golang的协程调度模型GMP
GMP模型
-
P(Processor):
处理器,主要用来限制实际运行的 M 的数量。受GOMAXPROCS控制。也就是说 P 的数量就是并发的协程数,在任何时刻,都只有GOMAXPROCS个Goroutine 在同时运行。在不指定的情况下,默认 P 的个数为逻辑CPU的个数,通过runtime.NumCPU()可以获得逻辑CPU的个数,也就是最大能同时运行的线程数,这个数包括了超线程技术。 -
M(Machine):
OS Thread,由 OS 调度和管理。M 的数量不一定。但是处于非阻塞状态的 M 由 P 决定。M 和 P 的区别与联系在于:P 是 GoLang 假想的处理器,控制实际能够跑起来的 M 的数量。
如,在 G 的数量无限多的情况下,一开始 M 和 P 的数量一样多。但是当运行在 M 上的 G 调用了同步系统调用阻塞了 M, 此时这个 M 线程是没办法做其他操作的。
但是 GoLang 想要运行中的 M 数量是和 P 的数量一样多的,所以它会再创建一个 M 来跑新的 G。这样就能动态的保证
运行中的 M 的数量等于 P 的总数。 -
G(GoRoutine):协程,应用层看到的
线程。由 M 调度和执行。G 会被均匀的分配在多个 P 上面去。就像OS线程在内核上进行上下文切换,G 在 M 上进行上下文切换。
-
LRQ(Local Run Queue):从定义可知,P 相当于是对 M 的约束,M 只有绑定了 P 才能实际调度和执行 G。
因此,GoLang 给每个 P 设置了一个 LRQ 来维护一个待执行 G 的队列。
当有 M 绑定在 P 上时,M 就会优先调度和执行该 P 的 LRQ 上的 G。
需要重点关注的一点是:M 才是 OS Thread,因此只有 M 才有执行和调度 G 的能力。而 P 只是一个约束条件。
-
GRQ(Global Run Queue):没有绑定任何 P 的 G 就会被扔进 GRQ,有一个将 G 从 GRQ 移动到 LRQ 的过程。
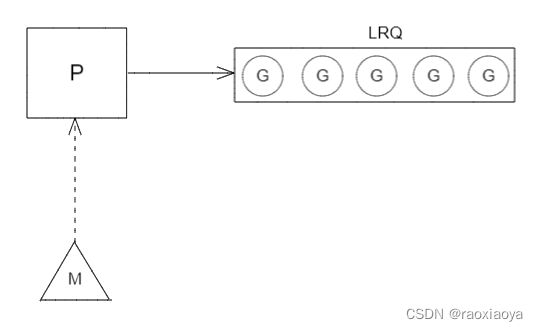
P 的状态
- Pidle: means a P is not being used to run user code or the scheduler. Typically, it’s on the idle P list and available to the scheduler
- Prunning: means a P is owned by an M and is being used to run user code or the scheduler.
- Psyscall: means a P is not running user code, may be stolen by another M.
- Pgcstop: means a P is halted for STW and owned by the M that stopped the world.
- Pdead: means a P is no longer used (
GOMAXPROCSshrank). We reusePifGOMAXPROCSincreases.G 的状态
- Gidle:just allocated and has not yet been initialized
- Grunnable:this goroutine is on a run queue
- Grunning:means this goroutine may execute user code
- Gsyscall: means this goroutine is executing a system call
