1.nodejs安装部署及快速入门
文章目录
- 1. 重点提炼
- 2. 简介
-
- 2.1 Node.js介绍
- 2.2 安装Node.js
- 3. 服务端和客户端
-
- 3.1 引例
- 3.2 使用nodejs搭建服务器
- 4. 模块化
- 5. Node.js中的模块化 commonjs规范
-
- 5.1 实例
-
- 5.1.1 example01-1
- 5.1.2 example01-2
- 5.1.3 example01-3
- 5.1.4 example01-4
- 5.1.5 example01-5
- 5.1.6 example01-6
- 5.1.7 example01-7
- 6. npm包管理器
- 7. fs模块
-
- 7.1 文件操作
-
- 7.1.1 文件写入
- 7.1.2 文件读取
- 7.1.3 文件删除
- 7.1.4 复制文件
-
- 7.1.4.1 原理
- 7.1.5 文件重命名
- 7.1.6 判断文件是否存在
- 7.2 目录操作
-
- 7.2.1 创建目录
- 7.2.2 修改目录名称
- 7.2.3 读取目录
- 7.2.4 删除空目录
- 7.3 判断文件或者目录是否存在
- 7.4 获取文件或者目录的详细信息
- 7.5 判断是否为目录还是文件
- 8. 如何删除非空目录
- 9. buffer缓冲区
- 10. stream流
1. 重点提炼
- nodejs的安装及使用
- 服务端及客户端
- 通过Node.js搭建服务器
- 模块化及自定义模块
- commonjs规范
- fs模块的使用(文件操作及目录操作)
- stream
- buffer
2. 简介
2.1 Node.js介绍
Node.js 诞生于2009年,Node.js采用C++语言编写而成,是 一个Javascript的运行环境。Node.js实际就是js,并不是一个框架。
Node.js 是一个基于Chrome V8 引擎的 JavaScript 运行环境 ,让JavaScript的运行脱离浏览器(客户)端,可以使用JavaScript语言书写服务器端代码。
2.2 安装Node.js
Node.js官网下载稳定版本,node偶数版本为稳定版本(推荐使用),奇数版本为非稳定版本。
- mac 直接安装 或者 brew(推荐使用Homebrew,它是一个软件管理工具)来安装
- 傻瓜式全部安装即可
- 安装完Node.js会自动安装NPM(Node Package Manager):包管理工具;
- 通过指令 node -v 来查看是否安装完成和查看node版本号;npm -v 来查看npm版本(windows下的环境变量安装时候会帮我们设置)。
安装的时候默认安装环境变量,如果没安上,可以手动复制过去。
cmd、vscode终端,还可以使用powershell

3. 服务端和客户端
3.1 引例
console.log('这是test.js');
这实际就是服务端的js,把其放入在node环境中执行的js实际就是nodejs。

