SQL Server中的报表–如何使用数据透视表和日期计算来获取有价值的报表
介绍 (Introduction)
A few months back I had been working on an interesting proof of concept for a human resources client (Mary Smith) who is the HR manager in a major hardware chain. The firm has a “ServiceNow” installation, with tables that stores employee ”hours worked”.
几个月前,我一直在为一个人力资源客户(玛丽·史密斯)(一个主要硬件链中的人力资源经理)研究一个有趣的概念证明。 该公司安装了“ ServiceNow”,其表存储了员工的“工作时间”。
These hours are stored within the “Time Card” table and each employee has two rows within the table for each week. One row is for billable activities and the other for non-billable activities (such as travel and vacation time and getting to the customer site)
这些时间存储在“时间卡”表中,每个员工每周有两行在表中。 一行用于收费活动,另一行用于非收费活动(例如旅行和休假时间以及到达客户现场)
Weeks begin on Sunday and end on Saturday. Oft times these weekly records run cross month ends which as the reader can understand prove to be a big challenge when it comes to creating corporate reports.
星期几从星期日开始,到星期六结束。 这些每周记录通常在跨月结束时运行,读者可以理解,这对创建公司报告是一个巨大的挑战。
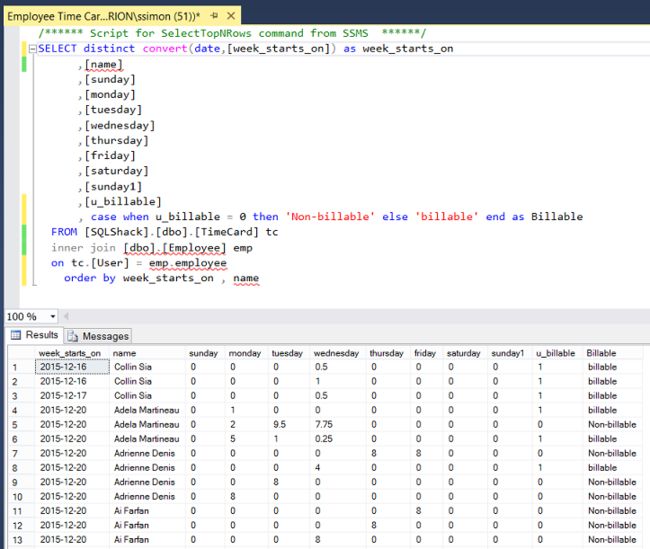
A sample of this ‘cacophony’ may be seen below:
以下是这种“共鸣”的示例:

In today’s “fireside chat” we shall be developing the necessary queries and reports that will permit Mary to extract the necessary data on a fiscal month to month basis in order to provide senior management with the vital profit and loss information.
在今天的“炉边聊天”中,我们将开发必要的查询和报告,使Mary可以逐月提取必要的数据,以便为高级管理层提供重要的损益信息。
Thus, let’s get started.
因此,让我们开始吧。
入门 (Getting started)
Opening SQL Server Management Studio, we open the SQLShack database. The query below provides the necessary raw data which is sourced from the “Employee” and “TimeCard” tables. We shall be working with this data.
打开SQL Server Management Studio,我们打开SQLShack数据库。 下面的查询提供了必要的原始数据,这些原始数据来自“ Employee”和“ TimeCard”表。 我们将使用此数据。
Opening a new query we declare a few variables (see below).
打开一个新查询,我们声明一些变量(见下文)。

