Redis Part1

单体架构:一台Web服务器、一台数据库服务器。
回顾,关系型数据库:基于二维表来存储数据的数据库就是关系型数据库。
MySQL跟Redis的区别:
- MySQL是关系型数据库,它是基于表来存储数据的,MySQL数据是写在磁盘的,它是跟磁盘进行交互的;Redis是非关系型数据库,它是把数据存储在内存当中的,是跟内存进行交互的。
- MySQL基于标准、统一的SQL语言去操作,而Redis是基于指令去操作的。
1.了解NoSql
什么是Nosql?
- NoSQL,即Not-Only-SQL,意思就是我们干事情不能只用SQL,泛指非关系型的数据库!
- NoSQL定位:作为关系型数据库的补充!最终数据还是存储在硬盘/磁盘里面。
-
NoSQL仅仅是一个概念, 泛指非关系型的数据库,区别于关系数据库,它们不保证关系数据的ACID特性。
-
NoSQL不是什么情况下都用的,是有适用前提的:应对基于海量用户(高并发)和海量数据前提下的数据处理问题。
 常见的NoSql产品
常见的NoSql产品

2.Redis介绍
2.1什么是Redis
- 是完全开源免费的,用C语言编写的, 遵守 BCD协议。
- 是一个高性能的(key-value)分布式内存数据库, 基于内存运行并支持持久化的NoSQL数据库,是当前最热门的NoSql数据库之一,也被人们称为数据结构服务器。
- 可用作高速缓存,提高系统的整体访问性能!(why高速===>内存)
- Redis是一个基于内存去交互的数据库。
- Redis的出现是为了解决性能问题。
- Redis更多保证我们数据的性能,既然保证性能,意味着一定会损失数据的一致性、可靠性。
- Redis属于CAP模型中的AP模型。如果发生网络分区了,是保证C呢还是保证A呢?
什么是CAP模型?
- CAP模型是一种用于描述分布式系统特性的理论模型。
- CAP模型由三个关键概念组成:一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance)。
- 一致性(Consistency):指的是在分布式系统中,当一个节点对数据进行修改后,其它节点立即能够看到这个修改。官方:指的是在分布式系统中,所有节点对于同一份数据的访问和操作都能保持一致的特性。
- 可用性:指的是系统能够及时响应用户请求,并一直保持可用的状态。即使系统中的某个节点发生故障或者网络出现问题,系统仍然能够继续运行。
- 分区容错性:指的是系统在面对网络分区(节点之间的通信中断或丢失)的情况下继续运行。分布式系统通常由多个节点组成,分布在不同的物理位置上,而网络分区可能导致节点之间无法直接通信。
- 根据CAP模型,分布式系统无法同时满足一致性、可用性和分区容错性这三个特性,最多只能同时满足其中的两个。
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储
- Redis支持数据的备份,即master-slave(主从)模式的数据备份
2.2 Redis优势
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。官方提供的数据是可以达到100000+的QPS(每秒内查询次数)
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的=>是线程安全的,同时Redis还支持对几个操作全并后的原子性执行。
- 丰富的特性 – Redis还支持 publish/subscribe订阅,通知,key 过期等等特性
- Redis的工作线程采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
- 使用多路I/O复用模型,非阻塞IO;
- 适合存储热点数据(热点商品、咨询、新闻)
key-value结构存储:
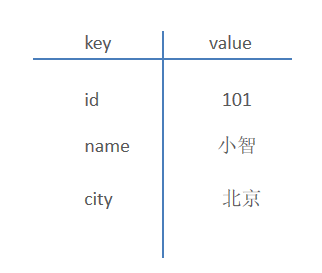
Redis为什么快?
- 基于内存去操作,没有实时的磁盘IO,数据异步刷新到磁盘。
- 本身就是Key-Value结构,类似于HashMap,一个Key会对应一个Value,通过一个Key的Hash值 取余 数组的长度-1 得到一个数组的下标,知道这个数据放在哪里,去拿的时候,直接能找到下标,所以查询速度戒心O(1)。
2.3 Redis下载
(1)Http://redis.io/ 英文地址
(2)Http://www.redis.cn/ 中文地址
3.2 Redis的安装
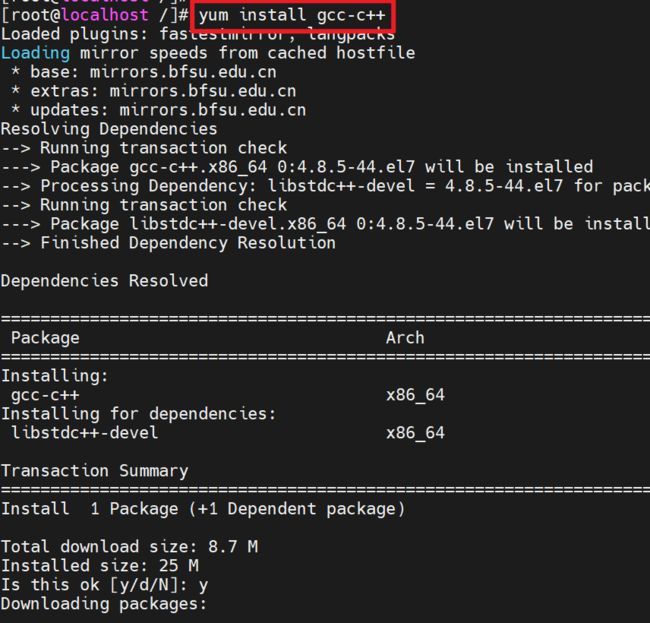
3.2.1 Redis的编译环境
- Redis是C语言开发的,安装redis需要先去官网下载源码进行编译,编译需要依赖于GCC编译环境,如果CentOS上没有安装gcc编译环境,需要提前安装,安装命令如下:yum install gcc-c++

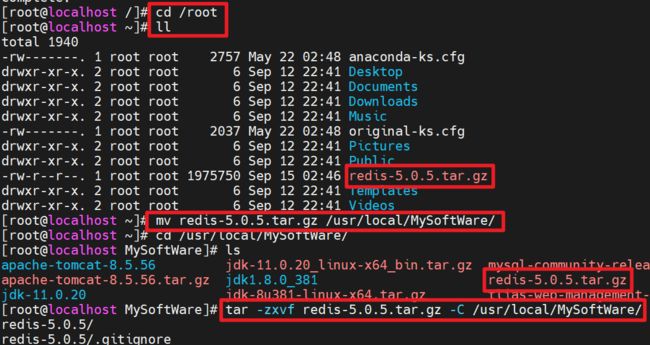
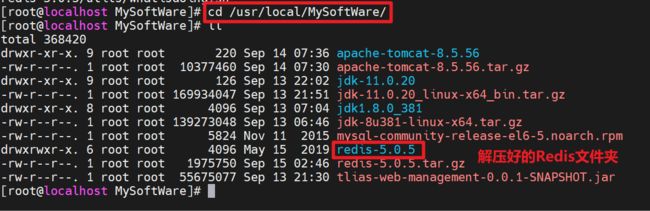
上传Redis安装文件到Linux服务器,并且移动到/usr/local/MySoftWare目录中,接着解压:
编译Redis(编译,将.c文件编译为.o文件)
- 进入解压文件夹,执行 make
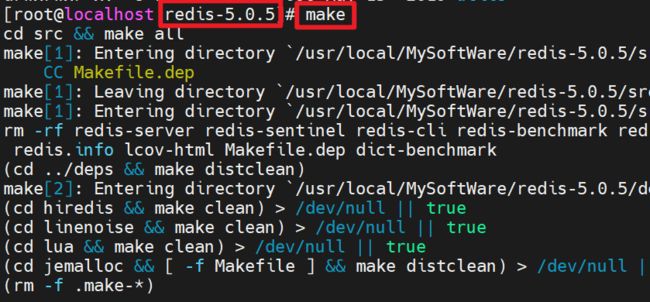
- 编译成功!如果编译过程中出错,先删除安装文件目录,后解压重新编译。
 安装:make PREFIX=/home/admin/myapps/redis install
安装:make PREFIX=/home/admin/myapps/redis install
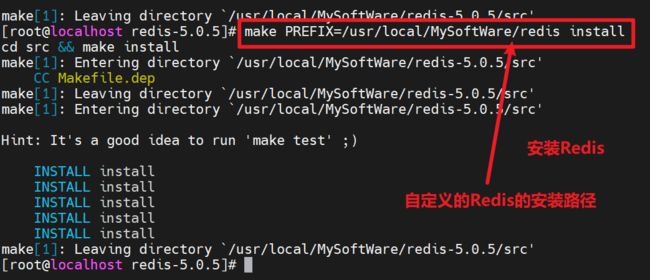
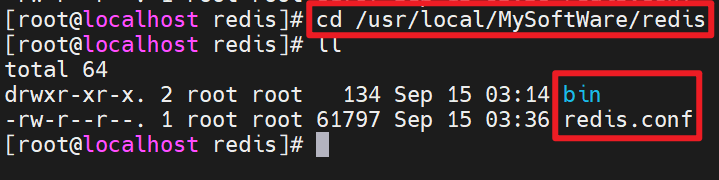
安装之后的bin目录:
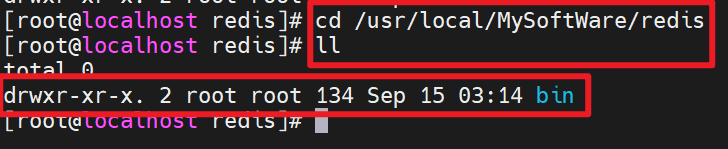 bin文件夹下的命令:
bin文件夹下的命令:
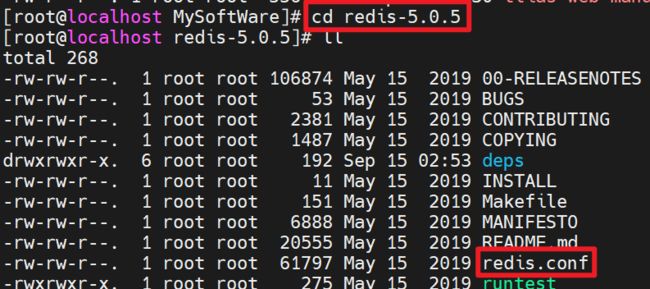
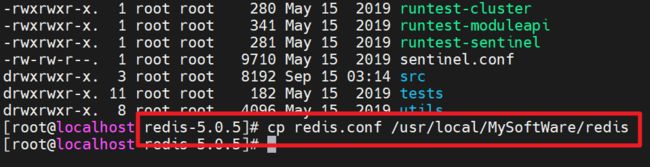