之前我们习惯将其放在html中通过浏览器去执行,实际这是客户端的js,即原生的js。
服务端的语言是可以搭建服务器的,那如何用nodejs搭建服务器呢?
3.2 使用nodejs搭建服务器
//引入http模块
const http = require('http');
//创建一个服务器
const server = http.createServer((req, res) => {
res.write('hello world');
res.end()
});
//设置端口号
server.listen(3000);
node http.js
我将它运行在我的服务器上,远程链接。
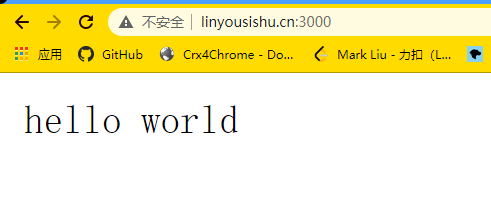
参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.01
Branch: branch01commit description:a0.01(使用nodejs搭建服务器)
tag:a0.01
如果修改代码,必须ctrl+c停止服务后重启服务才能生效。
推荐一个工具nodemon启动(修改代码,它能够自动帮助更新)
npm i nodemon -g 安装在全局
实际创建服务的就是服务端,访问的就是客户端,是很好的理解的。
注意:Google Chrome 默认非安全端口列表,尽量避免以下端口。
1, // tcpmux
7, // echo
9, // discard
11, // systat
13, // daytime
15, // netstat
17, // qotd
19, // chargen
20, // ftp data
21, // ftp access
22, // ssh
23, // telnet
25, // smtp
37, // time
42, // name
43, // nicname
53, // domain
77, // priv-rjs
79, // finger
87, // ttylink
95, // supdup
101, // hostriame
102, // iso-tsap
103, // gppitnp
104, // acr-nema
109, // pop2
110, // pop3
111, // sunrpc
113, // auth
115, // sftp
117, // uucp-path
119, // nntp
123, // NTP
135, // loc-srv /epmap
139, // netbios
143, // imap2
179, // BGP
389, // ldap
465, // smtp+ssl
512, // print / exec
513, // login
514, // shell
515, // printer
526, // tempo
530, // courier
531, // chat
532, // netnews
540, // uucp
556, // remotefs
563, // nntp+ssl
587, // stmp?
601, // ??
636, // ldap+ssl
993, // ldap+ssl
995, // pop3+ssl
2049, // nfs
3659, // apple-sasl / PasswordServer
4045, // lockd
6000, // X11
6665, // Alternate IRC [Apple addition]
6666, // Alternate IRC [Apple addition]
6667, // Standard IRC [Apple addition]
6668, // Alternate IRC [Apple addition]
6669, // Alternate IRC [Apple addition]
4. 模块化
require 是commonJs规范的引入,而import是es6的语法标准,最终也会经过babel编译为require。
实际在html中引用js的时候,会存在一个问题,就是变量污染问题,早期为了解决这个问题。为了让不同文件拥有不同的命名空间,就有了很多规范。nodeJS的CommonJS规范会帮助我们对每一个文件进行模块化(各自有各自的命名空间,是相互独立的),消除了变量污染。
客户端也有自己模块化手段:
AMD sea.js ; CMD require.js
5. Node.js中的模块化 commonjs规范
-
CommonJS就是为JS的表现来制定规范,因为js没有模块的功能所以CommonJS应运而生,它希望js可以在任何地方运行,不只是浏览器中。
1、创建自定义模块
-
引入一个文件 形式模块
home.js执行文件
//通过require来引入 require("./aModule"); //注意一定要有"./",文件后缀可加可不加。amodule.js文件
console.log("我是amodule模块111"); -
引入文件夹形式模块
- home.js执行文件
require("./aModuledir"); //必须加"./"aModuleDir里的index.js文件,会自动查找文件夹下的index.js文件执行
console.log("我是aModule模块文件夹");- 当然也可以配置默认启动文件,在文件夹内新建package.json来指定执行文件
{ "name":"aModule", "version":"1.0.0", "main":"test.js" }
-
-
自定义模块的按需导出
通过module.exports 导出; ___dirname , __filename
module.exports = { a:"我是a的值", b(){ console.log("我是导出的b函数"); } }引入导出文件
let mymodule = require("bModule"); console.log(mymodule.a); mymodule.b();或者 通过 exports来导出
exports.fn = function(){ console.log("我是fn函数"); }导入文件
let myfn = require("bModule").fn; myfn(); // 或者 通过解构赋值 let { fn } = require("bModule"); fn(); -
模块加载的优先级 ,先文件再目录;
2、内置模块;
nodejs内置模块有:Buffer,C/C++Addons,Child Processes,Cluster,Console,Cr
ypto,Debugger,DNS,Domain,Errors,Events,File System,
Globals,HTTP,HTTPS,Modules,Net,OS,Path,Process,P unycode,Query Strings,Readline,REPL,Stream,String De coder,Timers,TLS/SSL,TTY,UDP/Datagram,URL, Utilities,V8,VM,ZLIB;
内置模块不需要安装,外置模块需要安装;
第三方模块,我们用npm下载。
5.1 实例
5.1.1 example01-1
引用模块 =>
index.js
console.log("我是index.js");
// 引入
let Ma = require("./Ma.js");
Ma.js
console.log("我是Ma.js文件");
在终端:nodemon index.js

