Java专项练习二(选择题)
这里开始已经刷了200道题了!继续努力!
-
- 201、
- 202、下列不属于算法结构的是()
- 203、What will be printed when you execute the following code?
- 204、以下代码执行的结果显示是多少()?
- 205、 jre 判断程序是否执行结束的标准是()
- 206、以下代码执行的结果是多少()?
- 207、Java网络程序设计中,下列正确的描述是()
- 208、下面哪个语句是创建数组的正确语句?( )
- 209、下面有关java threadlocal说法正确的有?
- 210、下面的switch语句中,x可以是哪些类型的数据:()
- 211、只有实现了()接口的类,其对象才能序列化。
- 212、下列程序段的输出结果是:( )
- 213、请问所有的异常类皆直接继承于哪一个类?()
- 214、以下代码在编译和运行过程中会出现什么情况
- 215、下面关于hibernate核心接口说明错误的是?
- 216、JDK中提供的java、javac、jar等开发工具也是用Java编写的。==对==
- 217、下面哪个不属于HttpServletResponse接口完成的功能?
- 218、如果希望监听TCP端口9000,服务器端应该怎样创建socket?
- 219、 下面哪个行为被打断不会导致InterruptedException:( )?
- 220、下面代码的运行结果为:()
- 221、编译java程序的命令文件是( )
- 222、下列选项中属于面向对象设计方法主要特征的是( )。
- 223、在异常处理中,如释放资源,关闭数据库、关闭文件应由( )语句来完成。
- 224、以下代码的循环次数是==无限次==
- 225、在异常处理中,以下描述不正确的有
- 226、一个类的构造器不能调用这个类中的其他构造器。==错误==
- 227、运行结果为:
- 228、有如下代码:请写出程序的输出结果。
- 229、执行以下程序后的输出结果是()
- 230、设三个整型变量 x = 1 , y = 2 , z = 3,则表达式 y+=z--/++x 的值是( )。
- 231、下列程序的运行结果
- 232、关于protected 修饰的成员变量,以下说法正确的是
- 233、默认RMI采用的是什么通信协议?
- 234、下列说法正确的是( )
- 235、我们在程序中经常使用“System.out.println()”来输出信息,语句中的System是包名,out是类名,println是方法名。
- 236、执行如下程序,输出结果是( )
- 237、 关于 Socket 通信编程,以下描述错误的是:( )
- 238、java中下面哪个能创建并启动线程()
- 239、Which statement is true for the class java.util.ArrayList?
- 240、下列关于Java并发的说法中正确的是()
- 241、结构型模式中最体现扩展性的模式是()
- 242、关于数据库连接的程序,以下哪个语句的注释是错误的( )
- 243、What will happen when you attempt to compile and run the following code?
- 244、下列Java代码中的变量a、b、c分别在内存的____存储区存放。
- 245、存根(Stub)与以下哪种技术有关
- 246、如果Child extends Parent,那么正确的有()?
- 247、面向对象程序设计方法的优点包含:
- 248、关于下列代码的执行顺序,下面描述正确的有哪些选项()
- 249、常用的servlet包的名称是?
- 250、局部内部类可以用哪些修饰符修饰?
- 251、在程序代码中写的注释太多,会使编译后的程序尺寸变大。
- 252、关于异常处理机制的叙述正确的是()
- 253、 下列选项中,用于在定义子类时声明父类名的关键字是:( )
- 254、java中,用( )关键字定义常量?
- 255、 执行以下程序,最终输出可能是:
- 256、下面程序的输出是什么?
- 257、判断对错。在java的多态调用中,new的是哪一个类就是调用的哪个类的方法。
- 258、ResultSet中记录行的第一列索引为?
- 259、下面哪个描述正确? ()
- 260、下列哪些情况下会导致线程中断或停止运行( )
- 261、以下关于java封装的描述中,正确的是:
- 262、已知int a[]=new int[10],则下列对数组元素的访问不正确的是()
- 263、 在 java 中 , 一个类()
- 264、下面有关java classloader说法错误的是?
- 265、为AB类的一个无形式参数无返回值的方法method书写方法头,可以用AB.method()方式调用,该方法头的形式为( )。
- 266、哪个关键字可以对对象加互斥锁?()
- 267、下列程序执行后输出结果为( )
- 268、根据下面的程序代码,哪些选项的值返回true?
- 269、java接口的方法修饰符可以为?(忽略内部接口)
- 270、下面这段java代码,当 T 分别是引用类型和值类型的时候,分别产生了多少个 T对象和T类型的值()
- 271、看以下代码:
- 272、在jdk1.5之后,下列 java 程序输出结果为______。
- 273、下列哪个选项是Java调试器?如果编译器返回程序代码的错误,可以用它对程序进行调试。
- 274、以下哪一个不是赋值符号?
- 275、java8中,下面哪个类用到了解决哈希冲突的开放定址法
- 276、 下列不是 Java 关键字的是 ( )
- 277、Java是一门支持反射的语言,基于反射为Java提供了丰富的动态性支持,下面关于Java反射的描述,哪些是错误的:( )
- 278、以下哪些方法可以取到http请求中的cookie值()?
- 279、Java语言中,下面哪个语句是创建数组的正确语句?( )
- 280、关于Java中的数组,下面的一些描述,哪些描述是准确的:( )
- 281、 下列描述中,错误的是( )
- 282、java语言中的数组元素下标总是从0开始,下标可以是整数或整型表达式。()
- 283、一个以”.java”为后缀的源文件
- 284、针对下面的代码块,哪个equal为true:()
- 285、下列关于异常处理的描述中,错误的是()。
- 286、语句:char foo='中',是否正确?(假设源文件以GB2312编码存储,并且以javac – encoding GB2312命令编译)
- 287、已知如下类说明:
- 288、要求匹配以下16进制颜色值,正则表达式可以为: #ffbbad #Fc01DF #FFF #ffE
- 289、有以下类定义:
- 290、下面哪种流可以用于字符输入:
- 291、下列说法正确的是
- 292、以下哪一个正则表达式不能与字符串“https://www.tensorflow.org/”(不含引号)匹配?()
- 293、面向对象的基本特征是()
- 294、Java中的集合类包括ArrayList、LinkedList、HashMap等类,下列关于集合类描述正确的是()
- 295、关于equals和hashCode描述正确的是 ()
- 296、Choose the correct ones from the following statements:
- 297、下面哪些情况可以引发异常:
- 298、以下关于final关键字说法错误的是()
- 299、CMS垃圾回收器在那些阶段是没用用户线程参与的
- 300、在Java语言中,下列关于字符集编码(Character set encoding)和国际化(i18n)的问题,哪些是正确的?
