Redis缓存实现及其常见问题解决方案
随着互联网技术的发展,数据处理的速度和效率成为了衡量一个系统性能的重要指标。在众多的数据处理技术中,缓存技术以其出色的性能优化效果,成为了不可或缺的一环。而在众多的缓存技术中,Redis 以其出色的性能和丰富的功能,赢得了广大开发者的喜爱。
Redis 是一个开源的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。Redis 支持多种类型的数据结构,如字符串、哈希、列表、集合、有序集合等。此外,Redis 还提供了一系列的特性,如数据持久化、事务和发布订阅等。
然而,如何利用 Redis 实现高效的缓存机制呢?这就是我们今天要探讨的主题。在这篇文章中,我们将详细介绍 Redis 的缓存实现,包括其读写策略、过期策略和淘汰策略等。我们希望通过这篇文章,帮助读者更好地理解和使用 Redis,从而提高自己的系统性能。
文章目录
-
-
-
- 1、Redis缓存实现与缓存策略
-
- 1.1、Redis缓存应用
- 1.2、Redis缓存策略分类
- 1.3、Redis常见读策略
- 1.4、Redis常见写策略
- 1.5、Redis常见过期策略
- 1.6、Redis淘汰策略
- 2、Redis缓存常见问题及解决方案
-
- 2.1、Redis热键问题
- 2.2、Redis缓存穿透
- 2.3、Redis缓存击穿
- 2.4、Redis缓存雪崩
- 3、Java下Redis缓存实现
-
- 3.1、Jedis实现
- 3.2、SpringBoot实现
-
-
1、Redis缓存实现与缓存策略
1.1、Redis缓存应用
Redis 缓存是 Redis 的一种主要应用场景。通过将热点数据存储在内存中,可以大大提高应用的读取速度,从而提高应用的性能。
在使用 Redis 作为缓存时,通常会设置一个过期时间,当数据过期后,Redis 会自动删除这些数据,以释放内存空间。同时,为了防止缓存雪崩,通常会对过期时间进行随机化处理。
此外,Redis 还提供了丰富的数据结构,如字符串、列表、集合、哈希表等,可以满足各种复杂的缓存需求。例如,可以使用哈希表存储对象,使用列表实现最近最少使用(LRU)算法等。
1.2、Redis缓存策略分类
缓存策略是指在使用缓存时,如何选择和管理缓存中的数据的一系列规则和方法。缓存策略的目标是尽可能地提高数据访问的速度,减少对原始数据源(如数据库)的访问,从而提高系统的性能。
缓存策略主要包括以下几个方面:读策略、写策略、加载策略、过期策略、淘汰策略。
1.3、Redis常见读策略
Redis常见读策略:
- Read Through(读策略-按需加载):在读取数据时,如果发现缓存中没有,那么会从数据库中读取,读取后将数据放入缓存。这种策略可以保证缓存中的数据都是热点数据,但可能会导致第一次读取数据时延迟增加;
- Lazy Loading(读策略-按需加载):只有当数据被请求时,才将其加载到缓存中。如果数据在缓存中未命中,则从数据库中读取并添加到缓存中;
- Pre Loading(读策略-预加载):系统在启动或者在某个特定的时间点,会预先将可能需要的数据加载到缓存中。这样,当数据被请求时,可以直接从缓存中获取,无需再去数据库中查询,从而提高了数据访问的速度。预加载策略特别适用于那些数据访问模式比较固定,且数据更新频率不高的场景。例如,一些配置信息、静态内容等,就非常适合使用预加载策略。
在实际使用中,可以根据具体的应用场景和需求,选择合适的读策略。例如,如果数据更新频率较低,且读取操作的性能要求较高,可以选择使用 Read Through 策略;如果数据更新频率较高,或者希望节省缓存空间,可以选择使用 Lazy Loading 策略。
1.4、Redis常见写策略
Redis常见写策略:
- Write Through(写策略-同步更新):每次数据更新时,都会同时更新数据库和缓存。这种策略的优点是能够保持数据的一致性,但缺点是会影响性能,因为每次更新都需要同时操作数据库和缓存。
- Write Back(写策略-异步更新):每次数据更新时,先更新缓存,然后再异步更新数据库。这种策略的优点是不会影响缓存的高性能,能够快速响应客户端,但缺点是在数据异步写回到数据库之前,存在缓存和数据库数据短暂不一致的情况。
- Write Around(写策略-直接更新):在更新数据时,直接更新数据库,不更新缓存。当下次读取数据时,如果缓存中没有,再从数据库中读取。这种策略适用于那些被写入后很少被读取的数据。
1.5、Redis常见过期策略
Redis 的过期策略主要是通过设置 TTL(Time To Live)来实现的。对于每个设置了过期时间的键,Redis 会在键到达其过期时间时自动删除它。Redis 使用了惰性删除和定期删除两种策略来处理过期的键:
- 惰性删除:即只有当某个键被访问时,Redis 才会检查该键是否过期,如果过期则删除。这种策略的优点是可以减少对 CPU 的占用,避免在键过期的瞬间产生大量的删除操作,影响 Redis 的性能;

-
定期删除:即 Redis 会每隔一段时间随机检查一些键,如果发现有键已经过期,就会将其删除。这种策略可以有效地清理过期的键,释放内存空间。
但是,由于 Redis 不能对所有键进行轮询,所以可能会有一些已经过期的键没有被立即删除。这就是为什么 Redis 还需要使用惰性删除策略,即只有当某个键被访问时,Redis 才会检查该键是否过期,如果过期则删除。
这两种策略的结合使用,可以在保证 Redis 性能的同时,有效地管理过期的键,避免过期的键长时间占用内存。
1.6、Redis淘汰策略
那么定期+惰性都没有删除过期的 Key 怎么办?这时就需要 Redis 的内存淘汰策略登场了
当 Redis 的内存使用达到设定的上限时,如果还需要存储新的数据,就需要采用一种淘汰策略来删除一些旧的数据,以释放内存空间。这就是所谓的内存淘汰机制。
Redis 提供了多种淘汰策略,可以通过 maxmemory-policy 配置项来设置,包括:
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错;
- allkeys-lru:从数据集中挑选最近最少使用的数据淘汰;
- volatile-lru:从设置了过期时间的数据集中挑选最近最少使用的数据淘汰;
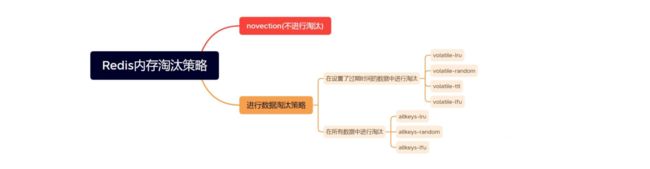
- allkeys-random:随机移除某个键;
- volatile-random:从设置了过期时间的数据集中任意选择数据淘汰;
- volatile-ttl:从设置了过期时间的数据集中挑选将要过期的数据淘汰。
以上策略可以根据实际应用的需求和场景进行选择。
2、Redis缓存常见问题及解决方案
2.1、Redis热键问题
所谓热键问题就是,某个或某些键被大量并发的请求访问,可能会导致流量过于集中,达到物理网卡上限,从而导致这台 Redis 的服务器宕机引发雪崩。
针对热键问题的解决方案:
- 提前把热键打散到不同的服务器:这种方法也被称为分片,可以将热键的数据分散到多个 Redis 服务器中,降低单个服务器的访问压力;
- 二级缓存:在应用服务器内部维护一个本地缓存,当 Redis 宕机时,可以从本地缓存中获取数据。这种方法可以提高系统的可用性,但需要注意的是,本地缓存和 Redis 之间可能会存在数据一致性的问题
另外,还可以考虑使用一些流量控制的手段,比如限流、熔断等,来防止大量的请求同时访问热键,从而避免服务器宕机的问题。
2.2、Redis缓存穿透
缓存穿透是指查询一个在缓存和数据库中都不存在的数据,每次请求都会打到数据库,造成数据库压力过大。
有效的解决方案是:
- 接口校验:对请求的参数进行校验,非法的请求直接返回错误,不让其打到数据库。
- 缓存空值:即使数据库中没有查询到数据,也将空值写入缓存,这样下次查询同样的数据时,直接从缓存中获取空值,不需要再访问数据库。
- 布隆过滤器:布隆过滤器是一种概率型数据结构,可以用来判断一个元素是否在一个集合中。我们可以将所有可能存在的数据的 Key 存入布隆过滤器,当查询数据时,先判断 Key 是否在布隆过滤器中,如果不在,直接返回不存在,如果在,再去缓存和数据库中查询。
布隆过滤器(Bloom Filter)的主要特点如下:
- 判断不存在:如果布隆过滤器判断一个元素不存在,则这个元素一定不存在。
- 判断存在:如果布隆过滤器判断一个元素存在,这个元素可能存在也可能不存在,存在一定的误判率。这个误判率是可以通过调整布隆过滤器的参数来控制的。
布隆过滤器由一个位数组(BitSet)和一组哈希函数组成,是一种空间效率极高的概率型算法和数据结构,主要用来判断一个元素是否在集合中存在。
相比于HashMap,布隆过滤器在处理大数据量时有明显的优势。当数据量较小,HashMap可以很好地处理问题,而且不存在误判率。但是,当数据量变大,尤其是要存储的键(Key)占用空间越大,布隆过滤器的空间优势就会开始体
这些方法可以有效地防止缓存穿透问题,保护数据库不被大量无效请求打垮。
2.3、Redis缓存击穿
缓存击穿是指一个热点数据在缓存中过期的瞬间,大量的请求直接打到数据库,可能会导致数据库压力骤增,甚至崩溃。
有效的解决方案是:
- 加互斥锁:在第一个请求查询数据库并更新缓存的过程中,其他的请求等待。这样可以保证只有一个请求会访问数据库,避免数据库压力过大。
- 热点数据不过期:将热点数据设置为永不过期,然后通过定时任务异步更新这些数据。这种方法可以避免热点数据突然过期导致的缓存击穿问题,但需要注意的是,这可能会导致数据在一段时间内不一致,需要根据业务需求来决定是否可以接受。
这些方法可以有效地防止缓存击穿问题,保护数据库不被大量请求打垮。
2.4、Redis缓存雪崩
缓存雪崩是指大量的热点数据在同一时间点过期,导致大量的请求直接打到数据库,可能会导致数据库压力骤增,甚至崩溃。
有效的解决方案是:
- 过期时间打散:给每个键的过期时间添加一个随机值,使得各个键的过期时间分散开来,避免在同一时间点大量键过期。
- 加互斥锁:对于同一个键,只允许一个请求查询数据库并更新缓存,其他的请求等待。这样可以保证只有一个请求会访问数据库,避免数据库压力过大。
- 热点数据不过期:将热点数据设置为永不过期,然后通过定时任务异步更新这些数据。这种方法可以避免热点数据突然过期导致的缓存雪崩问题,但需要注意的是,这可能会导致数据在一段时间内不一致,需要根据业务需求来决定是否可以接受。
这些方法可以有效地防止缓存雪崩问题,保护数据库不被大量请求打垮。
3、Java下Redis缓存实现
3.1、Jedis实现
以下是使用 Java 实现 Read Through 和 Write Through 策略的简单例子:
import redis.clients.jedis.Jedis;
public class Cache {
private Jedis jedis;
private Database db;
public Cache() {
this.jedis = new Jedis("localhost", 6379);
this.db = new Database();
}
// Read Through策略
public String readThrough(String key) {
// 先从缓存中读取数据
String value = jedis.get(key);
if (value == null) {
// 如果缓存中没有,那么从数据库中读取
value = db.getFromDatabase(key);
// 将从数据库中读取的数据放入缓存
jedis.set(key, value);
}
return value;
}
// Write Through策略
public void writeThrough(String key, String value) {
// 先将数据写入数据库
db.writeToDatabase(key, value);
// 然后将数据写入缓存
jedis.set(key, value);
}
}
class Database {
// 这里假设我们有一个数据库,具体实现省略
public String getFromDatabase(String key) {
// 从数据库中获取数据的代码
return "data";
}
public void writeToDatabase(String key, String value) {
// 将数据写入数据库的代码
}
}
在这个例子中,我们首先创建了一个Cache类,该类在构造函数中连接到 Redis 服务器,并初始化一个数据库对象。
然后,我们定义了两个方法:readThrough 和 writeThrough,分别实现了 Read Through 和 Write Through 策略。
readThrough方法首先尝试从缓存中读取数据,如果缓存中没有,那么从数据库中读取,并将从数据库中读取的数据放入缓存。writeThrough方法首先将数据写入数据库,然后将数据写入缓存。
Database类是一个假设的数据库类,具体实现省略。
3.2、SpringBoot实现
在 Spring Boot 中,我们也可以使用springframework.data.redis 来实现 Read Through 和 Write Through 策略。以下是一个简单的例子:
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Service;
@Service
public class DataService {
private final StringRedisTemplate redisTemplate;
public DataService(StringRedisTemplate redisTemplate) {
this.redisTemplate = redisTemplate;
}
public String readThrough(String key) {
// 先从缓存中读取数据
String value = redisTemplate.opsForValue().get(key);
if (value == null) {
// 如果缓存中没有,那么从数据库中读取
value = getFromDatabase(key);
// 将从数据库中读取的数据放入缓存
redisTemplate.opsForValue().set(key, value);
}
return value;
}
public void writeThrough(String key, String value) {
// 先将数据写入数据库
writeToDatabase(key, value);
// 然后将数据写入缓存
redisTemplate.opsForValue().set(key, value);
}
private String getFromDatabase(String key) {
// 从数据库中获取数据的代码
return "data";
}
private void writeToDatabase(String key, String value) {
// 将数据写入数据库的代码
}
}
在这个例子中,我们首先创建了一个 DataService 类,该类被 Spring 管理。
然后,我们定义了两个方法:readThrough 和 writeThrough,分别实现了 Read Through 和 Write Through 策略。
readThrough方法首先尝试从缓存中读取数据,如果缓存中没有,那么从数据库中读取,并将从数据库中读取的数据放入缓存。writeThrough方法首先将数据写入数据库,然后将数据写入缓存。
getFromDatabase 和 writeToDatabase方法是从数据库中获取数据和将数据写入数据库的代码,具体实现省略。
注意:在实际使用中,你需要在 Spring Boot 的配置文件中配置 Redis 连接信息。