We declare a start and an end date variable (as may be seen above) and set the start of the period and the end of the period. Once complete and implemented, the start and end dates will be passed from the front end report to the stored procedure which we shall create from the code that we are developing.
我们声明一个开始日期和一个结束日期变量(如上所示),并设置时间段的开始和时间段的结束。 一旦完成并实施,开始日期和结束日期将从前端报告传递到存储过程,该存储过程将由我们正在开发的代码创建。
As our point of departure, we create a small query that will decide which records we are looking for based on the user-defined start and end dates.
作为出发点,我们创建一个小查询,该查询将根据用户定义的开始日期和结束日期来确定要查找的记录。
We remember that the start and end dates will be any day within a given weekly record. Dates that are colored green are the dates that we require (see below). Thus for the period 1/1/2016 through 1/31/2016 we require the “start” records shown below:
我们记得开始和结束日期将是给定的每周记录中的任何一天。 绿色标记的日期是我们要求的日期(请参见下文)。 因此,从2016年1月1日到2016年1月1日,我们需要如下所示的“开始”记录:
| WeekStartsON | Sunday | Monday | Tuesday | Wednesday | Thursday | Friday | Saturday |
| 12/27/2015 | 12/27/2015 | 12/28/2015 | 12/29/2015 | 12/30/2015 | 12/31/2015 | 1/1/2016 | 1/2/2016 |
| WeekStartsON | 星期日 | 星期一 | 星期二 | 星期三 | 星期四 | 星期五 | 星期六 |
| 2015年12月27日 | 2015年12月27日 | 2015年12月28日 | 2015年12月29日 | 2015年12月30日 | 2015年12月31日 | 2016年1月1日 | 2016年1月1日 |
PLUS all records up until and including the end record, shown below.
加上所有记录,直到并包括最终记录,如下所示。
| WeekStartsON | Sunday | Monday | Tuesday | Wednesday | Thursday | Friday | Saturday |
| 1/31/2016 | 1/31/2016 | 2/1/2016 | 2/2/2016 | 2/3/2016 | 2/4/2016 | 2/5/2016 | 2/6/2016 |
| WeekStartsON | 星期日 | 星期一 | 星期二 | 星期三 | 星期四 | 星期五 | 星期六 |
| 2016/1/31 | 2016/1/31 | 2016/2/1 | 2016/2/2 | 2016/2/3 | 2016/2/4 | 2016/2/5 | 2016/2/6 |
Our first task is to find the date of the SUNDAY immediately before our start date. As discussed immediately above, all records within the time card table start on a Sunday. In this case, as we are looking at 1/1/2016 as a start date and because 1/1/2016 is NOT a Sunday, we go back in time to ascertain the date of the Sunday, immediately before 1/1/2016 which turns out to be 12/27/2015 as may be seen in the screenshot below. The code to perform the necessary calculation may also be found below the screen shot.
我们的第一个任务是找到紧接开始日期之前的SUNDAY的日期。 正如上面刚刚讨论过的,时间表表中的所有记录都是从星期日开始的。 在这种情况下,由于我们将1/1/2016作为开始日期,并且因为1/1/2016不是星期日,所以我们会及时返回以确定1/1/2016之前的星期日的日期如下面的屏幕截图所示,结果为2015年12月27日。 屏幕截图下方也提供了执行必要计算的代码。

Set @SStartdate = (Select case when DATEPART(dw,@startdate) <> 1 then dateadd(d,(DATEPART(dw,@startdate)-1) *-1,@startdate)
else @StartDate end )
Our next task is to calculate the Saturday immediately after the end date. The end date is 1/31/2016. This date is a Sunday and to be all inclusive we must find the Saturday immediately after this date. This being 2/6/2016 as may be seen in the screen dump below. The code to ascertain this is also below the screenshot.
我们的下一个任务是计算结束日期之后的星期六。 结束日期是2016年1月1日。 这个日期是星期天,并且要包容各方,我们必须在该日期之后 立即找到星期六。 如下面的屏幕转储所示,这是2/6/2016。 屏幕截图下方还提供了确定代码。

Set @EEnddate = (Select case when DATEPART(dw,@enddate) <> 7 then dateadd(d,(DATEPART(dw,@enddate)-1)*-1 ,@enddate)
else dateadd(d,-6,@endDate) end )
Select @EEnddate
Thus the first time card for each employee will be, for the week of December 27th 2015 and the last time card being for the week of January 31st 2016 (ending Saturday Feb 6th).
因此,每位员工的第一张考勤卡为2015年12月27 日那一周,最后一张为2016年1月31 日那一周(截至2月6 日星期六)。
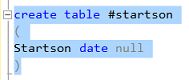
We now create a temporary table called #startson which will contain unique values of the suite of “Week_starts_on” that we are required to process (see above).
现在,我们创建一个名为#startson的临时表,该表将包含我们需要处理的“ Week_starts_on”套件的唯一值(请参见上文)。
填充我们的#startson表 (Populating our #startson table)

