Shell脚本编程教程
1.Shell脚本语言的基本结构
1.1 Shell脚本的用途:
- 自动化常用命令
- 执行系统管理和故障排除
- 创建简单的应用程序
- 处理文本或文件
1.2 Shell脚本基本结构:
Shell脚本编程:是基于过程式,解释执行的语言
编程语言的基本结构:
- 各种系统命令的组合:
- 数据存储:变量,数组
- 表达式:a+b
- 控制语句:if
shell脚本:包含一些命令或声明,并符合一定格式的文本文件
格式要求:首行执行shebang机制
#声明后续语句是通过那种语言写的
#!/bin/bash
#!/usr/bin/python
#!/usr/bin/perl
1.3 创建Shell脚本过程
-
使用vim创建文本文件,第一行必须包括shell声明序列:
#!/bin/bash -
加执行权限,给予执行权限,在命令行上指定脚本的绝对或相对路径
[root@localhost ~]# chmod +x shell/hello.sh -
运行脚本,直接运行解释器,将脚本作为解释器程序的参数运行。
[root@localhost ~]# shell/hello.sh
1.4 脚本注释规范
- 第一行一般为调用使用的语言
- 程序名,避免更改文件名为无法找到正确的文件
- 版本号
- 更改后的时间
- 作者相关信息
- 该程序的作用,及注意事项
- 最后是各版本的更新简要说明
1.5 第一个脚本
[root@localhost ~]# cat shell/hostname.sh
#!/bin/bash
echo "My hostname is `hostname`"
echo "Time is `date +'%F %T'`"
[root@localhost ~]# chmod +x shell/hostname.sh
[root@localhost ~]# shell/hostname.sh
1.6 执行远程脚本
#服务器:192.168.80.150
[root@client2 ~]# cd /var/www/html/
[root@client2 html]# ls
index.html
[root@client2 html]# vim hello.sh
[root@client2 html]# chmod +x hello.sh
[root@client2 html]# ls
hello.sh index.html
[root@client2 html]# ./hello.sh
Hello Linux
[root@client2 html]#
#客户端:192.168.80.134
[root@localhost ~]# curl http://192.168.80.150/hello.sh
#!/bin/bash
echo "Hello Linux"
[root@localhost ~]# wget -qO - 192.168.80.150/hello.sh | bash
Hello Linux
[root@localhost ~]#
课后实例:备份脚本
[root@localhost ~]# mkdir /backup/
[root@localhost ~]# vim shell/backup.sh
[root@localhost ~]# cat shell/backup.sh
#!/bin/bash
echo -e "\033[1;32mStarting backup..\033[0m"
sleep 2
cp -av /etc/ /backup/etc`date +%F`/
echo -e "\033[1;32mBackup is finished\033[0m"
[root@localhost ~]# chmod +x shell/backup.sh
[root@localhost ~]# ./shell/backup.sh
Starting backup..
……
Backup is finished
1.7 脚本错误
- 语法错误,会导致后续的命令不继续执行,可以用bash -n shellname检查错误
- 命令错误,后续的命令还会继续,可以使用bash -x shellname检查
- 逻辑错误,只能使用bash -x进行观察
1.8 Shell字符串详解
字符串(String)就是一系列字符的组合。字符串是Shell编程中最常用的数据类型之一
字符串可以由单引号''包围,也可以由""包围,也可以不用引号,三种方式的区别
- 由单引号
' '包围的字符串- 任何字符都会原样输出,在其中使用变量是无效的
- 字符串中不能出现单引号,即使对单引号进行转义也不行
- 由双引号
" "包围的字符串- 如果其中包含了某个变量,那么该变量就会被解析(得到该变量的值),而不是原样输出
- 字符串中可以出现双引号,只要进行转义就行
- 不被引号包围的字符串
- 不被引号包围的字符串中出现变量也会被解析,这一点和双引号
""包围的字符串一样 - 字符串中不能出现空格,否则空格后面的字符串会作为其他变量或者命令解析
- 不被引号包围的字符串中出现变量也会被解析,这一点和双引号
通过代码演示一下三种形式的区别
#!/bin/bash
n=74
str1=c.biancheng.net$n
str2="shell \"Script\" $n"
str3='C语言中文网 $n'
echo $str1
echo $str2
echo $str3
# 运行结果
c.biancheng.net74
shell "Script" 74
C语言中文网 $n
str1 中包含了$n,它被解析为变量 n 的引用。$n后边有空格,紧随空格的是 str2;Shell 将 str2 解释为一个新的变量名,而不是作为字符串 str1 的一部分
str2 中包含了引号,但是被转义了(由反斜杠\开头的表示转义字符)。str2 中也包含了$n,它也被解析为变量 n 的引用
str3 中也包含了$n,但是仅仅是作为普通字符,并没有解析为变量 n 的引用
获取字符串长度
在Shell中获取字符串长度很简单,具体方法如下:
${#string_name}
`string_name:表示字符串名字
1.9 Shell字符串拼接
在脚本语言中,字符串的拼接(也称为字符串连接或者字符串合并)往往都非常简单,例如:
- 在
PHP中使用.即可连接两个字符串 - 在
JavaScript中使用+即可将两个字符串合并为一个
然而,在Shell中你不需要使用任何运算符,将两个字符串并排放在一起就能实现拼接
#!/bin/bash
name="shell"
url="http://c.biancheng.net/shell/"
str1=$name$url #中间不能有空格
str1=$name":"$url
str2="$name $url" #如果被双引号包围,那么中间可以有空格,也可以出现别的字符串
str3="$name:$url"
str4="${name}Script:${url}Index.html" #在变量后加上字符串,需要给变量名加上大括号
1.10 Shell字符串截取
Shell截取字符串通常有两种方式,从指定位置开始截取和从指定字符(子字符串)开始截取
从指定位置开始截取
这种方式需要两个参数:除了指定起始位置,还需要截取长度,才能最终确定要截取的字符串
既然需要指定起始位置,那么就要涉及到计数方向的问题,到底是从字符串左边开始计数,还是从字符串右边开始计数?答案是:Shell同时支持两种计数方式
1.从字符串左边开始计数
如果想从字符串的左边开始计数,那么截取字符串的具体格式如下:
${string:start:length}
`其中,Sting是要截取的字符串,start是起始位置(从左边开始,从0开始计数),length是要截取的长度(省略的话表示直到字符串的末尾)
例如:
url="c.biancheng.net"
echo ${url:2:9}
>结果为:biancheng
url="c.biancheng.net"
echo ${url:2} #省略length,截取到字符串末尾
>结果为:biancheng.net
2.从右边开始计数
如果想从字符串的右边开始计数,那么截取字符串的具体格式如下:
${string:0-start:length}
`同第 1) 种格式相比,第 2) 种格式仅仅多了0-,这是固定的写法,专门用来表示从字符串右边开始计数。
这里需要强调两点:
从左边开始计数时,起始数字是 0(这符合程序员思维);
从右边开始计数时,起始数字是 1(这符合常人思维)
计数方向不同,起始数字也不同。
不管从哪边开始计数,截取方向都是从左到右。
例如:
url="c.biancheng.net"
echo ${url:0-13:9}
>结果为:biancheng 从右边数:b是第13个字符
url="c.biancheng.net"
echo ${url:0-13} #省略length,直接截取到字符串末尾
>结果为:biancheng.net
从指定字符(子字符串)开始截取
这种截取方式无法指定字符串长度,只能从指定字符(子字符串)截取到字符串末尾。Shell可以截取指定字符(子字符串)右边的所有字符,也可以截取左边的所有字符
1)使用#号截取右边字符
使用#号可以截取指定字符(或子字符串)右边的所有字符,具体格式如下:
${string#*chars}
`其中,string 表示要截取的字符,chars 是指定的字符(或者子字符串),*是通配符的一种,表示任意长度的字符串。*chars连起来使用的意思是:忽略左边的所有字符,直到遇见 chars(chars 不会被截取)
例如:
url="http://c.biancheng.net/index.html"
echo ${url#*:}
>结果为://c.biancheng.net/index.html
echo ${url#*p:}
echo ${url#*ttp:}
`如果不需要忽略chars左边的字符,那么也可以不写*
url="http://c.biancheng.net/index.html"
echo ${url#http://}
>结果为:c.biancheng.net/index.html
`注意:以上写法遇到第一个匹配的字符(子字符串)就结束了
url="http://c.biancheng.net/index.html"
echo ${url#*/}
>结果为:/c.biancheng.net/index.html。url 字符串中有三个/,输出结果表明,Shell 遇到第一个/就匹配结束了
使用##可以直到最后一个指定字符(子字符串)再匹配结束
${string##*chars}
例如:
#!/bin/bash
url="http://c.biancheng.net/index.html"
echo ${url#*/}
# 结果为:/c.biancheng.net/index.html
echo ${url##*/}
# 结果为:index.html
str="-----aa+++aa@@@"
echo ${str#*aa}
# 结果为:+++aa@@@
echo ${str##*aa}
# 结果为:@@@
2)使用%截取左边字符
使用%号可以截取指定字符(或者子字符串)左边的所有字符
${string%chars*}
`请注意*的位置,因为要截取 chars 左边的字符,而忽略 chars 右边的字符,所以*应该位于 chars 的右侧。其他方面%和#的用法相同
#!/bin/bash
url="http://c.biancheng.net/index.html"
echo ${url%/*} #结果为 http://c.biancheng.net
echo ${url%%/*} #结果为 http:
str="---aa+++aa@@@"
echo ${str%aa*} #结果为 ---aa+++
echo ${str%%aa*} #结果为 ---
汇总

2.Shell脚本语言的变量用法详解
2.1 变量
变量表示命名的内存空间,将数据放在内存空间中,通过变量名引用,获取数据
2.2 变量类型
变量类型:
- 内置变量:如PS1,PATH,UID,HOSTNAME,HISTSIZE
- 用户自定义变量
不同的变量存放的数据不同,决定了以下:
- 数据存储方式
- 参与的计算
- 表示的数据范围
变量数据类型:
- 字符
- 数值:整形,浮点型、bash不支持浮点数
2.3编程语言分类
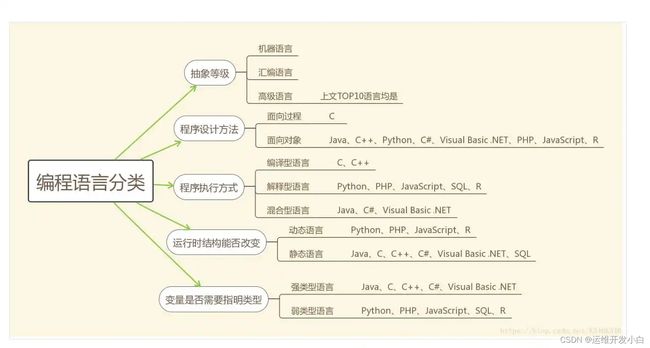
静态和动态语言:
- 静态编译语言:使用变量前,先声明变量类型,之后类型不能改变,在编译时检查,如Java语言
- 动态编译语言:不事先声明,可随时改变类型,如Shell语言
强类型和弱类型语言:
- 强类型语言:不同类型数据操作,必须经过强制转换成同一类型才能运算,如java,C#
- 弱类型语言:语言的运行时会隐式地做数据类型转换。无需指定类型,默认均为字符型;参与计算会自动进行隐式类型转换;变量无需事先定义可直接调用。如Shell语言,php,JavaScript
2.4 Shell中变量命名法则
- 不能使用程序中的保留字,如:if,for
- 只能使用数字,字母及下划线,且不能以数字开头
- 见名思意,用英文名字,并体现真正含义
- 统一命名规则:驼峰命名法
- 变量名大写
- 局部变量小写
- 函数名小写
2.5 变量定义和引用
变量的生效范围
- 普通变量:生效范围为当前shell进程;对当前shell之外的其他shell进程,包括当前shell的子shell进程均无效
- 环境变量:生效范围为当前shell进程及其子进程
- 本地变量:生效范围为当前shell进程中某代码片段,通常指函数
变量赋值:
name="value"
value可以是以下多种类型
直接字符串:name='root'
变量引用:name="$USER"
命令应用:name=`command` || name=$(command)
通配符:FILE=/etc/* /*表示etc目录下所有的文件名*/
注意:变量赋值是临时生效,当退出终端后,变量会自动删除,无法持久保存。
变量引用:
$name
${name}
弱引用和强引用:
- “$name”:弱引用,其中的变量引用会被替换成为变量值
- ‘$name’:强引用,其中的变量引用不会被替换成变量值,而保持原字符串
实例:
[root@localhost ~]# name='Mike'
[root@localhost ~]# NAME="$USER"
[root@localhost ~]# hostname=`hostname`
[root@localhost ~]# echo "My name is $name"
My name is Mike
[root@localhost ~]# echo "My name is $NAME"
My name is root
[root@localhost ~]# echo "My hostname is $hostname"
My hostname is localhost.localdomain
[root@localhost ~]#
[root@localhost ~]# NUM=`seq 10`
[root@localhost ~]# echo $NUM
1 2 3 4 5 6 7 8 9 10
[root@localhost ~]# echo "$NUM"
1
2
3
4
5
6
7
8
9
10
[root@localhost ~]#
查看已定义的所有变量:
[root@localhost ~]#set
删除变量
[root@localhost ~]#unset shellname1 shellname2
//实例:
[root@localhost ~]# echo $name
Mike
[root@localhost ~]# unset name
[root@localhost ~]# echo $name
[root@localhost ~]#
实例:"{}"的使用
[root@localhost ~]# NAME=mage
[root@localhost ~]# AGE=20
[root@localhost ~]# echo $NAME
mage
[root@localhost ~]# echo $AGE
20
[root@localhost ~]# echo $NAME $AGE
mage 20
[root@localhost ~]# echo $NAME_$AGE
20
[root@localhost ~]# echo ${NAME}_$AGE
mage_20
[root@localhost ~]#
显示系统信息
[root@localhost ~]# vim shell/OS.sh
#!/bin/bash
RED="\E[1;31m"
GREEB="\E[1;32m"
END="\E[0m"
echo -e "\E[1;32m----------Host systeminfo----------$END"
echo -e "HOSTNAME: $RED `hostname`$END"
echo -e "IPADDR: $RED `ifconfig ens160 | grep -Eo '([0-9]{1,3}\.){3}[0-9]{1,3}' | head -n1` $END"
echo -e "OSVERSION: $RED `cat /etc/redhat-release`$END"
echo -e "KERNEL: $RED `uname -r`$END"
echo -e "CPU: $RED `lscpu | grep "型号名称:" | tr -s ' ' ' '|cut -d ' ' -f 2-5` $END"
echo -e "MEMORY: $RED `free -h | grep Mem | tr -s ' ' ' '|cut -d ' ' -f 4` $END"
echo -e "DISK: $RED `lsblk | grep '^nv' | tr -s ' ' | cut -d ' ' -f 4` $END"
echo -e "\E[1;32m---------- END ----------$END"
[root@localhost ~]# chmod +x shell/OS.sh
[root@localhost ~]# shell/OS.sh
----------Host systeminfo----------
HOSTNAME: localhost.localdomain
IPADDR: 192.168.80.134
OSVERSION: Red Hat Enterprise Linux release 8.0 (Ootpa)
KERNEL: 4.18.0-80.el8.x86_64
CPU: AMD Ryzen 5 4600U
MEMORY: 1.1Gi
DISK: 20G
---------- END ----------
[root@localhost ~]#
利用变量实现动态命令
[root@localhost ~]# CMD=hostname
[root@localhost ~]# $CMD
localhost.localdomain
[root@localhost ~]#
2.6 环境变量
环境变量:
- 可以使子进程(包括孙子进程)继承父进程的变量,但是无法让父进程使用子进程的变量。
- 一旦子进程修改了从父进程继承的变量,将会传递新的值给孙子进程
- 一般只在配置文件中使用,在脚本中较少使用
课程引入:普通变量生效的范围与环境变量生效的范围
[root@localhost ~]# vim shell/father.sh
#!/bin/bash
NAME=father
echo "father.sh:NAME=$NAME"
echo "fatther is PID=$BASHPID"
shell/son.sh
[root@localhost ~]#vim shell/son.sh
#!/bin/bash
echo "son.sh:NAME=$NAME"
NAME=son
echo "son.sh:NAME=$NAME"
echo "son.sh PID is $BASHPID"
echo "son.sh father pid is $PPID"
sleep 100
[root@localhost ~]#chmod -R +x shell/*
[root@localhost ~]# ./shell/father.sh
father.sh:NAME=father
fatther is PID=12053
son.sh:NAME=
son.sh:NAME=son
son.sh PID is 12054
son.sh father pid is 12053
#子进程无法使用父进程的变量,需要自己赋值
变量声明和赋值:
export name=VALUE
declare -x name =VALUE
或者先赋值再声明~
value可以是以下多种类型
直接字符串:name='root'
变量引用:name="$USER"
命令应用:name=`command` || name=$(command)
通配符:FILE=/etc/* /*表示etc目录下所有的文件名*/
declare命令详解:
declare 为 shell 指令,在第一种语法中可用来声明变量并设置变量的属性([rix]即为变量的属性),在第二种语法中可用来显示 shell 函数。若不加上任何参数,则会显示全部的 shell 变量与函数(与执行 set 指令的效果相同)
语法
declare [+/-][rxi][变量名称=设置值] 或 declare -f
参数说明:
- +/- "-“可用来指定变量的属性,”+"则是取消变量所设的属性。
- -f 仅显示函数
- r 将变量声明为只读变量。注意,一旦设置为只读变量,既不能修改变量的值也不能删除变量,甚至不能通过+r取消只 读属性
- x 指定的变量会成为环境变量,可供shell以外的程序来使用
- i 将变量声明为整数型(integer)
- p 显示指定变量的被声明类型。
实例
1.声明整数型变量
#!/bin/bash
declare -i ab //声明整数型变量
ab=56 //改变变量内容
echo $ab //显示变量内容
--->
56
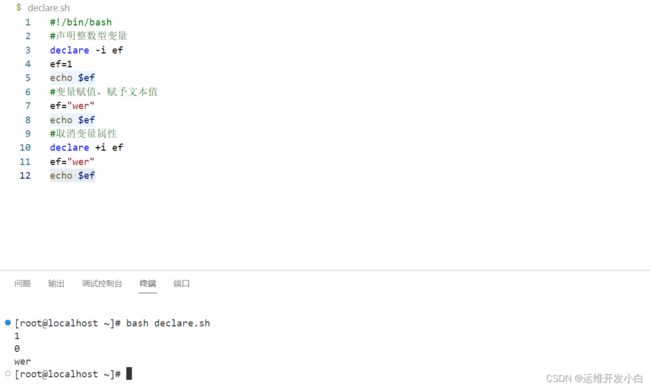
2.改变变量属性
#!/bin/bash
#声明整数型变量
declare -i ef
ef=1
echo $ef
#变量赋值,赋予文本值
ef="wer"
echo $ef
#取消变量属性
declare +i ef
ef="wer"
echo $ef
3.设置变量只读
#!/bin/bash
declare -r ab #设置变量为只读
ab=88 #改变变量内容
echo $ab #显示变量内容
--->
declare.sh:行3: ab: 只读变量
4.声明数组变量
#!/bin/bash
#声明数组变量
declare -a cd
cd[0]=a
cd[1]=b
cd[2]=c
#输出数组的指定内容
echo ${cd[1]}
#显示整个数组变量内容
echo ${cd[@]}
![]()
5.显示函数
#!/bin/bash
#声明函数
declare -f
function command_not_found_handle(){
if [ -x /usr/lib/command_not_found_handle ];then
/usr/bin/python /usr/lib/command_not_found_handle -- $1;
return $?;
else
if [ -x /usr/share/command_not_found_handle ];then
/usr/bin/python /usr/share/command_not_found_handle --$1;
return $?;
else
return 127;
fi;
fi;
}
变量引用:
$name
${name}
完善课程导入:
[root@localhost ~]# vim shell/father.sh
#!/bin/bash
NAME=father
export NAME
echo "father.sh:NAME=$NAME"
echo "fatther is PID=$BASHPID"
shell/son.sh
[root@localhost ~]#vim shell/son.sh
#!/bin/bash
echo "son.sh:NAME=$NAME"
NAME=son
echo "son.sh:NAME=$NAME"
echo "son.sh PID is $BASHPID"
echo "son.sh father pid is $PPID"
sleep 100
[root@localhost ~]#chmod -R +x shell/*
[root@localhost ~]# ./shell/father.sh
father.sh:NAME=father
fatther is PID=12053
son.sh:NAME=father
son.sh:NAME=son
son.sh PID is 12054
son.sh father pid is 12053
[root@localhost ~]# ./shell/father.sh
father.sh:NAME=father
fatther is PID=12142
son.sh:NAME=father
son.sh:NAME=son
son.sh PID is 12143
son.sh father pid is 12142
#父进程定义了一个环境变量,在子进程上可以进行调用
#父进程无法使用子进程的变量
#子进程自己定义了一个同名变量,就覆盖环境变量
显示所有环境变量:
[root@localhost ~]# env
[root@localhost ~]# printenv
[root@localhost ~]# export
[root@localhost ~]# declare -x
删除变量
[root@localhost ~]#unset shellname1 shellname2
Bash内建的环境变量
PATH
SHELL
USER
UID
PWD
SHLVL #shell的嵌套层数,即深度
LANG
MAIL
HOSTNAME
HISTSIZE
_ #下划线,表示前一命令的最后一个参数
2.7 只读变量
只读变量:只能声明定义,但后续不能修改和删除
声明只读变量:
readonly name
declare -r name
查看只读变量:
readonly [-p]
declare -r
2.8 位置变量
位置变量:在Bash Shell中内置的变量,在脚本代码中调用命令行传递给脚本的参数
$1,$2,... 对应第一个,第二个等参数,shift[n]换位置
$0 命令本身,包括路径
$* 传递给脚本的所有参数,全部参数合成一个字符串
$@ 传递给脚本的所有参数,每个参数为独立字符串
$# 传递给脚本的参数的个数
$? 上个命令的退出状态,或函数的返回值
$$ 当前shell进程ID。对于Shell脚本,就是这些脚本所在的进程ID
注意:$@,$*只有被双引号括起来的时候才会有差异
清空所有位置变量
set --
//写在脚本内部
实例演示1:
[root@localhost ~]# vim shell/ARG.sh
#!/bin/bash
echo "1st arg is $1"
echo "2st arg is $2"
echo "3st arg is $3"
echo "4st arg is $4"
echo "The number of are is $#"
echo "All args are $*"
echo "All args are $@"
echo "The scriptname is `basename $0`"
[root@localhost ~]# chmod +x shell/ARG.sh
[root@localhost ~]# shell/ARG.sh {1..10}
1st arg is 1
2st arg is 2
3st arg is 3
4st arg is 4
The number of are is 10
All args are 1 2 3 4 5 6 7 8 9 10
All args are 1 2 3 4 5 6 7 8 9 10
The scriptname is ARG.sh
[root@localhost ~]#
实例演示2:编写一个移动文件脚本
[root@localhost ~]# vim shell/move.sh
#!/bin/bash
WANGING_COLOR="echo -e \E[1;31m"
END="\E[0m"
DIR=/tmp/`date +%F_%H-%M-%S`
mkdir $DIR
mv $* $DIR
${WANGING_COLOR} MOVE $* to $DIR $END
[root@localhost ~]# chmod +x shell/move.sh
[root@localhost ~]# touch {a,b,c}
[root@localhost ~]# ls
a anaconda-ks.cfg b c shell
[root@localhost ~]# shell/move.sh a b c
MOVE a b c to /tmp/2022-08-16_10-07-55
[root@localhost ~]# tree /tmp/
/tmp/
└── 2022-08-16_10-07-55
├── a
├── b
└── c
1 directory, 3 files
[root@localhost ~]#
2.9 退出状态码变量
进程执行后,将使用变量 ? 保存状态码的相关数字,不同的值反应成功与失败, ?保存状态码的相关数字,不同的值反应成功与失败, ?保存状态码的相关数字,不同的值反应成功与失败,的取值范围为[0,255]
$?的值为0 代表成功
$?的值不为0 代表失败
用户可以在脚本中使用以下命令自定义退出状态码
exit [n]
实例:
[root@localhost ~]# ping -c 2 www.baidu.com > /dev/null
[root@localhost ~]# echo $?
0
[root@localhost ~]# cmd
-bash: cmd: 未找到命令
[root@localhost ~]# echo $?
127
[root@localhost ~]#
注意:
- 脚本中一旦遇到了exit命令,脚本会立即终止;终止退出状态取决于exit命令后面的数字
- 如果未给脚本指定退出状态码,整个脚本的退出状态码取决于脚本中执行的最后一条命令的状态码
实例1:$?获取上一个命令的退出状态
#!/bin/bash
if [ "$1"==100 ];then
exit 0 #参数正确,退出状态为0
else
exit 1 #参数错误,退出状态为1
fi
exit表示退出当前 Shell 进程,我们必须在新进程中运行 test.sh,否则当前 Shell 会话(终端窗口)会被关闭,我们就无法取得它的退出状态了
[root@localhost re_study]# bash test.sh 100
[root@localhost re_study]# echo $?
0
[root@localhost re_study]# bash test.sh 99
[root@localhost re_study]# echo $?
1
[root@localhost re_study]#
实例2:$?获取函数的返回值
#!/bin/bash
#得到两个数相加的和
function add(){
return `expr $1 + $2`
}
add 23 50 #调用函数
echo $? #获取函数返回值
# 运行结果:
[root@localhost re_study]# bash test.sh
73
2.10 展开命令行
2.10.1展开命令执行顺序
把命令行分成单个命令词
展开别名
展开大括号的声明{}
展开波浪符声明(~)
命令替换$()和``
再次把命令行分成命令词
展开文件通配(*,?,[abc]等)
准备I/O重导向(<,>)
运行命令
2.10.2 防止扩展
反斜线(\)会使随后的字符按原意解释
实例:
[root@localhost ~]# echo Your cost: \$5.00
Your cost: $5.00
[root@localhost ~]#
2.10.3 加引号来防止扩展
单引号(' ')防止所有扩展
双引号(" ")可防止扩展,但是以下清空例外:$(美元符号)
2.10.4 变量扩展
``:反引号,命令替换
\:反斜线,禁止单个字符扩展
!:叹号,历史命令替换
2.11 脚本安全和set
set命令:可以用来定制shell环境
2.11.1 $-变量
- h:hashell,打开选项后,Shell会将命令所在的路径hash下来,避免每次都要查询。通过set +h将h选项关闭.默认开启
- i:interactive-comments,包含这个选项说明当前的shell是一个交互式的shell。所谓的交互式shell,在脚本中,i选项是关闭的
- m:monitor,打开监控模式,就可以通过Job control来控制进程的停止,继续,后台或者前台执行等
- B:braccexpand,大括号扩展
- H:history,H选项打开,可以展开历史列表中的命令,可以通过
!来完成,例如!!返回最近的一个历史命令,!n返回第n个历史命令
实例:
[root@localhost ~]# echo $-
himBHs
[root@localhost ~]# hash
命中 命令
1 /usr/sbin/ping
[root@localhost ~]# set +h
[root@localhost ~]# echo $-
imBHs
[root@localhost ~]# hash
-bash: hash: 已禁用哈希
[root@localhost ~]#
[root@localhost ~]# echo {1..10}
1 2 3 4 5 6 7 8 9 10
[root@localhost ~]# set +B
[root@localhost ~]# echo {1..10}
{1..10}
[root@localhost ~]#
[root@localhost ~]# set +H
[root@localhost ~]# history !!
-bash: history: !!: 需要数字参数
[root@localhost ~]# history !3
-bash: history: !3: 需要数字参数
[root@localhost ~]# set -H
[root@localhost ~]# history !!
history set -H
-bash: history: set: 需要数字参数
[root@localhost ~]# history !3
history ifconfg
-bash: history: ifconfg: 需要数字参数
[root@localhost ~]#
2.11.2 set命令实现脚本安全
- -u:在扩展一个没有设置的变量时,显示错误信息,等同于set -o nounset
- -e:如果一个命令返回一个非0退出的状态值(失败)就退出,等同于set -o errexit
- -o:option 显示,打开或关闭选项
- 显示选项:set -o
- 打开选项:set -o 选项
- 关闭选项:set +o 选项
- -x:当执行命令时,打印命令及其参数,类似bash -x
实例:
[root@localhost ~]# set -o
allexport off
braceexpand off
emacs on
errexit off
errtrace off
functrace off
hashall on
histexpand on
history on
ignoreeof off
interactive-comments on
keyword off
monitor on
noclobber off
noexec off
noglob off
nolog off
notify off
nounset off
onecmd off
physical off
pipefail off
posix off
privileged off
verbose off
vi off
xtrace off
[root@localhost ~]# vim shell/error.sh
#!/bin/bash
echo "Hello World"
sssss
echo "Hello Linux"
[root@localhost ~]# chmod +x shell/error.sh
[root@localhost ~]# shell/error.sh
Hello World
shell/error.sh:行3: sssss: 未找到命令
Hello Linux
[root@localhost ~]# vim shell/error.sh
#!/bin/bash
set -e
echo "Hello World"
sssss
echo "Hello Linux"
[root@localhost ~]# shell/error.sh
Hello World
shell/error.sh:行4: sssss: 未找到命令
[root@localhost ~]#
3.Shell的格式化输出printf
3.1 语法格式:
printf "指定的格式" "文本1" "文本2" .....
3.2 常用格式替换符:
| 替换符 | 功能 |
|---|---|
| %s | 字符串 |
| %f | 浮点格式 |
| %b | 相对应的参数中包括转义字符时,可以使用此替换符进行替换,对应的转义字符会被转义 |
| %c | ASCII字符,即显示对应参数的第一个字符 |
| %d,%i | 十进制整数 |
| %o | 八进制值 |
| %u | 不带正负号的十进制值 |
| %x | 十六进制值(a-f) |
| %X | 十六进制值(A-F) |
| %% | 表示%本身 |
说明:%s中的数字代表此替换符中的输出字符宽度,不足补空格,默认是右对齐,%-10s表示10个字符宽,-表示左对齐
3.3 常用转义字符:
| 转义符 | 功能 |
|---|---|
| \a | 警告字符,通常为ASCII的BEL字符 |
| \b | 后退 |
| \f | 换页 |
| \n | 换行 |
| \r | 回车 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \ | 表示\本身 |
实例
[root@localhost ~]# printf "%s\n" 1 2 3 4
1
2
3
4
[root@localhost ~]# printf "%f\n" 1 2 3 4
1.000000
2.000000
3.000000
4.000000
[root@localhost ~]# printf "%.2f\n" 1 2 3 4 #.2f表示保留两位小数
1.00
2.00
3.00
4.00
[root@localhost ~]# printf "(%s)" 1 2 3 4;echo " "
(1)(2)(3)(4)
[root@localhost ~]# printf " (%s) " 1 2 3 4;echo " "
(1) (2) (3) (4)
[root@localhost ~]# printf " (%s) (%s)\n" 1 2 3 4;echo " "
(1) (2)
(3) (4)
[root@localhost ~]# printf " %s %s\n" 1 2 3 4;echo " "
1 2
3 4
[root@localhost ~]# printf "%s %s %s\n" 1 2 3 4
1 2 3
4
[root@localhost ~]#
#%-10s表示宽度10个字符,左对齐
[root@localhost ~]# printf "%-10s %-10s %-4s %s \n" 姓名 性别 年龄 体重 小明 男性 20岁 70KG 小红 女性 18岁 50KG
姓名 性别 年龄 体重
小明 男性 20岁 70KG
小红 女性 18岁 50KG
[root@localhost ~]#
#将十进制的1000转换为16进制数
[root@localhost ~]# printf "%X\n" 1000
3E8
[root@localhost ~]# printf "%x\n" 1000
3e8
[root@localhost ~]#
#将十六进制的C转换为十进制
[root@localhost ~]# printf "%d\n" 0xc
12
[root@localhost ~]#
[root@localhost ~]# var="welcome to study";printf "\033[31m%s\033[0m\n" $var
welcome
to
study
[root@localhost ~]# var="welcome to study";printf "\033[31m%s\033[0m\n" "$var"
welcome to study
[root@localhost ~]#
4.Shell脚本语言的运算
4.1 算数运算
shell支持算术运算,但只支持整数,不支持小数
4.2 Bash中的算术运算
-- + 加法运算
-- - 减法运算
-- * 乘法运算
-- / 除法运算
-- % 取模,即取余数
-- ** 乘方
#乘法符号在有些场景需要转义
4.2 实现算术运算
1. let var=算术表达式
2. var=$[算术表达式]
3. var=$((算术表达式))declare
4. var=$(expr arg1 arg2 arg3 ...)
