深入理解指针与参数传递
我们都知道在C语言Swap函数要这么写
void Swap(int* a, int* b) {
int temp = *a;
*a = *b;
*b = temp;
}
Swap能交换两个变量的值,因为传入的是两个变量的指针(地址),交换这两个指针所指向的值,如果参数是int的话,传入是副本,则不能更改。那么我们稍微改一下
void Swap(int* a, int* b) {
int* temp = a;
a = b;
b = temp;
}
int main() {
int a = 10, b = 5;
cout << &a << ' ' << a << endl;
cout << &b << ' ' << b << endl;
Swap(&a, &b);
cout << &a << ' ' << a << endl;
cout << &b << ' ' << b << endl;
return 0;
}
//0055FC9C 10
//0055FC90 5
//0055FC9C 10
//0055FC90 5
Swap函数里面的a和b前面的都没加*,所以也就是试图在Swap函数内部交换a和b的这两个指针变量的值(不是它们所指向的值),传入的参数是a,b的地址,但传入的这个地址也是个副本,所以自然是不能交换的。
“一切传引用其实本质上是传值”,这句话很有争议,但我认为是没有错的,搞清楚形参现在是作为地址还是作为值进行运算,作为值时,就不会对函数外造成影响,作为地址时,就可以对函数外造成影响,如下:
#include 再比如:
#include 总结有几点
-
函数传入的永远是副本,只不过当传入的是指针(地址)时,可以直接修改地址所指向的变量。
-
指针也是一种变量,它的值是个地址,需要存放在物理内存中,自然就有自己的地址,如下:
#include 
所以就可以有这样的写法,来直接“交换”两个数组
void Swap(int** a, int** b) {
int* temp = *a;
*a = *b;
*b = temp;
}
int main() {
int* a = new int[10];
int* b = new int[10];
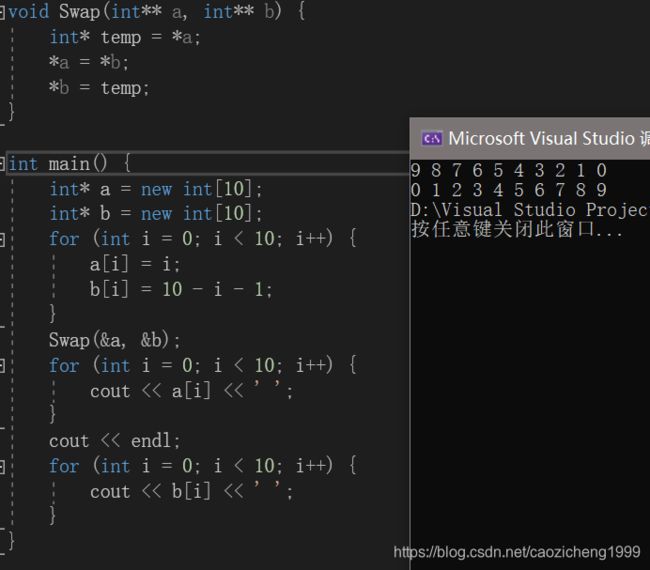
cout << &a << ' ' << a << endl;
cout << &b << ' ' << b << endl;
Swap(&a, &b);
cout << &a << ' ' << a << endl;
cout << &b << ' ' << b << endl;
}
具体应用,比如,一般初始化链表我习惯这样写:
#include 也可以这样写
#include 其它的,在树中,某些情况用起来会更方便一点,当然不用也完全能够实现想要的功能,比如二叉搜索树的结点删除:
//删除结点左子树的最大值结点
BSTree DelMax(BSTree root) {
if (root->Right == NULL) {
BSTNode *t= root->Left;
delete root;
return t;
}
root->Right = DelMax(root->Right);
return root;
}
BSTree BSTDel(BSTree root,int x) {
if (root == NULL)
return NULL;
if (root->data == x) {
//情况1和2,被删除的结点只有左子树或右子树,或没有子树
if (! root->Right || !root->Left) {
BSTNode *t = !root->Right ? root->Left : root->Right;
delete root;
return t;
}
//删除既有左子树,也有右子树的结点
else{
root->data = GetMax(root->Left);
root->Left = DelMax(root->Left);
}
}
else if (x > root->data)
root->Right = BSTDel(root->Right, x);
else
root->Left = BSTDel(root->Left, x);
return root;
}
//删除子树中的最大值
void DelMax(BSTree &root,int &value) {
if (!root)return;
if (root->Right == NULL) {