- Gwaiting: means this goroutine is blocked in the runtime(channel)
线程的状态
- Waiting:这意味着线程停止并等待某些东西才能继续。这可能是由于等待硬件(磁盘、网络)、操作系统(系统调用)或同步调用(原子、互斥体)等原因。这些类型的延迟是性能不佳的根本原因。
- Runnable:线程处于就绪状态,这意味着线程需要时间在内核上,以便它可以执行分配给它的机器指令。如果您有很多线程需要时间,那么线程必须等待更长的时间才能获得时间。此外,随着更多线程争夺时间,任何给定线程获得的单独时间量都会缩短。这种类型的调度延迟也可能是性能不佳的原因。
- Executing:这意味着线程已被放置在核心上并正在执行其机器指令。与应用程序相关的工作正在完成。这是每个人都想要的。
线程的工作类型
- CPU密集型:这项工作永远不会造成线程可能处于等待状态的情况。这是一项不断进行计算的工作。
- IO密集型:这是导致线程进入等待状态的工作。这项工作包括通过网络请求访问资源或对操作系统进行系统调用。需要访问数据库的线程将是 IO密集型。包括同步事件(互斥体、原子),这会导致线程处于等待状态。
GMP协作
1、一般调度
当 M 绑定 P 时,就会开始调度执行 P 的 LRQ 中的 G。
当执行 61 ticks,或者 LRQ 没有 G 时,就会消费 GRQ 或者其他 LRQ 中 G。
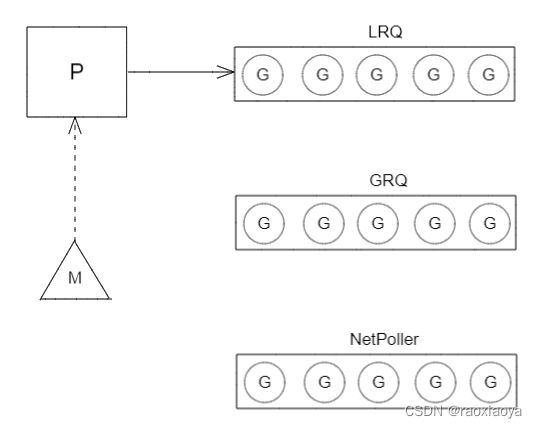
2、异步系统调用
当 G 需要执行异步网络IO时,M 会把它扔给 NetPoller 管理,然后从 LRQ 中重新取一个 G 来处理。
NetPoller 通过 epoll 等函数,由监控线程 sysmon 定期询问。异步网络系统调用由 NetPoller 完成的。当某个 G 的异步系统调用完成后,该 G 就会被扔进原先的 P 的 LRQ 中,等待被再次调度。这里最大的好处是,要执行网络系统调用,不需要额外的 M。因为网络轮询器 NetPoller 有一个操作系统线程,它正在处理一个有效的事件循环。
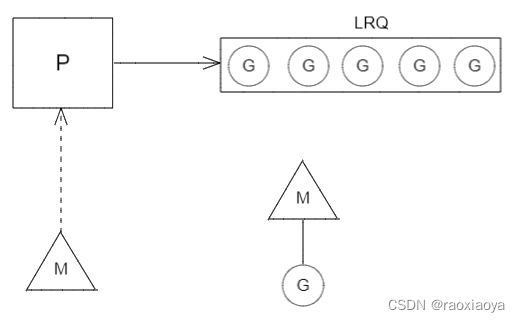
3、同步系统调用
当 G 进行同步系统调用(比如文件IO),将会阻塞 M,这是无法避免的,因为要同步等待调用结果, 该 M 是没有办法为其他 G 提供服务的。此时,该 M 对 P 而言就是没有意义的。(P 的意义是约束运行中的 M 的个数)
所以,GoLang 会将阻塞的 M 和 G 从 P 解绑,然后给 P 创建(或者从线程缓存中取出)一个新的 M。这样就能保证运行中的 M 的数量等于 P 的总数。
当同步系统调用完成后,G 被放回原先的 LRQ,M 必须尝试去绑定到一个 P。
4、窃取工作
为了提高整体效率,如果某个 P 的 LRQ 为空,那么它会去窃取其他 P 的 LRQ 和 GRQ 上面的 G。取的量为其的一半,如果最终所有的 P 的 LRQ 都是空的,那么就会去窃取 GRQ 中的 G。
上下文切换
在内核上交换线程的物理行为称为上下文切换。当调度程序从核心中拉出一个执行线程(Executing)并用一个可运行线程(Runnable)替换它时,就会发生上下文切换。从运行队列中选择的线程进入执行状态。被拉出的线程可以移回可运行状态(如果它仍然具有运行能力),或进入等待状态(如果由于 IO-Bound 类型的请求而被替换)。
上下文切换被认为是昂贵的,因为在内核上和内核上交换线程需要时间。上下文切换期间的潜在延迟量取决于不同的因素,但它在1000 ~1500 纳秒之间并不是不合理的。考虑到硬件应该能够合理地执行(平均)每个内核每纳秒 12 条指令,上下文切换可能会花费您 12k ~18k 指令的延迟。从本质上讲,您的程序在上下文切换期间失去了执行大量指令的能力。
如果您有一个专注于 IO-Bound 工作的程序,那么上下文切换将是一个优势。一旦一个线程进入等待状态,另一个处于可运行状态的线程就会代替它。这允许核心始终在工作。这是调度最重要的方面之一。如果有工作(处于可运行状态的线程)要完成,则不要让内核空闲。
如果您的程序专注于 CPU 密集型工作,那么上下文切换将是一场性能噩梦。由于 Thead 总是有工作要做,上下文切换正在阻止该工作的进行。这种情况与 IO-Bound 工作负载的情况形成鲜明对比。
- 关键字的使用
go:关键字go是你如何创建 Goroutines。一旦创建了一个新的 Goroutine,它就会给调度器一个机会来做出调度决定。 - 垃圾收集:由于 GC 使用自己的一组 Goroutines 运行,因此这些 Goroutines 需要在 M 上运行。这会导致 GC 造成大量的调度混乱。然而,调度器非常聪明地知道 Goroutine 正在做什么,它将利用这种智能来做出明智的决定。一个明智的决定是在 GC 期间将想要接触堆的 Goroutine 与那些不接触堆的 Goroutine 进行上下文切换。当 GC 运行时,会做出很多调度决策。
- 系统调用:如果 Goroutine 进行系统调用会导致 Goroutine 阻塞 M,有时调度程序能够将 Goroutine 从 M 上进行上下文切换,并将新的 Goroutine 上下文切换到同一个 M 上。但是,有时新的 M 是需要继续执行在 P 中排队的 Goroutines。下一节将更详细地解释这是如何工作的。
- 同步和编排:如果原子、互斥或通道操作调用将导致 Goroutine 阻塞,调度程序可以上下文切换一个新的 Goroutine 来运行。一旦 Goroutine 可以再次运行,它就可以重新排队并最终在 M 上切换回上下文。
关于上下文切换,举一个例子
想象一个用 C 语言编写的多线程应用程序,其中程序正在管理两个操作系统线程,这些线程彼此来回传递消息。
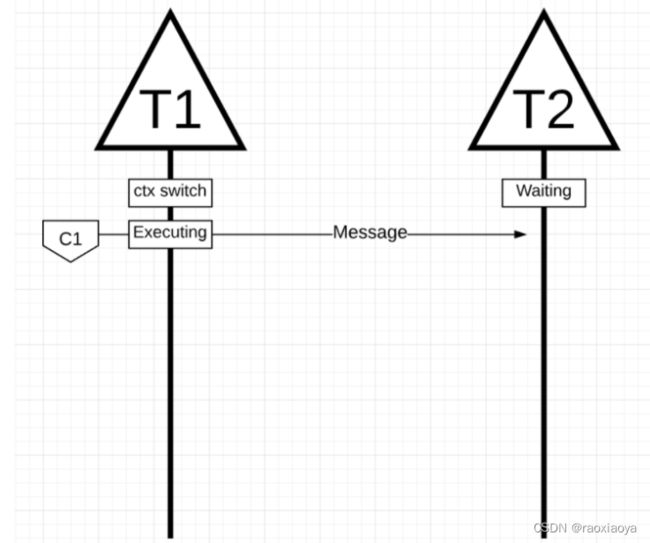
图中,有 2 个线程来回传递消息。线程 1 在核心 1 上进行上下文切换,现在正在执行,这允许线程 1 将其消息发送到线程 2。
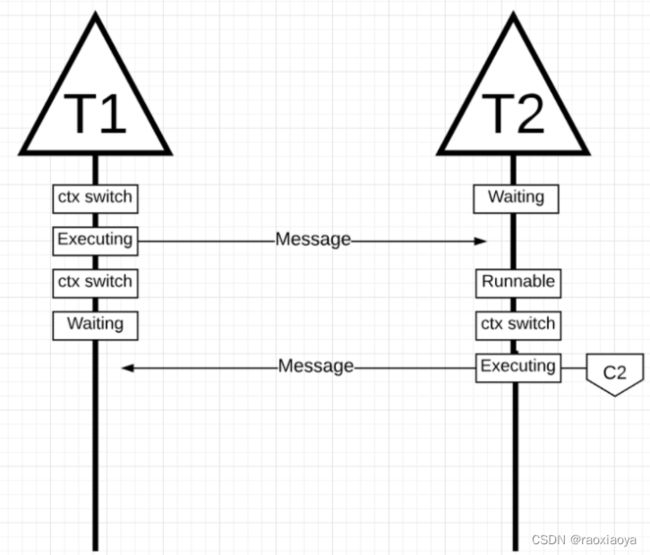
图中,一旦线程 1 完成发送消息,它现在需要等待响应。这将导致线程 1 被上下文关闭核心 1 并进入等待状态。一旦线程 2 收到有关消息的通知,它就会进入可运行状态。现在操作系统可以执行上下文切换并让线程 2 在核心上执行,它恰好是核心 2。接下来,线程 2 处理消息并将新消息发送回线程 1。
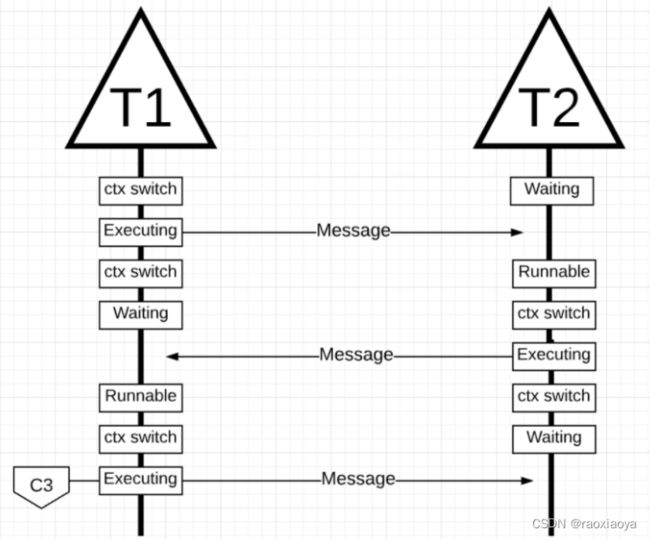
当线程 2 的消息被线程 1 接收时,线程再次进行上下文切换。现在线程 2 从执行状态切换到等待状态,线程 1 从等待状态切换到可运行状态最后回到执行状态,这允许它处理并发送新消息。
所有这些上下文切换和状态更改都需要时间来执行,这限制了完成工作的速度。由于每个上下文切换可能会导致约 1000 纳秒的延迟,并且希望硬件每纳秒执行 12 条指令,您正在查看或多或少的 12k 条指令,这些指令在这些上下文切换期间未执行。由于这些线程也在不同的核心之间弹跳,因此由于缓存线未命中而导致额外延迟的可能性也很高。
如果我们将T1和T2使用协成G1和G2来代替,就会发现,G 的阻塞并不会导致 M 挂起和上下文切换,甚至可以在一个时间片之内完成 G1 和 G2 之间的通讯。所以使用协程代替操作系统线程会大大降低内核线程切换的频率,当然,协程的切换也会存在上下文的切换和挂起,但这是在用户态内部的,代价要小很多。经过这个分析,我们意识到,我们并不需要太多线程,因为在协程的调度下,每个线程都无比忙碌,着也会导致CPU很忙碌,因此我们只需要将线程数设置为逻辑CPU个数即可。