5. declare -i var = 数值
6. echo '算术表达式' | bc
实例:使用bc计算小数和declare -i计算
[root@localhost ~]# echo "scale=3;20/3"|bc
6.666
[root@localhost ~]# echo "scale=3;2/3"|bc
.666
[root@localhost ~]# i=20
[root@localhost ~]# j=20
[root@localhost ~]# declare -i sum=i*j
[root@localhost ~]# echo $sum
400
[root@localhost ~]#
内建的随机数生成器变量:
$RANDOM 取值范围:0-32767
实例:生成0-49之间的随机数
[root@localhost ~]# echo $[$[$RANDOM%50]+1]
40
[root@localhost ~]# echo $[$RANDOM%50]
44
[root@localhost ~]# echo $[$[$RANDOM%50]+1] #生成1~50之间的随机数
实例:生成随机颜色字符串
[root@localhost ~]# echo -e "\033[1;$[RANDOM%7+31]mStudy\033[0m"
Study
[root@localhost ~]# echo -e "\033[1;$[RANDOM%7+31]mStudy\033[0m"
Study
[root@localhost ~]#
4.3 增强型赋值:
+=
i+=10 <==> i=1+10
-=
i-=j <==> i=i-j
*=
/=
%=
++
i++,++1 <==> i=i+1
--
i--,--i <==> i=i-1
格式:
let varOPERvalue
实例:自增,自减
[root@localhost ~]# let var+=1
[root@localhost ~]# echo $var
1
[root@localhost ~]# let var++
[root@localhost ~]# echo $var
2
[root@localhost ~]# let var-=1
[root@localhost ~]# echo $var
1
[root@localhost ~]# let var--
[root@localhost ~]# echo $var
0
[root@localhost ~]#
[root@localhost ~]# unset i j ;i=1;let j=i++;echo "i=$i,j=$j"
i=2,j=1
[root@localhost ~]# unset i j ;i=1;let j=++i;echo "i=$i,j=$j"
i=2,j=2
[root@localhost ~]#
# i++ 与 ++i的区别:
i++ 先赋值再运算
++i 先运算再赋值
实例:鸡兔同笼问题
[root@localhost ~]# vim shell/chicken.sh
#!/bin/bash
HEAD=35
FOOT=94
RABBIT=$(((FOOT-HEAD-HEAD)/2))
CHOOK=$[35-RABBIT]
echo "兔子的数量为:"$RABBIT
echo "鸡的数量为: "$CHOOK
[root@localhost ~]# chmod +x shell/chicken.sh
[root@localhost ~]# shell/chicken.sh
兔子的数量为::12
鸡的数量为::23
[root@localhost ~]#
# 在脚本中写入变量,让用户在命令行写入需要计算的数值
[root@localhost ~]# vim shell/chicken.sh
#!/bin/bash
HEAD=$1
FOOT=$2
RABBIT=$(((FOOT-HEAD-HEAD)/2))
CHOOK=$[35-RABBIT]
echo "兔子的数量为:"$RABBIT
echo "鸡的数量为: "$CHOOK
[root@ansible-salve1 ~]# ./chicken.sh 30 80
兔子的数量为:10
鸡的数量为: 25
[root@ansible-salve1 ~]#
面试题:计算出所有人的年龄总和
[root@ansible-salve1 shell]# vim nianling.txt
[root@ansible-salve1 shell]# cat nianling.txt
a=20
b=18
c=22
[root@ansible-salve1 shell]# cut -d"=" -f2 nianling.txt
20
18
22
[root@ansible-salve1 shell]# cut -d"=" -f2 nianling.txt | tr '\n' + | grep -Eo ".*[0-9]" | bc
60
[root@ansible-salve1 shell]# grep -Eo "[0-9]+" nianling.txt
20
18
22
[root@ansible-salve1 shell]# grep -Eo "[0-9]+" nianling.txt | tr '\n' +| grep -Eo ".*[0-9]" | bc
60
[root@ansible-salve1 shell]#
Linux操作系统之bc命令:Linux bc 命令 | 菜鸟教程 (runoob.com)
4.2 逻辑运算
True用数字表示1,False用数字表示0
-
与:&
1 与 1 = 1 1 与 0 = 0 0 与 1 = 0 0 与 0 = 0 -
或:|
1 或 1 = 1 1 或 0 = 1 0 或 1 = 1 0 或 0 = 0 -
非:!
!1 = 0 !True=False !0 = 1 !False=True -
异或:^
#异或的两个值,相同为假,不同为真 1 ^ 1 =0 1 ^ 0 =1 0 ^ 1 =1 0 ^ 0 =0
4.3 短路运算
-
短路与
CMD1 短路与 CMD2 --第一个CMD1结果为0(假),总的结果必定为0,所以不需要执行CMD2 --第二个CMD1结果为1(真),第二个CMD2必须要参与计算,才能得到最终的结果 -
短路或
CMD1 短路或 CMD2 --第一个CMD1结果为1(真),总的结果必定为1,因此不需要执行CMD2 --第一个CMD1结果为0(假),第二个CMD2必须要参与运算,才能得到最终的结果
4.4 条件测试命令
条件测试:判断某需求是否满足,需要由测试机制来实现,专用的测试表达式需要由测试命令辅助完成测试过程,实现评估布尔声明,以便在条件性环境下进行执行。
- 若真,则状态码变量$?返回0
- 若假,则状态码变量$?返回1
扩展: [ ] 与 [[ ]] 的区别
`区别1:
[ ]是符合POSIX标准的测试语句,兼容性强,几乎可以运行在所有的Shell解释器中
[[ ]]仅可运行在特定的几个Shell解释器中(如Bash)
`区别2:
> < 可以在[[ ]]中使用ASCII码顺序进行排序,而[]不支持
`区别3:
在[ ]中使用-a 和 -o 表示逻辑与和逻辑或,[[ ]]使用&& 和 || 表示,[[ ]]不支持-a
`区别4:
在[ ]中==是字符匹配,在[[ ]]中==是模式匹配
`区别5:
[ ]不支持正则匹配,[[ ]]支持用=~进行正则匹配
`区别6:
[ ]仅在部分Shell中支持用()进行分组,[[ ]]均支持
`区别7:
在[ ]中如果变量没有定义,那么需要用双引号引起来,在[[ ]]中不需要
4.4.1 条件测试命令及其语法
语法1:test <测试表达式> 说明:test命令和<测试表达式>之间至少有一个空格
# 在shell中,大于用 -gt 表示,小于用 -lt 表示,大于或等于用 -ge 表示,小于或等于用 -le表示 ,不相等用-ne 表示
[root@ansible-salve1 ~]# test 1 -lt 2
[root@ansible-salve1 ~]# echo $?
0
[root@ansible-salve1 ~]# test 2 -lt 1
[root@ansible-salve1 ~]# echo $?
1
[root@ansible-salve1 ~]#
语法2:[<测试表达式>] 说明:该方法和test命令的用法一样,[]的两边和内容之间至少有一个空格
[root@ansible-salve1 ~]# [ 1 -gt 3 ]
[root@ansible-salve1 ~]# echo $?
1
[root@ansible-salve1 ~]# [ 1 -lt 3 ]
[root@ansible-salve1 ~]# echo $?
0
[root@ansible-salve1 ~]#
语法3:[[ <测试表达式> ]] 说明:比test和[]更新的语法格式。[[]]的边界和内容之间至少有一个空格。[[]]中可以使用通配符等进行模式匹配
[root@ansible-salve1 ~]# [[ 1 > 3 ]]
[root@ansible-salve1 ~]# echo $?
1
[root@ansible-salve1 ~]# [[ 1 < 3 ]]
[root@ansible-salve1 ~]# echo $?
0
[root@ansible-salve1 ~]#
语法4:((<测试表达式>)) 说明:一般用于if语句里,双小括号两端不需要有空格,测试对象只能是整数
[root@ansible-salve1 ~]# ((1>2))
[root@ansible-salve1 ~]# echo $?
1
[root@ansible-salve1 ~]# ((1<2))
[root@ansible-salve1 ~]# echo $?
0
[root@ansible-salve1 ~]#
4.4.2 变量测试
语法规则:-v VAR 变量var是否被定义
示例:判断NAME变量是否被定义
[root@ansible-salve1 shell]# [[ -v NAME ]]
[root@ansible-salve1 shell]# echo $?
1
[root@ansible-salve1 shell]# NAME=1
[root@ansible-salve1 shell]# [[ -v NAME ]]
[root@ansible-salve1 shell]# echo $?
0
[root@ansible-salve1 shell]#
语法规则: -R VAR 变量VAR是否被引用
示例:判断NAME变量是否被引用
[root@ansible-salve1 shell]# NAME=10
[root@ansible-salve1 shell]# test -v NAME
[root@ansible-salve1 shell]# echo $?
0
[root@ansible-salve1 shell]# test -R NAME
[root@ansible-salve1 shell]# echo $?
1
[root@ansible-salve1 shell]#
4.4.3 文件测试表达式
| 常用的文件测试操作符 | 说明 |
|---|---|
| -a/-e 文件 | 文件是否存在 |
| -b 文件 | 文件是否存在,且为块文件,如果文件存在且是一个块文件,则结果为0 |
| -c 文件 | 文件是否存在且为字符文件,如果文件存在且是一个字符文件,则结果为0 |
| -L 文件 或 -h 文件 | 文件存在且为链接文件则为真 |
| -d 文件 | 文件存在且为目录则为真,即测试表达式成立 |
| -f 文件 | 文件存在且为普通文件则为真,即测试表达式成立 |
| -s 文件 | 文件存在且文件大小不为0则为真 |
| -S 文件 | 文件是否存在且为套接字文件 |
| -p 文件 | 文件是否存在且为管道文件 |
| -u 文件 | 文件是否存在且拥有suid的权限,如果设置了suid,则结果为0 |
| -g 文件 | 文件是否存在且拥有sgid的权限 |
| -r 文件 | 文件存在且可读为真 |
| -w 文件 | 文件存在且可写为真 |
| -x 文件 | 文件存在且可执行则为真 |
| -t fd | fd 文件描述符是否在某终端已经被打开 |
| -N 文件 | 文件自从上一次读取之后是否被修改过 |
| -O 文件 | 当前有效用户是否为文件属主 |
| -G 文件 | 当前有效用户是否为文件属组 |
| f1 -ef f2 | 文件f1是否是文件f2的硬链接 |
| f1 -nt f2,nt为newerthan | 文件f1比文件f2新则为真,根据文件的修改时间来计算 |
| f1 -ot f2,ot为olderthan | 文件f1比文件f2旧则为真,根据文件的修改时间来计算 |
测试文件
[root@ansible-salve1 ~]# test -a test.txt
[root@ansible-salve1 ~]# echo $?
1
[root@ansible-salve1 ~]# test -d shell
[root@ansible-salve1 ~]# echo $?
0
[root@ansible-salve1 ~]# touch test.txt
[root@ansible-salve1 ~]# test -w test.txt &&echo "true"
true
[root@ansible-salve1 ~]# test -r test.txt &&echo "true"
true
[root@ansible-salve1 ~]# test -x test.txt &&echo "true"
[root@ansible-salve1 ~]#
4.4.4 字符串测试表达式
| 常用字符串测试操作符 | 说明 |
|---|---|
| -n ”字符串“ | 若字符串的长度不为0,则为真,即测试表达式成立,n可以理解为nozero |
| -z ”字符串“ | 若字符串的长度为0,则为真,z可以理解为zero |
| > | Ascii码是否大于Ascii码 |
| “字符串1” == ”字符串2“ | 若字符串1长度等于字符串2长度,则为真 |
| “字符串1” != ”字符串2“ | 若字符串1长度不等于字符串2长度,则为真 |
| “字符串1” =~ “字符串2” | 左侧字符串是否能被右侧的PATTERN所匹配。注意:此表达式用于[[ ]]中:扩展的正则表达式 |
测试字符串
[root@ansible-salve1 ~]# var_test='Mike'
[root@ansible-salve1 ~]# echo $var_test
Mike
[root@ansible-salve1 ~]# [[ -n var_test ]] && echo "True"
True
# 通配符
[root@ansible-salve1 ~]# FILE=test.log
[root@ansible-salve1 ~]# [[ "$FILE" == *.log ]] && echo "True"
True
[root@ansible-salve1 ~]# FILE=test.txt
[root@ansible-salve1 ~]# [[ "$FILE" == *.log ]] && echo "True"
[root@ansible-salve1 ~]# [[ "$FILE" != *.log ]] && echo "True"
True
[root@ansible-salve1 ~]#
# 扩展的正则表达式
[root@ansible-salve1 ~]# FILE=test.log
[root@ansible-salve1 ~]# [[ "$FILE" =~ \.log$ ]] && echo "True"
True
[root@ansible-salve1 ~]# N=100
[root@ansible-salve1 ~]# [[ "$N" =~ ^[0-9]+$ ]] && echo "True"
True
[root@ansible-salve1 ~]# N=A10
[root@ansible-salve1 ~]# [[ "$N" =~ ^[0-9]+$ ]] && echo "True"
[root@ansible-salve1 ~]# IP=1.2.3.4
[root@ansible-salve1 ~]# [[ "$IP" =~ ^([0-9]{1,3}\.){3}[0-9]{1,3}$ ]]
[root@ansible-salve1 ~]# echo $?
0
[root@ansible-salve1 ~]#
# 使用正则表达式判断IP是否合法
[root@ansible-salve1 ~]# IP=1.2.3.333
[root@ansible-salve1 ~]# [[ $IP =~ ^(([1-9]?[0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\.){3}([1-9]?[0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])$ ]]
[root@ansible-salve1 ~]# echo $?
1
[root@ansible-salve1 ~]# IP=255.255.255.255
[root@ansible-salve1 ~]# [[ $IP =~ ^(([1-9]?[0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\.){3}([1-9]?[0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])$ ]]
[root@ansible-salve1 ~]# echo $?
0
[root@ansible-salve1 ~]#
4.4.5 整数测试表达式
| 在[ ] 或 test中使用的比较符号 | 在(()) 或 [[ ]]中使用的比较符号 | 说明 |
|---|---|---|
| -eq | == 或 = | 相等,equal |
| -ne | != | 不相等,not equal |
| -gt | > | 大于,greater than |
| -ge | > = | 大于等于,greater equal |
| -lt | < | 小于,less than |
| -le | <= | 小于等于,less equal |
4.4.6 逻辑操作符
| 在[ ] 中使用的操作符 | 在test, [[ ]] , (( ))中使用的逻辑操作符 | 说明 |
|---|---|---|
| -a | && | and,与,两边都为真,则结果为真 |
| -o | || | or,或,两端有一个真,则结果为真 |
| ! | ! | not,非,两端相反,则结果相反 |
示例
[root@ansible-salve1 ~]# var_test=1
[root@ansible-salve1 ~]# var_t=2
[root@ansible-salve1 ~]# [ $var_test -lt 0 -a $var_t -gt 0 ]
[root@ansible-salve1 ~]# echo $?
1
[root@ansible-salve1 ~]# [ $var_test -lt 0 -o $var_t -gt 0 ]
[root@ansible-salve1 ~]# echo $?
0
[root@ansible-salve1 ~]#
4.5 关于()与 { }
( )和 { }都可以将多个命令组合再一次,批量执行,{ } 里的内容需要与两侧用空格隔开并在命令结尾加上;
-
( )会开启子shell,并且list中变量赋值及内部命令执行后,将不再影响后续的环境
[root@ansible-salve1 ~]# name=mage;(echo $name;name=wang;echo $name);echo $name mage wang mage [root@ansible-salve1 ~]# (umask 444;umask);umask 0444 0022 [root@ansible-salve1 ~]# (umask 444;touch 1.txt);umask 0022 [root@ansible-salve1 ~]# ll 1.txt --w--w--w- 1 root root 0 11月 13 22:12 1.txt [root@ansible-salve1 ~]# echo $BASHPID 1418 [root@ansible-salve1 ~]# (echo $BASHPID; sleep 3) 1501 -
{ } 不会开启子shell,在当前shell中运行,会影响当前shell环境
[root@ansible-salve1 ~]# name=mage;{ echo $name;name=wang;echo $name; };echo $name mage wang wang [root@ansible-salve1 ~]# { umask 444;touch 1.txt; };umask 0444 [root@ansible-salve1 ~]# umask 0444 [root@ansible-salve1 ~]# ll 1.txt --w--w--w- 1 root root 0 11月 13 22:23 1.txt [root@ansible-salve1 ~]# echo $BASHPID 1418 [root@ansible-salve1 ~]# { echo $BASHPID; sleep 3; } 1418 [root@ansible-salve1 ~]#
4.6 组合测试条件
4.6.1 第一种方式[ ]
[ EXPRESSION1 -a EXPRESSION2] 并且 ==> 条件1与条件2都为真,结果才为真
[ EXPRESSION1 -O EXPRESSION2] 或 ==> 条件1与条件2只要有一个为真,结果就为真
[ !EXPRESSION1 ] 取反
说明:-a 和 -o 需要使用测试命令执行,[[ ]] 不支持
示例:
[root@ansible-salve1 ~]# ll 1.txt
--w--w--w- 1 root root 0 11月 13 22:23 1.txt
[root@ansible-salve1 ~]# FILE=/root/1.txt
[root@ansible-salve1 ~]# [ -f $FILE -a -x $FILE ]
[root@ansible-salve1 ~]# echo $?