- 301、 下列程序段执行后t3的结果是()。
- 302、 Java 源程序文件的扩展名为()
- 303、 如果一个接口Cow有个方法drink(),有个类Calf实现接口Cow,则在类Calf中正确的是? ( )
- 304、运行代码,结果正确的是:
- 305、以下声明合法的是
- 306、下面程序段的时间复杂度是()
- 307、Given the following code:
- 308、下面哪一项不是加载驱动程序的方法?
- 309、单例模式中,两个基本要点是
- 310、java中关于继承的描述正确的是()
- 311、(C#、JAVA)扩展方法能访问被扩展对象的public成员(==能==)
- 312、 以下关于继承的叙述正确的是
- 313、 下列修饰符中与访问控制权限无关的是?( )
- 314、以下哪个接口的定义是正确的?( ==D==)
- 315、关于AOP错误的是?
- 316、 导出类调用基类的构造器必须用到的关键字: ( )
- 317、静态内部类不可以直接访问外围类的非静态数据,而非静态内部类可以直接访问外围类的数据,包括私有数据。==√==
- 318、对于以下代码段,4个输出语句中输出true的个数是(==3==)。
- 319、在jdk 1.7中,以下说法正确的是( )。
- 320、Java表达式"13 & 17"的结果是什么?()
- 321、在Java图形用户界面编程中,如果需要显示信息,一般是使用__________类的对象来实现。
- 322、以下哪个类包含方法flush()?()
- 323、面向对象方法的多态性是指()
- 324、如何获取ServletContext设置的参数值?
- 325、下面关于程序编译说法正确的是()
- 326、以下代码段执行后的输出结果为 ==1,3,2==
- 327、下面有关java类加载器,说法正确的是?
- 328、下列代码片段中,存在编译错误的语句是(==语句1,3,4==)
- 329、下面哪个不是Java的关键字?
- 330、下列那些方法是线程安全的(所调用的方法都存在)
- 331、以下有关构造方法的说法,正确的是:(==A==)
- 332、以下程序的输出结果是==A==
- 333、在 main() 方法中给出的字节数组,如果将其显示到控制台上,需要(==A== )。
- 334、以下哪个I / O类可以附加或更新文件(==A==)
- 335、Math.floor(-8.5)=(==D== )
- 336、下面代码运行结果是?(==A==)
- 337、以下哪个式子有可能在某个进制下成立()?
- 338、jdk1.8版本之前的前提下,接口和抽象类描述正确的有()
- 339、Java是一门支持反射的语言,基于反射为Java提供了丰富的动态性支持,下面关于Java反射的描述,哪些是错误的:( )
- 340、以下哪几种方式可用来实现线程间通知和唤醒:( )
- 341、 有以下代码片段:
- 342、请问以下代码运行结果是:
- 343、以下代码执行的结果显示是多少()?
- 344、设int x=1,float y=2,则表达式x/y的值是:()
- 345、下面程序的结果是
- 346、哪个类可用于处理 Unicode?
- 347、要使某个类能被同一个包中的其他类访问,但不能被这个包以外的类访问,可以( )
- 348、运行代码,输出的结果是()
- 349、 下面哪些具体实现类可以用于存储键,值对,并且方法调用提供了基本的多线程安全支持:( )
- 350、mysql数据库,game_order表表结构如下,下面哪些sql能使用到索引()?
- 351、下面程序段执行完成后,则变量sum的值是( )。
- 352、定义类中成员变量时不可能用到的修饰是()
- 353、建立Statement对象的作用是?
- 354、根据以下接口和类的定义,要使代码没有语法错误,则类Hero中应该定义方法( )。
- 355、一个Java源程序文件中定义几个类和接口,则编译该文件后生成几个以.class为后缀的字节码文件。
- 356、关于ASCII码和ANSI码,以下说法不正确的是()?
- 357、java程序内存泄露的最直接表现是( )
- 358、下列语句中,正确的是
- 359、以下关于final关键字说法错误的是()
- 360、关于volatile关键字,下列描述不正确的是?
- 361、下面有关JDK中的包和他们的基本功能,描述错误的是?
- 362、接口不能扩展(继承)多个接口。( )
- 363、上述代码返回结果为:
- 364、假设num已经被创建为一个ArrayList对象,并且最初包含以下整数值:[0,0,4,2,5,0,3,0]。 执行下面的方法numQuest(),最终的输出结果是什么?
- 365、以下 _____ 不是 Object 类的方法
- 366、以下代码的输出的正确结果是
- 367、在Java中,关于HashMap类的描述,以下错误的是()?
- 368、从以下哪一个选项中可以获得Servlet的初始化参数?
- 369、下面代码运行结果是?
- 370、 在 Java 中,属于整数类型变量的是()
- 371、以下哪一项正则能正确的匹配网址: http://www.bilibili.com/video/av21061574 ()
- 372、类A1和类A2在同一包中,类A2有个protected的方法testA2,类A1不是类A2的子类(或子类的子类),类A1可以访问类A2的方法testA2。(==√== )
- *373、输出结果为:
- 374、下面代码将输出什么内容:()
- 375、以下代码结果是什么?
- 376、说明输出结果。
- 377、根据下面这个程序的内容,判断哪些描述是正确的:( )
- 378、 String s=null;下面哪个代码片段可能会抛出NullPointerException?
- 379、关于身份证号,以下正确的正则表达式为( )
- 380、下面语句正确的是()
- 381、已知如下类定义:
- 382、能用来修饰interface的有()
- 383、在Web应用程序的文件与目录结构中,web.xml是放置在( )中。
- 384、下面程序的运行结果:()
- *385、下面代码的执行结果是 :
- 386、以下程序段的输出结果为:
- 387、 关于访问权限,说法正确的是? ( )
- 388、假设有以下代码String s = "hello";String t = "hello";char c [ ] = {'h','e','l','l','o'};下列选项中返回false的语句是?
- *389、以下代码执行的结果显示是多少( )?
- *390、下面对静态数据成员的描述中,正确的是
- 391、下面哪些语法结构是正确的?
- 392、final、finally、finalize三个关键字的区别是()
- 393、下列关于JAVA多线程的叙述正确的是()
- 394、下面有关Java的说法正确的是( )
- 395、下列可作为java语言标识符的是()
- 396、下列说法正确的有( )
- 397、下面有关forward和redirect的描述,正确的是() ?
- *398、关于运行时常量池,下列哪个说法是正确的
- 399、下面有关值类型和引用类型描述正确的是()?
- 400、 在java中,在同一包内,类Cat里面有个公有方法sleep(),该方法前有static修饰,则可以直接用Cat.sleep()。(==对==)
201、
int i, sum=0;
for(i=0;i<10;++i,sum+=i); i 的最终结果是?