 Copy文件:将redis解压的文件夹中的redis.conf文件复制到安装目录
Copy文件:将redis解压的文件夹中的redis.conf文件复制到安装目录
- Redis启动需要一个配置文件,可以修改端口号信息。
3.3 Redis的启动
3.3.1 Redis的前端模式启动
直接运行bin/redis-server将使用前端模式启动:
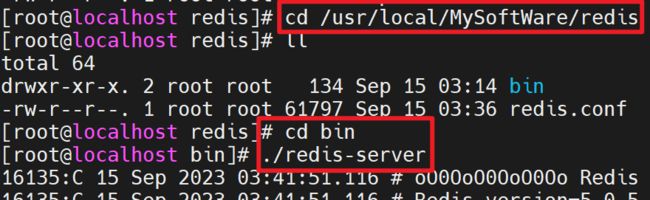
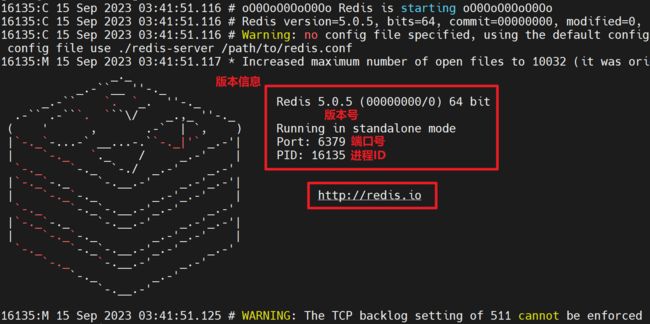
前端模式启动的缺点是启动完成后,不能再进行其他操作,这个界面只能启动,启动后不能进行其他操作,如果要退出操作必须使用Ctrl+C。
3.3.2 Redis的后端启动
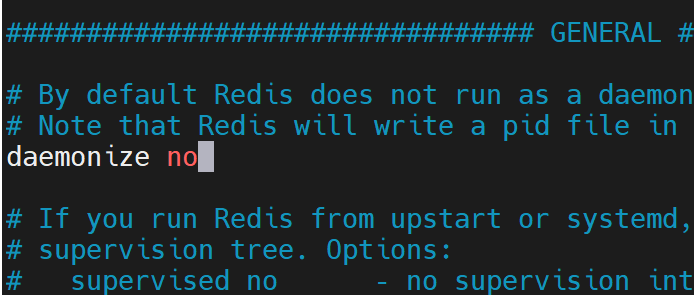
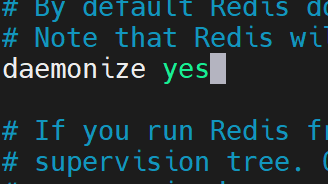
修改redis.conf配置文件,找到daemonize no,将no改为yes,然后可以使用后端模式启动。
- no表示不允许后端启动!
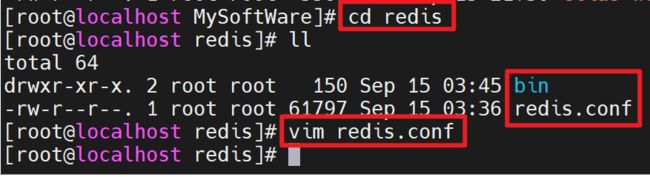
启动时,需要既指定指令,指定配置文件(这里所在文件夹是redis)