1
[root@ansible-salve1 ~]# chmod +x /root/1.txt
[root@ansible-salve1 ~]# [ -f $FILE -a -x $FILE ]
[root@ansible-salve1 ~]# echo $?
0
[root@ansible-salve1 ~]#
4.6.2 第二种方式[[ ]]
COMMAND1 && COMMAND2 #并且,短路与,代表条件性的AND THEN
如果COMMAND1 成功,将执行COMMAND2,否则,将不执行COMMAND2
COMMAND1 || COMMAND2 #或者,短路或,代表条件性的OR ELSE
如果COMMAND1 成功,将不执行COMMAND2,否则,将执行COMMAND2
! COMMAND #非,取反
# 结论:如果&& 和 || 混合使用,&&要在前,||放在后
示例
[root@ansible-salve1 ~]# id hehao &> /dev/null || useradd hehao # 前面执行不成功,则执行后面的语句
[root@ansible-salve1 ~]# id hehao &> /dev/null && echo "此账户已存在"
此账户已存在
[root@ansible-salve1 ~]#
[root@ansible-salve1 ~]# IP=10.0.0.11;ping -c1 -w1 $IP &> /dev/null && echo $IP is up || echo $IP is down
10.0.0.11 is down
[root@ansible-salve1 ~]# IP=192.168.80.1;ping -c1 -w1 $IP &> /dev/null && echo $IP is up || echo $IP is down
192.168.80.1 is up
[root@ansible-salve1 ~]#
示例:磁盘空间的判断
# 查看磁盘空间占用率
[root@ansible-salve1 shell]# df | grep '^/dev/nv' | grep -oE '[0-9]+%' | tr -d %
17
[root@ansible-salve1 shell]# cat fd.sh
#!/bin/bash
WARNING=10
SPACE_USED=`df | grep '^/dev/nv' | grep -oE '[0-9]+%' | tr -d %`
["$SPACE_USED" -gt $WARNING] && echo "磁盘空间不足,请尽快处理" | mail -s "DISK Warning" 1446528135@qq.com
4.7 使用read命令命令来接受输入
read 是 Shell 内置命令,用来从标准输入中读取数据并赋值给变量。如果没有进行重定向,默认就是从键盘读取用户输入的数据;如果进行了重定向,那么可以从文件中读取数据
4.7.1 语法结构
read [option] [variables]
--options表示选项
--variables表示用来存储数据的变量,可以有一个,也可以有多个。
-- options和variables都是可选的,如果没有提供变量名,那么读取的数据将存放到环境变量 REPLY 中。
4.7.2 选项:
| Option | 说明 |
|---|---|
| -a array | 把读取的数据赋值给数组array,从下标0开始 |
| -d delimiter | 把字符串delimiter指定读取结束的位置,而不是一个换行符(读取的数据不包括delimiter) |
| -e | 在获取用户输入的时候,对功能键进行编码转换,不会直接显示功能键对应的字符 |
| -n num | 读取num个字符,而不是整行字符 |
| -p prompt | 显示提示信息,提示内容为prompt |
| -r | 原样读取(Raw mode),不会把反斜杠字符解释为转义字符 |
| -s | 静默模式(Silent mode),不会再屏幕上显示输入的字符。例如:输入密码 |
| -t seconds | 设置超时时间,单位为秒。如果用户没能按时完成,返回一个非0的退出状态 |
| -u fd | 使用文件描述符fd作为输入源,而不是标准输入,类似于重定向 |
示例:使用read给多个变量赋值并输出
[root@ansible-salve1 shell]# vim info.sh
#!/bin/bash
read -p "Enter some information > " name url age
echo "网站名字:$name"
echo "网址:$url"
echo "年龄:$age"
[root@ansible-salve1 shell]# chmod +x info.sh
[root@ansible-salve1 shell]# ./info.sh
Enter some information > hehao www.baidu.com 18
网站名字:hehao
网址:www.baidu.com
年龄:18
[root@ansible-salve1 shell]#
# 注意:必须在一行内输入所有的值,不能换行,否则只能给第一个变量赋值,后续变量都会赋值失败
示例:只读取一个字符
# -n 1表示只读取一个字符,运行脚本后,只要用户输入一个字符,立即就读取结束,不等待用户按下回车键
[root@ansible-salve1 shell]# vim info1.sh
#!/bin/bash
read -n 1 -p "Enter a char > " char && printf "\n"
echo "---------------------------------------------------------"
echo $char
[root@ansible-salve1 shell]# chmod +x info1.sh
[root@ansible-salve1 shell]# ./info1.sh
Enter a char > a
---------------------------------------------------------
a
示例:在指定时间内输入密码
#使用&&组合了多个命令,这些命令会依次执行,并且从整体上作为 if 语句的判断条件,只要其中一个命令执行失败(退出状态为非 0 值),整个判断条件就失败了,后续的命令也就没有必要执行
[root@ansible-salve1 shell]# vim info2.sh
#!/bin/bash
if
read -t 20 -sp "Enter password in 20 seconds(once) > " pass1 && printf "\n" && #第一次输入密码
read -t 20 -sp "Enter password in 20 seconds(again)> " pass2 && printf "\n" && #第二次输入密码
[ $pass1 == $pass2 ] #判断两次输入的密码是否相等
then
echo "Valid password"
else
echo "Invalid password"
fi
[root@ansible-salve1 shell]# chmod +x info2.sh
[root@ansible-salve1 shell]# ./info2.sh
Enter password in 20 seconds(once) >
Enter password in 20 seconds(again)>
Valid password
[root@ansible-salve1 shell]#
示例:利用正则表达式
[root@ansible-salve1 shell]# vim info3.sh
[root@ansible-salve1 shell]# cat info3.sh
#!/bin/bash
read -p "Are you rich? yes or no: " ANSWER
[[ $ANSWER =~ ^[Yy]|[Yy][Ee][Ss]$ ]] && echo "You Are Rich" || echo "Good Good Study,Day Day up"
[root@ansible-salve1 shell]# chmod +x info3.sh
[root@ansible-salve1 shell]# ./info3.sh
Are you rich? yes or no: y
You Are Rich
[root@ansible-salve1 shell]# ./info3.sh
Are you rich? yes or no: YeS
You Are Rich
[root@ansible-salve1 shell]#
示例:工作选项
[root@ansible-salve1 shell]# vim backup.sh
#!/bin/bash
SRC=/etc/
DEST=/data/backup_`date +%F_%H-%M-%S`
cp -a $SRC $DEST
[ $? -eq 0 ] && echo "备份成功" || echo "备份失败"
[root@ansible-salve1 shell]# chmod +x backup.sh
[root@ansible-salve1 shell]# vim info4.sh
#!/bin/bash
cat <<EOF
请选择:
1.备份文件
2.清理日志文件
3.软件升级
4.软件回滚
5.删库跑路
EOF
read -p "请输入上面的数字1-5:" MENU
[ $MENU -eq 1 ] && ./backup.sh
[ $MENU -eq 2 ] && echo "清理日志文件"
[ $MENU -eq 3 ] && echo "软件升级"
[ $MENU -eq 4 ] && echo "软件回滚"
[ $MENU -eq 5 ] && echo "删除跑路"
[root@ansible-salve1 shell]# chmod +x info4.sh
[root@ansible-salve1 shell]# ./info4.sh
请选择:
1.备份数据库
2.清理日志文件
3.软件升级
4.软件回滚
5.删库跑路
请输入上面的数字1-5:1
备份成功
[root@ansible-salve1 shell]#
5.bash的配置文件
bash shell的配置文件很多,可以分为以下类别
5.1 按生效范围划分为两类
5.1.1 全局配置:
/etc/profile
/etc/profile.d/*.sh
/etc/bashrc
5.1.2 个人配置
~/.bash_profile
~/.bashrc
5.2 shell登录的两种方式分类
5.2.1 交互式登录
- 直接通过终端输入账户密码
- 使用
su - username切换用户
配置文件执行顺序:
/etc/profile --> /etc/profile.d/*.sh --> ~/.bash_profile --> ~/.bashrc --> /etc/bashrc
5.2.2 非交互式登录
- su username
- 图形界面下打开的终端
- 执行脚本
- 任何其他的bash实例
配置文件执行顺序:
/etc/profile.d/*.sh --> /etc/bashrc --> ~/.bashrc
5.3 按功能划分分类
5.3.1 Profile类
profile类为交互式登录的shell提供配置
- 全局:
/etc/profile, /etc/profile.d/*.sh - 个人:
~/.bash_profile
功能:
- 用于定义环境变量
- 运行命令或脚本
5.3.2 Bashrc类
bashrc类:为非交互式和交互式登录的shell提供配置
- 全局:
/etc/bashrc - 个人:
~/.bashrc
功能:
- 定义命令别名和函数
- 定义本地变量
5.4 编辑配置文件生效
source 配置文件
6.流程控制
6.1 条件选择
6.1.1 选择执行if语句
if结构:
[root@ansible-salve1 shell]# help if
if: if 命令; then 命令; [ elif 命令; then 命令; ]... [ else 命令; ] fi
根据条件执行命令。
`if COMMANDS'列表被执行。如果退出状态为零,则执行`then COMMANDS'
列表。否则按顺序执行每个 `elif COMMANDS'列表,并且如果它的退出状态为
零,则执行对应的 `then COMMANDS' 列表并且 if 命令终止。否则如果存在的
情况下,执行 `else COMMANDS'列表。整个结构的退出状态是最后一个执行
的命令的状态,或者如果没有条件测试为真的话,为零。
退出状态:
返回最后一个执行的命令的状态。
[root@ansible-salve1 shell]#
6.1.1.1 单分支
if [ 条件判断式 ];then
命令
fi
或者
if [ 条件判断式 ]
then
命令
fi
6.1.1.2 双分支
if [ 条件判断式 ]
then
命令
else
命令
fi
6.1.1.3 多分支
if [ 条件判断式1 ]
then
命令
elif [ 条件判断式2 ]
then
命令
...
...
else
命令
fi
示例:依据BMI参数写出判断语句
[root@ansible-salve1 shell]# vim info5.sh
#!/bin/bash
read -p "请输入身高(m为单位):" HIGH
if [[ ! "$HIGH" =~ ^[0-2].?[0-9]{,2}$ ]]
then
echo "请不要输入错误的身高";
exit 1;
fi
read -p "请输入体重(Kg为单位):" WEIGHT
if [[ ! "$WEIGHT" =~ ^[0-9]{1,3}$ ]]
then
echo "请不要输入错误的体重";
exit 1;
fi
BMI=`echo $WEIGHT/$HIGH^2|bc`
if [ $BMI -le 18 ] ;then
echo "你太瘦了,请注意身体建康"
elif [ $BMI -lt 24 ] ;then
echo "身材很棒!"
else
echo "你太胖了,注意节食,加强运动"
fi
[root@ansible-salve1 shell]# chmod +x info5.sh
[root@ansible-salve1 shell]# ./info5.sh
说明:
- 多个if条件时,逐个条件进行判断,第一次遇见为“真”条件时,执行其分支,而后结束整个if语句
- if语句可嵌套
6.1.2条件判断case语句
格式
[root@ansible-salve1 shell]# help case
case: case 词 in [模式 [| 模式]...) 命令 ;;]... esac
基于模式匹配来执行命令。
基于 PATTERN 模式匹配的词 WORD,有选择的执行 COMMANDS 命令。
`|' 用于分隔多个模式。
退出状态:
返回最后一个执行的命令的状态。
[root@ansible-salve1 shell]#
case 变量引用 in
PAT1)
分支1
;;
PAT2)
分支2
;;
...
*)
默认分支
;;
esac
case支持glob风格的通配符
*: 任意长度任意字符
?: 任意单个字符
[]: 指定范围内的任意单个字符
|: 或,如a|b ,a或b
示例:
[root@ansible-salve1 shell]# vim info6.sh
#!/bin/bash
read -p "Do you agree(yes/no)?" INPUT
INPUT=`echo $INPUT | tr 'A-Z' 'a-z'`
case $INPUT in
y|yes)
echo "You input is Yes"
;;
n|no)
echo "You input is No"
;;
*)
echo "Input fales,please input yes or no!"
esac
[root@ansible-salve1 shell]# chmod +x info6.sh
[root@ansible-salve1 shell]# ./info6.sh
Do you agree(yes/no)?yes
You input is Yes
[root@ansible-salve1 shell]# ./info6.sh
Do you agree(yes/no)?no
You input is No
[root@ansible-salve1 shell]# ./info6.sh
Do you agree(yes/no)?111
Input fales,please input yes or no!
