Python语言:列表初体验
列表是Python中的一个对象,他类似于C语言中的数组,可以存储许多数据,也可以称之为数据集合。他原则是可以存储不同类型的数据,一般不建议这样使用,有点奇怪;一般情况下一个列表中保存的都是同一种类型的数据。
- 列表的创建
列表(list)是把数据放到一个中括号里,数据之间用逗号隔开。
1)创建一个空列表并检查其类型
students = []
print(type(type))运行结果如下:

2)给空列表赋值并打印列表
students = ["刘华","张海","韩梅梅","马冬梅","朱晓明"]运行结果如下:

3)使用len函数统计列表中的数据个数
students = ["刘华","张海","韩梅梅","马冬梅","朱晓明"]
print(len(students))运行结果如下:

- 修改以及删除列表中的值。
知识点补充:索引的本质是通过列表数据的下标值找到特定位置的数据。下标值从0开始,到 n-1结束。
1)通过索引找到需要修改的数据并重新赋值且打印输出新的列表。
students = ["刘华","张海","韩梅梅","马冬梅","朱晓明"]
# print(students)
students[3] = "闰土"
print(students) 运行结果如下:

2)通过del函数删除列表中的某一位置的数据并打印输出新的列表。
students = ["刘华","张海","韩梅梅","马冬梅","朱晓明"]
del(students[4])
print(students)运行结果如下:

- 查找列表中的值
1)查找列表中的最大值以及最小值:使用max函数来查找最大值,min函数查找最小值。
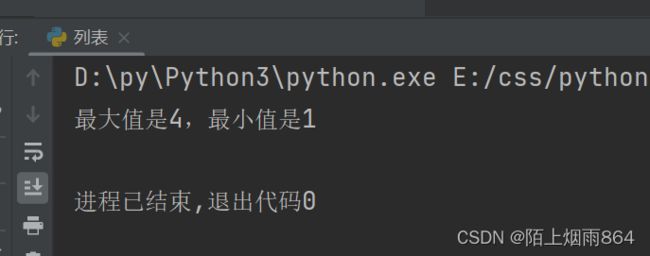
a = [1,2,3,4,3,3]
print("最大值是%d,最小值是%d" % (max(a),min(a)))
运行结果如下:
2)查找列表中某个数据出现的位置(即索引)以及某个数据出现的次数。
使用index函数来查找指定数据的位置,使用count函数来查找指定数据出现的次数。
a = [1,2,2,3,8,4]
print("列表中8的索引是%d" % (a.index(8)))
print("列表中2出现的次数是%d" % (a.count(2)))运行结果如下:

3)查找列表中比某个数据数值大的数据有哪些以及统计其个数。
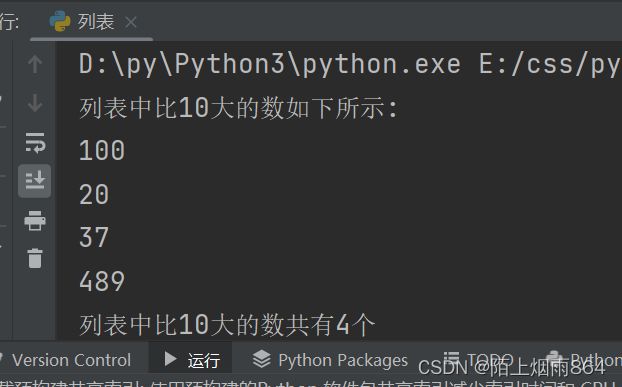
案例:查找列表中比10大的数据有那些以及统计其个数
b_list = [100,20,37,489,10]
i = 0 # 索引定义为0
j = 0 # 比10大的个数先赋值为0
print("列表中比10大的数如下所示:")
while i < len(b_list) : # 通过len函数可以知道列表的数据个数
if b_list[i] > 10 :
print(b_list[i])
j += 1
i += 1
print("列表中比10大的数共有%d个" % j)运行结果如下:
4)打印输出列表特定位置的值
a = [10,20,30,40,50,60]
print("索引为5的元素是%d" % (a[5]))运行结果如下:
