![]()
背景
本项目,低成本预渲染:
- 非侵入式,无需改动业务代码
- 屏蔽框架差异,无依赖,单文本实现,直接拷贝粘贴本脚本即可实现功能
- 简单,开源代码,无编译,脚本代码量仅一百多行,二次集成门槛低,代码清晰易懂
- 注意本项目仅适合低成本的中小型项目,大型商业项目可参考以下成熟方案
- SSG 预渲染:Prerender SPA Plugin,和本工具类似,但集成了 puppeteer,自动运行项目,截取内容,生产页面元素
- SSR 服务端渲染:Next.js React 应用程序的服务器渲染框架,Nuxt.js Vue.js 应用程序的服务器渲染框架

效果
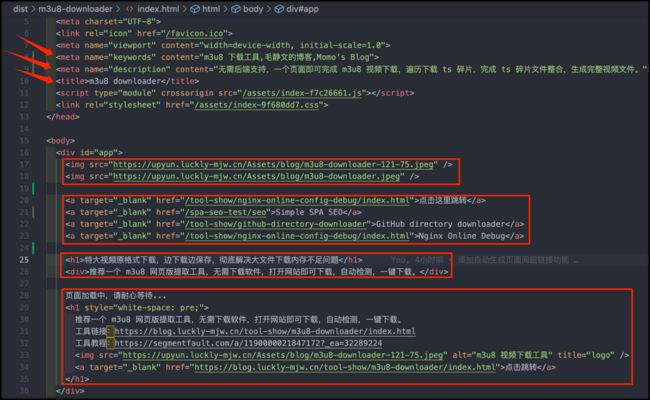
- 在指定目录生成与 index.html 为模版的入口文件

- 在每个入口文件中,实现各自定制的 seo 配置,实现 title、keywords、description 等信息的自定义
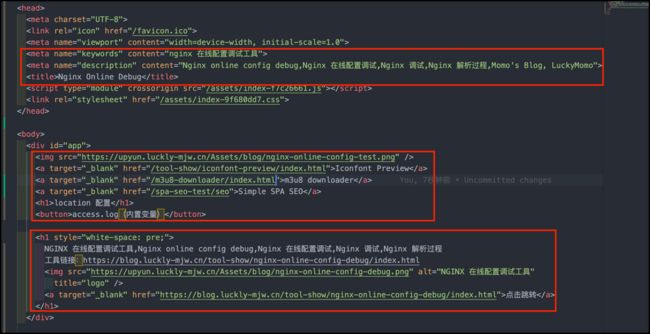
功能
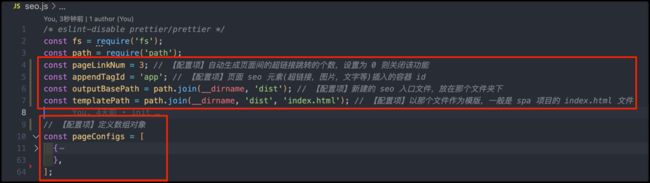
- 【pageLinkNum】自动生成页面间的超链接跳转,实现页面间关联效果,设置为 0 则关闭该功能
- 【path】需要对外暴露的路径,脚本将自动在相对路径生成对应入口文件。注意,无需刻意携带文件后缀,通过后文 nginx 的一行配置,可将无后缀文件统一以 html 文件类型返回。让浏览器正常解析。

- 【title】指定页面的 title,
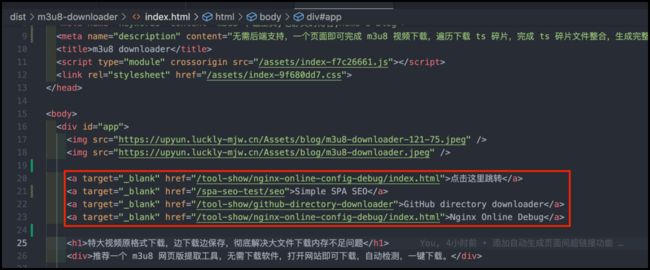
m3u8 downloader 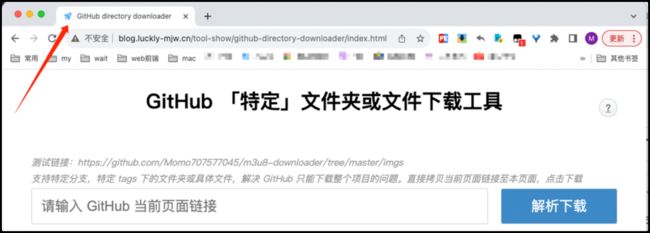
- 【keywords】指定页面的 seo 关键字,
- 【description】指定页面的 seo 摘要,
- 【img】设置页面的图片,实现搜索引擎收录,展示效果时,展示缩略图
- 【link】设置页面的超链接跳转,使得搜索引擎的蜘蛛爬虫可以按照超链接找到系统中其他页面的链接,提供相关页面的入口
- 【content】设置页面主体文案内容,使得搜索引擎可匹配关键字
- 【html】其他自定义标签,提供自定义插入特定 html 代码功能
{
path: '/m3u8-downloader/index.html', // 访问链接
title: 'm3u8 downloader',
keywords: "m3u8 下载工具,毛静文的博客,Momo's Blog",
description: '无需后端支持,一个页面即可完成 m3u8 视频下载,遍历下载 ts 碎片,完成 ts 碎片文件整合,生成完整视频文件。', // 页面描述
img: [
'https://upyun.luckly-mjw.cn/Assets/blog/m3u8-downloader-121-75.jpeg',