[root@ansible-salve1 shell]#
示例:工作选项
[root@ansible-salve1 shell]# vim info7.sh
#!/bin/bash
cat <<EOF
请选择:
1.备份文件
2.清理日志文件
3.软件升级
4.软件回滚
5.删库跑路
EOF
read -p "请输入上面的数字1-5:" MENU
case $MENU in
1)
./backup.sh
;;
2)
echo "清理日志"
;;
3)
echo "软件升级"
;;
4)
echo "软件回滚"
;;
5)
echo "删库跑路"
;;
*)
echo "Input False"
esac
[root@ansible-salve1 shell]# chmod +x info7.sh
[root@ansible-salve1 shell]# ./info7.sh
请选择:
1.备份数据库
2.清理日志文件
3.软件升级
4.软件回滚
5.删库跑路
请输入上面的数字1-5:1
备份成功
[root@ansible-salve1 shell]#
6.2 循环
6.2.1 循环执行介绍

讲某代码段重复运行多次,通常有进入循环的条件和退出循环的条件
重复运行次数
- 循环次数事先已知
- 循环次数事先未知
常见的循环的命令:for,while,until
#循环的逻辑:程序先进行语句判断,如果为真则执行循环语句,然后再进行语句判断,直至语句判断失败才跳出
6.2.2 for循环
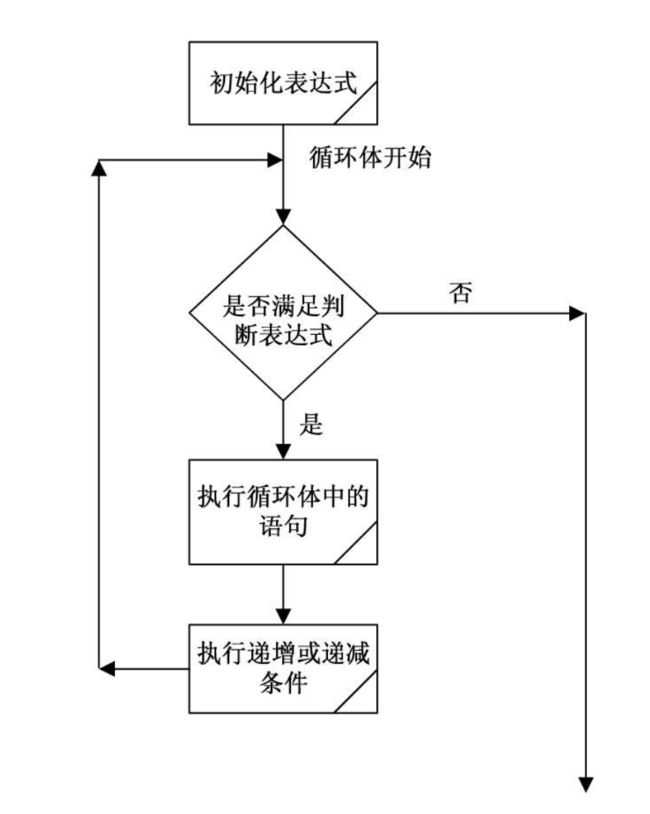
格式1:
# 第一种写法
for NAME [in words ...]; do commands;done
# 第二种写法
for 变量 in 列表
循环体
done
# 第三种写法
for 变量 in 列表
do
循环体
done
执行机制:
依次将列表中的元素赋值给”变量名“;每次赋值后即执行一次循环体;直到列表中的元素耗尽,循环结束
示例:
[root@ansible-salve1 shell]# for i in 1 2 3 4 5 6 ; do echo i=$i;done
i=1
i=2
i=3
i=4
i=5
i=6
[root@ansible-salve1 shell]# for i in {1..10..2};do echo i=$i;done
i=1
i=3
i=5
i=7
i=9
[root@ansible-salve1 shell]# for i in `seq 10`;do echo i=$i;done
i=1
i=2
i=3
i=4
i=5
i=6
i=7
i=8
i=9
i=10
[root@ansible-salve1 shell]# sum=0; for i in `seq 10`;do let sum+=i;done;echo sum=$sum
sum=55
[root@ansible-salve1 shell]#
for循环列表生成方式
-
直接给出列表
-
整数列表
{start..end} $(seq [start [step]] end) -
返回列表的命令
$(COMMAND) -
使用glob,如:*.sh
# 示例 [root@ansible-salve1 log]# for FILE in `ls /var/log/*.log`;do ll $FILE;done -rw-------. 1 root root 0 11月 16 08:15 /var/log/boot.log -rw------- 1 root root 675624 11月 16 07:48 /var/log/dnf.librepo.log -rw------- 1 root root 81415 11月 16 07:48 /var/log/dnf.log -rw------- 1 root root 1208 11月 16 07:38 /var/log/dnf.rpm.log -rw------- 1 root root 39189 11月 16 07:48 /var/log/hawkey.log -rw------- 1 root root 775 11月 15 04:46 /var/log/vmware-network.1.log -rw------- 1 root root 775 11月 15 03:54 /var/log/vmware-network.2.log -rw------- 1 root root 775 11月 14 21:22 /var/log/vmware-network.3.log -rw------- 1 root root 775 11月 14 06:54 /var/log/vmware-network.4.log -rw------- 1 root root 775 11月 14 01:21 /var/log/vmware-network.5.log -rw------- 1 root root 775 11月 13 21:04 /var/log/vmware-network.6.log -rw------- 1 root root 775 11月 13 04:59 /var/log/vmware-network.7.log -rw------- 1 root root 775 11月 12 22:00 /var/log/vmware-network.8.log -rw------- 1 root root 775 10月 28 21:42 /var/log/vmware-network.9.log -rw------- 1 root root 775 11月 16 07:28 /var/log/vmware-network.log -rw-r--r--. 1 root root 80892 11月 16 07:28 /var/log/vmware-vmsvc.log [root@ansible-salve1 log]# -
变量引用,如: @ , @, @,#,$*
位置参数# 示例 [root@ansible-salve1 shell]# vim info8.sh #!/bin/bash sum=0; for i in $@;do let sum+=i done echo sum=$sum [root@ansible-salve1 shell]# chmod +x info8.sh [root@ansible-salve1 shell]# ./info8.sh 1 2 4 5 6 7 9 sum=34 [root@ansible-salve1 shell]#
示例:打印99乘法表
[root@ansible-salve1 shell]# vim info9.sh
#!/bin/bash
for i in {1..9};do
for j in `seq $i`;do
echo -e "${j}x$i=$((j*i))\t\c "
done
echo
done
[root@ansible-salve1 shell]# chmod +x info9.sh
[root@ansible-salve1 shell]# ./info9.sh
1x1=1
1x2=2 2x2=4
1x3=3 2x3=6 3x3=9
1x4=4 2x4=8 3x4=12 4x4=16
1x5=5 2x5=10 3x5=15 4x5=20 5x5=25
1x6=6 2x6=12 3x6=18 4x6=24 5x6=30 6x6=36
1x7=7 2x7=14 3x7=21 4x7=28 5x7=35 6x7=42 7x7=49
1x8=8 2x8=16 3x8=24 4x8=32 5x8=40 6x8=48 7x8=56 8x8=64
1x9=9 2x9=18 3x9=27 4x9=36 5x9=45 6x9=54 7x9=63 8x9=72 9x9=81
[root@ansible-salve1 shell]#
生产案例:将指定目录下的所有文件的后缀都进行备份
# 取出文件的后缀名
[root@ansible-salve1 shell]# echo nianling.sh | sed -En 's/^(.*)\.([^.]+)$/\2/p'
sh
# 取出文件的前缀名
[root@ansible-salve1 shell]# echo nianling.sh | sed -En 's/^(.*)\.([^.]+)$/\2/p'
nainling
[root@ansible-salve1 shell]# vim info10.sh
#!/bin/bash
DIR=/root/shell
cd $DIR
for FILE in *;do
PRE=`echo $FILE | sed -nr 's/(.*)\.([^.]+)$/\1/p'`
cp $FILE $PRE.bak
done
[root@ansible-salve1 shell]# chmod +x info10.sh
面试题:要求将目录中YYYY-MM-DD中的所有文件移动到YYYY-MM/DD目录下
1.创建YYYY-MM-DD,当前日期一年前365天到目前一共365个目录,里面有10个文件,$random.log
[root@ansible-salve1 ~]# vim mkdir.sh
#!/bin/bash
for i in {1..365};do
DIR=`date -d "-$i day" +%F`
mkdir /data/test/$DIR
cd /data/test/$DIR
for n in {1..10};do
touch $RANDOM.log
done
done
# 2.移动到YYYY-MM/DD下
[root@ansible-salve1 ~]# mkdir mv.sh
#!/bin/bash
DIR=/data/test
cd $DIR
for DIR in *;do
YYYY_MM=`echo $DIR | cut -d"_" -f1,2`
DD=`echo $DIR |cut -d"_" -f3`
[ -d $YYYY_MM/$DD ] || mkdir -p $YYYY_MM/$DD &> /dev/null
mv $DIR/* $YYYY_MM/$DD
done
面试题:扫描一个网段192.168.80.0/24,判断输入的网段中主机的在线状态,将在线的主机IP打印出来
[root@ansible-salve1 ~]# vim ip.sh
#!/bin/bash
IP=192.168.80.
for i in `seq 254`;do
{
ping -c1 -W1 $IP$i &> /dev/null && echo $IP$i "is up"
}&
done
wait
格式2:
双小括号方法,即((…))格式,也可以用于算术运算,双小括号方法也可以使用bash shell 实现C语言风格的变量操作l=10;((l++))
for ((控制变量初始化;条件判断表达式;控制变量的修正表达式))
do
循环体
done
说明:
- 控制变量初始化:仅在运行到循环代码段时执行一次
- 控制变量的修正表达式:每轮循环结束后会先进行控制变量修正运算,然后在做条件判断
示例:1到100的和
#!/bin/bash
sum=0
for i in {1..100} ;do
let sum+=i
done
echo sum=$sum
sum=0
for ((i=1;i<=100;i++));do
let sum+=i
done
echo sum=$sum
示例:九九乘法表
#!/bin/bash
for ((i=1;i<10;i++));do
for ((j=1;j<=i;j++));do
echo -e "${j}x$i=$((j*i))\t\c"
done
echo
done
示例:打印三角形
# 直角三角形
#!/bin/bash
for((i=1;i<=10;i++));do
for((j=1;j<=2*i-1;j++));do
echo -e '*\c'
done
echo
done
# 等腰三角形
#!/bin/bash
for((i=1;i<=10;i++));do
for((k=1;k<=10-i;k++));do
echo -e ' \c'
done
for((j=1;j<=2*i-1;j++));do
echo -e '*\c'
done
echo
done
6.2.3 while循环
[root@ansible-salve1 shell]# help while
while: while 命令; do 命令; done
只要测试成功即执行命令。
只要在 `while' COMMANDS 中的最终命令返回结果为0,则
展开并执行 COMMANDS 命令。
退出状态:
返回最后一个执行的命令的状态。
[root@ansible-salve1 shell]#

格式:
while command; do commands;done
while condition;do 循环体 done
说明:
condition:循环控制条件;进入循环之前,先做一次判断;每一次循环之后会再次做判断;条件为“Ture”,则执行一次循环;直到条件测试状态为“false”终止循环,因此:condition一般应该有循环控制变量;而此变量的值会在循环不断地被修正
进入条件:condition为True
退出条件:condition为False
无限循环
while true;do
循环体
done
案例1:猜数游戏
#!/bin/bash
# 脚本生成一个100以内得随机数,提示用户猜数字,根据用户得输入,提示用户猜小了或猜大了,直至用户猜对脚本结束
# RANDOM为系统自带的系统变量,值为0~32767的随机数
# 使用取余算法将随机数变为1~100的随机数
num=$[RANDOM%100+1]
echo $num
# 使用read 提示用户猜数字
# 使用if判断用户猜数字的大小关系:
# -eq(等于),-ne(不等于),-gt(大于),-ge(大于等于),-lt(小于),-le(小于等于)
while :
do
read -p "数字炸弹在1~100的随机数,请选择数字:" n
if [ $n -eq $num ];then
echo "恭喜,爆炸了"
exit
elif [ $n -gt $num ];then
echo "你猜大了,缩小范围为:0~$n之中"
else
echo "你猜小了,缩小范围为$n~100之中"
fi
done
案例2:DNS地址查询小程序
#!/bin/bash
# Function 基于DNS字典文件做一个中国电信DNS查询地址
IPPattern='^(\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>\.){3}\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>$'
echo -e "\e[34m --------------------------这是一个指定地区查询对应的DNS地址小程序-------------------------- \e[0m"
read -p "请输入你想查询的省份:" Province
read -p "请输入你想查询的城市: " City
echo -e "\e[34m --------------------------你查询的地址为$Province$City ,正在为你查询,请稍后---------------------- \e[0m"
count=0
while read line
do
province=$(echo $line | awk -F " " '{print $2}') #省份
city=$(echo $line | awk -F " " '{print $3}') #城市
if [[ "${city}" =~ ${IPPattern} ]];then
city=" "
dns_address=$(echo $line | awk -F " " '{print $3}') #DNS地址
else
dns_address=$(echo $line | awk -F " " '{print $4}') #DNS地址
fi
if [[ "$province" == $Province* ]];then
if [[ "$city" == $City* ]];then
echo -e "\e[32m $province $city地址为:$dns_address \e[0m"
fi
fi
done < /root/re_study/Shell_Study/dns_list.txt
echo -e "\e[34m --------------------------这就是以上对$Province$City的DNS地址查询,查询结果仅供参考---------------------- \e[0m"
exit 0

案例3:持续检查服务器负载
#!/bin/bash
#Fuction:持续检查服务器负载,如果负载过高则发送警告邮件
while true
do
load=$(uptime | awk '{print $10}'|tr -s "," ' ')
if [ $(echo "$load > 1.0" | bc) -eq 1 ];then
echo "Warning:Server load is high:$load" | mail -s "Server load warning" [email protected]
fi
sleep 300
done
# echo "$load > 1.0" | bc 返回一个数字布尔值,0为True,1为False
案例4:持续检查应用日志
#!/bin/bash
#fuction:持续检查错误日志.如有错误日志则发送警告邮件
while true
do
if grep -q "Error" /var/log/maillog;then
echo "Warning:Error log found in maillog" | mail -s "Application error" [email protected]
fi
sleep 600
done
案例5:持续同步文件夹
#!/bin/bash
#Fuction:持续将本地文件夹同步到远程服务器上
while true
do
rsync -avz /local/folder/ user@remote-server:/remote/folder/
sleep 3600
done
案例6:持续备份数据库
#!/bin/bash
#Fuction:持续备份数据库,每天备份一次
while true:
do
now=$(date +"%Y-%m-%d-%H-%M-%S")
mysqldump -uroot -p password mydb > "/backup/mydb_$now.sql"
sleep 86400
done
案例7:逐行读取文件
#!/bin/bash
#Fuction:逐行读取文件
while read line
do
echo $line
done < filename.txt
案例8:计数器循环
#!/bin/bash
#Fuction:计数器循环器
counter=0
while [ $counter -lt 10 ]
do
echo $counter
counter=$((counter+1))
done
案例9:监听文件变化
#!/bin/bash
while inotifywait -e modify filename
do
echo "File Changed"
sleep 10
done
6.2.4 until循环
[root@ansible-salve1 ~]# help until
until: until 命令; do 命令; done
当测试不同过时执行命令。
`until' COMMANDS 命令的最终命令返回状态不为 0 时,
展开并执行 COMMANDS 命令。
退出状态:
返回最后一个执行的命令的状态。
格式:
until Commands;do commands;done
until condition;do
循环体
done
说明:
进入条件:condition为false
退出条件:condition为ture
无限循环
until false;do
循环体
done
案例1:等待网络服务启动
#!/bin/bash
#Function:等待MySQL服务启动
until mysqladmin ping > /dev/null 2>&1
do
sleep 1
systemctl start mariadb.service
done
echo "MySQL服务已经启动"
`这个脚本等待 MySQL 服务启动,每隔 1 秒钟检查一次 MySQL 是否已经启动。当 MySQL 服务已经启动,脚本会输出一条消息。
案例2:等待用户输入
#!/bin/bash
#Function:等待用户输入
until read -p "请输入你的姓名: " name && [ -n "$name"]
#test -n 字符串字符串的长度非零
do
echo "姓名不能为空"
done
echo "你的姓名为: $name"
`这个脚本等待用户输入姓名,如果输入为空,则提示用户重新输入。当输入不为空时,脚本会输出用户输入的姓名
案例3:等待文件被删除
#!/bin/bash
# Function:等待文件被删除
until [ ! -f /path/to/file ]
do
sleep 1
done
echo "文件已被删除"
`这个脚本等待文件 /path/to/file 被删除,每隔 1 秒钟检查一次文件是否存在。当文件不存在时,脚本会输出一条消息
案例4:等待用户按下某个键
#!/bin/bash
until read -n1 -p "按下Y/y继续..." Key && [ "$Key" == "Y" ] || [ "$Key" == "y" ]
do
echo "无效的键 $Key"
done
echo "成功的继续"
案例5:等待某个端口开放
#!/bin/bash
#Function:等待端口开放
until nc -z localhost 8080
do
sleep
done
echo "端口已开放"
`nc为namp工具所具备的命令,yum -y install nc
使用事项
until循环与while循环类似,不同之处在于until循环会一直循环,直到条件为真才会停止,而while会一直循环,直到条件为假才会停止until循环的语法格式为:until condition; do commands; done,其中condition表示循环条件,commands表示需要执行的命令- 在
until循环中,可以使用sleep命令来延迟循环执行的时间,避免过度消耗系统资源 - 在循环条件中使用
&&运算符可以将多个条件组合起来,只有当所有条件都满足时,循环才会结束。使用||运算符可以将多个条件组合起来,只有当任意一个条件满足时,循环才会结束 - 在循环体中使用
break命令可以提前结束循环 - 在循环体中使用
continue命令可以跳过当前循环,直接执行下一次循环 - 在使用
until循环时,要确保循环条件最终能够被满足,否则循环会一直执行下去,直到被手动中断 - 在循环条件中,要使用测试命令或者其他命令来判断条件是否为真,比如使用
[]或者test命令来进行比较或者测试 - 在循环体中,可以使用各种 Shell 命令和语句来执行一系列操作,比如打印输出、文件操作、进程管理、网络通信等等
until循环可以用于各种场景,比如等待某个操作完成、等待某个资源可用、等待某个服务启动等等,只需要根据具体需求编写相应的脚本即可
6.2.5 循环控制语句continue
continue[N]:提前结束第N层的本轮循环,而直接进入下一轮判断;最内层为第1层
格式:
while CONDITION1;do
循环体1
...
if command2;then
continue
fi
CMDn
....
done
示例: 结束最内层循环
#!/bin/bash
for((i=0;i<10;i++));do
for((j=0;j<10;j++));do
[ $j -eq 5 ] && continue
echo $j
done
echo ----------------------------
done
示例:结束外层循环
#!/bin/bash
for((i=0;i<10;i++));do
for((j=0;j<10;j++));do
[ $j -eq 5 ] && continue 2
echo $j
done
echo ----------------------------
done
[root@ansible-salve1 shell]# vim info14.sh
[root@ansible-salve1 shell]# bash info14.sh
0
1
2
3
4
0
1
2
3
4
6.2.6 循环控制语句break
break[N]:提前结束第N层后的全部循环;最内层为第1层,默认为1
示例:结束内层循环
#!/bin/bash
for((i=0;i<10;i++));do
for((j=0;j<10;j++));do
[ $j -eq 5 ] && break
echo $j
done
echo ----------------------------
done
[root@ansible-salve1 shell]# vim info14.sh
[root@ansible-salve1 shell]# bash info14.sh
0
1
2
3
4
----------------------------
0
1
2
3
4
----------------------------
示例:结束外层循环
#!/bin/bash
for((i=0;i<10;i++));do
for((j=0;j<10;j++));do
[ $j -eq 5 ] && break 2
echo $j
done
echo ----------------------------
done
[root@ansible-salve1 shell]# vim info14.sh
[root@ansible-salve1 shell]# bash info14.sh
0
1
2
3
4
[root@ansible-salve1 shell]#
案例1:餐厅简易点餐系统
#!/bin/bash
sum=0
COLOR='echo -e \033[1;31m'
COLOR2='echo -e \033[1;32m'
END="\033[0m"
while true;do
echo -e "\033[33;1m\c"
cat <<EOF
1)鲍鱼
2)满汉全席
3)龙虾
4)燕窝
5)帝王蟹
6)退出
EOF
echo -e "\033[0m"
read -p "请点菜:" MENU
case $MENU in
1|4)
$COLOR'菜价:$10'$END
let sum+=10
;;
3|5)
$COLOR'菜价:$20'$END
let sum+=20
;;
2)
$COLOR'菜价:$1000'$END
let sum+=1000
;;
6)
$COLOR2"你点菜的总价格是$sum"$END
break
;;
*)
echo "没有这道菜,请重新点单"
;;
esac
$COLOR2"你点的菜总价格是$sum"$END
done`
案例2:持续监控应用状态
#!/bin/bash
#Fuction:基于While循环持续监控应用状态
while true
do
if systemctl status sshd | grep -q "active (running)";then
break
fi
sleep 10
done
6.2.7 shift与select技术
shift命令用于对参数的向左移动,通常用于在不知道传入参数个数的情况下依次遍历每个参数,然后进行相应的处理(常见与Linux中各种程序的启动脚本)。在扫描处理脚本程序的参数时,经常要用到shift命令
shift命令每执行一次,参数序列顺次左移一个位置,$#的值减1,用于分别处理每个参数,移出去的参数不可再用
注意:$#表示脚本后跟随的参数总的个数,$n可以获取脚本后跟随的第n个参数的值
[root@nqs22-tps22 ~]# type shift
shift 是 shell 内嵌
[root@nqs22-tps22 ~]# help shift
shift: shift [n]
移位位置参数。
重命名位置参数 $N+1、$N+2 ... 到 $1、$2 ... 如果没有给定 N,
则假设为1.