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.02
Branch: branch01commit description:a0.02(example01-1——引用模块 )
tag:a0.02
5.1.2 example01-2
index.js
console.log("我是index.js");
// 引入
let Ma = require("./Ma.js");
console.log(a);
Ma.js
console.log("我是Ma.js文件");
let a = 10;
报错:这样就防止了多个文件变量之间的污染

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.03
Branch: branch01commit description:a0.03(example01-2——引用模块中变量出错 )
tag:a0.03
5.1.3 example01-3
如何把变量暴露出来呢?
可以将a导出一个对象,再从另一个模块获取。
index.js
console.log("我是index.js");
// 引入
let Ma = require("./Ma.js");
console.log(Ma.a)
Ma.js
console.log("我是Ma.js文件");
let a = 10;
// 导出一个对象
module.exports = {
a
}

也可导出多个,可以导出变量,也可导出类。
Ma.js
console.log("我是Ma.js文件");
let a = 10;
class Person{
constructor(){
this.name = "张三";
}
hobby(){
console.log("喜欢篮球");
}
}
module.exports = {
a,
Person
}
index.js
console.log("我是index.js");
// 引入
let Ma = require("./Ma.js");
console.log(Ma.a)
let cai = new Ma.Person();
cai.hobby();
这种导出实际是按需导出。

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.04
Branch: branch01commit description:a0.04(example01-3——模块内导出 )
tag:a0.04
5.1.4 example01-4
注意引入文件作为模块化对象,“./”不能省略,但是可以省略“.js”。
let Ma = require("Ma.js"); // fail
let Ma = require("./Ma"); // success
同时也可以用以下方法导出:
exports.a = a;
exports.Person = Person;
exports 是 module.exports 的引用;
注意:exports不能直接导出一个对象,而是用module.exports导出。
模块之间都可以相互引入的。
index.js
console.log("我是index.js");
// 引入
let Ma = require("./Ma.js");
console.log(Ma.a)
let cai = new Ma.Person();
cai.hobby();
Ma.js
console.log("我是Ma.js文件");
require("./Mb");
let a = 10;
class Person{
constructor(){
this.name = "张三";
}
hobby(){
console.log("喜欢篮球");
}
}
exports.a = a;
exports.Person = Person;
Mb.js
console.log("我是模块b");

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.05
Branch: branch01commit description:a0.05(example01-4——模块间相互引入)
tag:a0.05
5.1.5 example01-5
模块引入多了比较混乱,我们一般可以通过目录的形式包装:
我们新建一个home目录,新建三个js文件:
index.js(主入口)
console.log("我是index.js");
require("./a");
require("./b");
a.js(依赖模块)
console.log("我是a.js")
b.js(依赖模块)
console.log("我是b.js")
我们在外部可以以目录的形式引入:
require("./home");
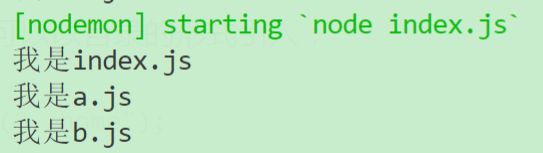
参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.06
Branch: branch01commit description:a0.06(example01-5——优化模块间相互引入)
tag:a0.06
5.1.6 example01-6
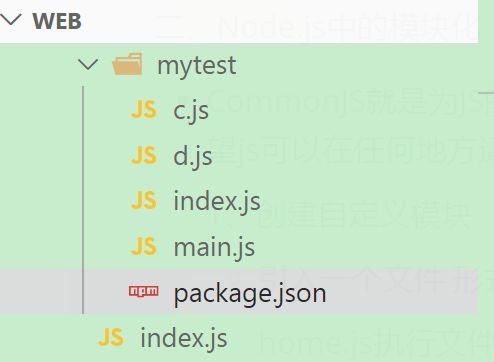
除此之外,node还提供一个文件夹来管理各个模块(主要针对第三方,当然自定义的也可以放入的):

mytest/index.js
require("./c.js");
require("./d.js");
module.exports = {
a:10,
b(){
console.log("我是 b fn");
}
}
c.js
console.log('c.js');
d.js
console.log('d.js');
外部index.js
node_modules里的模块,注意这里不用“./”。
// node_modules里的模块;
// 注意这里不用“./”
let {a,b} = require("mytest");
console.log(a);
b();