A、10
B、9
C、11
D、以上答案都不正确
202、下列不属于算法结构的是()
A、输入数据
B、处理数据
C、存储数据
D、输出结果
解析:算法包括0个或多个输入,1个或多个输出,中间有穷个处理过程。
存储结构不属于算法结构
203、What will be printed when you execute the following code?
class C {
C() {
System.out.print("C");
}
}
class A {
C c = new C();
A() {
this("A");
System.out.print("A");
}
A(String s) {
System.out.print(s);
}
}
class Test extends A {
Test() {
super("B");
System.out.print("B");
}
public static void main(String[] args) {
new Test();
}
}
A、BB
B、CBB
C、BAB
D、None of the above
解析: 初始化过程是这样的:
1.首先,初始化父类中的静态成员变量和静态代码块,按照在程序中出现的顺序初始化;
2.然后,初始化子类中的静态成员变量和静态代码块,按照在程序中出现的顺序初始化;
3.其次,初始化父类的普通成员变量和代码块,在执行父类的构造方法;
4.最后,初始化子类的普通成员变量和代码块,在执行子类的构造方法;
(1)初始化父类的普通成员变量和代码块,执行 C c = new C(); 输出C
(2)super(“B”); 表示调用父类的构造方法,不调用父类的无参构造函数,输出B
(3) System.out.print(“B”);
所以输出CBB
204、以下代码执行的结果显示是多少()?

A、num * count = 505000
B、num * count = 0
C、运行时错误
D、num * count = 5050
解析:
count = count++ 原理是 temp = count; count = count+1 ; count = temp; 因此count始终是0 这仅限于java 与c是不一样的
205、 jre 判断程序是否执行结束的标准是()
A、所有的前台线程执行完毕
B、所有的后台线程执行完毕
C、所有的线程执行完毕
D、和以上都无关
解析:后台线程:指为其他线程提供服务的线程,也称为守护线程。JVM的垃圾回收线程就是一个后台线程。 前台线程:是指接受后台线程服务的线程,其实前台后台线程是联系在一起,就像傀儡和幕后操纵者一样的关系。傀儡是前台线程、幕后操纵者是后台线程。由前台线程创建的线程默认也是前台线程。可以通过isDaemon()和setDaemon()方法来判断和设置一个线程是否为后台线程。
206、以下代码执行的结果是多少()?
public class Demo {
public static void main(String[] args) {
Collection<?>[] collections =
{new HashSet<String>(), new ArrayList<String>(), new HashMap<String, String>().values()};
Super subToSuper = new Sub();
for(Collection<?> collection: collections) {
System.out.println(subToSuper.getType(collection));
}
}
abstract static class Super {
public static String getType(Collection<?> collection) {
return “Super:collection”;
}
public static String getType(List<?> list) {
return “Super:list”;
}
public String getType(ArrayList<?> list) {
return “Super:arrayList”;
}
public static String getType(Set<?> set) {
return “Super:set”;
}
public String getType(HashSet<?> set) {
return “Super:hashSet”;
}
}
static class Sub extends Super {
public static String getType(Collection<?> collection) {
return "Sub"; }
}
}
A、
Sub:collection
Sub:collection
Sub:collection
B、
Sub:hashSet
Sub:arrayList
Sub:collection
C、
Super:collection
Super:collection
Super:collection
D、
Super:hashSet
Super:arrayList
Super:collection
解析:这是静态分派的过程,在编译时已经决定了使用super的方法,因为subToSuper 是指super对象,可是为什么会选择collection呢,for循环出来他们实际上指的是collection对象表示的,即类似于Collection col = new HashSet<>();这样传入方法getType()中的参数就是col,左边是静态类型,右边是实际类型。由于重载实际上是使用静态分派的,重载时是通过参数的静态类型而不是实际类型作为判定依据的。详细参考深入理解java虚拟机248页解释。
207、Java网络程序设计中,下列正确的描述是()
A、Java网络编程API建立在Socket基础之上
B、Java网络接口只支持tcP以及其上层协议
C、Java网络接口只支持UDP以及其上层协议
D、Java网络接口支持IP以上的所有高层协议
208、下面哪个语句是创建数组的正确语句?( )
A、float f[][] = new float[6][6];
B、float []f[] = new float[6][6];
C、float f[][] = new float[][6];
D、float [][]f = new float[6][6];
E、float [][]f = new float[6][];
解析:数组命名时名称与[]可以随意排列,但声明的二维数组中第一个中括号中必须要有值,它代表的是在该二维数组中有多少个一维数组。 即数组声明,必须要明确行数,列数随意
209、下面有关java threadlocal说法正确的有?
A、ThreadLocal存放的值是线程封闭,线程间互斥的,主要用于线程内共享一些数据,避免通过参数来传递
B、从线程的角度看,每个线程都保持一个对其线程局部变量副本的隐式引用,只要线程是活动的并且 ThreadLocal 实例是可访问的;在线程消失之后,其线程局部实例的所有副本都会被垃圾回收
C、在Thread类中有一个Map,用于存储每一个线程的变量的副本
D、对于多线程资源共享的问题,同步机制采用了“以时间换空间”的方式,而ThreadLocal采用了“以空间换时间”的方式
210、下面的switch语句中,x可以是哪些类型的数据:()
switch(x)
{
default:
System.out.println("Hello");
}
A、long
B、char
C、float
D、byte
E、double
F、Object
解析:以java8为准,switch支持10种类型 基本类型:byte char short int 对于包装类 :Byte,Short,Character,Integer String enum 2、实际只支持int类型 Java实际只能支持int类型的switch语句,那其他的类型时如何支持的 a、基本类型byte char short 原因:这些基本数字类型可自动向上转为int, 实际还是用的int。 b、基本类型包装类Byte,Short,Character,Integer 原因:java的自动拆箱机制 可看这些对象自动转为基本类型 c、String 类型 原因:实际switch比较的string.hashCode值,它是一个int类型 如何实现的,网上例子很多。此处不表。 d、enum类型 原因 :实际比较的是enum的ordinal值(表示枚举值的顺序),它也是一个int类型 所以也可以说 switch语句只支持int类型
211、只有实现了()接口的类,其对象才能序列化。
A、Serializable
B、Cloneable
C、Comparable
D、Writeable
解析:Serializable接口是专门提供给类实现序列化用的。要实现序列化对象必须要实现 Serializable 接口
212、下列程序段的输出结果是:( )
public void complicatedexpression_r(){
int x=20, y=30;
boolean b;
b = x > 50 && y > 60 || x > 50 && y < -60 || x < -50 && y > 60 || x < -50 && y < -60;
System.out.println(b);
}
A、true
B、false
C、1
D、0
解析:
x>50为false,由于&&与操作,||或操作都是短路操作符,即与操作时一旦遇到false就停止执行后当前关系式中的后续代码,同理或操作时一旦遇到true也停止执行。
x>50&&y>60中x>50结果为false,所以就不需要判断y>60。继续判断第一个||或操作符后面的代码,结果为false || false || false || false。因此最终答案选择false。
213、请问所有的异常类皆直接继承于哪一个类?()
A、java.applet.Applet
B、java.lang.Throwable
C、java.lang.Exception
D、java.lang.Error
解析:

214、以下代码在编译和运行过程中会出现什么情况
public class TestDemo{
private int count;
public static void main(String[] args) {
TestDemo test=new TestDemo(88);
System.out.println(test.count);
}
TestDemo(int a) {
count=a;
}
}
A、编译运行通过,输出结果是88
B、编译时错误,count变量定义的是私有变量
C、编译时错误,System.out.println方法被调用时test没有被初始化
D、编译和执行时没有输出结果
解析:private是私有变量,只能用于当前类中,题目中的main方法也位于当前类,所以可以正确输出
215、下面关于hibernate核心接口说明错误的是?