退出状态:
返回成功,除非 N 为负或者大于 $#。
参考实例:依次读取输入的参数并打印参数个数:
[root@nqs22-tps22 ~]# vim run.sh
[root@nqs22-tps22 ~]# cat run.sh
#!/bin/bash
while [ $# != 0 ];do
echo "第一个参数为:$1,参数个数为:$#"
shift
done
[root@nqs22-tps22 ~]# sh run.sh a b c d e f
第一个参数为:a,参数个数为:6
第一个参数为:b,参数个数为:5
第一个参数为:c,参数个数为:4
第一个参数为:d,参数个数为:3
第一个参数为:e,参数个数为:2
第一个参数为:f,参数个数为:1
参考实例:将参数从左到右逐个移动
[root@nqs22-tps22 ~]# vim shift.sh
#!/bin/bash
while [ $# -ne 0 ]
do
echo "第一个参数为:$1 参数个数为:$#"
shift
done
[root@nqs22-tps22 ~]# sh shift.sh Lily Lucy Jake Mike
第一个参数为:Lily 参数个数为:4
第一个参数为:Lucy 参数个数为:3
第一个参数为:Jake 参数个数为:2
第一个参数为:Mike 参数个数为:1
[root@nqs22-tps22 ~]#
7.Shell中的数组
7.1 Shell数组的概念
数组是若干数据的集合,其中存放的每一份数据都称为元素。Shell不限制数组的大小,理论上可以存放无限量的数据,Shell数组元素的下标也是从0开始计数
获取数组中的元素要使用下标[ ],下标可以是一个整数,也可以是一个结果为整数的表达式;下标必须大于等于0
注意:
Shell只支持一维数组,不支持多维数组
7.2 Shell数组的定义
7.2.1 数组的基本定义
在Shell中,用小括号()来表示数组,数组元素之间用空格来分隔
#arrayname=(1 2 3 4 5)
`输出定义数组中的全部元素
#echo ${arrayname[*]}
#echo ${arrayname[@]}
`输出定义数组中的第二个元素
#echo ${arrayname[0]}
`输出定义数组中的第二个元素
#echo ${arrayname[1]}
`输出定义数组中的元素个数
#echo ${#arrayname[*]}
7.2.2 采用键值对的形式赋值
在Shell中用小括号将变量括起来,同时采用键值对的形式赋值
#array2=([1]=one [2]=two [3]=three)
echo ${array2[*]} #输出定义数组的所有元素
echo ${array2[@]} #输出定义数组的所有元素
echo ${#array2[@]} #输出定义数组的元素个数
7.2.3 通过分别定义数组变量的方法来定义
#array3[1]=a
#array3[2]=b
#array3[3]=c
`输出定义数组中的全部元素
echo ${array3[@]}
`输出定义数组中的第一个元素
echo ${array3[1]}
7.2.4 动态定义数组数量
动态地定义数组变量,并使用命令的输出结果作为数组的内容
# mkdir -p /array
# touch /array/{1..5}.txt
# ls /array
# array4=($(ls /array))
# echo ${array4[*]}
# echo ${array4[@]}
# echo ${#array4[*]}
7.3 Shell数组的打印
- 打印单个数组元素: ${数组名[下标]} 。当未指定数组下标时,下标默认从0开始
- 打印全部数组内容:${数组名[@]}或 ${数组名[*]}
- 打印数组元素的个数:${#数组名[@]}或 ${#数组名[*]}
7.4 Shell数组的赋值
如果下标不存在,则自动添加一个新的元素;如果下标存在,则覆盖原来的值
7.5 Shell数组的拼接合并
所谓Shell数组拼接(数组合并),就是将两个数组连接成一个数组
拼接数组的思路是:先利用@或者*,将数组扩展成列表,然后再合并到一起,具体格式如下:
array_new=(${array1[@]} ${array2[@]})
array_new=(${array1[*]} ${array2[*]})
`两种方式是等价的,选择其一即可。其中,array1 和 array2 是需要拼接的数组,array_new 是拼接后形成的新数组。
示例:
#!/bin/bash
array1=(1 2 3 4 5)
array2=("https://www.baidu.com" "https://www.hehao.online" "https://www.taobao.com")
array_new=(${array1[*]} ${array2[*]})
echo ${array_new[@]}
--->结果
1 2 3 4 5 https://www.baidu.com https://www.hehao.online https://www.taobao.com
7.6 Shell删除数组元素
在Shell中,使用unset关键字来删除数组元素,具体格式如下:
unset array_name[index]
`其中,array_name表示数组名,index表示数组下标
unset array_name
`删除整个数组
7.7 获取数组某范围的元素
在Shell中直接通过${数组名[@/*]:起始位置:长度}获取数组给定范围内元素,返回字符串,中间用空格分开
#!/bin/bash
array=(yoona lucy tom)
echo ${array[*]}
echo ${array[*]:1:2}
echo ${array[@]:0:2}
-->结果为:
yoona lucy tom
lucy tom
yoona lucy
7.7 数组元素的替换
${数组名[@/*]/查找字符/替换字符}该操作不会改变原先数组内容,如果需要修改,使用覆盖
#!/bin/bash
array=(yoona lucy tom)
echo ${array[@]/lucy/lily}
echo ${array[*]}
--->结果为:
yoona lily tom
yoona lucy tom
7.8 关联数组
Bash支持关联数组,它可以使用字符串作为数组索引,有时候采用字符串索引更容易理解
7.8.1 定义关联数组
首先需要使用声明语句declare将一个变量声明为关联数组
# declare -A assArray
声明后,可以有两种方法将添加到关联数组中
1.利用内嵌索引-值列表的方法
# assArray=([lucy]=beijing [yoona]=shanghai)
# echo ${assArray[lucy]}
--->结果为:
beijing
2.使用独立的索引-值进行赋值
# assArray[lily]=shandong
# assArray[sunny]=xian
# echo ${assArray[sunny]}
-->结果为:xian
7.8.2 列出数组索引
每一个数组都有一个索引用于查找。使用${!数组名[@/*]}获取数组的索引列表
# echo ${!assArray[*]}
# echo ${!assArray[@]}
7.8.2 获取所有键值对
#! /bin/bash
declare -A cityArray
cityArray=([yoona]=beijing [lucy]=shanghai [lily]=shandong)
for key in ${!cityArray[*]}
do
echo "${key} come from ${cityArray[$key]}"
done
--->结果为:
lily come from shandong
yoona come from beijing
lucy come from shanghai
7.9 mapfile命令
7.9.1 mapfile命令介绍
mapfile命令用于从标准输入读取行并赋值到数组
7.9.2 mapfile语法结构
mapfile [-d delim] [-n count] [-O origin] [-s count] [-t] [-u fd] [-C callback] [-c quantum] [array]
选项介绍
`-d delim :将delim设为行分隔符,代替默认的换行符
`-n count :从标准输入中获取最多的count行,如果count为0那么获取全部
`-O origin:从数组下标为origin的位置开始赋值,默认的下标为0
`-s count: 跳过对前count行的读取
`-t : 读取时移除分隔符delim(默认为换行符)
`-u fd:从文件描述符fd中读取
`-C callback:每当读取了quantum行时,调用callback语句
`-c quantum:设定读取的行数为quantum
`array(可选):用于输出的数组名称。如果没有指定数组名称,那么会默认写入到变量名为MAPFILE的数组中
# 如果使用-C时没有同时使用-c指定quantum的值,那么quantum默认为5000。
#当callback语句执行时,将数组下一个要赋值的下标以及读取的行作为额外的参数传递给callback语句。
#如果使用-O时没有提供起始位置,那么mapfile会在实际赋值之前清空该数组
7.9.3 使用示例
`dns_list.txt
www.baidu.com
www.taobao.com
www.douyin.com
www.4399.com
[root@localhost Shell_Study]# mapfile array < dns_list.txt
[root@localhost Shell_Study]# echo ${#array[*]}
4
[root@localhost Shell_Study]# echo ${array[#]}
[root@localhost Shell_Study]# echo ${array[@]}
www.baidu.com www.taobao.com www.douyin.com www.4399.com
8.Shell中的函数
8.1 Shell函数的定义
Shell函数的本质是一段可以重复使用的脚本代码,这段代码被提前编好了,放在了指定位置,使用时直接调用即可
Shell 中的函数和C++、Java、Python、C# 等其它编程语言中的函数类似,只是在语法细节有所差别。
Shell 函数定义的语法格式如下:
function name() {
statements
[return value]
}
对各个部分的说明:
function是 Shell 中的关键字,专门用来定义函数;name是函数名;statements是函数要执行的代码,也就是一组语句;return value表示函数的返回值,其中 return 是 Shell 关键字,专门用在函数中返回一个值;这一部分可以写也可以不写。
由{ }包围的部分称为函数体,调用一个函数,实际上就是执行函数体中的代码。
函数定义的简化写法
1.
name() {
statements
[return value]
}
2.
function name {
statements
[return value]
}
8.2 Shell函数的调用
调用 Shell 函数时可以给它传递参数,也可以不传递。如果不传递参数,直接给出函数名字即可:
name
如果传递参数,那么多个参数之间以空格分隔:
name param1 param2 param3
不管是哪种形式,函数名字后面都不需要带括号。
和其它编程语言不同的是,Shell 函数在定义时不能指明参数,但是在调用时却可以传递参数,并且给它传递什么参数它就接收什么参数。
8.3 Shell函数详解
Shell中的函数在定义时不能指明参数,但是在调用时却可以传递参数。函数参数是Shell位置参数的一种,在函数内部可以使用$n来接收,例如:$1表示第一个参数,$2表示第二个参数,依次类推
除了$n,还有另外三个比较重要的变量:
$#可以获取传递的参数的个数;$@或者$*可以一次性获取所有的参数
扩展:在Shell中 @ 与 @与 @与*的区别
在Shell脚本中,$*和$@是Shell脚本的特殊变量,作用都是获取传递给脚本或函数的所有参数
$@与$*的相同点:当它们没有被双引号包裹时,两者是没有区别的,都代表一个包含接收到的所有参数的数组,各个数组元素都是传入的独立参数
$@与$*的不同点:当被双引号包裹时,$@仍为一个数组,而$*会将所有参数整合成一个字符串
9.Shell高级
9.1 echo 带颜色输出
9.1.1 echo命令介绍
`语法:
echo [-ne] [字符串]/echo [--help] [--version]
补充说明:echo会将输入的字符串送往标准输出。输出的字符串加以空白字符隔开,并在最后加上换行符
参数:
-n:不要再最后自动换行
-e:打开反斜杠ESC转义。若字符串出现以下字符,则特别加以处理,而不会将它当成一般文字输出:
\a:发出警告声
\b:删除前一个字符
\c:最后不加上换行符号
\f:换行光标仍停留在原来的位置
\n:换行且光标移至行首
\r:光标移至行首,但不换行
\t:插入tab
\v与\f相同
\\:插入\
\nnn:插入nnn(八进制)所代表的ASCII字符
-E:取消反斜杠ESC转义
-help:显示帮助
-version:显示版本信息
9.1.2 使用echo达到输出有颜色字体的效果
echo -e "\e[背景底色号码;字体颜色号码m 文本内容 \e[0m"
echo -e "\033[背景;字体颜色m 字符串\033[0m"
`扩展:使用printf显示颜色字体
printf "\e[背景底色号码;字体颜色号码m 格式化输出符号 \e[0m" "文本内容"
显示黑色背景绿色字体
printf "\e[40;32m %s\n \e[0m" "hello world"
对应的颜色范围:
字体背景颜色范围 40-47
40:黑
41:深红
42:绿
43:黄色
44:蓝色
45:紫色
46:深绿
47:白色
字基本颜色号码 30-37
30:黑
31:红
32:绿
33:黄
34:蓝色
35:紫色
36:深绿
37:白色
字体高亮颜色号码 90-97
90:黑
91:红
92:绿
93:黄
94:蓝色
95:紫色
96:深绿
97:白色
字背景颜色范围 40-47
40:黑
41:深红
42:绿
43:黄色
44:蓝色
45:紫色
46:深绿
47:白色
还有一些特殊的颜色
\33[0m 关闭所有属性
\33[1m 设置高亮度
\33[4m 下划线
\33[5m 闪烁
\33[7m 反显
\33[8m 消隐
\33[30m — \33[37m 设置前景色
\33[40m — \33[47m 设置背景色
\33[nA 光标上移n行
\33[nB 光标下移n行
\33[nC 光标右移n行
\33[nD 光标左移n行
\33[y;xH设置光标位置
\33[2J 清屏
\33[K 清除从光标到行尾的内容
\33[s 保存光标位置
\33[u 恢复光标位置
\33[?25l 隐藏光标
\33[?25h 显示光标
9.2 Shell的八大扩展功能
9.2.1 花括号
在shell脚本中,可以使用括号对字符串进行扩展,我们可以在一对花括号中包含一组以分号分隔的字符串或者字符串序列组成一个字符串扩展,注意最终输出结果以空格分隔,使用该扩展花括号不可以被引号引用,花括号的数量必须是偶数个
[root@localhost ~]# echo {1,5} #对字符串进行扩展
1 5
[root@localhost ~]# echo {hello,world} #对字符串进行扩展
hello world
[root@localhost ~]# echo {a..z} #对字符串序列进行扩展
a b c d e f g h i j k l m n o p q r s t u v w x y z
#字符串后面可以跟一个步长整数,默认为1或-1
[root@localhost ~]# echo {a..z..2}
a c e g i k m o q s u w y
[root@localhost ~]# echo {a..z..3}
a d g j m p s v y
[root@localhost ~]# echo {1..9..3}
1 4 7
[root@localhost ~]# echo {1..9..2}
1 3 5 7 9
[root@localhost ~]# echo "{a..z}" #花括号扩展不能使用引号
{a..z}
[root@localhost ~]# echo t{i,o}p #花括号前后都可以添加可选字符串
tip top
[root@localhost ~]# echo t{o,e{a,m}}p #花括号支持嵌套
top teap temp
#花括号批量操作
[root@localhost ~]# mkdir -p t{o,e{a,m}}p
[root@localhost ~]# touch t{o,e{a,m}}p/{a,b,c,d}e.txt
9.2.2 波浪号
波浪号在Shell脚本中默认代表当前用户家目录
[root@localhost /]# echo ~ #显示当前用户的家目录
/root
[root@localhost /]# echo ~/elk
/root/elk
[root@localhost /]# echo ~elk #显示特定用户的家目录,该用户必须存在
/home/elk
[root@localhost /]# echo ~+ #显示当前工作目录
/
[root@localhost /]# echo ~- #显示前一个工作目录
/root
9.2.3 变量替换
在Shell脚本中我们会使用 对变量进行扩展替换,变量字符可以放到花括号中,这样可以防止需要扩展的变量字符与其他不需要扩展的字符混淆,如果 对变量进行扩展替换,变量字符可以放到花括号中,这样可以防止需要扩展的变量字符与其他不需要扩展的字符混淆,如果 对变量进行扩展替换,变量字符可以放到花括号中,这样可以防止需要扩展的变量字符与其他不需要扩展的字符混淆,如果后面是位置变量且多余一个数字,必须使用{}
[root@localhost ~]# a="hello word"
[root@localhost ~]# echo $a
hello word
[root@localhost ~]# echo ${a}
hello word
[root@localhost ~]# b=a
[root@localhost ~]# echo ${b} #直接返回变量的值
a
[root@localhost ~]# echo ${!b} #间接引用a变量的值
hello word
[root@localhost ~]# c=b
[root@localhost ~]# echo ${!c} #尽可以实现一层简介引用
a
变量替换操作还可以测试变量是否存在及是否为空,若变量不存在或为空,则可以为变量设置一个默认值