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.07
Branch: branch01commit description:a0.07(example01-6——node_modules的使用)
tag:a0.07
5.1.7 example01-7
很多情况下,我们都在文件模块下添加一个描述性的文件:(包含描述和功能)
{
"name":"mytest",
"version":"1.0",
"main":"main.js"
}
// main:主入口,如果找不到,就找默认的index.js
main.js
console.log('我是main.js');
外部index.js
require("mytest");

注意:一般情况下,都会把我们引入的第三方模块放入node_modules文件夹中,第三方模块借助包管理器即可。实际node遵循规则即是按需安装,不会一次性全部给我们使用。
const http = require(“http”); 为啥node_modules文件夹没有http,这个http是哪里来的呢?因为http模块是内置模块,或者称为官方模块,它已经继承在nodejs里了。
参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.08
Branch: branch01commit description:a0.08(example01-7——package.json的使用)
tag:a0.08
6. npm包管理器
NPM(Node Package Manager) 官网的地址是 npm官网 (安装node的时候就装上npm了),借助它管理第三方模块。
- npm常用指令;
-
npm init:引导创建一个package.json文件{ "name": "code01", "version": "1.0.0", "description": "", "main": "index.js", "dependencies": { "jquery": "^3.5.1", "cookie": "^0.4.1" }, "devDependencies": {}, "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "author": "", "license": "ISC" } -
npm help(npm -h) :查看npm帮助信息
-
npm version (npm -v): 查看npm版本; -
npm search:查找
-
npm install (npm i):安装 默认在当前目录,如果没有node_modules 会创建文件夹; => 其实这里默认执行的是npm install module_name --save
npm i cookie
参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.09
Branch: branch01commit description:a0.09(npm简单使用)
tag:a0.09
npm install module_name -S或者–save 即 npm install module_name --save 写入dependenciesnpm install module_name -D或者 —save-dev 即 npm install module_name --save-dev 写入devDependenciesnpm install module_name -g全局安装(命令行使用),否则默认是局部安装;- 指定版本安装模块
npm i module_name @1.0通过 "@"符号指定;
-
npm update(npm -up):更新
-
npm remove或者npm uninstall:删除我们可以删除一个包:npm remove/uninstall cookie
"dependencies"中的cookie就没了。
"dependencies": { "jquery": "^3.5.1" },
参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.10
Branch: branch01commit description:a0.10(example01-7——包卸载)
tag:a0.10
-
npm root查看当前包安装的路径 或者通过npm root -g来查看全局安装路径;
-
注意:dependencies => 运行依赖
在package.json文件写入dependencies(运行依赖<如:jquery、vue、react、axios>:开发的时候需要,上线后也需要。)
devDependencies => 开发依赖
在package.json文件写入devDependencies(开发依赖如:sass less 只是开发的时候使用,最终打包后编译成css,即线上发布里不会存在sass和less,则对应的包也没有用了:node开发可以安装很多工具,有些工具是开发的时候用,而真正产品上线的时候不需要用它。)
note 在传项目的时候,不需要传node_modules文件夹,只需要有package.json就行了,然后用“install i / yarn”自动查找各种依赖,然后安装。
假如当前目录下没有node_modules,但是却可以找到第三方模块,node_modules会一层一层查找。
首先在当前目录下没有找到node_modules(当前文件夹下),则出来往上一层找,最终一层层往上,找到系统根目录的node_modules(npm root -g 可以),最终找到了我们需要的该第三方模块。
7. fs模块
fs模块是node的内部比较重要的模块,实际上原生nodejs的网页加载就是通过fs模块进行的,先读取然后写入到浏览器上。
fs是文件操作模块,所有文件操作都是有同步和异步之分,特点是同步会加上 “Sync” 如:异步读取文件 “readFile”,同步读取文件 “readFileSync”;
fs模块操作 => 增、删、改、查
fs的操作细分为
- 文件操作
- 目录(文件夹)操作
7.1 文件操作
7.1.1 文件写入
fs.writeFile 写入操作 => 四个参数
path:写入的文件
data:写入的数据
options:配置项 (可选)
callback:回调函数 err 是否有错误
const fs = require("fs");
fs.writeFile("1.txt","我是1.txt文件",function(err){
if(err){
console.log(err);
}else{
console.log("添加成功");
}
})