'https://upyun.luckly-mjw.cn/Assets/blog/m3u8-downloader.jpeg'
],
link: [{
text: '点击这里跳转',
href: '/tool-show/nginx-online-config-debug/index.html',
}],
content: [{
tag: 'h1',
text: '特大视频原格式下载,边下载边保存,彻底解决大文件下载内存不足问题',
}, {
tag: 'div',
text: '推荐一个 m3u8 网页版提取工具,无需下载软件,打开网站即可下载,自动检测,一键下载。',
}],
html: `
页面加载中,请耐心等待...
推荐一个 m3u8 网页版提取工具,无需下载软件,打开网站即可下载,自动检测,一键下载。
工具链接:https://blog.luckly-mjw.cn/tool-show/m3u8-downloader/index.html
工具教程:https://segmentfault.com/a/1190000021847172?_ea=32289224
 点击跳转
点击跳转
`,
}用法
- 拷贝项目的 seo.js 文件,修改配置项
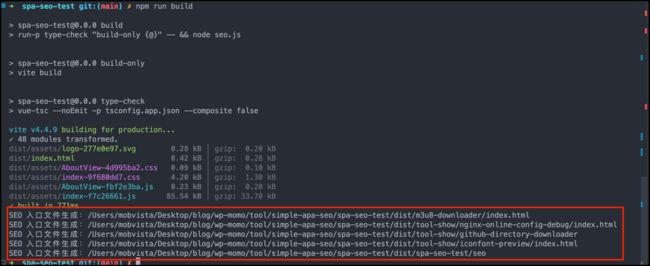
- 执行脚本,
node seo.js - 集成 package script

- 添加 nginx 配置,
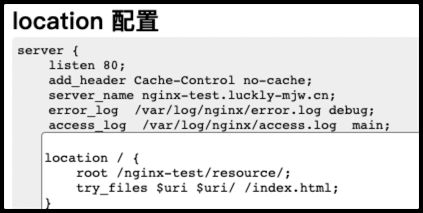
default_type text/html;使无后缀文件以 html 类型返回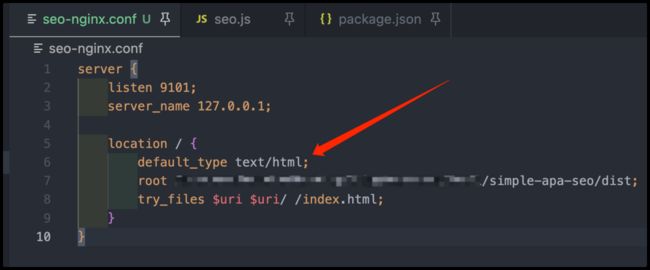
源代码
/* eslint-disable prettier/prettier */
const fs = require('fs');
const path = require('path');
const pageLinkNum = 3; // 自动生成页面间的超链接跳转的个数,设置为 0 则关闭该功能
const appendTagId = 'app'; // 页面 seo 元素(超链接,图片,文字等)插入的容器 id
const outputBasePath = path.join(__dirname, 'dist'); // 新建的 seo 入口文件,放在那个文件夹下
const templatePath = path.join(__dirname, 'dist', 'index.html'); // 以那个文件作为模版,一般是 spa 项目的 index.html 文件
// SEO 参考资料:https://github.com/madawei2699/awesome-seo/blob/main/README_CN.md
// 定义数组对象
const pageConfigs = [
{