BSTNode *t= root;
value = root->data;
root = root->Left;
delete t;
}
else
DelMax(root->Right, value);
}
void BSTDel(BSTree &root,int x) {
if (root == NULL)
return;
BSTree p = root;
if (p->data == x) {
if (! p->Right || !p->Left) {
root = !p->Right ? p->Left : p->Right;
delete p;
}
else
DelMax(root->Left, root->data);
}
else if (x > p->data) BSTDel(p->Right, x);
else BSTDel(p->Left, x);
}
区别不大,只是能让代码稍微短一点,具体用哪种,我觉得还是个人习惯吧,只要理解了指针,两种写法实现起来都是险象环生,一样要考虑很多问题,只是角度不同。
Java
探究了C/C++的参数传递后,也去了解了JAVA的参数传递。首先先明确一个差异
- C/C++ 的参数传递(赋值)默认就是值传递,基础数据类似就是直接复制一个值,类就是调用拷贝构造函数来创建一个新对象(这也是为什么当返回值是对象时最好加上一个&,避免调用拷贝构造函数),除非用指针或引用,
- 在JAVA的参数传递(赋值),基础数据类型和引用数据类型是区别对待的。
除了这个,二者基本上没什么区别。
基础数据类型与引用数据类型
基础数据类型/引用数据类型和值传递/引用传递没有绝对的关系
基本数据类型是CPU可以直接进行运算的类型,如下几种:
- 整数类型:
byte,short,int,long - 浮点数类型:
float,double - 字符类型:
char - 布尔类型:
boolean
除了上述基本类型的变量,剩下的都是引用类型。
此外,像 String 和 Integer 等包装类是 immutable 类型,不可变,每次改变它们的值都会指向新值的内存地址,所以无法用方法改变Integer的值,可以看做是值传递
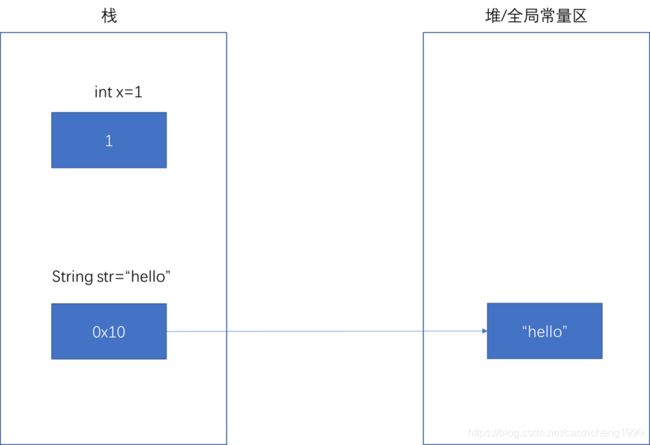
对于基础数据类型,变量中存储的就是值,值存储于栈中
对于引用类型,变量中存储着值的地址,地址存储在栈中,值存储在堆/全局常量区中
int x = 1;
String str = "hello"
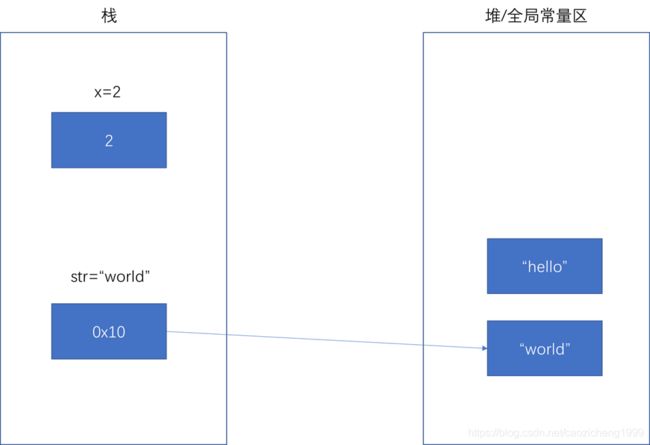
分别对它们做修改操作,基础数据类型值会改变,引用类型的值“不变”,只是改变了指向,这也是为什么说“引用类型不可变”
x = 2;
str = "world"
值传递与引用传递
大家普遍对于值传递和引用传递的定义就是,值传递即传入方法内部的是实参值的拷贝,引用传递传入方法内部的是实参地址。这句话不完全对,引用传递传进去的确实是地址,但是地址本身就是值,它可以作为地址,也可以作为值,比方说在C语言中:
#include 在java中类似的:
class A {
public int num;
public A(int num) {
this.num = num;
}
public void setNum(int num) {
this.num = num;
}
}
public class Main {
private static void modify(A a1, A a2) {
/*这里a1作为地址,会对函数外部造成影响*/
a1.setNum(3);
/*这里把a2当作值进行赋值操作,不会对函数外部造成影响*/
a2 = new A(3);
a2 = a1;
}
public static void main(String[] args) {
A a1 = new A(0);
A a2 = new A(1);
modify(a1, a2);
System.out.println(a1.num + " " + a2.num);
}
}
//3 1
不管是JAVA还是C++,不管传入的参数是什么,一切传引用(指针或是引用类型)其实本质上是传值,是否会对函数外部造成影响,在于它作为值还是地址进行操作。
在 C/C++ 中不加 & 或者 * 就是复制一份,这也是为什么想要在数组中操作传入的 string 或者 vector 必须要用 & ,JAVA 将 C/C++ 的指针做了封装,实现了这种“引用传递”。