参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.11
Branch: branch01commit description:a0.11(文件操作——文件写入)
tag:a0.11
文件内容覆盖
fs.writeFile("1.txt","我是1.txt文件11111",function(err){
if(err){
console.log(err);
}else{
console.log("添加成功");
}
})
内容则被覆盖了:

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.12
Branch: branch01commit description:a0.12(文件操作——文件写入-文件内容覆盖)
tag:a0.12
文件内容写入追加
使用第三个配置项参数 =>
flag =>
a追加写入 w(默认)写入(覆盖) r读取
fs.writeFile("1.txt","我是追加的文字",{flag:"a"},function(err){
if(err){
console.log(err);
}else{
console.log("添加成功");
}
})

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.13
Branch: branch01commit description:a0.13(文件操作——文件写入-文件内容写入追加)
tag:a0.13
7.1.2 文件读取
文件读取:readFile
path:读取的文件
第二个参数(可选):读取的格式(默认为二进制Buffer格式)
最后一个参数可传回调:err 是否有错误,data 读取到的数据
utf-8 格式读取文件。
fs.readFile("1.txt","utf-8",function(err,data){
if(err){
console.log(err);
}else{
console.log(data)
}
})

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.14
Branch: branch01commit description:a0.14(文件操作——文件读取-
utf-8格式读取文件)tag:a0.14
二进制 格式读取文件。
fs.readFile("1.txt",function(err,data){
if(err){
console.log(err);
}else{
console.log(data)
}
})

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.15
Branch: branch01commit description:a0.15(文件操作——文件读取-
二进制格式读取文件)tag:a0.15
也可以再从二进制转成文字(默认):
fs.readFile("1.txt",function(err,data){
if(err){
console.log(err);
}else{
console.log(data.toString());
}
})
注意:读写操作都是异步的(因为有回调),没有加sync的都是异步,否则是同步。
参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.16
Branch: branch01commit description:a0.16(文件操作——文件读取-
二进制格式读取文件-再解析为文本)tag:a0.16
7.1.3 文件删除
fs.unlink("2.txt",err=>{
if(err){
return console.log(err);
}
console.log("删除成功");
})
![]()
参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.17
Branch: branch01commit description:a0.17(文件操作——文件删除)
tag:a0.17
7.1.4 复制文件
fs.copyFile("fs.js","111.txt", err=>{
if(err){
return console.log(err);
}
console.log("复制成功!");
});
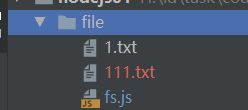

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.18
Branch: branch01commit description:a0.18(文件操作——文件复制)
tag:a0.18
7.1.4.1 原理
原理:先读取再写入的一个过程
同步实现
function mycopy(src, dest){
fs.writeFileSync(dest,fs.readFileSync(src));
}
mycopy("1.txt","4.txt");
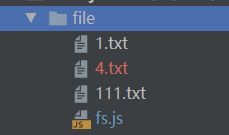
参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.19
Branch: branch01commit description:a0.19(文件操作——文件复制之原理实现)
tag:a0.19
7.1.5 文件重命名
修改文件名,目录也可以通过rename来操作
fs.rename("1.txt","5.txt",function (err) {
if(err){
console.log(err);
}else{
console.log("修改成功");
}
});