A、Configuration 接口:配置Hibernate,根据其启动hibernate,创建SessionFactory 对象
B、SessionFactory 接口:负责保存、更新、删除、加载和查询对象,是线程不安全的,避免多个线程共享同一个session,是轻量级、一级缓存
C、Query 和Criteria 接口:执行数据库的查询
D、Transaction 接口:管理事务
解析: B选项中应该是Session接口而不是SessionFactory接口\
1,Configuration接口:配置Hibernate,根据其启动Hibernate,创建SessionFactory对象;
2,SessionFactory接口:初始化Hibernate,充当数据存储源的***,创建session对象,SessionFactory是
线程安全的,意味着它的同一个实例可以被应用的多个线程共享,是重量级二级缓存;
3,session接口:负责保存、更新、删除、加载和查询对象,是一个非线程安全的,避免多个线程共享一个session,是轻量级,一级缓存。
4,Transaction接口:管理事务。可以对事务进行提交和回滚;
5,Query和Criteria接口:执行数据库的查询。
216、JDK中提供的java、javac、jar等开发工具也是用Java编写的。对
217、下面哪个不属于HttpServletResponse接口完成的功能?
A、设置HTTP头标
B、设置cookie
C、读取路径信息
D、输出返回数据
解析:
218、如果希望监听TCP端口9000,服务器端应该怎样创建socket?
A、new Socket(“localhost”,9000);
B、new ServerSocket(9000);
C、new Socket(9000
D、new ServerSocket(“localhost”,9000);
解析:

219、 下面哪个行为被打断不会导致InterruptedException:( )?
A、Thread.join
B、Thread.sleep
C、Object.wait
D、CyclicBarrier.await
E、Thread.suspend
解析:
抛InterruptedException的代表方法有:
java.lang.Object 类的 wait 方法
java.lang.Thread 类的 sleep 方法
java.lang.Thread 类的 join 方法
220、下面代码的运行结果为:()
import java.io.*;
import java.util.*;
public class foo{
public static void main (String[] args){
String s;
System.out.println("s=" + s);
}
}
A、代码得到编译,并输出“s=”
B、代码得到编译,并输出“s=null”
C、由于String s没有初始化,代码不能编译通过
D、代码得到编译,但捕获到 NullPointException异常
解析:局部变量可以先申明不用必须初始化,但使用到了一定要先初始化
221、编译java程序的命令文件是( )
A、java.exe
B、javac.exe
C、applet.exe
解析:javac.exe是编译功能javaCompiler
java.exe是执行程序,用于执行编译好的.class文件
javadoc.exe用来制作java文档
jdb.exe是java的调试器
javaprof.exe是剖析工具
222、下列选项中属于面向对象设计方法主要特征的是( )。
A、继承
B、自顶向下
C、模块化
D、逐步求精
解析:
A,面向对象设计方法主要特征有继承封装多态。
223、在异常处理中,如释放资源,关闭数据库、关闭文件应由( )语句来完成。
A、try子句
B、catch子句
C、finally子句
D、throw子句
解析:
try:可能发生异常的语句
catch:捕获,并处理异常(printStackTrace()用来跟踪异常事件发生时执行堆栈的内容)
throw: 在程序中引发异常
throws:把方法中异常抛出该方法
finally:代码中无论是否有异常都会执行,清除资源
224、以下代码的循环次数是无限次
public class Test {
public static void main(String args[]) {
int i = 7;
do {
System.out.println(--i);
--i;
} while (i != 0);
System.out.println(i);
}
}
解析:
执行1次,输出是6,然后再减1为5进行while判定不为o再进入do
执行2次,输出是4,然后再减1为3进行while判定不为o再进入do
执行3次,输出是2,然后再减1为1进行while判定不为o再进入do
执行4次,输出是0,然后再减1为-1进行while判定不为o再进入do
永远执行不到0
225、在异常处理中,以下描述不正确的有
A、try块不可以省略
B、可以使用多重catch块
C、finally块可以省略
D、catch块和finally块可以同时省略
解析:
用try-catch 捕获异常;
用try-finally 清除异常;
用try-catch-finally 处理所有的异常. 三者选一种即可
226、一个类的构造器不能调用这个类中的其他构造器。错误
解析:this()和super()都是构造器,this()调用本类构造器,super()调用父类构造器
227、运行结果为:
public static void main(String[] args) {
Thread t = new Thread() {
public void run() {
my360DW();
}
};
t.run();
System.out.print("DW");
}
static void my360DW() {
System.out.print("360");
}
A、DW
B、360
C、360DW
D、都不输出
解析:本题意在考察开启线程的方法t.start()和直接调用t.run()的区别。但在题目中没有提现 注:直接调用线程的run()方法不是开启线程,就是普通调用,会直接执行run()方法中的内容
228、有如下代码:请写出程序的输出结果。
public class Test
{
public static void main(String[] args)
{
int x = 0;
int y = 0;
int k = 0;
for (int z = 0; z < 5; z++) {
if ((++x > 2) && (++y > 2) && (k++ > 2))
{
x++;
++y;
k++;
}
}
System.out.println(x + ”” +y + ”” +k);
}
}
531
解析:
z=0时候,执行++x > 2,不成立,&&后面就不执行了,此时 x=1,y=0,k=0;
z=1时候,执行++x > 2,还不成立 ,&&后面就不执行了,此时 x=2,y=0,k=0;
z=2时候, 执行++x > 2,成立,继续执行 ++y > 2, 不成立 , &&后面就不执行了, 此时 x=3,y=1,k=0;
z=3时候,执行++x > 2,成立,继续执行++y > 2,不成立 , &&后面就不执行了, 此时 x=4,y=2,k=0;
z=4 时候,执行++x > 2,成立,继续执行 ++y > 2, 成立 , 继续执行k++>2 ,不成立,此时仍没有进入for循环的语句中, 但此时 x=5,y=3,k=1;
z=5时候,不满足条件了,整个循环结束,所以最好打印时候: x=5,y=3,k=1;
229、执行以下程序后的输出结果是()
public class Test {
public static void main(String[] args) {
StringBuffer a = new StringBuffer("A");
StringBuffer b = new StringBuffer("B");
operator(a, b);
System.out.println(a + "," + b);
}
public static void operator(StringBuffer x, StringBuffer y) {
x.append(y); y = x;
}
}
AB,B
解析:
230、设三个整型变量 x = 1 , y = 2 , z = 3,则表达式 y+=z--/++x 的值是( )。
3
解析: y是2,返回的结果是2+(z–/++x),再来看z–/++x,结果应该是3/2,但是因为x,y,z都是int型的,所以最后的返回值只能是int,这时候z–/++x的值就是1,那么最终的结果就是2+1=3
y是2,返回的结果是2+(z–/++x),再来看z–/++x,结果应该是3/2,但是因为x,y,z都是int型的,所以最后的返回值只能是int,这时候z–/++x的值就是1,那么最终的结果就是2+1=3
231、下列程序的运行结果
public static void main(String args[]) {
Thread t = new Thread() {
public void run() {
pong();
}
};
t.run();
System.out.print("ping");
}
static void pong() {
System.out.print("pong");
}
pongping
解析: 这里需要注意Thread的start和run方法
用start方法才能真正启动线程,此时线程会处于就绪状态,一旦得到时间片,则会调用线程的run方法进入运行状态。
而run方法只是普通方法,如果直接调用run方法,程序只会按照顺序执行主线程这一个线程。
232、关于protected 修饰的成员变量,以下说法正确的是
A、可以被该类自身、与它在同一个包中的其它类、在其它包中的该类的子类所访问
B、只能被该类本身和该类的所有的子类访问
C、只能被该类自身所访问
D、只能被同一个包中的类访问
233、默认RMI采用的是什么通信协议?
A、HTTP
B、UDP/IP
C、TCP/IP
D、Multicast
234、下列说法正确的是( )
A、volatile,synchronized 都可以修改变量,方法以及代码块
B、volatile,synchronized 在多线程中都会存在阻塞问题
C、volatile能保证数据的可见性,但不能完全保证数据的原子性,synchronized即保证了数据的可见性也保证了原子性
D、volatile解决的是变量在多个线程之间的可见性、原子性,而sychroized解决的是多个线程之间访问资源的同步性
解析:
synchronized关键字和volatile关键字比较:
volatile关键字是线程同步的轻量级实现,所以volatile性能肯定比synchronized关键字要好。但是volatile关键字只能用于变量而synchronized关键字可以修饰方法以及代码块。synchronized关键字在JavaSE1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的偏向锁和轻量级锁以及其它各种优化之后执行效率有了显著提升,实际开发中使用 synchronized 关键字的场景还是更多一些。
多线程访问volatile关键字不会发生阻塞,而synchronized关键字可能会发生阻塞
volatile关键字能保证数据的可见性,但不能保证数据的原子性。synchronized关键字两者都能保证。
volatile关键字主要用于解决变量在多个线程之间的可见性,而 synchronized关键字解决的是多个线程之间访问资源的同步性。
235、我们在程序中经常使用“System.out.println()”来输出信息,语句中的System是包名,out是类名,println是方法名。
错
解析:System是java.lang中的一个类,out是System内的一个成员变量,这个变量是一个java.io.PrintStream类的对象,println呢就是一个方法了
236、执行如下程序,输出结果是( )
class Test
{
private int data;
int result = 0;
public void m()
{
result += 2;
data += 2;
System.out.print(result + " " + data);
}
}
class ThreadExample extends Thread
{
private Test mv;
public ThreadExample(Test mv)
{
this.mv = mv;
}
public void run()
{
synchronized(mv)
{
mv.m();
}
}
}
class ThreadTest
{
public static void main(String args[])
{
Test mv = new Test();
Thread t1 = new ThreadExample(mv);
Thread t2 = new ThreadExample(mv);
Thread t3 = new ThreadExample(mv);
t1.start();
t2.start();
t3.start();
}
}
A、0 22 44 6
B、2 42 42 4
C、2 24 46 6
D、4 44 46 6
解析:
Test mv =newTest()声明并初始化对data赋默认值
使用synchronized关键字加同步锁线程依次操作m()
t1.start();使得result=2,data=2,输出即为2 2
t2.start();使得result=4,data=4,输出即为4 4
t3.start();使得result=6,data=6,输出即为6 6
System.out.print(result +" "+ data);是print()方法不会换行,输出结果为2 24 46 6
237、 关于 Socket 通信编程,以下描述错误的是:( )
A、服务器端通过new ServerSocket()创建TCP连接对象
B、服务器端通过TCP连接对象调用accept()方法创建通信的Socket对象
C、客户端通过new Socket()方法创建通信的Socket对象
D、客户端通过new ServerSocket()创建TCP连接对象
解析: Socket套接字
就是源Ip地址,目标IP地址,源端口号和目标端口号的组合
服务器端:ServerSocket提供的实例
ServerSocket server= new ServerSocket(端口号)
客户端:Socket提供的实例
Socket soc=new Socket(ip地址,端口号)
238、java中下面哪个能创建并启动线程()
public class MyRunnable implements Runnable {
public void run() {
//some code here
}
}
A、new Runnable(MyRunnable).start()
B、new Thread(MyRunnable).run()
C、new Thread(new MyRunnable()).start()
D、new MyRunnable().start()
解析: C正确
首先:创建并启动线程的过程为:定义线程—》实例化线程—》启动线程。
一 、定义线程: 1、扩展java.lang.Thread类。 2、实现java.lang.Runnable接口。
二、实例化线程: 1、如果是扩展java.lang.Thread类的线程,则直接new即可。
2、如果是实现了java.lang.Runnable接口的类,则用Thread的构造方法:
Thread(Runnable target)
Thread(Runnable target, String name)
Thread(ThreadGroup group, Runnable target)
Thread(ThreadGroup group, Runnable target, String name)
Thread(ThreadGroup group, Runnable target, String name, long stackSize)
所以A、D的实例化线程错误。
三、启动线程: 在线程的Thread对象上调用start()方法,而不是run()或者别的方法。
所以B的启动线程方法错误。
239、Which statement is true for the class java.util.ArrayList?
A、The elements in the collection are ordered.
B、The collection is guaranteed to be immutable.
