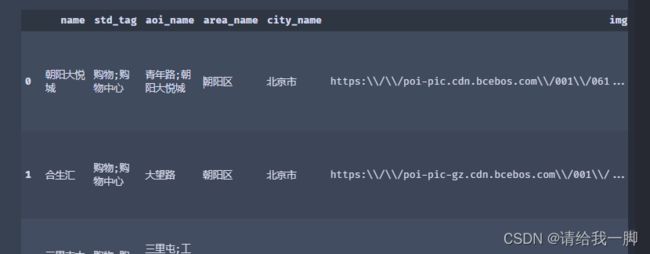
【爬虫】百度FengXiangBiao(完全爬虫卡住了,是爬虫+文本提取方式)
学习使用。爬虫有风险。使用需谨慎。切记切记。
参考链接:学习python爬虫—爬虫实践:爬取B站排行榜
都是排行榜反正
网页细节
按F12,打开控制台。前端就是这点好,非常直观。
找到排行的具体位置,如下图,这里是【top_rank_list-poi-card】
(所以百度方向标这里实际上是poi数据,刚刚在手机上操作了下,确实,点击某个具体的mall在地图显示的是一个点,不是aoi)
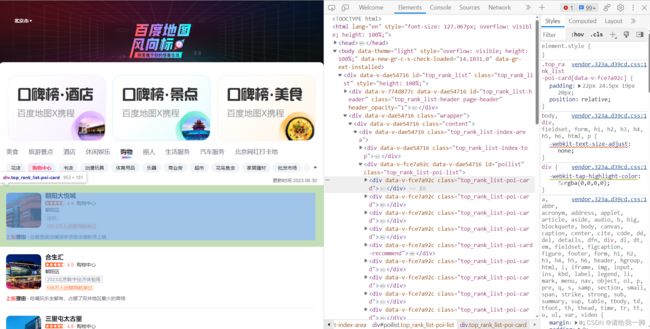
进一步细节找我需要的数据。一层一层拨开它的心。实际上我只需要名字。也就是绿色框框里的东西。
(问就是懒,一个rank少一二十个,多四五十个,不想一个个自己打)
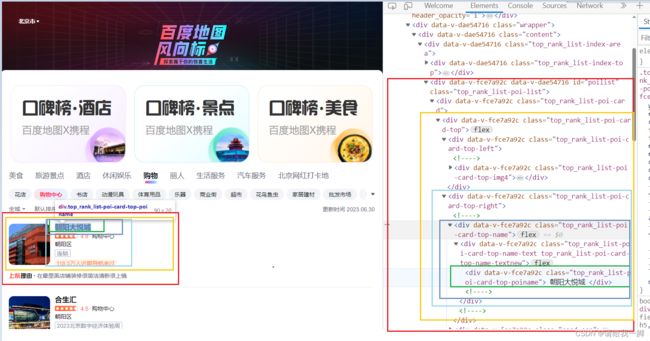
综合分析可知,每一个mall都是在class为【top_rank_list-poi-card】的div标签中,
而需要的mall名字则是在【top_rank_list-poi-card-top】的div标签下,【top_rank_list-poi-card-top-right】的【top_rank_list-poi-card-top-right-name】的div标签
request爬取【暂停版】
百度方向标的链接:手机打开百度地图,输入百度风向标,然后分享链接,在电脑端打开就行(直接搜索搜不出来的)
https://ugc.map.baidu.com/cube/feed/bangdancollect?stbar_height=48&city_id=131&loc=&tab1=%E8%B4%AD%E7%89%A9&tab2=%E8%B4%AD%E7%89%A9%E4%B8%AD%E5%BF%83&district_index=%E5%85%A8%E5%9F%8E&shangquan_index=&ncpshare=yymap
从链接其实可以看出,诸如city_id=131,这个131是北京,后面具体每个分类tab有不同。
没用过百度地图API,应该是一样的对应方式
![]()
import json
import requests
from bs4 import BeautifulSoup
#返回服务器响应
def download_html(url, headers):
# 发送请求,获取并返回响应
res = requests.get(url, headers=headers)
res.encoding = 'utf-8-sig'
res = res.text.encode('utf-8-sig').decode('unicode_escape') #返回的res从ASCII转为unicode格式
return res
#main function
def main():
url = 'https://ugc.map.baidu.com/cube/feed/bangdancollect?'\
'stbar_height=48&city_id=131&loc=&tab1=%E8%B4%AD%E7%89%A9&'\
'tab2=%E8%B4%AD%E7%89%A9%E4%B8%AD%E5%BF%83'\
'&district_index=%E5%85%A8%E5%9F%8E&shangquan_index=&ncpshare=yymap'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us)'
'AppleWebKit/534.50 (KHTML, like Gecko)'
'Version/5.1 Safari/534.50'}
html = download_html(url, headers)
print(html)
print('***********************************************************')
if __name__ == '__main__':
main()
注意了,直接用跑上面代码,html获得的信息,需要仔细找我们需要的信息
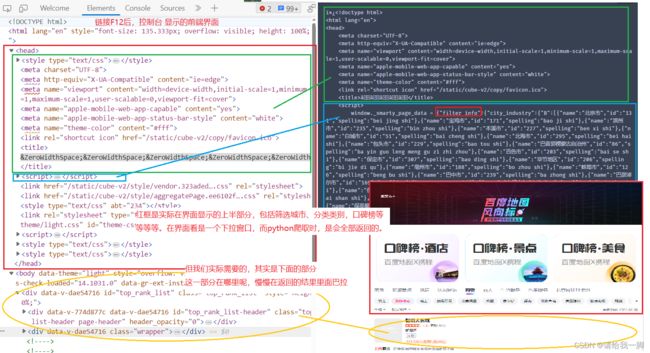
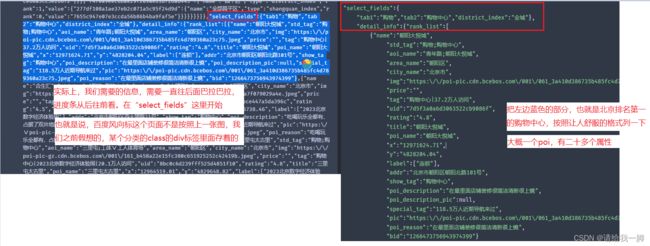
从上面的图可以知道,我们需要的信息实际上,是在“select_field”里面。
所以下面做的是完善代码,提取我们需要的信息。
好的那么问题又来了。
现在根据参考链接,定义一个新的函数parse_html用来解析html,在rank_list,我们是不会得到返回值的!!!