// 参考资料:https://developers.google.com/search/docs/crawling-indexing/url-structure?hl=zh-cn
path: '/m3u8-downloader/index.html', // 访问链接
// 页面标题:搜索引擎通常显示页面标题的前 55 至 60 个字符,超出此范围的文本可能会丢失
// 参考资料:https://developers.google.com/search/docs/appearance/title-link?hl=zh-cn
// 参考资料:https://developer.mozilla.org/en-US/docs/Web/HTML/Element/title#page_titles_and_seo
title: 'm3u8 downloader',
// 页面关键字,google 已经弃用该字段
// https://zhuanlan.zhihu.com/p/382454488
// https://developers.google.com/search/docs/crawling-indexing/special-tags?hl=zh-cn
keywords: "m3u8 下载工具,毛静文的博客,Momo's Blog",
// 页面摘要
// https://developers.google.com/search/docs/appearance/snippet?hl=zh-cn
description: '无需后端支持,一个页面即可完成 m3u8 视频下载,遍历下载 ts 碎片,完成 ts 碎片文件整合,生成完整视频文件。', // 页面描述
// 自定插入的图片
img: [
'https://upyun.luckly-mjw.cn/Assets/blog/m3u8-downloader-121-75.jpeg',
'https://upyun.luckly-mjw.cn/Assets/blog/m3u8-downloader.jpeg'
],
// 自定义超链接跳转
// 参考资料:https://developers.google.com/search/docs/appearance/sitelinks?hl=zh-cn
link: [{
text: '点击这里跳转',
href: '/tool-show/nginx-online-config-debug/index.html',
}],
// 自定义插入的标签
content: [{
tag: 'h1',
text: '特大视频原格式下载,边下载边保存,彻底解决大文件下载内存不足问题',
}, {
tag: 'div',
text: '推荐一个 m3u8 网页版提取工具,无需下载软件,打开网站即可下载,自动检测,一键下载。',
}],
// 自定义插入的 html
// 参考资料:https://zhuanlan.zhihu.com/p/391844443
html: `
页面加载中,请耐心等待...