C、The elements in the collection are guaranteed to be unique.
D、The elements in the collection are accessed using a unique key.
E、The elements in the collections are guaranteed to be synchronized.
解析: A
Serializable, Cloneable , Iterable , Collection , List , RandomAccess List接口是有序的,通常允许重复,因此可以确定A对,C错;ArrayList是实现List 接口的大小可变数组,所以B错;D是Map的特性,所以D错;查看手册: Note that this implementation is not synchronized. ArrayList的实现是不是线程同步的,所以E错。
240、下列关于Java并发的说法中正确的是()
A、CopyOnWriteArrayList适用于写多读少的并发场景
B、ReadWriteLock适用于读多写少的并发场景
C、ConcurrentHashMap的写操作不需要加锁,读操作需要加锁
D、只要在定义int类型的成员变量i的时候加上volatile关键字,那么多线程并发执行i++这样的操作的时候就是线程安全的了
解析: A,CopyOnWriteArrayList适用于写少读多的并发场景
B,ReadWriteLock即为读写锁,他要求写与写之间互斥,读与写之间互斥,
读与读之间可以并发执行。在读多写少的情况下可以提高效率
C,ConcurrentHashMap是同步的HashMap,读写都加锁
D,volatile只保证多线程操作的可见性,不保证原子性
241、结构型模式中最体现扩展性的模式是()
A、装饰模式
B、合成模式
C、桥接模式
D、适配器
解析: A
结构型模式是描述如何将类对象结合在一起,形成一个更大的结构,结构模式描述两种不同的东西:类与类的实例。故可以分为类结构模式和对象结构模式。
在GoF设计模式中,结构型模式有:
1.适配器模式 Adapter
适配器模式是将一个类的接口转换成客户希望的另外一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
两个成熟的类需要通信,但是接口不同,由于开闭原则,我们不能去修改这两个类的接口,所以就需要一个适配器来完成衔接过程。
2.桥接模式 Bridge
桥接模式将抽象部分与它的实现部分分离,是它们都可以独立地变化。它很好的支持了开闭原则和组合锯和复用原则。实现系统可能有多角度分类,每一种分类都有可能变化,那么就把这些多角度分离出来让他们独立变化,减少他们之间的耦合。
3.组合模式 Composite
组合模式将对象组合成树形结构以表示部分-整体的层次结构,组合模式使得用户对单个对象和组合对象的使用具有一致性。
4.装饰模式 Decorator
装饰模式动态地给一个对象添加一些额外的职责,就增加功能来说,它比生成子类更灵活。也可以这样说,装饰模式把复杂类中的核心职责和装饰功能区分开了,这样既简化了复杂类,有去除了相关类中重复的装饰逻辑。 装饰模式没有通过继承原有类来扩展功能,但却达到了一样的目的,而且比继承更加灵活,所以可以说装饰模式是继承关系的一种替代方案。
5.外观模式 Facade
外观模式为子系统中的一组接口提供了同意的界面,外观模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
外观模式中,客户对各个具体的子系统是不了解的,所以对这些子系统进行了封装,对外只提供了用户所明白的单一而简单的接口,用户直接使用这个接口就可以完成操作,而不用去理睬具体的过程,而且子系统的变化不会影响到用户,这样就做到了信息隐蔽。
6.享元模式 Flyweight
享元模式为运用共享技术有效的支持大量细粒度的对象。因为它可以通过共享大幅度地减少单个实例的数目,避免了大量非常相似类的开销。.
享元模式是一个类别的多个对象共享这个类别的一个对象,而不是各自再实例化各自的对象。这样就达到了节省内存的目的。
7.代理模式 Proxy
为其他对象提供一种代理,并由代理对象控制对原对象的引用,以间接控制对原对象的访问。
《大话设计模式》
242、关于数据库连接的程序,以下哪个语句的注释是错误的( )
A、Class.forName(“sun.jdbc.odbc.JdbcOdbcDriver”); //指定MySQL JDBC驱动程序
B、String url=”jdbc:odbc:student_access”; //指定数据源为student_access
C、Connection con=DriverManager.getConnection(url); //创建连接指定数据库的对象
D、Statement stmt=con.creatStatement();//创建执行SQL语句的Statement对象
解析:

243、What will happen when you attempt to compile and run the following code?
public class Test{
static{
int x=5;
}
static int x,y;
public static void main(String args[]){
x--;
myMethod( );
System.out.println(x+y+ ++x);
}
public static void myMethod( ){
y=x++ + ++x;
}
}
A、compiletime error
B、prints:1
C、prints:2
D、prints:3
E、prints:7
F、prints:8
解析: D
1.静态语句块中x为局部变量,不影响静态变量x的值
2.x和y为静态变量,默认初始值为0,属于当前类,其值得改变会影响整个类运行。
3.java中自增操作非原子性的
main方法中:
执行x--后 x=-1
调用myMethod方法,x执行x++结果为-1(后++),但x=0,++x结果1,x=1 ,则y=0
x+y+ ++x,先执行x+y,结果为1,执行++x结果为2,得到最终结果为3
244、下列Java代码中的变量a、b、c分别在内存的____存储区存放。
class A {
private String a = “aa”;
public boolean methodB() {
String b = “bb”;
final String c = “cc”;
}
}
堆区、栈区、栈区
解析:
答案是C
a是类中的成员变量,存放在堆区
b、c都是方法中的局部变量,存放在栈区
245、存根(Stub)与以下哪种技术有关
动态链接
解析:存根类是一个类,它实现了一个接口,它的作用是:如果一个接口有很多方法,如果要实现这个接口,就要实现所有的方法。但是一个类从业务来说,可能只需要其中一两个方法。如果直接去实现这个接口,除了实现所需的方法,还要实现其他所有的无关方法。而如果通过继承存根类就实现接口,就免去了这种麻烦。
RMI 采用stubs 和 skeletons 来进行远程对象(remote object)的通讯。stub 充当远程对象的客户端,有着和远程对象相同的远程接口,远程对象的调用实际是通过调用该对象的客户端对象stub来完成的。
每个远程对象都包含一个对象stub,当运行在本地Java虚拟机上的程序调用运行在远程Java虚拟机上的对象方法时,它首先在本地创建该对象的对象stub, 然后调用对象上匹配的方法。每一个远程对象同时也包含一个skeleton对象,skeleton运行在远程对象所在的虚拟机上,接受来自stub对象的调用。这种方式符合等到程序要运行时将目标文件动态进行链接的思想
246、如果Child extends Parent,那么正确的有()?