Redis默认端口:6379,通过当前服务进行查看

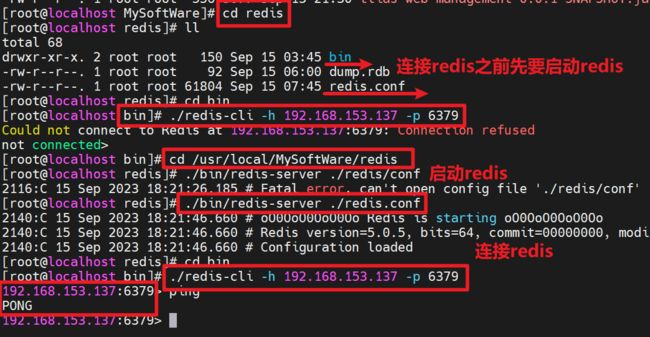
3.3.3 客户端访问连接redis
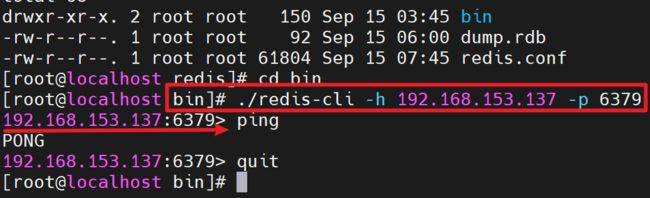
- 如果想要通过指令来操作redis,可以使用redis的客户端进行操作,在bin文件夹下运行redis-cli
- 如果想要连接指定的ip地址以及端口号,则需要按照: redis-cli -h ip地址 -p 端口号 语法结构连接。
- 该指令默认连接的127.0.0.1 ,端口号是6379
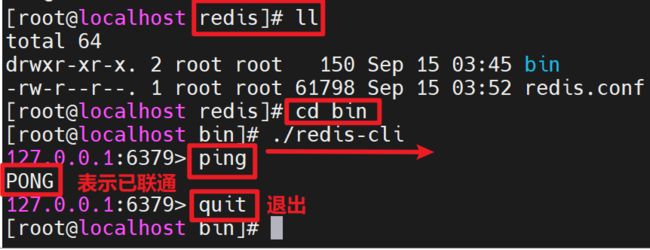
3.3.4 向Redis服务器发送命令
- ping,测试客户端与Redis的连接是否正常,如果连接正常,回收到Pong
3.3.5 退出客户端:quit
3.3.6 Redis的停止
(1) 强制结束程序(不推荐)
- 强制终止Redis进程可能会导致Redis持久化数据丢失。
- 语法:kill -9 pid
- 进程号pid可以通过 ps -aux | grep redis 进行查询。
(2) 正确停止Redis的方式应该是 :向Redis发送SHUTDOWN命令,方法为(关闭默认的端口)

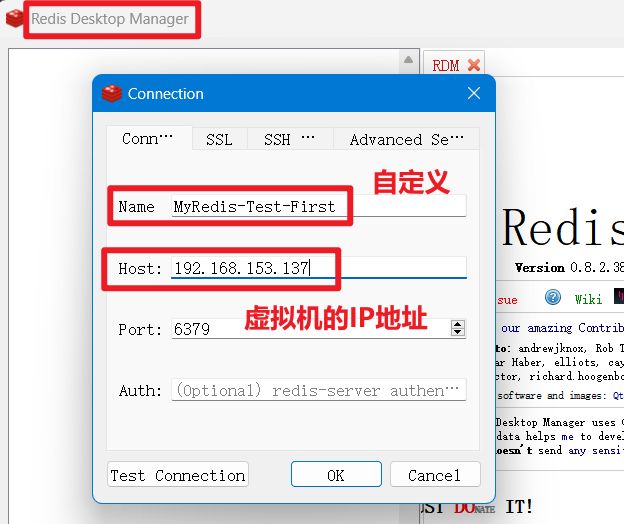
3.3.7 第三方工具(redis-desktop-manager)操作redis
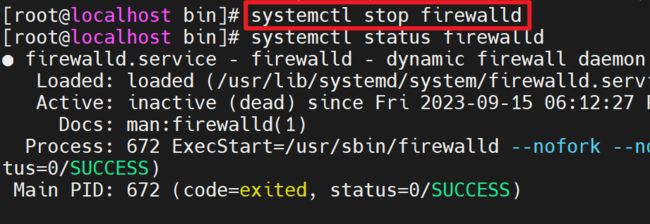
1. 关闭Linux防火墙
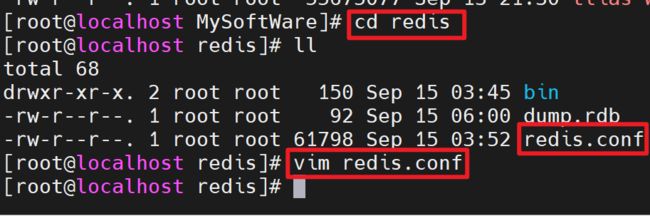
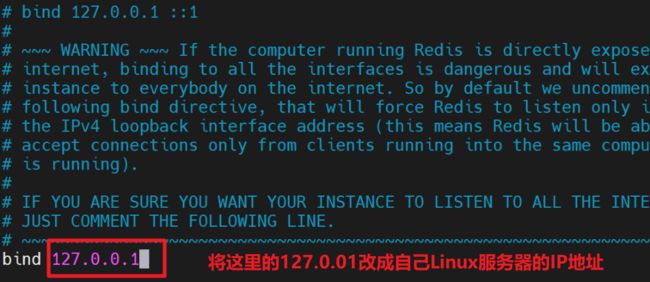
2. 进入自己的redis安装目录,vim进入redis.conf修改redis.conf文件中的bind参数
接着重新启动Redis:

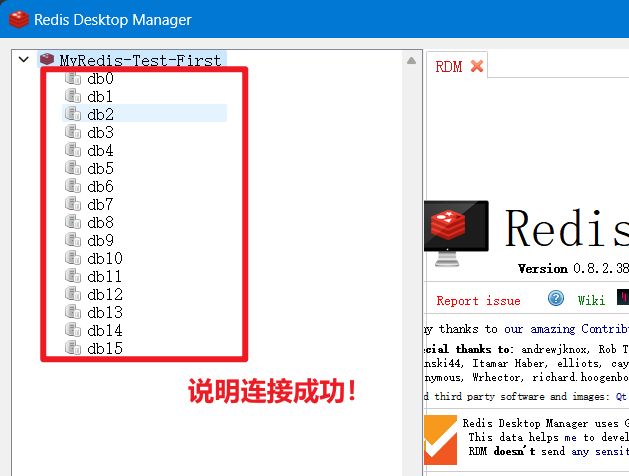
连接Redis:
4.Redis数据结构
Redis是一种基于内存的数据库,并且提供一定的持久化功能,它是一种键值(key-value)数据库,使用 key 作为索引找到当前缓存的数据,并且返回给程序调用者。
当前的 Redis 支持 6 种数据类型,它们分别是字符串(String)、列表(List)、集合(set)、哈希结构(hash)、有序集合(zset)和基数(HyperLogLog)
重点掌握前五种数据结构!!!

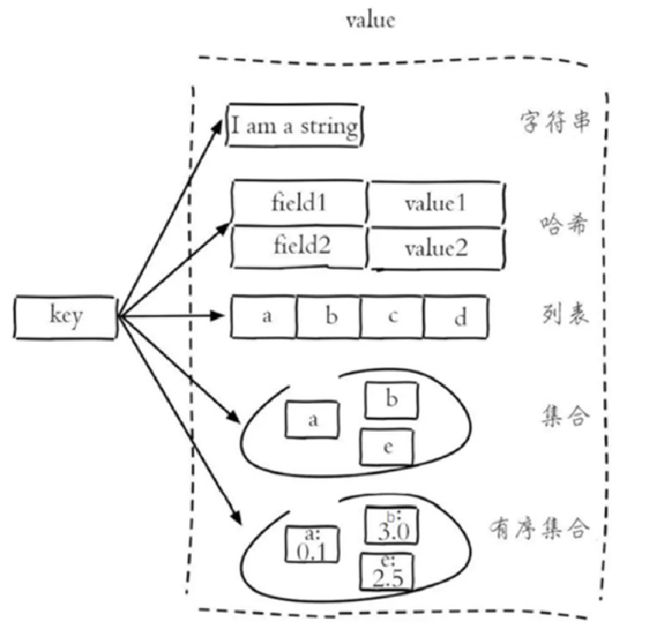
解释说明:
- 字符串(string):普通字符串,Redis中最简单的数据类型
- 哈希(hash):也叫散列,类似于Java中的HashMap结构
- 列表(list):按照插入顺序排序(有序),可以有重复元素,类似于Java中的LinkedList
- 集合(set):无序集合,没有重复元素,类似于Java中的HashSet
- 有序集合(sorted set/zset):集合中每个元素关联一个分数(score),根据分数升序排序,没有重复元素
5.Redis常用指令
命令学习网站:Redis 命令参考 — Redis 命令参考
5.1 String类型
赋值语法:SET key value

取值语法: GET key

设置多个键值语法: MSET key value [key value …]
![]()
获取多个键值语法: MGET key [key …]