参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.20
Branch: branch01commit description:a0.20(文件操作——文件重命名)
tag:a0.20
7.1.6 判断文件是否存在
fs.exists("4.txt",function (exists) {
console.log(exists);
})
![]()
参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.21
Branch: branch01commit description:a0.21(文件操作——判断文件是否存在)
tag:a0.21
7.2 目录操作
同步操作也是加Sync
7.2.1 创建目录
fs.mkdir("我的目录", err=>{
if(err){
console.log(err);
}else{
console.log("创建目录成功");
}
})

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.22
Branch: branch01commit description:a0.22(目录操作——创建目录)
tag:a0.22
7.2.2 修改目录名称
fs.rename("我的目录", "xd的目录", err=>{
if(err){
console.log(err);
}else{
console.log("修改目录成功");
}
});
参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.23
Branch: branch01commit description:a0.23(目录操作——修改目录名称)
tag:a0.23
7.2.3 读取目录
fs.readdir("xd的目录", (err, data)=>{
if(err){
console.log(err);
}else{
console.log(data);
}
});

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.24
Branch: branch01commit description:a0.24(目录操作——读取目录)
tag:a0.24
7.2.4 删除空目录
fs.rmdir('xd的目录', err=>{
if(err){
console.log(err);
}else{
console.log("删除目录成功");
}
});
注意:删除的必须是**空文件夹/目录**

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.25
Branch: branch01commit description:a0.25(目录操作——删除目录失败)
tag:a0.25
fs.rmdir('123', err=>{
if(err){
console.log(err);
}else{
console.log("删除目录成功");
}
});
![]()
参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.26
Branch: branch01commit description:a0.26(目录操作——删除空目录)
tag:a0.26
7.3 判断文件或者目录是否存在
目录和文件的通用方法
fs.exists("xd的目录", exists=>{
console.log(exists);
})

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.27
Branch: branch01commit description:a0.27(判断文件或者目录是否存在)
tag:a0.27
7.4 获取文件或者目录的详细信息
fs.stat("filesystem.js", (err, stat)=>{
if(err){
console.log(err);
}else{
console.log(stat);
}
});
打印信息
Stats {
dev: 439228,
mode: 33206,
nlink: 1,
uid: 0,
gid: 0,
rdev: 0,
blksize: 4096,
ino: 1970324838805979,
size: 897,
blocks: 8,
atimeMs: 1600706689435.417,
mtimeMs: 1600706689435.417,
ctimeMs: 1600706689435.417,
birthtimeMs: 1600705761555.937,
atime: 2020-09-21T16:44:49.435Z,
mtime: 2020-09-21T16:44:49.435Z,
ctime: 2020-09-21T16:44:49.435Z,
birthtime: 2020-09-21T16:29:21.556Z
}
参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.28
Branch: branch01commit description:a0.28(获取文件或者目录的详细信息)
tag:a0.28
7.5 判断是否为目录还是文件
// 获取文件或者目录的详细信息
fs.stat("filesystem.js", (err, stat)=>{
if(err){
console.log(err);
}else{
console.log(stat);
}
// 判断文件是否是文件
let res = stat.isFile();
console.log(res);
// 判断文件是否是文件夹/目录
res = stat.isDirectory();
console.log(res);
});
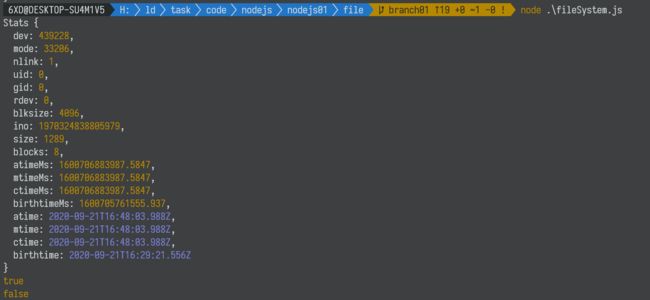
参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.29
Branch: branch01commit description:a0.29(判断是否为目录还是文件)
tag:a0.29
8. 如何删除非空目录
// 删除非空文件夹;
// 先把目录里的文件删除-->删除空目录;
function removeDir(path){
let data = fs.readdirSync(path);
for(let i=0;i<data.length;i++){
// 是文件或者是目录; --->?文件 直接删除 ---> ?目录继续查找;
let url = path + "/" + data[i];
let stat = fs.statSync(url);
if(stat.isDirectory()){
//目录 继续查找;
removeDir(url);
}else{
// 文件 删除
fs.unlinkSync(url);
}
}
// 删除空目录
fs.rmdirSync(path);
}
removeDir("xd的目录");
注意这里的删除是不经过回收站的,所以一定需要备份文件。
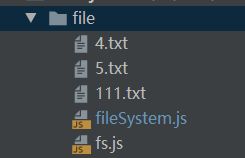
参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.30
Branch: branch01commit description:a0.30(如何删除非空目录)
tag:a0.30
9. buffer缓冲区
- buffer的创建
- 直接创建
- 数组创建
- 字符串创建
- 乱码的处理
- buffer转换tostring
buffer是一个类,实际它是一种数据格式,nodejs传输数据很多时候通过buffer转成二进制的数据,二进制数据在底层数据传输会非常快,并且也不分各种形式,传输效率很高。
注意:fs是node内置的模块,而buffer不是模块而是类。
// buffer创建
// new Buffer() //nodejs6.0之前版本的创建格式
let buffer = Buffer.alloc(10); // 指定大小(单位:字节)
console.log(buffer);

