream流
一、概念以及用途
Java8的两个重大改变,一个是Lambda表达式,另一个就是本节要讲的Stream API表达式。Stream 是Java8中处理集合的关键抽象概念,它可以对集合进行非常复杂的查找、过滤、筛选等操作,在新版的JPA【连接数据库】中,也已经加入了Stream。如:
@Query("select u from User u")
Stream findAllByCustomQueryAndStream();
Stream readAllByFirstnameNotNull();
@Query("select u from User u")
Stream streamAllPaged(Pageable pageable); Stream API给我们操作集合带来了强大的功用,同时Stream API操作简单,容易上手。
二、Stream流的操作步骤
- 创建Stream 从一个数据源,如集合、数组中获取流。
- 中间操作 一个操作的中间链,对数据源的数据进行操作。
- 终止操作 一个终止操作,执行中间操作链,并产生结果

假设我们现在有一个List
- 拿到所有姓张的
- 拿到名字长度为3个字的
- 打印这些数据
下面代码为大家展现Stream流与JDK8之前对该需求的操作方法:
package test.StreamTest;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
/**
* @作者:徐志豪
* @创建时间 2022/7/20 20:16
* 为什么要使用Stream流 书写优雅,提高性能
**/
public class WhyWeUseStream {
public static void main(String[] args) {
ArrayList list = new ArrayList<>();
Collections.addAll(list, "张无忌", "周芷若", "赵敏", "张强", "张三丰");
//需求:1.拿到所有姓张的 2.拿到名字长度为3个字的 3.打印这些数据
//传统做法 for循环,new新的ArrayList存放需求的数据
//1.拿到所有姓张的
List nameList = new ArrayList<>();
for (String s : list) {
if (s.startsWith("张")){
nameList.add(s);
}
}
//2.拿到名字长度为3个字的
List lengthList = new ArrayList<>();
for (String s : list) {
if (s.length()==3){
lengthList.add(s);
}
}
//3.打印这些数据
for (String s : nameList) {
System.out.println(s);
}
System.out.println("------------");
for (String s : lengthList) {
System.out.println(s);
}
System.out.println("+++++++++++++++++++++++++++++++");
//Stream流实现上述需求
//1.拿到所有姓张的并打印
list.stream()
.filter((str)->str.startsWith("张"))
.forEach(System.out::println);
System.out.println("------------");
//2.拿到名字长度为3个字的并打印
list.stream()
.filter((str)->str.length()==3)
.forEach(System.out::println);
}
} 我们可以看到传统做法想要实现上述的需求,需要不断的循环和创建新的集合来接操作后的数组,这样性能不高,而且比较繁琐
Stream流操作中,其中 list.stream()是创建stream流,filter()属于中间操作,forEach()属于终止操作。具体这三个操作步骤会在下面详细讲述:
2.1 创建Stream流对象
(1)通过Collection对象的Stream()或parallerStream()方法
List list = new ArrayList<>();
//串行 单线程
Stream stream = list.stream();
//并行 多线程
Stream stringStream = list.parallelStream(); (2)通过Arrays类的Stream()方法
Integer[] arr = {1,2,3,4,5,6};
Stream stream1 = Arrays.stream(arr); (3)通过Stream接口的of(),iterate(),generate()方法
Stream integerStream = Stream.of(1, 2, 3, 4, 5, 6, 7);
Stream stringStream1 = Stream.of("1", "2", "3", "4"); (4)通过IntStream,LongStream,DoubleStream接口中的of(),range(),rangeClosed()方法
IntStream intStream = IntStream.of(1, 2, 3, 4, 5, 6);
DoubleStream doubleStream = DoubleStream.of(1.1, 2.2, 3.3, 4.4, 5.5);2.2 中间操作
用下面这个集合来举例:
public static void main(String[] args) {
ArrayList list = new ArrayList<>();
Collections.addAll(list, "张无忌", "周芷若", "赵敏", "张强", "张三丰","张无忌");
} (1).limit(n) 从list中取出n个元素
list.stream().limit(2).forEach(System.out::println);(2).skip(n) 从list第n个元素开始,取出所有元素
list.stream().skip(3).forEach(System.out::println);(3).distinct() 去除重复
list.stream().distinct().forEach(System.out::println);(4).filter(Predicate predicate) 筛选条件
括号中的内容为一个断言型函数式接口,其中的T为当前集合中元素的类型。
下面的中间操作我们换一个集合来举例,为大家附上集合代码,直接cv拿来用就可以:
Person类:
class Person {
private String name;
private Integer age;
private String country;
private char sex;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getCountry() {
return country;
}
public void setCountry(String country) {
this.country = country;
}
public char getSex() {
return sex;
}
public void setSex(char sex) {
this.sex = sex;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
", country='" + country + '\'' +
", sex=" + sex +
'}';
}
public Person(String name, Integer age, String country, char sex) {
this.name = name;