删除语法:DEL key 【key...】

5.2 字符串数字的递增与递减
递增数字:
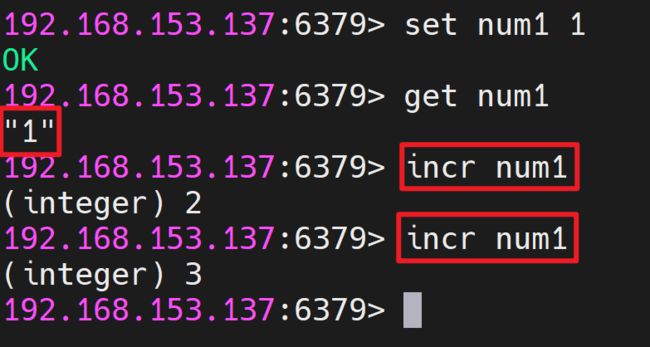
- 当存储的字符串是整数时,Redis提供了一个实用的命令INCR,其作用是让当前键值递增,并返回递增后的值。
- 递增数字语法: INCR key
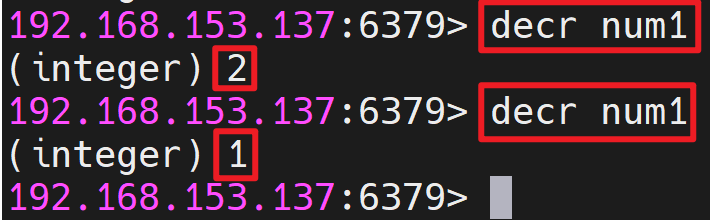
- 递减数值语法: DECR key
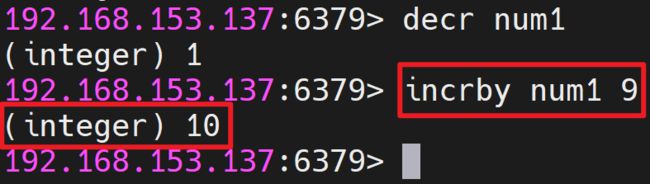
- 增加指定的整数语法: INCRBY key increment
- 减少指定的整数 语法:DECRBY key decrement

5.3 Hash散列(了解)
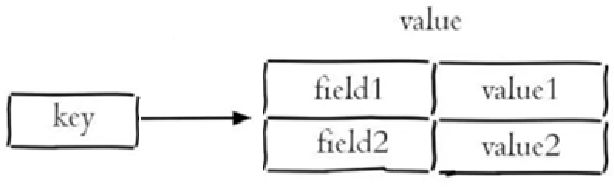
Redis hash 是一个String类型的 field 和 value 的映射表,hash特别适合用于存储对象,常用命令:
- hash叫散列类型,它提供了字段和字段值的映射。
- 字段值只能是字符串类型,不支持散列类型、集合类型等其它类型。相当于是对象格式的存储
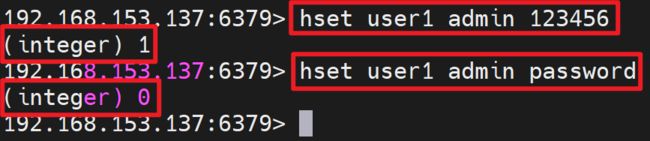
赋值语法: HSET key/大key/一级key field-属性-小key/二级key value-属性值
- 设置一个字段值, HSET命令不区分插入和更新操作,当执行插入操作时HSET命令返回1,当执行更新操作时返回0。
取值语法: HGET key field-属性值

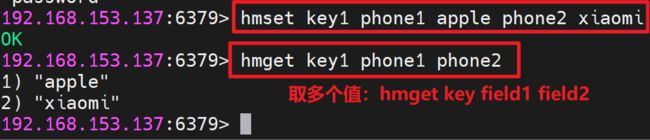
设置多个字段语法: HMSET key field value [field value ...]