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.31
Branch: branch01commit description:a0.31(buffer创建)
tag:a0.31
通过字符串创建:
let buffer = Buffer.from("大家好");
console.log(buffer);
打印是以两位16进制进行呈现

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.32
Branch: branch01commit description:a0.32(buffer操作—通过字符串创建)
tag:a0.32
通过数组创建:
(注意:两位的16进制js不识别,所以手动再加两位,必须4位才识别)
let buffer = Buffer.from([0xe5,0xa4,0xa7,0xe5,0xae,0xb6,0xe5,0xa5,0xbd]);
console.log(buffer.toString());

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.33
Branch: branch01commit description:a0.33(buffer操作—通过数组创建)
tag:a0.33
3个字节代表一个中文字符,这里4个字节打印出来会乱码
let buffer1 = Buffer.from([0xe5,0xa4,0xa7,0xe5]);
let buffer2 = Buffer.from([0xae,0xb6,0xe5,0xa5,0xbd]);
console.log(buffer1.toString());
// 连接两个buffer
let newbuffer = Buffer.concat([buffer1,buffer2]);
console.log(newbuffer.toString());

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.34
Branch: branch01commit description:a0.34(buffer操作—中文乱码)
tag:a0.34
基于nodejs内置模块StringDecoder,更高一些的性能处理方式(处理乱码)
// 3个字节代表一个中文字符,这里4个字节打印出来会乱码
let buffer1 = Buffer.from([0xe5,0xa4,0xa7,0xe5]);
let buffer2 = Buffer.from([0xae,0xb6,0xe5,0xa5,0xbd]);
console.log(buffer1.toString());
// 基于nodejs内置模块StringDecoder,更高一些的性能处理方式(处理乱码)
let { StringDecoder } = require("string_decoder");
let decoder = new StringDecoder();
let res1 = decoder.write(buffer1); // 自动处理乱码,存乱码并隐藏
let res2 = decoder.write(buffer2);
console.log(res1);
console.log(res2);
console.log(res1+res2);// 连接的时候会把隐藏的乱码加进去一块连接