this.age = age;
this.country = country;
this.sex = sex;
}
}PersonList集合:
public static void main(String[] args) {
List personList = new ArrayList<>();
personList.add(new Person("欧阳雪",18,"中国",'F'));
personList.add(new Person("Tom",24,"美国",'M'));
personList.add(new Person("Harley",22,"英国",'F'));
personList.add(new Person("向天笑",20,"中国",'M'));
personList.add(new Person("李康",22,"中国",'M'));
personList.add(new Person("小梅",20,"中国",'F'));
personList.add(new Person("何雪",21,"中国",'F'));
personList.add(new Person("李康",22,"中国",'M'));
} 由此可见,在我们这个例子中,filter()中的内容中的T应该为Person类。
我们知道断言型函数式接口返回值为boolean,所以他的用法就是让结果是true的元素留下,结果是false的元素筛选掉。
找出年龄大于20的人并打印输出:
personList.stream()
.filter((person)->person.getAge()>20)
.forEach(System.out::println);(5).map(Function mapper ) 将元素转换成其他形式或提取信息。
其中的T在这里应为Person
.map() 接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。就好比将现有元素,经过map方法处理过后,变成一个新的元素,这个元素就是你想过滤后的,你需要的元素,过滤的要求就是map中的Function函数型函数式接口。
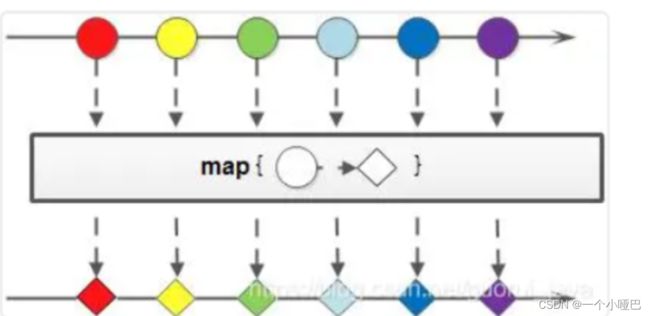
打印出集合中所有人的年龄各式多少:
personList.stream()
.map((person -> person.getAge()))
.forEach(System.out::println);这里的map中的Lambda表达式可以转换为实例方法引用的形式:
.map((Person::getAge))(6).sorted() / .sort(Comparator comparator) 对元素进行排序
我们可以看到这个操作方法进行了重载,可以是无参(自带默认排序)或是传入一个比较器参数(自定义排序规则)
打印出所有的中国人并按照年龄升序排序:
personList.stream()
.filter((p) -> p.getCountry().equals("中国"))
.sorted((p1,p2)->p1.getAge()-p2.getAge())
.forEach(System.out::println);2.3 终止操作
(1).count() 计算元素的个数
求中国人的个数并打印输出:
long num = personList.stream()
.filter((p) -> p.getCountry().equals("中国"))
.count();
System.out.println("中国人的个数为"+num);(2).forEach() 遍历
遍历元素,一般用于遍历输出。
打印输出所有元素:
personList.stream().forEach(System.out::println);(3).reduce () 规约 元素反复结合,得到一个值 传参方式有如下两种:
Integer identity,BinaryOperatoraccumulator
BinaryOperatoraccumulator 第一种传参方式的第一个参数为默认值,后面的参数为合并方式。
第二种传参方式与第一种的第二个参数相同
求元素中的年龄总和:
Optional reduce = personList.stream()
.map((person -> person.getAge()))
.reduce((a1, a2) -> a1 + a2);
System.out.println(reduce.get()); (4).collect() 收集 将流转换为其他形式
参数 接收一个Collector接口实现 ,用于给Stream中汇总的方法 ,常见的有Collecters.toList等等
将元素中年龄大于20的人收集并转为list:
List collect = personList.stream()
.filter((person -> person.getAge() > 20))
.collect(Collectors.toList());
System.out.println(collect); (5).max(Comparator comparator) 最大值 传入一个比较器参数
.min(Comparator comparator) 最小值 传入一个比较器参数
求集合中年龄最大的人:
Optional min = personList.stream()
.min((p1, p2) -> p1.getAge() - p2.getAge());
System.out.println(min.get()); 求集合中年龄最小的人:
Optional max = personList.stream()
.max((p1, p2) -> p1.getAge() - p2.getAge());
System.out.println(max.get()); (6).allMatch(Predicate predicate) 检查是否匹配所有元素
.anyMatch(Predicate predicate) 检查是否至少匹配一个元素
.noneMatch(Predicate predicate) 检查是否没有匹配所有元素
//match->
// allMatch 都满足返回true
boolean b = personList.stream()
.allMatch((person -> person.getAge() < 25));
System.out.println(b);
// anyMatch 只要有满足条件的就返回true
boolean b1 = personList.stream()
.anyMatch(person -> person.getAge() == 18);
System.out.println(b1);
// noneMatch 都不满足返回true
boolean b2 = personList.stream()
.noneMatch(person -> person.getAge() < 10);
System.out.println(b2);(7).findFirst() 返回第一个元素
.findAny() 返回当前流中的任意元素
//find ->
// findFirst 返回第一个满足条件的元素
//返回第一个年龄大于20的人
Optional first = personList.stream()
.filter(person -> person.getAge() > 20)
.findFirst();
System.out.println(first.get());
// findAny 随机返回一个满足条件的元素 一般用在parallelStream()中
//随机返回一个中国人
Optional p = personList.parallelStream()
.filter(person -> person.getCountry().equals("中国"))
.findAny();
System.out.println(p.get());