取多个值语法: HMGET key field [field ...]
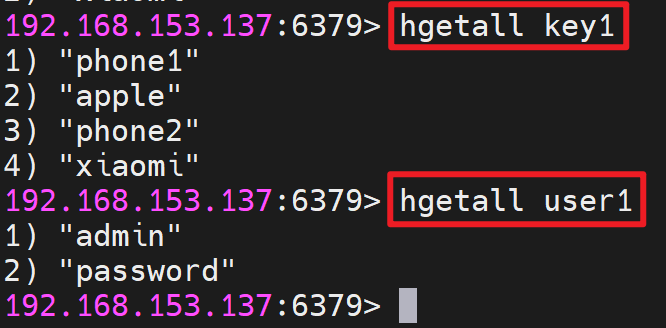
获取所有字段值语法:HGETALL key
删除字段语法:HDEL key field [field ...]
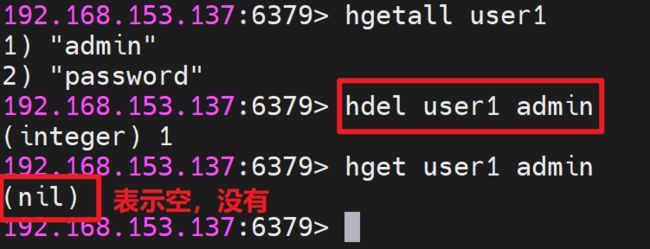
5.4 列表List
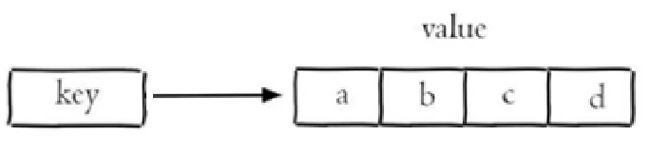
Redis的List是采用来链表来存储,双向链表存储数据,特点:增删快、查询慢(Linkedlist).这个队列是有序的。
Redis 列表是简单的字符串列表,按照插入顺序排序,常用命令:
| 命令 | 含义 |
|---|---|
| lpush key value1 [value2] | 将一个或多个值插入到列表头部 |
| rpush key value1 [value2] | 将一个或多个值插入到列表尾部 |
| lrange key start stop | 获取列表指定范围内的元素 |
| lpop key | 移出并获取列表的第一个元素 |
| rpop key | 移除并获取列表最后一个元素 |
| BRPOP key1 [key2 ] timeout | 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止 |
| llen key | 获取列表长度 |
| rpoplpush source dest | 移除列表的最后一个元素,并将该元素添加到另一个列表并返回 |
| brpoplpush source dest timeout | 从列表中弹出一个值,将弹出的元素插入到另外一个列表中并返回它; 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。 |
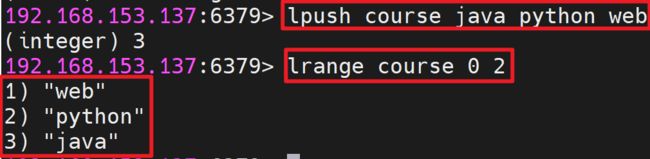
向列表左边增加元素: LPUSH key value [value ...]

从列表左边弹出元素: LPOP key(临时存储,弹出后,从队列中清除)
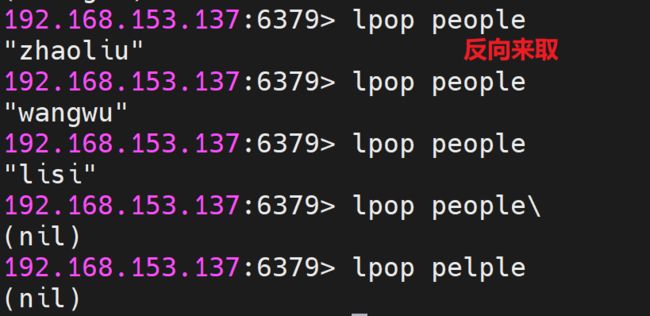
向列表右边增加元素 : RPUSH key value [value ...]

从列表右边弹出元素: RPOP key
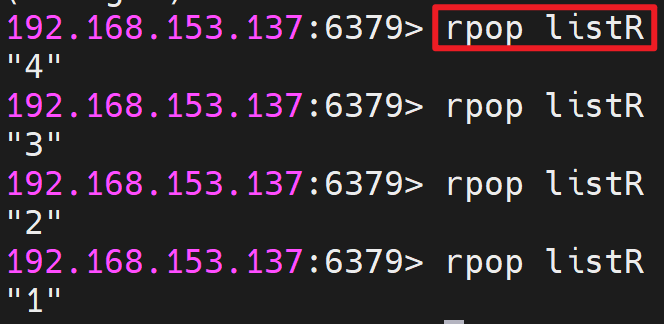
获取列表中元素的个数: LLEN key
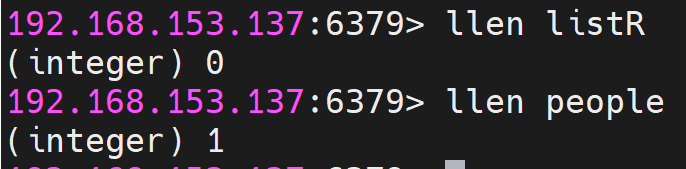
获取列表指定范围内的元素:LRANGE key start stop
-
将返回start、stop之间的所有元素(包含两端的元素),索引从0开始,可以是负数,如:“-1”代表最后的一个元素。