Utilizing a “while” loop, we insert the first date (our Sunday on or prior to the start date) into our #startson table. We then add 7 days to this date and the cycle begins again. The”trip –out” being when the incremented date is greater than the actual end date (provided by the client via the report).
利用“ while”循环,我们将第一个日期(开始日期或之前的星期日)插入我们的#startson表。 然后,我们将7天添加到该日期,并且周期再次开始。 “跳出”是指增加的日期大于实际的结束日期(由客户通过报告提供)。
Running this code snippet we find that we must consider records with the following Sunday’s as “week_starts_on” values:
运行此代码段,我们发现我们必须将以下星期日的记录视为“ week_starts_on”值:

Having obtained both the start of period and end of period dates, we are now in a position to pull the actual time card data including the “Week_starts_on” column and place these records into another temporary table.
在获得期间开始日期和期间结束日期之后,我们现在可以提取包括“ Week_starts_on”列在内的实际时间卡数据,并将这些记录放入另一个临时表中 。

Now that we have the necessary data within our temporary table(s), we are in a position to manipulate the data and assemble it in a convenient fashion, utilizing a pivot table. The first and most important task is to rotate the data from this format
现在我们已经在临时表中有了必要的数据,现在我们可以使用数据透视表来操纵数据并以方便的方式组合起来。 第一项也是最重要的任务是旋转此格式的数据
| WeekStartsOn | Sunday | Monday | Tuesday | Wednesday | Thursday | Friday | Saturday |
| 12/27/2015 | 2 hours | 3 | 1 | 8 | 9 | 4 | 2 |
| WeekStartsOn | 星期日 | 星期一 | 星期二 | 星期三 | 星期四 | 星期五 | 星期六 |
| 2015年12月27日 | 2小时 | 3 | 1个 | 8 | 9 | 4 | 2 |
To this format
以此格式
| Week Starts On | Day of week | Hours Entered | DayEnteredNumber |
| 12/27/2015 | Sunday | 2 | 1 |
| 12/27/2015 | Monday | 3 | 2 |
| 12/27/2015 | Tuesday | 1 | 3 |
| 12/27/2015 | Wednesday | 8 | 4 |
| 12/27/2015 | Thursday | 9 | 5 |
| 12/27/2015 | Friday | 4 | 6 |
| 12/27/2015 | Saturday | 2 | 7 |
| 一周开始 | 星期几 | 输入的小时数 | DayEnteredNumber |
| 2015年12月27日 | 星期日 | 2 | 1个 |
| 2015年12月27日 | 星期一 | 3 | 2 |
| 2015年12月27日 | 星期二 | 1个 | 3 |
| 2015年12月27日 | 星期三 | 8 | 4 |
| 2015年12月27日 | 星期四 | 9 | 5 |
| 2015年12月27日 | 星期五 | 4 | 6 |
| 2015年12月27日 | 星期六 | 2 | 7 |
The code to achieve this may be seen in the screenshot below PLUS the code sample itself may be found in Addenda 1.
可以在下面的屏幕快照中看到实现此目的的代码,此外,可以在附录1中找到代码示例本身。

The astute reader will note the inner join of the main body of the code to the #startson temporary table that we created and populated above. This is an important fact, as the join (as discussed above) acts as a query predicate to ensure that we are pulling only those weekly time card relative to the period under consideration.
精明的读者会注意到代码主体与我们在上面创建并填充的#startson临时表的内部连接 。 这是一个重要的事实,因为联接(如上所述) 充当了查询谓词,以确保我们只提取相对于所考虑时期的那些每周时间卡。
Our next task is to obtain the actual date upon which the hours were booked. Through the usage of the field “week_starts_on” and the field “dayenterednum”, we are able to calculate the proper calendar date.
我们的下一个任务是获取预订小时数的实际日期。 通过使用“ week_starts_on”字段和“ dayenterednum”字段,我们能够计算正确的日历日期。
In order to achieve this, we add one small piece of code to our query. This code utilizes the SQL Server date function “dateadd” (see below).
为了实现这一点,我们向查询添加了一小段代码。 此代码利用SQL Server日期函数“ dateadd”(请参见下文)。
,case when dayenterednum = 1 then dateadd(d,1,week_starts_on)
when dayenterednum = 2 then dateadd(d,2,week_starts_on)
when dayenterednum = 3 then dateadd(d,3,week_starts_on)
when dayenterednum = 4 then dateadd(d,4,week_starts_on)
when dayenterednum = 5 then dateadd(d,5,week_starts_on)
when dayenterednum = 6 then dateadd(d,6,week_starts_on) else week_starts_on
end as truedate
Running our query again, (after having included this piece of code) we note the new field called “truedate”(see below). This field contains the actual calendar date for this field.
再次运行我们的查询(在包含了这段代码之后),我们注意到一个名为“ truedate”的新字段(请参见下文)。 该字段包含此字段的实际日历日期。

Now that we have our actual date field, all that remains to be done is to set the extraction predicate to pull “truedates” between the start and end date (see below).
现在我们有了实际的日期字段,剩下要做的就是将提取谓词设置为在开始日期和结束日期之间提取“ truedates”(请参见下文)。

Now that our coding is complete, our very last task is to create a stored procedure from our code. From the reports (that we are going to create), the user will pass a start and end date to our stored procedure.
现在我们的编码已经完成,我们的最后一个任务是从我们的代码创建存储过程。 从报告(我们将要创建的报告)中,用户将开始日期和结束日期传递给我们的存储过程。
报告中 (Reporting)
In order to create our report, we open either Visual Studio 2015 or SQL Server Data Tools 2010 or greater. Should you have never worked with Reporting Services or should you not feel comfortable creating a Reporting Services project, then please do have a look at one of our earlier chats where the “creation” process is described in detail.
为了创建我们的报告,我们打开Visual Studio 2015或SQL Server Data Tools 2010或更高版本。 如果您从未使用过Reporting Services,或者您对创建Reporting Services项目感到不自在,请查看我们之前的聊天中详细描述“创建”过程的内容。
Beer and the tabular model DO go together
啤酒和表格模型DO在一起
We begin by creating a new Reporting Services project. We shall call our project “TimeCard”.
我们首先创建一个新的Reporting Services项目。 我们将我们的项目称为“ TimeCard”。
Our design surface is brought into view (see below).
我们的设计图面可见(见下文)。

As we have done in our past “get togethers”, we create a shared data source which we call “TimeCardDataSource” (see below).
正如我们过去“聚在一起”所做的那样,我们创建了一个共享数据源,我们将其称为“ TimeCardDataSource”(见下文)。
Having created our new shared data source, our next task is to create a new report.
创建了新的共享数据源之后,我们的下一个任务是创建一个新报告。
We right click on the “Report” tab and select “Add” and “New Item” (see below).
我们右键单击“报告”选项卡,然后选择“添加”和“新项目”(见下文)。

We are brought to the “Add New Item” menu. We select “Report” and give our report a name (see below).
我们被带到“添加新项”菜单。 我们选择“报告”并给我们的报告起一个名字(见下文)。

We click “Add” and we are returned to the drawing surface of our new report.
单击“添加”,然后返回到新报告的图形表面。

Our next task is to create a start date and an end date parameter.
我们的下一个任务是创建开始日期和结束日期参数。
创建必要的参数 (Creating the necessary parameters)
In order for our query to function correctly, we are required to pass a valid start and end date to the stored procedure. As discussed above we shall now create two parameters to do just this. We right-click on the Parameters tab and select “Add Parameter” (see below).
为了使查询正常运行,我们需要将有效的开始日期和结束日期传递给存储过程。 如上所述,我们现在将创建两个参数来执行此操作。 我们右键单击“参数”选项卡,然后选择“添加参数”(见下文)。