import json
import requests
from bs4 import BeautifulSoup
#返回服务器响应
def download_html(url, headers):
# 发送请求,获取并返回响应
res = requests.get(url, headers=headers)
res.encoding = 'utf-8-sig'
res = res.text.encode('utf-8-sig').decode('unicode_escape') #返回的res从ASCII转为unicode格式
return res
#解析html,返回排行榜信息
def parse_html(html):
soup=BeautifulSoup(html,'html.parser')
rank_list = soup.find_all('.detail_info') # 获取排行榜列表
print(rank_list)
#main function
def main():
url = 'https://ugc.map.baidu.com/cube/feed/bangdancollect?'\
'stbar_height=48&city_id=131&loc=&tab1=%E8%B4%AD%E7%89%A9&'\
'tab2=%E8%B4%AD%E7%89%A9%E4%B8%AD%E5%BF%83'\
'&district_index=%E5%85%A8%E5%9F%8E&shangquan_index=&ncpshare=yymap'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us)'
'AppleWebKit/534.50 (KHTML, like Gecko)'
'Version/5.1 Safari/534.50'}
html = download_html(url, headers)
data_list = parse_html(html)
print(html)
print('***********************************************************')
if __name__ == '__main__':
main()
为什么呢,因为
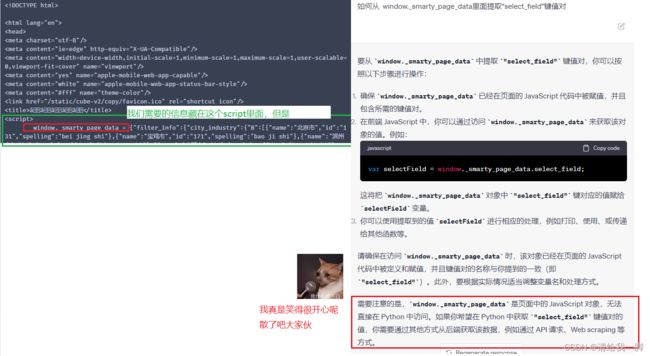
这里有个beautifulsoup的基础文档还可以:
CSDN博主MilkLeong:Beautiful Soup库入门(标签树、基本元素、遍历、输出)
https://blog.csdn.net/MilkLeong/article/details/106156193
转文档提取版
由前面的卡壳处可知,需要转JavaScript。这个我还没研究。山重水复疑无路,咱换种思路。
首先,把前面的内容转为文本。就是整个【window._smarty_page_data = {“filter_info”:{"cXXXXXX】。然后跑下面的代码
import re
import pandas as pd
import json
def extract_key_value_pairs(data):
data = data.strip('{}')
pairs = data.split(',')
result = {}
for pair in pairs:
pattern = r'"([^"]+)":"([^"]+)"' #"key":"value"
match = re.search(pattern, pair)
if match:
key = match.group(1)
value = match.group(2)
# print(key, value)
else:
continue
print("Invalid key-value pair")
result[key] = value
return result
filepath=r"XXXXX.txt"
with open(filepath, "r") as file:
contents=file.read()
#regular expression
pattern=re.compile('rank_list.+本市商业街榜')
specific_content=pattern.findall(contents)
#delete certain contents
specific_content=str(specific_content)
cleaned_text = specific_content.replace("['rank_list\":[", '')
cleaned_text = cleaned_text.replace('],"title":"本市商业街榜\']', '')
#split individual mall infomation
single_mall = cleaned_text.split('},{')
#change the infomation to dataframe format
result_list = []
for mall in single_mall:
key_value_pairs = extract_key_value_pairs(mall)
result_list.append(key_value_pairs)
print(result_list)
# 将结果列表转换为 JSON 格式
df=pd.DataFrame(result_list)
df
# result_list.append(key_value_pairs)
最后获得我们想要的df格式