A、如果Child是class,且只有一个有参数的构造函数,那么必然会调用Parent中相同参数的构造函数
B、如果Child是interface,那么Parent必然是interface
C、如果Child是interface,那么Child可以同时extends Parent1,Parent2等多个interface
D、如果Child是class,并且没有显示声明任何构造函数,那么此时仍然会调用Parent的构造函数
解析: A、子类的构造器第一行默认都是super(),默认调用直接父类的无参构造,一旦直接父类没有无参构造,那么子类必须显式的声明要调用父类或者自己的哪一个构造器。
BC、接口只能继承接口,但是可以多继承。类都是单继承,但是继承有传递性。
D、一个类一旦没有显式的定义任何构造,那么JVM会默认给你一个无参构造。无参构造的第一行依然默认是super()。
247、面向对象程序设计方法的优点包含:
A、可重用性
B、可扩展性
C、易于管理和维护
D、简单易懂
248、关于下列代码的执行顺序,下面描述正确的有哪些选项()
public class HelloA {
public HelloA() {
System.out.println("A的构造函数");
}
{
System.out.println("A的构造代码块");
}
static {
System.out.println("A的静态代码块");
}
public static void main(String[] args) {
HelloA a = new HelloA();
}
}
A、打印顺序A的静态代码块> A的构造函数
B、打印顺序A的静态代码块> A的构造代码块
C、打印顺序A的构造代码块> A的构造函数
D、打印顺序A的构造函数> A的构造代码块
解析:
打印顺序为A的静态代码块,A的构造代码块,A的构造函数
249、常用的servlet包的名称是?
A、java.servlet
B、javax.servlet
C、servlet.http
D、javax.servlet.http
解析:
JEE5.0中的Servlet相关的就下面这几个包:
javax.servlet
javax.servlet.jsp
java.servlet.jsp.el
java.servlet.jsp.tagext
而最用得多的就是
javax.servlet
javax.servlet.http
这两个包了.
250、局部内部类可以用哪些修饰符修饰?
A、public
B、private
C、abstract
D、final
解析:
251、在程序代码中写的注释太多,会使编译后的程序尺寸变大。
错误
解析:javadoc 用来识别注释,javac 用来识别代码,二者互不影响,注释不会被编译 ,注释是给程序员看的 。
252、关于异常处理机制的叙述正确的是()
A、catch部分捕捉到异常情况时,才会执行finally部分
B、当try区段的程序发生异常时,才会执行finally部分
C、当try区段不论程序是否发生错误及捕捉到异常情况,都会执行finally部分
D、以上都是
解析:
在Java语言的异常处理中,finally块的作用就是为了保证无论出现什么情况,finally块里的代码一定会执行。
由于程序执行return就意味着结束了对当前函数的调用并跳出这个函数体,因此任何语句执行都要放在return前执行(除非碰到exit函数),因此finally块里面的函数也是在return前执行的。
如果try-finally或者catch-finally中都有return语句,那么finally中的return语句会覆盖别处的,最终返回到调用者那里的是finally中的return值。
253、 下列选项中,用于在定义子类时声明父类名的关键字是:( )
A、interface
B、package
C、extends
D、class
254、java中,用( )关键字定义常量?
final
255、 执行以下程序,最终输出可能是:

A、010 2123012 3434
B、01201 340124 2334
==C、0012314 01223344 ==
D、12345 12345 12345
解析:每个线程输出0,1,2,3,4,’空格, 输出空格前必有线程输出了0-4,所以选C、
256、下面程序的输出是什么?
package algorithms.com.guan.javajicu;
public class TestDemo
{
public static String output = ””;
public static void foo(inti)
{
try
{
if (i == 1)
{
throw new Exception();
}
}
catch (Exception e)
{
output += “2”;
return ;
} finally
{
output += “3”;
}
output += “4”;
}
public static void main(String[] args)
{
foo(0);
foo(1);
System.out.println(output);
}
}
A、342
B、3423
C、34234
D、323
解析:
答案:B
首先是foo(0),在try代码块中未抛出异常,finally是无论是否抛出异常必定执行的语句,
所以 output += “3”;然后是 output += “4”;
执行foo(1)的时候,try代码块抛出异常,进入catch代码块,output += “2”;
前面说过finally是必执行的,即使return也会执行output += “3”
由于catch代码块中有return语句,最后一个output += “4”不会执行。
所以结果是3423
257、判断对错。在java的多态调用中,new的是哪一个类就是调用的哪个类的方法。
错
解析: java多态有两种情况:重载和覆写
在覆写中,运用的是动态单分配,是根据new的类型确定对象,从而确定调用的方法;
在重载中,运用的是静态多分派,即根据静态类型确定对象,因此不是根据new的类型确定调用的方法
258、ResultSet中记录行的第一列索引为?
1
解析:ResultSet跟普通的数组不同,索引从1开始而不是从0开始
259、下面哪个描述正确? ()
**==A、echo KaTeX parse error: Can't use function '$' in math mode at position 20: …shell的PID和echo $̲? 返回上一个命令的状态== …返回上一个命令和echo $的状态? 返回登录shell的PID
C、echo KaTeX parse error: Can't use function '$' in math mode at position 7: 和echo $̲? 返回一些无意义的整数值 D…
代表所在命令的PID
$!
代表最后执行的后台命令的PID
$?
代表上一个命令执行后的退出状态 echo $? 如果返回值是0,就是执行成功;如果是返回值是0以外的值,就是失败。
260、下列哪些情况下会导致线程中断或停止运行( )
A、InterruptedException异常被捕获
B、线程调用了wait方法
C、当前线程创建了一个新的线程
D、高优先级线程进入就绪状态
解析:
A选项正确,Java中一般通过interrupt方法中断线程
B选项正确,线程使用了wait方法,会强行打断当前操作,进入阻塞(暂停)状态,然后需要notify方法或notifyAll方法才能进入就绪状态
C选项错误,新创建的线程不会抢占时间片,只有等当前线程把时间片用完,其他线程才有资格拿到时间片去执行。
D选项错误,调度算法未必是剥夺式的,而准备就绪但是还没有获得CPU,它的权限更高只能说明它获得CPU被执行的几率更大而已
261、以下关于java封装的描述中,正确的是:
A、封装的主要作用在于对外隐藏内部实现细节,增强程序的安全性
B、封装的意义不大,因此在编码中尽量不要使用
C、如果子类继承父类,对于父类中进行封装的方法,子类仍然可以直接调用
D、只能对一个类中的方法进行封装,不能对属性进行封装
解析: 关于封装:
封住、继承、多态是面向对象的三大特征,其重要性与使用频率不言而喻。------所以B错误。
1 、什么是封装?
封装就是将属性私有化,提供公有的方法访问私有属性。------------------- 所以CD错误。
做法就是:修改属性的可见性来限制对属性的访问,并为每个属性创建一对取值( getter )方法和赋值( setter )方法,用于对这些属性的访问。
如:
private String name;
public String getName(){
return;
}
public void setName(String name){
this.name=name;
}
2、为什么需要封装?