GMP 的源代码结构位于src/runtime/runtime2.go
几个重要的函数
runtime.schedule 参考文献 [24]
(1)从 TLS 获取当前正在运行的 G 的信息
(2)M 是否绑定到当前的 G(同步系统调用)?M 让出绑定的 P ,等待同步系统调用的 G 结束
(3)GC?STW(stop the word) for GC
(4)当前 P 每执行 61 ticks,从 GRQ 取一定量的 G 加入 LRQ 中
(5)从 LRQ 获取可执行的 G
(6)如果当前的 LRQ 没有 G, 则从 GRQ 或者其他 P 的 LRQ 抢 G 来调度执行
(7)如果都没有找到 G,当前 M 让出占用的 P, 进入休眠状态
runtime.mainPC(runtime.main) 参考文献[20]
(1)限制最大栈大小: Max stack size is 1 GB on 64-bit, 250 MB on 32-bit
(2)创建一个不需要绑定 P 的 M,,执行 sysmon 函数
(3)创建 GC goroutine,启动 GC
(4)运行 package main 的 main 函数
(5)一系列的收尾操作
runtime.sysmon 参考文献[21]
(1)获取 NetPoller 中已完成操作的 G,将其加入 GRQ 中
(2)retake:
- 抢占长时间运行的 G
- 回收被 syscall 长时间阻塞的 P
参考
- https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part1.html
- https://blog.csdn.net/yanglingwell/article/details/103538730
- [1] A Quick Guide to Go’s Assembler
- [2] Lecture 4: x86_64 Assembly Language
- [3] http://visualgdb.com/gdbreference/commands/info_files)
- [4] 探索golang程序启动过程
- [5] Compile packages and dependencies
- [6] _rt0_amd64_linux function
- [7] _rt0_amd64 function
- [8] runtime·rt0_go function
- [9] Notes on the Go 1.4 Run-Time
- [10] runtime.schedinit funtion
- [11] runtime.newproc funtion
- [12] runtime.mstart funtion
- [13] runtime.main funtion
- [14] the definition of G, M, P
- [15] Concurrency, Goroutines and GOMAXPROCS
- [16] The Go scheduler
- [17] Scheduling In Go : Part II - Go Scheduler
- [18] Thread-local storage - Wikipedia
- [19] findrunnable function
- [20] runtime.mainPC
- [21] runtime.sysmon
- [22] runtime.retake
- [23] runtime.preemptone
- [24] runtime.schedule