5.4 Set集合操作命令
Redis set 是string类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据,常用命令:
| 命令 | 含义 |
|---|---|
| SADD key member1 [member2] | 向集合添加一个或多个成员 |
| SMEMBERS key | 返回集合中的所有成员 |
| SCARD key | 获取集合的成员数 |
| SINTER key1 [key2] | 返回给定所有集合的交集 |
| SUNION key1 [key2] | 返回所有给定集合的并集 |
| sdiff key1 [key2] | 返回所有给定集合的差集 |
| SREM key member1 [member2] | 移除集合中一个或多个成员 |
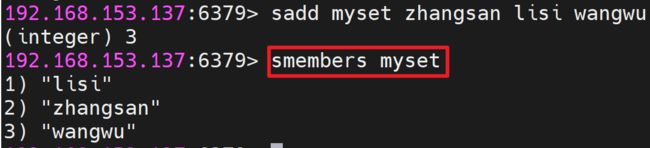
添加元素语法:SADD key member1 [member2 ...]

获取集合中的所有元素 : smembers key
删除元素语法: SREM key member1 [member2 ...]

判断元素是否在集合中: SISMEMBER key member 返回1表示存在,反之0表示不存在

5.5 Zset有序集合操作命令
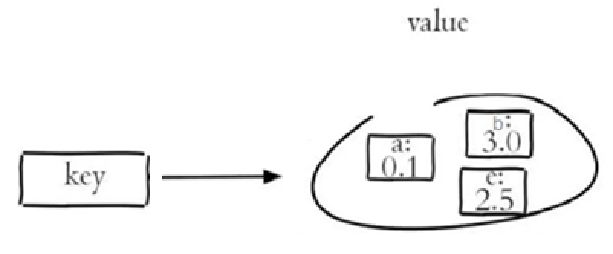
- SortedSet又叫Zset,是有序集合,可排序的,但是唯一。 SortedSet和Set的不同之处,是会给Set中的元素添加一个分数,然后通过这个分数进行排序。
Redis Zset有序集合是String类型元素的集合,且不允许有重复成员。每个元素都会关联一个double类型的分数。常用命令: withscores选项代表得到对应的分数!
| 命令 | 含义 |
|---|---|
| zadd key score1 member1 [score2 member2] | 向有序集合添加一个或多个成员 |
| zrange key start stop [withscores] | 通过索引区间返回有序集合中指定区间内的成员(分数从小到大,升序排序) |
| zrevrange key start stop [withscores] | 通过索引区间返回有序集合中指定区间内的成员(分数从大到小,降序排序) |
| zincrby key increment member | 有序集合中对指定成员的分数加上增量 increment |
| zrem key member [member ...] | 移除有序集合中的一个或多个成员 |
| zcard key | 计算集合中元素的数量 |
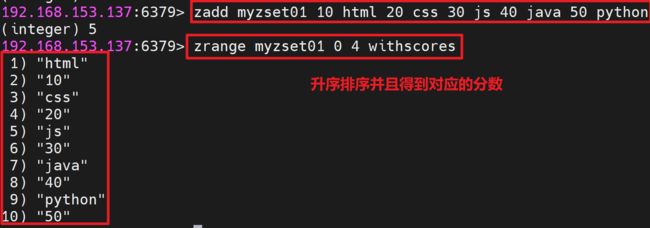
增加元素:ZADD key score1 member1 [score2 member2 ...]
- 向有序集合中加入一个元素和该元素的分数(score),如果该元素已经存在则会用新的分数替换原有的分数。
![]()
获得排名在某个范围的元素列表,并按照元素分数降序返回:

获取元素的分数:ZSCORE key member

删除元素ZREM key member [member ...]

升序排序,获得元素的分数的可以在命令尾部加上WITHSCORES参数
应用:商品销售量;学生排名等
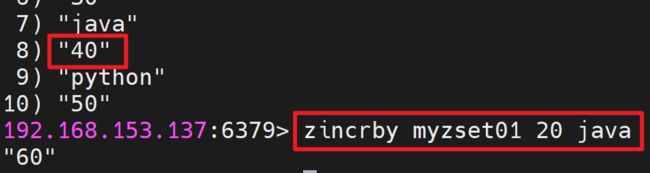
对指定成员的分数加上增量Increment:zincrby key increment member
5.6 HyoperLogLog命令
HyperLogLog是一种使用随机化的算法,以少量内存提供集合中唯一元素数量的近似值。
HyperLogLog可以接受多个元素作为输入,并给出输入元素的基数估算值:
-
基数:集合中不同元素的数量。比如 {‘apple’, ‘banana’, ‘cherry’, ‘banana’, ‘apple’} 的基数就是 3 。
-
估算值:算法给出的基数并不是精确的,可能会比实际稍微多一些或者稍微少一些,但会控制在合理的范围之内。