推荐一个 m3u8 网页版提取工具,无需下载软件,打开网站即可下载,自动检测,一键下载。
工具链接:https://blog.luckly-mjw.cn/tool-show/m3u8-downloader/index.html
工具教程:https://segmentfault.com/a/1190000021847172?_ea=32289224
点击跳转
`,
},
];
// 生成页面间随机页面跳转
pageLinkNum && pageConfigs.forEach(config => {
config.link = config.link || [];
const pageLinks = [...pageConfigs];
for (let index = 0; index < Math.min(pageConfigs.length, pageLinkNum); index++) {
const pageConfig = pageLinks.splice(Math.floor(Math.random() * pageLinks.length), 1)[0];
config.link.push({ // 自定义插入的标签
text: pageConfig.title || pageConfig.keywords || pageConfig.description,
href: pageConfig.path,
})
}
})
const appendTagRegex = new RegExp(`(id="${appendTagId}"[^>]*>)`);
const templateStr = fs.readFileSync(templatePath, 'utf8');
pageConfigs.forEach(data => {
// 读取目标文件内容
let fileContent = templateStr;
// 替换 title 标签
if (data.title) {
fileContent = fileContent.replace(/.*<\/title>/, `<title>${data.title} `);
}
// 替换 meta name="keywords" 标签
if (data.keywords) {
fileContent = fileContent.replace(/name="keywords"[^>]+/, `name="keywords" content="${data.keywords}"`);
}
// 替换 meta name="description" 标签
if (data.description) {
fileContent = fileContent.replace(/name="description"[^>]+/, `name="description" content="${data.description}"`);
}
// 插入自定义 html 标签
if (data.html) {
fileContent = fileContent.replace(appendTagRegex, `$1\n${data.html}`);
}
// 插入 content 标签
if (data.content) {
const contentTags = data.content.map(contentConf => typeof contentConf === 'object' ? `\n<${contentConf.tag}>${contentConf.text}` : `\n${content}`).join('');
fileContent = fileContent.replace(appendTagRegex, `$1${contentTags}`);
}
// 插入 a 标签,设置超链接跳转
if (data.link) {
const aTags = data.link.map(linkConf => `\n${linkConf.text}`).join('');
fileContent = fileContent.replace(appendTagRegex, `$1${aTags}`);
}
// 插入 img 标签
if (data.img) {
const imgTags = data.img.map(imgUrl => `\n `).join('');
fileContent = fileContent.replace(appendTagRegex, `$1${imgTags}`);
}
// 将修改后的内容写入目标文件
const targetPath = path.join(outputBasePath, data.path);
fs.mkdirSync(targetPath.substring(0, targetPath.lastIndexOf('/')), { recursive: true });
fs.writeFileSync(targetPath, fileContent, 'utf8');
console.log(`SEO 入口文件生成:${targetPath}`);
});
`).join('');
fileContent = fileContent.replace(appendTagRegex, `$1${imgTags}`);
}
// 将修改后的内容写入目标文件
const targetPath = path.join(outputBasePath, data.path);
fs.mkdirSync(targetPath.substring(0, targetPath.lastIndexOf('/')), { recursive: true });
fs.writeFileSync(targetPath, fileContent, 'utf8');
console.log(`SEO 入口文件生成:${targetPath}`);
});
其他优秀工具推荐
-
- 单文件,单命令完成项目图片视觉无损压缩
- 自动跳过已压缩文件,脚本运行快
-
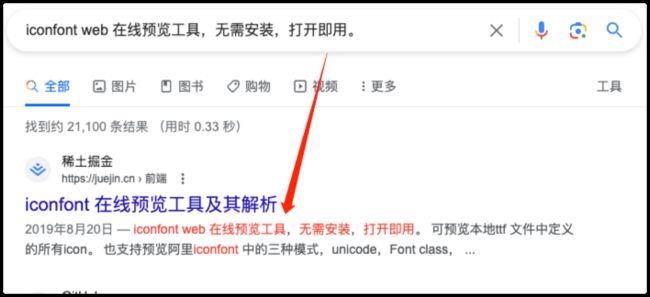
- 支持解析本地 ttf 文件,支持解析在线阿里图标资源链接

-
- Nginx 学习,Nginx 在线配置调试神器,解析各命令运行过程
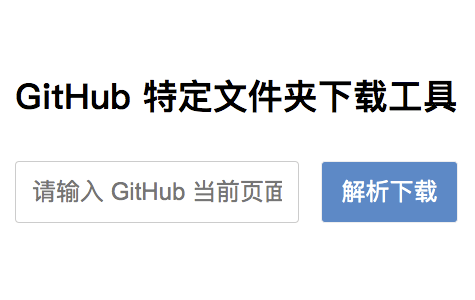
-
- 复制目标页面链接,直接下载 GitHub 「特定」文件夹或文件(支持特定分支或 tag)。解决 GitHub 只能下载整个项目的问题