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.35
Branch: branch01commit description:a0.35(buffer操作—nodejs内置模块StringDecoder处理乱码,性能更好)
tag:a0.35
10. stream流
- stream流:流与数据处理方面密不可分
- 流的原理
- 流数据的获取
- pipe
- data
- end
- copy的流方法实现
- 加载视图的流方法实现
假若传递的文件特别大有两个g, 一次性就需要占两个g的带宽,传递过去,那一边电脑也需要占用2GB的内存,假设内存不足带宽不够就会导致传输失败,也可能导致内存溢出。因此为了解决这一问题,就引入了”流“。假如有2GB文件,系统会把它切割成很多的小块,像流水一样依次传递。可能一次性传1mb或2mb等等,然后接收端接收,最后存下来再开始传递第二份,不停地循环发。这样就避免了传递文件过程中,一次性占满CPU和内存了。
文件操作、post数据、文件上传等就应用了stream流。
文件操作
我是1.txt文件
const fs = require("fs");
let res = fs.readFileSync("1.txt");
console.log(res);

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.36
Branch: branch01commit description:a0.36(stream流—文件读取操作)
tag:a0.36
const fs = require("fs");
let res = fs.readFileSync("1.txt");
console.log(res.toString());

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.37
Branch: branch01commit description:a0.37(stream流—文件读取操作转成字符)
tag:a0.37
如果这个文件2GB,我的内存只有1GB,用以上方式读文件会致使内存溢出,机器奔溃。我们通过”流“来优化。
// stream 流;
const fs = require("fs");
// 创建可读流
let rs = fs.createReadStream("1.txt");
// on监听事件,读取的数据在data事件中
// 每次一小段一小段读取的chunk
rs.on("data",chunk=>{
console.log(chunk);
console.log(chunk.toString());
})
主要这里文件数据量不大,因此没有做数据流拆分。

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.38
Branch: branch01commit description:a0.38(stream流—stream流文件读取操作)
tag:a0.38
创建一个文件:
const fs = require("fs");
// 创建一个65kb的文件;不写内容
let buffer = Buffer.alloc(65*1024);
// 第一个参数是文件名
fs.writeFile("64kb",buffer,err=>{
if(err){
return console.log(err);
}
console.log("写入成功");
})

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.39
Branch: branch01commit description:a0.39(stream流—stream流写入文件)
tag:a0.39
let rs = fs.createReadStream("64kb");
// 每次一小段一小段读取的chunk
rs.on("data",chunk=>{
console.log(chunk);
})
打印了两个chunk,即拆分了两块。

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.40
Branch: branch01commit description:a0.40(stream流—stream流读取文件)
tag:a0.40
let num = 0;
rs.on("data",chunk=>{
num++;
console.log(num);
})
(65kb文件)拆分了两块。

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.41
Branch: branch01commit description:a0.41(stream流—stream流读取65kb文件切分为两块)
tag:a0.41
用同样方式创建一个64k的文件,我们再运行发现只执行了一次,因此流会把数据分成64kb的小文件传输。 => 提高文件传输性能。
const fs = require("fs");
let rs = fs.createReadStream("64kb(2)");
let num = 0;
rs.on("data",chunk=>{
num++;
console.log(num);
})
![]()
参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.42
Branch: branch01commit description:a0.42(stream流—stream流读取64kb文件切分为1块)
tag:a0.42
同时怎么知道文件读完了呢?假如不知道文件的大小呢!=> 触发end事件(相当于生命周期钩子)
// stream 流;
const fs = require("fs");
let rs = fs.createReadStream("1.txt");
let num = 0;
let str = "";
// 每次一小段一小段读取的chunk
rs.on("data",chunk=>{
num++;
str += chunk; // buffer加等于变成字符串
console.log(num);
})
// 流完成了;
rs.on("end",()=>{
console.log(str);
})

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.43
Branch: branch01commit description:a0.43(stream流—stream流读取完文件后触发的生命钩子)
tag:a0.43
流还可通过pipe(管道),把读取的数据导出到要写出的位置。
pipe(管道)来写,实际先读再写,即复制的操作。
let rs = fs.createReadStream("1.txt");
let ws = fs.createWriteStream("2.txt");
rs.pipe(ws);

参考:https://github.com/6xiaoDi/blog-nodejs-novice/tree/a0.44
Branch: branch01commit description:a0.44(stream流—stream流复制文件使用管道)
tag:a0.44
(后续待补充)