The “Report Parameter Properties” dialogue box is brought up (see below).
出现“报告参数属性”对话框(见下文)。

We name our parameter “startdate” and set the data type to date / time (see above).
我们将参数命名为“ startdate”,并将数据类型设置为日期/时间(请参见上文)。
We click “OK” to create the parameter.
我们单击“确定”以创建参数。
We repeat the same process to create our “enddate” parameter. Our working surface and parameter frame should appear as follows.
我们重复相同的过程来创建“ enddate”参数。 我们的工作表面和参数框架应如下所示。

Finally, we require two local datasets. Before we do this, we are reminded that Mary would like to see two matrices on the report surface. One showing billable hours and the other non-billable hours, hence the need for two local datasets.
最后,我们需要两个本地数据集。 在执行此操作之前,请注意,玛丽希望在报表表面上看到两个矩阵。 一个显示计费小时,另一个显示非计费小时,因此需要两个本地数据集。
创建我们的本地数据集 (Creating our LOCAL datasets)
As we shall have two matrices for Mary’s report, one showing billable hours and the other the non-billable hours, we are forced to apply different filters to each matrix. The astute reader will remember seeing a field called “u_billable”. This field is a boolean, 0 being non-billable and 1 being billable.
由于我们将为Mary的报告提供两个矩阵,一个矩阵显示可计费时间,另一个矩阵显示非计费时间,因此我们被迫对每个矩阵应用不同的过滤器。 精明的读者会记得看到一个名为“ u_billable”的字段。 此字段为布尔值,0为不可计费,1为可计费。
创建可计费的本地数据集 (Creating the billable local dataset)

We right click upon the “Dataset” folder and select “Add (local) dataset” as shown above.
我们右键单击“数据集”文件夹,然后选择“添加(本地)数据集”,如上所示。

We opt to “Use a dataset embedded in my report” and click on the new button to create a new local data source which will utilize the shared data source which we created above.
我们选择“使用嵌入到我的报表中的数据集”,然后单击“新建”按钮以创建一个新的本地数据源,该数据源将利用我们上面创建的共享数据源。
Clicking “New”, the “Data Source Properties” dialog box opens. We opt to utilize the “Shared data source reference” as shown below. We click OK to exit this dialogue box.
单击“新建”,将打开“数据源属性”对话框。 我们选择利用“共享数据源参考”,如下所示。 我们单击确定退出此对话框。

We are returned to our report surface with the “Dataset Properties” dialogue box showing. We select “Stored Procedure “ for the query type, choose our stored procedure, and then click the “Refresh Fields” button (see below).
返回到报表界面,并显示“数据集属性”对话框。 我们为查询类型选择“存储过程”,选择我们的存储过程,然后单击“刷新字段”按钮(见下文)。

We now click the “Fields” tab (see below).
现在,我们单击“字段”选项卡(见下文)。
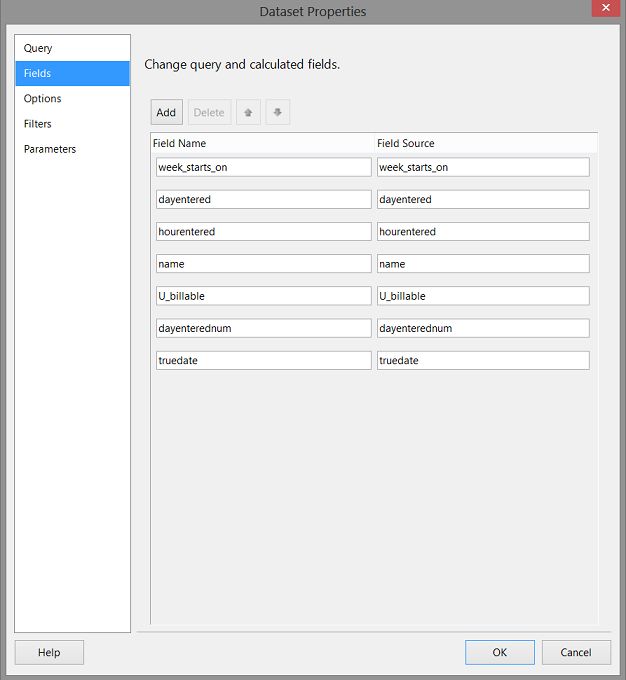
Clicking on the “Fields” tab we see the fields from the shared data source which in turn had obtained its field list from the stored procedure that we created (see above).
单击“字段”选项卡,我们将看到共享数据源中的字段,而共享数据源又从我们创建的存储过程中获取了其字段列表(请参见上文)。

As this dataset will contain billable records, we must set a filter in order for our dataset to contain only those records that are billable(see above). We set the filter to look at the field “u_billable” and only extract those records whose “u_billable” value is 1. Further, we wish to extract only the records where the actual billing date is between the start and end dates.(see above). While this may seem a bit redundant, it ensures that the dataset displayed is exactly what the end user desires.
由于此数据集将包含可结算记录,因此我们必须设置一个过滤器,以便我们的数据集仅包含那些可结算记录(请参见上文)。 我们将过滤器设置为查看“ u_billable”字段,仅提取“ u_billable”值为1的那些记录。此外,我们只希望提取实际账单日期在开始日期和结束日期之间的记录。(请参见上文) )。 尽管这看起来有些多余,但可以确保显示的数据集恰好是最终用户想要的。
We click upon the “Parameters” tab to bring up the parameters dialogue box.
我们单击“参数”选项卡以打开参数对话框。

We ensure that the “Parameter Value” boxes are correctly populated (as may be seen above).
我们确保正确填写了“参数值”框(如上所示)。
In a similar fashion, we are able to create the “nonbillable” local dataset. We note that “u_billable” is 0 in this case (see below).
以类似的方式,我们能够创建“不可计费”的本地数据集。 我们注意到在这种情况下,“ u_billable”为0(请参见下文)。

创建并填充矩阵 (Creating and populating our matrices)
Now that our datasets have been created, we are in a position to view our results.
现在我们的数据集已经创建,我们可以查看结果了。
We drag two matrices from the toolbox and place them on the drawing surface (see below).
我们从工具箱中拖动两个矩阵并将它们放置在工程图面上(请参见下文)。

We click on the left-hand matrix and set the dataset property to point to the “billable” data set (see below).
我们单击左侧矩阵,然后将数据集属性设置为指向“可结算”数据集(请参见下文)。

Our next task is to define the “Row Group” aggregation. This will permit the totaling of the hours (per person) for each day.
我们的下一个任务是定义“行组”聚合。 这将允许每天总计(每人)小时。

We right click on the “RowGroup” and select “Group Properties” (see above). The “Group Properties” dialogue box appears. We set the grouping on the employee name and the week (see below). It should be noted that we could just as well utilized the “Truedate” field.
我们右键单击“ RowGroup”,然后选择“ Group Properties”(参见上文)。 出现“组属性”对话框。 我们根据员工姓名和星期设置分组(请参见下文)。 应当指出,我们可以很好地利用“ Truedate”字段。

Processing the column grouping
处理列分组
We now right click upon the Column grouping and select “Delete Group” (see below).
现在,我们在“列”分组上单击鼠标右键,然后选择“删除组”(请参见下文)。
We are asked if we wish to delete the group and the related rows and columns OR merely to delete the groups. We opt to delete the groups only (see below).
询问我们是否要删除组以及相关的行和列,还是仅删除组。 我们选择仅删除组(请参见下文)。

Now that our matrix aggregation has been set, we are in a position to populate our “billable” matrix.
既然已经设置好矩阵汇总,就可以填充“可计费”矩阵了。