Shell脚本支持多种形式的变量测试与替换功能,如下表所示
| 语法格式 | 功能描述 |
|---|---|
| ${变量:-关键字} | 如果变量未定义或为空,则返回关键字,否则返回变量值 |
| ${变量:=关键字} | 如果变量未定义或为空,则将关键字赋值给变量,并返回结果,否则直接返回变量值 |
| ${变量:?关键字} | 如果变量未定义或为空,则通过标准错误显示包含关键字的错误信息,否则返回变量值 |
| ${变量:+关键字} | 如果变量未定义或为空,则直接返回空,否则返回关键字 |
[root@localhost ~]# echo $bb
[root@localhost ~]# echo ${bb:-bbb}
bbb
[root@localhost ~]# echo $bb
[root@localhost ~]# echo ${bb:=bbb}
bbb
[root@localhost ~]# echo $bb
bbb
此外,变量替换还有非常实用的字符串切割与掐头去尾功能
偏移量起始值为0
| 语法格式 | 功能描述 |
|---|---|
| ${变量:偏移量} | 从变量的偏移量位置开始,切割截取变量的值到结尾 |
| ${变量:偏移量:长度} | 从变量的偏移量位置开始,切割截取特定长度的变量值 |
| ${变量#关键字} | 用关键字对变量进行模式匹配,从左到右删除匹配到的内容,关键字可以用*表示,使用#匹配时为最短匹配 |
| ${变量##关键字} | 用关键字对变量进行模式匹配,从左到右删除匹配到的内容,关键字可以用*表示,使用##匹配时为最长匹配 |
| ${变量%关键字} | 用关键字对变量进行模式匹配,从右到左删除匹配到的内容,关键字可以用*表示,使用%匹配时为最短匹配 |
| ${变量%%关键字} | 用关键字对变量进行模式匹配,从右到左删除匹配到的内容,关键字可以用*表示,使用%%匹配时为最长匹配 |
这几种变量替换方式,都不会改变原变量的值
#!/bin/bash
#!/bin/bash
home="hello world linux java spring"
echo ${home:2}
#llo world linux java spring
echo ${home:2:5}
#llo w
echo ${home#he}
# lo world linux java spring
echo ${home#*ja}
# va spring
echo ${home##*r}
# ing
echo ${home%ing}
# hello world linux java spr
echo ${home%i*}
# hello world linux java spr
echo ${home%%i*}
# hello world l
变量内同的统计与替换
| 语法格式 | 功能描述 |
|---|---|
| ${!前缀字符*} | 查找以指定字符开头的变量名称,变量名之间使用IFS分隔 |
| ${!前缀字符@} | 查找已指定字符开头的变量名称,@在引号中将被扩展为独立的单词 |
| ${!数组名称[*]]} | 列出数组中所有下标,*在引号中被扩展为一个整体 |
| ${!数组名称[@]]} | 列出数组中所有下标,@在引号中被扩展为独立的单词 |
| ${#变量} | 统计变量的长度,变量可以是数组 |
| ${变量/旧字符串/新字符串} | 将变量中的旧字符串替换为新字符串,仅替换第一个 |
| ${变量//旧字符串/新字符串} | 将变量中的旧字符串替换为新字符串,替换所有 |
| ${变量^匹配字符} | 将变量中的小写替换为大写,仅替换第一个 |
| ${变量^^匹配字符} | 将变量中的小写替换为大写,替换所有 |
| ${变量,匹配字符} | 将变量中的大写替换为小写,仅替换第一个 |
| ${变量,匹配字符} | 将变量中的大写替换为小写,替换所有 |
9.2.4 命令替换
#我们可以通过$(命令)或`命令`方式实现替换
[root@localhost /]# echo -e "$(date +%Y-%m-%d;uptime)"
2021-07-14
23:47:56 up 29 days, 4:12, 1 user, load average: 0.36, 0.18, 0.14
[root@localhost /]# echo "系统登录人数:$(who | wc -l)"
系统登录人数:1
[root@localhost /]# echo "系统登录人数:`who | wc -l`"
系统登录人数:1
9.2.5 算数替换
通过算数替换阔可以进行算数计算并返回计算结果,算数替换扩展的格式为$(()),也可以使用$[]的方式,算数扩展支持嵌套
[root@localhost /]# echo $((i++))
1
[root@localhost /]# echo $((++i))
3
[root@localhost /]# echo $((--i))
2
[root@localhost /]# echo $((18%5)) #取余
3
[root@localhost /]# echo $((2**3)) #幂运算
8
[root@localhost /]# echo $((2>3))
0
[root@localhost /]# echo $((2<3))
1
[root@localhost /]# echo $((2!=3))
1
9.2.6 进程替换
进程替换将进程的返回结果通过命令管道的方式传递给另一个进程
语法格式为:<(命令)或者>(命令)
一旦使用了进程替换功能,系统将会在/dev/fd目录下创建文件描述符文件,通过该文件描述符将进程的输出结果传递给其他进程
Linux系统中可以使用管道将前一个命令输出重定向到文件,但是一旦使用了重定向输出到文件,输出结果无法在屏幕上显示
[root@localhost /]# ls /etc/*.conf > ~/conf.log
[root@localhost /]# cat ~/conf.log
/etc/asound.conf
...后续内容省略...
使用tee命令既可以重定向到文件,又可以在屏幕上显示输出结果
[root@localhost /]# ls /etc/*.conf | tee ~/conf.log
/etc/dracut.conf
...后续内容省略...
[root@localhost /]# cat ~/conf.log
/etc/dracut.conf
...后续内容省略...
9.2.7 单词切割
单词切割又叫做分词,Shell使用IFS变量进行分词处理。如果没有自定义IFS变量,默认为空格,Tab制表符,换行符
[root@localhost ~]# read -p "输入:" x y z
输入:1 2 3
[root@localhost ~]# echo $x
1
[root@localhost ~]# echo $y
2
[root@localhost ~]# echo $z
3
#自定义IFS变量的值
[root@localhost ~]# IFS=$',' read -p "输入:" x y z
输入:4,5,6
[root@localhost ~]# echo $x
4
[root@localhost ~]# echo $y
5
[root@localhost ~]# echo $z
6
9.2.8 路径替换
除非使用set -f禁用路径替换,否则bash会在路径和文件名中搜索*、?和[符号,如果找到了这些符号则进行模式匹配的替换。
使用shopt命令时开启了nocaseglob选项,则bash的进行模式匹配时不区分大小写,默认区分大小写。
此外还可以开启extglob选项,让bash支持扩展通配符。
shopt命令-s选项可以开启特定的Shell属性,-u选项可以关闭特定的Shell属性
[root@localhost shopt]# touch {a,A,b,B}.txt
[root@localhost shopt]# ls a.txt
a.txt
[root@localhost shopt]# shopt -s nocaseglob
[root@localhost shopt]# shopt nocaseglob
nocaseglob on
[root@localhost shopt]# ls B*
b.txt B.txt
[root@localhost shopt]# ls a*
a.txt A.txt
[root@localhost shopt]# shopt -u nocaseglob
[root@localhost shopt]# ls a*
a.txt
[root@localhost shopt]# shopt -s extglob
[root@localhost shopt]# ls !(a.txt|b.txt)
A.txt B.txt
[root@localhost shopt]# shopt -u extglob
[root@localhost shopt]# ls !(a.txt|b.txt)
-bash: !: event not found
basename和dirname:
basename:可以获取一个路径中的文件名
dirname:仅保留路径,删除文件名
9.3 Shell中的expect
9.3.1 expect介绍
expect 是由Don Libes基于Tcl( Tool Command Language )语言开发的,主要应用于自动化交互式操作的场景,借助Expect处理交互的命令,可以将交互过程如:ssh登录,ftp登录等写在一个脚本上,使之自动化完成。尤其适用于需要对多台服务器执行相同操作的环境中,可以大大提高系统管理人员的工作效率。
`expect 的安装
yum -y install expect
9.3.2 expect命令
`语法格式:
expect [选项] [ -c cmds ] [ [ -[f|b] ] cmdfile ] [ args ]
常用选项
-c :从命令行执行expect脚本,默认expect是交互地执行的
-d :可以输出调试信息
expect中相关的命令
spawn:启动新的进程
send:用于向进程发送字符串
expect:从进程接收字符串
interacr:允许用户交互
exp_continue:匹配多个字符串在执行动作后加此命令
set timeout 30:设置超时时间timeout为30s,expect命令阻塞超时时会自动往下继续执行。将timeout配置为-1时表示expect一直阻塞直到与期待的字符串匹配上才继续往下执行。超时时间timeout默认为10s。
[lindex $argv n]:可以在脚本中使用该命令获取在脚本执行时传入的第n个参数。这里argv为传入的参数,另外argv为传入的参数,另外argc表示传入参数的个数,$argv0表示脚本名字。另外我们也可以使用[lrange $argv sn en]命令获取第sn到第en个参数。
9.3.3 expect最常用的语法(tcl语言:模式-动作)
1.expect的单分支语法
[root@localhost ~]# expect
expect1.1> expect "hi" {send "say hi\n"} #捕捉用户输入的hi,然后给用户发送"say hi\n"
hi #这一行是我输入的,由于被我上面定义的语句捕捉到了,下面一行的输出信息就是我之前自定义的
say hi
expect1.2> # 如果不想使用该程序了,可以通过输入"exit"或者ctrl+D来正常退出交互式界面
2.expect的多分支语法
[root@localhost ~]# expect
expect1.1> expect "hi" {send "say hi\n"} "bye" {send "byebye\n"}
bye
byebye
9.3.4 通过实际脚本来理解expect
#!/usr/bin/expect
# 使用expect来解释该脚本
set timeout 30
# 设置超时时间,单位为秒,默认情况下是10s
set host "njdx01.91vps1.com"
#设置远程连接的主机
set port "31026"
#设置SSH端口变量
set username "root"
set pass "Gizakps@1289"
#设置密码
spawn ssh $username@$host -p$port
# spawn:是进入expect环境后才可以执行的expect内部命令,如果没有装expect或者直接在默认的SHELL下执行是找不到spawn命令的。
# 它主要的功能是给ssh运行进程加个壳,用来传递交互指令
expect "*password*" {send "$pass\r"}
#这里的expect也是expect的一个内部命令,这个命令的意思是判断上次输出结果里是否包含"password"的字符串,如果有则立即返回;否则就等待一段时间后返回
interact
#执行完后保持交互状态,把控制权交给控制台,这个时候就可以手工操作了
`特别提醒:该脚本不能通过bash 脚本名来运行,而是需要通过
#chmod +x 脚本名
#./脚本名
在上述的示例中,设计到expect中一个非常重要的概念–模式-动作;即上述expect "*password*" {send "$password\r"}这句代码表达出来的含义。简单的说就是匹配一个模式,就执行对应的做东;匹配到password字符串,就输入密码。你可能回看到这样的代码
expect {
"password"{
send "$pass\r"
exp_continue
}
eof
{
send "eof"
}
}
其中exp_continue表示循环式匹配,通常匹配之后都会退出语句,但如果有exp_continue则可以不断循环匹配,输入多条命令,简化写法。
很多时候,我们需要传递参数到脚本中,现在通过下面这段代码来看看如何在expect中使用参数:
#!/usr/bin/expect
if {$argc < 3} {
puts "Usage:cmd "
exit 1
}
set timeout -1
# 表示expect一直阻塞直到与期待的字符串匹配上才继续往下运行
set host [lindex $argv 0]
set username [lindex $argv 1]
set port [lindex $argv 2]
set pass [lindex $argv 3]
spawn ssh $username@$host -p$port
expect "*password*" {send "$pass\r"}
interact
# 在expect,$argc表示参数个数,而参数值存放在$argv中,比如取第一个参数就是[index $argv 0],以此类推
`特别提醒:该脚本不能通过bash 脚本名来运行,而是需要通过
#chmod +x 脚本名
#./脚本名 参数1 参数2 参数3 参数4
9.3.5 实例
1.传参式登录指定主机
#!/usr/bin/expect -f
set ip [ lindex $argv 0 ]
set pass [ lindex $argv 1 ]
set timeout 10
spawn ssh root@$ip
expect {
"*yes/no" { send "yes\r";exp_continue}
//第一次ssh连接会提示yes/no,自动发送yes
"*password:" { send "$pass\r"}
}
interact
`chmod +x 脚本名
`./脚本名 参数1 参数2
2.利用expect批量ssh互信
#!/bin/bash
# 判断id_rsa密钥文件是否存在
if [ ! -f ~/.ssh/id_rsa ];then
ssh-keygen -t rsa -P "" -f ~/.ssh/id_rsa
# -t
else
echo "id_rsa has created ..."
fi
# 分发到各个节点,这里分发到host文件中的主机中
while read line
do
user=`echo $line | cut -d " " -f 2`
ip=`echo $line | cut -d " " -f 1`
passwd=`echo $line | cut -d " " -f 4`
port=`echo $line | cut -d " " -f 3`
expect <<EOF
set timeout 10
spawn ssh-copy-id $user@$ip -p$port
expect {
"*yes/no" { send "yes\n";exp_continue }
"password" { send "$passwd\n" }
}
expect "password" { send "$passwd\n" }
EOF
done < /root/host.txt
`/root/host.txt
njdx01.91vps1.com root 21062 Gizakps@1289
xadx01.91vps1.com root 26154 Gizakps@1289
dllt01.91vps1.com root 20270 Gizakps@1289
9.4 Shell中的信号捕捉trap
Linux常用命令trap用于指定在接收信号后将要采取的动作,常见的用途是在脚本程序被中断时完成清理工作
9.4.1 Linux信号
信号(IPC)最初是UNIX系统响应某些状况而产生的事件,进程在接收到信号时会采取相应的行动。简单来说信号是操作系统(内核)响应某些条件而产生的一个事件(给进程)。进程之间无法通信,可以使用信号来解决。
信号是由于某些错误条件而生成的,如内存段冲突,浮点处理器错误或非法指令等。他们由 shell 和终端处理器生成来引起中断,他们还可以作为在进程中传递消息或修改行为的一种方式,明确地由一个进程发送给另外一个进程
Linux常见的信号有:
| 信号 | 值 | |
|---|---|---|
| 1 | SIGHP | 挂起进程 |
| 2 | SIGINT | 终止进程 |
| 3 | SIGQUIT | 停止进程 |
| 9 | SIGKILL | 无条件终止进程 |
| 15 | SIGTERM | 尽可能终止进程 |
| 17 | SIGSTOP | 无条件停止进程,但不是终止进程 |
| 18 | SIGTSTP | 停止或暂停进程,但不终止进程 |
| 19 | SIGCONT | 继续运行停止的进程 |
ctrl+c组合键会产生SIGINT信号,ctrl+z组合键会产生SIGTSTP信号
kill -0 pid不发送任何信号,但是系统会进行错误检查。该命令可以用来检查一个进程是否存在,若存在,即进程正在运行,执行echo $?会返回0.若不存在,即进程已停止运行,执行echo $?会返回1
9.4.2 trap命令
trap命令允许你来指定Shell脚本要监视并拦截的Linux信号
`语法格式:
trap commands signal1 [signal2 signal3 ....]
# 如果当前脚本进程收到上述signals信号中的一个,就会执行commands命令
trap '' 信号 # 忽略信号的操作
trap '-' 信号 # 恢复原信号的操作
trap -p # 列出自定义信号操作
trap finish EXIT #当脚本退出时.执行finish函数,当然这个"finish"这个名字可以自定义
脚本示例
#!/bin/bash
trap "echo 'Sorry~I have trapped Ctrl+c'" SIGINT
echo "This is a test script"
count=1
while [ $count -le 10 ];do
echo "Loop $count"
sleep 1
count=$[ $count +1 ]
done
echo "The end"
日常生活中用到的简单脚本案例:
1.自动备份文件或目录:
#!/bin/bash
# 设置备份目录
backup_dir="/path/to/backup/dir"
# 设置要备份的文件或目录
files_to_backup="/path/to/files /path/to/dir"
# 创建一个日期时间戳
timestamp=$(date +%F_%T)
# 备份文件
tar -czvf "${backup_dir}/backup_${timestamp}.tar.gz" ${files_to_backup}
2.批量重命名文件:
#!/bin/bash
# 设置文件扩展名
extension=".txt"
# 遍历当前目录下的所有文件
for file in *${extension}
do
# 获取文件名(不包括扩展名)
filename=$(basename "${file}" "${extension}")
# 重命名文件
mv "${file}" "${filename}_new${extension}"
done
3.批量删除文件
#!/bin/bash
# 设置文件扩展名
extension=".tmp"
# 遍历当前目录下的所有文件
for file in *${extension}
do
# 删除文件
rm "${file}"
done
4.查找并删除指定名称的文件:
#!/bin/bash
# 设置文件名
filename="example.txt"
# 查找并删除文件
find . -name "${filename}" -delete
5.查找并替换文件内容:
#!/bin/bash
# 设置要查找的字符串
search_string="old_string"
# 设置要替换成的字符串
replace_string="new_string"
# 查找并替换文件内容
find . -type f -exec sed -i "s/${search_string}/${replace_string}/g" {} \;
6.批量创建文件:
#!/bin/bash
# 设置文件名前缀
prefix="file"
# 设置文件数量
num_files=10
# 循环创建文件
for i in $(seq 1 ${num_files})
do
touch "${prefix}${i}.txt"
done
7.创建文件夹并移动文件:
#!/bin/bash
# 设置文件夹名称
dir_name="new_dir"
# 设置要移动的文件
files_to_move="file1.txt file2.txt"
# 创建文件夹并移动文件
mkdir ${dir_name} && mv ${files_to_move} ${dir_name}
8.在文件夹中查找文件:
#!/bin/bash
# 设置文件夹路径
dir_path="/path/to/dir"
# 设置文件名
filename="example.txt"
# 在文件夹中查找文件
find ${dir_path} -name "${filename}"
9.计算文件夹中文件数量:
#!/bin/bash
# 设置文件夹路径
dir_path="/path/to/dir"
# 计算文件数量
num_files=$(find ${dir_path} -type f | wc -l)
echo "Number of files in ${dir_path}: ${num_files}"
10.计算文件夹大小:
#!/bin/bash
# 设置文件夹路径
dir_path="/path/to/dir"
# 计算文件夹大小
dir_size=$(du -sh ${dir_path})
echo "Size of ${dir_path}: ${dir_size}"
11.定时执行命令:
#!/bin/bash
# 设置命令
command="echo hello"
# 设置执行周期(以秒为单位)
period=10
# 定时执行命令
while true
do
eval ${command}
sleep ${period}
done
12.发送邮件:
#!/bin/bash
# 设置收件人邮箱
to="[email protected]"
# 设置发件人邮箱
from="[email protected]"
# 设置邮件主题
subject="Test Email"
# 设置邮件内容
body="This is a test email."
# 发送邮件
echo "${body}" | mail -s "${subject}" -r "${from}" "${to}"
13.批量解压缩文件:
#!/bin/bash
# 设置文件扩展名
extension=".tar.gz"
# 遍历当前目录下的所有文件
for file in *${extension}
do
# 解压缩文件
tar -xvzf ${file}
done
14.在文件夹中查找并删除文件:
#!/bin/bash
# 设置文件夹路径
dir_path="/path/to/dir"
# 设置要删除的文件扩展名
extension=".tmp"
# 在文件夹中查找并删除文件
find ${dir_path} -name "*${extension}" -delete
15.批量重命名文件:
#!/bin/bash
# 设置文件扩展名
extension=".old"
# 设置新文件扩展名
new_extension=".new"
# 遍历当前目录下的所有文件
for file in *${extension}
do
# 获取文件名(不包含扩展名)
filename=$(basename "${file}" "${extension}")
# 重命名文件
mv "${file}" "${filename}${new_extension}"
done
16.对文件夹中的文件按修改时间排序:
#!/bin/bash
# 设置文件夹路径
dir_path="/path/to/dir"
# 对文件夹中的文件按修改时间排序
find ${dir_path} -type f -printf "%T@ %p\n" | sort -n
17.批量转换文件格式:
#!/bin/bash
# 设置文件扩展名
extension=".txt"
# 设置新文件扩展名
new_extension=".md"
# 遍历当前目录下的所有文件
for file in *${extension}
do
# 转换文件格
pandoc -s "${file}" -o "${file/${extension}/${new_extension}}"
done
注意:需要先安装Pandoc。
18.删除文件夹中的空文件夹:
#!/bin/bash
# 设置文件夹路径
dir_path="/path/to/dir"
# 删除文件夹中的空文件夹
find ${dir_path} -type d -empty -delete
19.删除文件夹中的空文件:
#!/bin/bash
# 设置文件夹路径
dir_path="/path/to/dir"
# 删除文件夹中的空文件
find ${dir_path} -type f -empty -delete
20.批量更改文件权限:
#!/bin/bash
# 设置文件夹路径
dir_path="/path/to/dir"
# 设置文件权限(以八进制表示)
permission="644"
# 批量更改文件权限
find ${dir_path} -type f -exec chmod ${permission} {} \;
21.使用awk分隔文件
#!/bin/bash
# 本脚本的作用是读取文件中的内容,并对其进行awk分隔输出
# 设置被读取的文件
filename=$1
info=`awk -F " " '{printf "%-8s %-8s %-8s %-8s\n",$2,$4,$5,$6}' $filename`
# 输出awk的内容
printf "异常机器名称为 运营商为 异常地区 异常问题 \n$info"
echo -e " "
从shell脚本中学习文本三剑客
牛客网在线编程_编程学习|练习题_数据结构|系统设计题库 (nowcoder.com)
1.编写一个shell脚本以输出一个文本文件nowcoder.txt中的行数
#include shell脚本如下:
#!/bin/bash
# 使用wc -l 命令查询文件行数,但当文件中包含#开头的行,则表示注释,不算一行
wc -l ./1 | awk '{print $1}'
# 使用grep命令查询文件的行数
grep -n "" ./1 | awk -F ":" '{print $1 }' | tail -n 1
# 使用awk命令查询文件的行数
awk '{print NR}' ./1 |tail -n1 # awk命令可以打印文件的行数,tail -n1 表示读取最后一列
# 使用sed命令查询文件的行数
sed -n '$=' ./1
# 使用cat命令查询文件的行数
cat ./1 | wc -l
2.获取一个目录所有文件的行数
#!/bin/bash
# 获取特定目录所有文件的行数
#!/bin/bash
filesCount=0
linesCount=0
function funCount()
{
for file in ` ls $1 `
do
if [ -d $1"/"$file ];then
funCount $1"/"$file
else
declare -i fileLines
fileLines=`sed -n '$=' $1"/"$file`
let linesCount=$linesCount+$fileLines
let filesCount=$filesCount+1
fi
done
}
if [ $# -gt 0 ];then
for m_dir in $@
do
funCount $m_dir
done
else
funCount "."
fi
echo "filesCount = $filesCount"
echo "linesCount = $linesCount"
# 注释
# $1,$2,... 对应第一个,第二个等参数,shift[n]换位置
# $0 命令本身,包括路径
# $* 传递给脚本的所有参数,全部参数合成一个字符串
# $@ 传递给脚本的所有参数,每个参数为独立字符串
# $# 传递给脚本的参数的个数
3.获取特定目录特定扩展名文件的行数
#!/bin/bash
extens=(".conf" ".html")
filesCount=0
linesCount=0
function funCount()
{
for file in ` ls $1 `
do
if [ -d $1"/"$file ];then
funCount $1"/"$file
else
fileName=$1"/"$file
EXTENSION="."${fileName##*.}
echo "fileName = $fileName Extension = $EXTENSION"
if [[ "${extens[@]/$EXTENSION/}" != "${extens[@]}" ]];then
declare -i fileLines
fileLines=`sed -n '$=' $fileName`
echo $fileName" : "$fileLines
let linesCount=$linesCount+$fileLines
let filesCount=$filesCount+1
fi
fi
done
}
if [ $# -gt 0 ];then
for m_dir in $@
do
funCount $m_dir
done
else
funCount "."
fi
echo "filesCount = $filesCount"
echo "linesCount = $linesCount"
4.写一个 bash脚本以输出数字 0 到 500 中 7 的倍数(0 7 14 21…)的命令
#!/bin/bash
for i in `seq 500`
do
if [[ i%7 -eq 0 ]];then
echo $i
fi
done
for ((j=0;j<=500;j++))
do
if [[ j%7 -eq 0 ]];then
echo $j
fi
done
seq 0 7 500
5.输出指定行的内容
#!/bin/bash
sed -n '5p' $1
awk 'NR==5' $1
6.打印空行的行号
#!/bin/bash
grep -n '^\s*$' $1 | awk -F: '{print $1}'
#注释 grep:用于查找文件里符合条件的字符串 grep ‘字符串/正则表达式’ 文件名:从文件内容查找匹配指定字符串或正则表达式的行 -n:输出的内容带行号 ^:正则里表示行首 $:正则里表示行尾 ‘^$’:表示空行(只有行首和行尾,连空白字符都没有) \s:匹配任何空白字符:包括空格,制表符,换页符等等,等价于[ \f\n\r\t\v],且输出带行号 *:在正则表达式中,表示有0个或多个某个字符 `\s*:表示有0个或多个空白字符 '^\s*$':匹配(含有空白符的)空行 grep -n ‘^\s*$’ nowcoder.txt:输出空白行,每行前有行号 | :管道符,左边命令的输出会作为右边命令的输入 awk:一种处理文本文件的语言,是一个强大的文本分析工具 -F fs:指定文件拆分隔符,fs是一个字符串或一个正则表达式。如 -F : 是用 : 把字符串分隔开来 $n:当前记录的第n个字段,如$1取第一个字段
#!/bin/bash
awk '/^\s*$/{print NR}' $1
awk 'pattern{action}' 文件名:逐行检查文件中内容是否满足pattern,如果满足就执行{}中的操作;如果没有指定操作,则打印与正则表达式匹配的记录。 awk的正则表达式是放在两个正斜杠中间//,由字符组成的模式。 /^\s*$/:就是进行匹配的正则表达式,内部的含义与方法一里说明的一样。 NR:已读记录数,即行号,从1开始。 {print NR}:输出行号
#!/bin/bash
sed -n '/^\s*$/=' $1
sed:依照脚本的指令来处理、编辑文本文件 -n:屏蔽默认输出,仅打印输出脚本处理后的结果 /^\s*$/:跟方法二的说明一样 '=':输出行号
7.去掉空行
cat $1 | tr -s '\n'
cat $1 | sed '/^$/d'
grep -v '^$' $1
cat $1 | awk '{if($0!="")print}'
cat $1 | awk '{if(length!=0)print}'
tr命令: tr -s '\n' 删除文件中的空行 sed命令: sed '/^$/d' 删除文件中的空行 awk命令: awk '{if($0!="")print}' `$0表示整行,如果行不为空的话,就输出 `如果length判断不等于0的话就输出
8.输出一个文本中字母数小于8的单词
#!/bin/bash
cat $1 | tr -s '\n' | tr ' ' '\n' | awk '{if(length>=8)print}'
--------------------------------------------------------------
awk '{
for(i=1;i<=NF;i++)
if(length($i)>=8)
print $i;
}' $1
#NF:整数值,表示当前记录(变量$0所代表的记录)的字段数
#$i:字段变量,其中i为整数,且i大于等于1。表示第i个字段的值
--------------------------------------------------------------
awk 'BEGIN{FS=" ";RS=" ";OFS="/n"}{if(NF<8)print$0}' ./1
#FS:输入分隔符,与-F分隔符一样
#RS:输入记录分隔符
#OFS:输出字段分隔符,默认为"/n"
--------------------------------------------------------------
for s in $(cat $1)
do
if [ ${#s} -lt 8 ]
then
echo $s
fi
done
#${#s}表示字符s的长度数值
--------------------------------------------------------------
cat $1 | xarges -n 1 | awk '{if(length<8)print}'
# 表示每行输出一个字符后就换行
9.统计所有进程占用内存百分比的和
ps aux > 1
echo `cat ./1 | tr -s ' ' | cut -d ' ' -f 4 |grep -v "%MEM"| tr '\n' '+'`0|bc
----------------------------------------------------------------------------------------------------------------------------
echo `ps aux | tr -s ' ' | cut -d ' ' -f 4 | grep -v "%MEM" | tr '\n' '+'` 0 | bc
#tr -s ' ' 删除重复出现的空格,只保留一个
#cut -d ' ' -f 6 提取第6列的数据
echo `ps aux | awk -F " " '{print $4}' | grep -v "%MEM" | tr '\n' '+'`0 | bc
----------------------------------------------------------------------------------------------------------------------------
ps aux | awk '{sum+=$4} END{print sum}'
----------------------------------------------------------------------------------------------------------------------------
ps aux | awk -F " " '{print $4}' |grep -v "%MEM"|xargs|sed 's/\ /+/g' | bc
10.统计每个单词出现的个数
`1
welcome nowcoder
welcome to nowcoder
nowcoder
----------------------------------------------------------------------------------------------------------------------------
cat $1 | xargs -n1 | sort | uniq -c | sort -n | awk -F " " '{print $2,$1}'
#sort 及其参数
-n是按照数字大小排序
-r是以相反顺序
-k是指定需要排序的栏位
-t指定栏位分隔符为冒号
11.第二列是否有重复
`1
20201001 python 99
20201002 go 80
20201002 c++ 88
20201003 php 77
20201001 go 88
20201005 shell 89
20201006 java 70
20201008 c 100
20201007 java 88
20201006 go 97
----------------------------------------------------------------------------------------------------------------------------
cat $1 | sort -rk 2 | awk -F " " '{print $2}' |sort |uniq -c|sort | grep -v 1
- 转置文件的内容
`1
job salary
c++ 13
java 14
php 12
----------------------------------------------------------------------------------------------------------------------------
#!/bin/bash
# 从shell脚本中学习文本三剑客
n=`cat $1 | wc -l`
# echo $n
cat $1 | awk -F " " '{print $1}'|xargs -n$n
cat $1 | awk -F " " '{print $2}' | xargs -n$n
13.打印每一行出现的数字(1~5)个数
`1
a12b8
10ccc
2521abc
9asf
----------------------------------------------------------------------------------------------------------------------------
#!/bin/bash
# 从shell脚本中学习文本三剑客
awk -v sum=0 '{
gsub(/[^1-5]/,"",$0);
print "line"NR" number: "length;
sum+=length
}
END{
print "sum is "sum
}' $1
#awk -v 指定变量和默认值
#NR代表第几行
----------------------------------------------------------------------------------------------------------------------------
sed s/[^1-5]//g $1 | awk '{print "line"NR" number: "length; total+=length} END{print "sum is "total}'
14.去掉所有包含this的句子
#!/bin/bash
# 从shell脚本中学习文本三剑客
# grep命令过滤
cat $1 | grep -v "this"
# awk命令过滤
awk '$0!~/this/ {print $0}' $1
# $0:表示整行
# !~:不匹配正则表达式
# ~:匹配正则表达式
# 输出整行中不包含this的行
# sed命令过滤
sed '/this/d' $1
# 删除包含this的行
15.输入的一个数组的平均值
read -p "请输入数组长度" a
read -p "请分别输入数组元素" -a array
# echo ${#array[@]}
if [ "${#array[@]}" -ne "$a" ]
then
echo "输入的数组元素数量错误";
else
sum=0;
for ((i=0;i<$a;i++));
do
echo ${array[$i]};
let sum+=${array[$i]};
done
# echo $sum;
echo "scale=2;$sum/$a"|bc
fi