Our populated “Billable” matrix may be seen above. The astute reader will note that we utilized the field “truedate” as our date field. “truedate” is the actual date on which our hours were worked.
我们填充的“可结算”矩阵可以在上方看到。 精明的读者会注意到我们将字段“ truedate”用作我们的日期字段。 “真实日期”是我们工作时间的实际日期。
In a similar fashion, we repeat the same process for our “Non-Billable” hours, however, this time utilizing the non-billable dataset. The “non-billable” matrix is shown above as well.
以类似的方式,我们在“非计费”小时中重复相同的过程,但是这次使用的是非计费数据集。 上面也显示了“不可计费”矩阵。
Lastly, we apply a little make-up to the report by adding the main header and a sub-header for each of the matrices. We also apply some fill to our data boxes (see above).
最后,我们通过为每个矩阵添加主标题和子标题来对报告进行一些补充。 我们还对数据框进行了一些填充(请参见上文)。
让我们旋转一下报告 (Let us give our report a whirl)
In order to prove to Mary that we have in fact created the report according to the correct specifications, we set the start date to 1/1/2016 and the end date to 1/31/ 2016. We click on the “Preview” tab and our report comes up (see below).
为了向Mary证明我们实际上已经按照正确的规范创建了报告,我们将开始日期设置为2016年1月1日,将结束日期设置为2016年1月1日。我们点击“预览”标签然后我们的报告出现了(见下文)。

The end of period records may be seen below:
期末记录可以在下面看到:

The reader will note that the extract begins on 1/1/2016 and ends on or before 1/31/2016.
读者会注意到,摘录开始于2016年1月1日,结束于 2016 年1月1日或之前 。
结论 (Conclusions)
So, we arrive at the end of another “fireside” chat. Oft times the format of the data (available for us to utilize) is not all that conducive to reporting. Mary’s SeviceNow installation’s “TimeCard” table has the daily chargeable and non-chargeable hours as seven columns within the table, a separate column for each day of the week. Each week begins on Sunday and the weekly records often will cross month ends. This makes it challenging to report on the results for a particular fiscal month. Pivot tables and date calculations help us make some sense out of this mess. They also help when it comes to report aggregation and ensuring that the decision maker is able to make efficient and effective decisions.
因此,我们到达了另一个“炉边”聊天的结尾。 通常,数据格式(可供我们使用)并不总是有助于报告。 Mary的SeviceNow安装的“ TimeCard”表具有每天可收费和不可收费的时间,该表中的七个列分别是一周中的每一天。 每周从星期日开始,每周记录通常跨月结束。 这使得报告特定财政月的结果具有挑战性。 数据透视表和日期计算有助于我们从这种混乱中了解一些东西。 它们还有助于报告汇总,并确保决策者能够做出有效的决策。
Happy programming and all the best!
祝您编程愉快,一切顺利!
附录1 (Addenda 1)
枢纽代码 (Pivot code)
Select week_starts_on,dayentered, hourentered,name,u_billable,
case when dayentered = 'monday' then 1 when dayentered = 'tuesday' then 2
when dayentered = 'wednesday' then 3 when dayentered = 'thursday' then 4
when dayentered = 'friday' then 5 when dayentered = 'saturday' then 6
when dayentered = 'sunday' then 0 end as dayenterednum into #rawdata2
from #rawdata1
unpivot
(
hourentered for dayentered in (monday, tuesday, wednesday, thursday, friday, saturday, sunday)
) as unpvt
inner join #startson ss
on convert(date,ss.Startson) = convert(date,week_starts_on)
where week_starts_on between dateadd(d,-7,@startdate) and dateAdd(d,7,@EndDate)
Select * from #rawdata2
order by week_starts_on,name, dayenterednum
参考文献: (References:)
- Using PIVOT and UNPIVOT 使用PIVOT和UNPIVOT
- Create a Matrix (Report Builder and SSRS) 创建矩阵(报表生成器和SSRS)
- Date and Time Data Types and Functions (Transact-SQL) 日期和时间数据类型和函数(Transact-SQL)
翻译自: https://www.sqlshack.com/reporting-sql-server-use-pivot-tables-and-date-calculations-to-obtain-valuable-reports/