通过封装,可以实现对属性的数据访问限制,同时增加了程序的可维护性。
由于取值方法和赋值方法隐藏了实现的变更,因此并不会影响读取或修改该属性的类,避免了大规模的修改,程序的可维护性增强
262、已知int a[]=new int[10],则下列对数组元素的访问不正确的是()
A、a[0]
B、a[1]
C、a[9]
D、a[10]
解析:ArrayIndexOutOfBoundsException
263、 在 java 中 , 一个类()
A、可以继承多个类
B、可以实现多个接口
C、在一个程序中只能有一个子类
D、只能实现一个接口
解析:一个类可以有多个子类,但是只能有一个直接父类,但是类对于接口可以多实现(接口本身可以多继承)
264、下面有关java classloader说法错误的是?
A、Java默认提供的三个ClassLoader是BootStrap ClassLoader,Extension ClassLoader,App ClassLoader
B、ClassLoader使用的是双亲委托模型来搜索类的
C、JVM在判定两个class是否相同时,只用判断类名相同即可,和类加载器无关
D、ClassLoader就是用来动态加载class文件到内存当中用的
解析:JVM在判定两个class是否相同时,不仅要判断两个类名是否相同,而且要判断是否由同一个类加载器实例加载的。
265、为AB类的一个无形式参数无返回值的方法method书写方法头,可以用AB.method()方式调用,该方法头的形式为( )。
A、static void method( )
B、public void method( )
C、final void method( )
D、abstract void method( )
解析:
首先声明什么是静态方法:
用static修饰的方法
静态方法是使用公共内存空间的,就是说所有对象都可以直接引用,不需要创建对象再使用该方法。
其次说明静态方法的使用:
在外部调用静态方法时,可以使用"类名.方法名"的方式,也可以使用"对象名.方法名"的方式。
而实例方法只有后面这种方式。
也就是说,只有调用静态方法时可以无需创建对象。
根据题目.
1:AB为一个类,可以不创建对象,直接使用AB.method ("类名.方法名"的方式)
---------------所以method是static修饰的静态方法
2:其次method无返回值
----------------所以method是void类型的方法.
所以选B static void method();
266、哪个关键字可以对对象加互斥锁?()
A、synchronized
B、volatile
C、serialize
D、static
解析:synchronized关键字是同步代码块关键字,对对象加互斥锁
267、下列程序执行后输出结果为( )
class BaseClass {
public BaseClass() {}
{
System.out.println("I’m BaseClass class");
}
static {
System.out.println("static BaseClass");
}
}
public class Base extends BaseClass {
public Base() {}
{
System.out.println("I’m Base class");
}
static {
System.out.println("static Base");
}
public static void main(String[] args) {
new Base();
}
}
A、
static BaseClass
I’m BaseClass class
static Base
I’m Base class
B、
I’m BaseClass class
I’m Base class
static BaseClass
static Base
C、
I’m BaseClass class
static BaseClass
I’m Base class
static Base
D、
static BaseClass
static Base
I’m BaseClass class
I’m Base class
解析:
父类静态代码块 ->子类静态代码块 ->父类非静态代码块 -> 父类构造函数 -> 子类非静态代码块 -> 子类构造函数。
268、根据下面的程序代码,哪些选项的值返回true?
public class Square {
long width;
public Square(long l) {
width = l;
}
public static void main(String arg[]) {
Square a, b, c;
a = new Square(42L);
b = new Square(42L);
c = b;
long s = 42L;
}
}
A、a = = b
B、s = = a
C、b = = c
D、a.equals(s)
解析:a = new Square(42L); b = new Square(42L);
这里new了两个对象,所以a,b不是同一个引用a!=b
s的类型跟a,b不同类型,所以s!=a,s!=b
c = b;
这里b,c是同一个对象的引用,所以b==c是true
269、java接口的方法修饰符可以为?(忽略内部接口)
A、private
B、protected
C、final
D、abstract
解析:
270、下面这段java代码,当 T 分别是引用类型和值类型的时候,分别产生了多少个 T对象和T类型的值()
T t = new T();(值类型时:T t;)
Func(t);
Func 定义如下:
public void Func(T t) { }
1 2
解析:引用类型作为函数的参数时,复制的是引用的地址,不会产生一个新的T;而如果T是值类型,其作为函数实参时会复制其值,也就是产生了一个新的T。
271、看以下代码:
文件名称:forward.jsp
<html>
<head><title> 跳转 </title> </head>
<body>
<jsp:forward page="index.htm"/>
</body>
</html>
如果运行以上jsp文件,地址栏的内容为
A、http://127.0.0.1:8080/myjsp/forward.jsp
B、http://127.0.0.1:8080/myjsp/index.jsp
C、http://127.0.0.1:8080/myjsp/index.htm
D、http://127.0.0.1:8080/myjsp/forward.htm
解析: forward和redirect是最常问的两个问题
forward,服务器获取跳转页面内容传给用户,用户地址栏不变
redirect,是服务器向用户发送转向的地址,redirect后地址栏变成新的地址
因此这个题是A
272、在jdk1.5之后,下列 java 程序输出结果为______。
int i=0;
Integer j = new Integer(0);
System.out.println(i==j);
System.out.println(j.equals(i));
true,true
解析:

273、下列哪个选项是Java调试器?如果编译器返回程序代码的错误,可以用它对程序进行调试。
A、java.exe
B、javadoc.exe
C、jdb.exe
D、javaprof.exe
解析:
java,exe是java虚拟机
javadoc.exe用来制作java文档
jdb.exe是java的调试器
javaprof,exe是剖析工具
274、以下哪一个不是赋值符号?
A、+=
B、<<=
C、<<<=
D、>>>=
选c
解析:A.很明显是赋值符号
B.<<=左移赋值
C.不是
D.>>>= 右移赋值,左边空出的位以0填充
275、java8中,下面哪个类用到了解决哈希冲突的开放定址法
A、LinkedHashSet
B、HashMap
C、ThreadLocal
D、TreeMap
解析:ThreadLocalMap中使用开放地址法来处理散列冲突,而HashMap中使用的是分离链表法。之所以采用不同的方式主要是因为:在ThreadLocalMap中的散列值分散得十分均匀,很少会出现冲突。并且ThreadLocalMap经常需要清除无用的对象,使用纯数组更加方便。
276、 下列不是 Java 关键字的是 ( )
A、abstract
B、false
C、native
D、sizeof
解析:
Java中的关键字有哪些?
答:1)48个关键字:abstract、assert、boolean、break、byte、case、catch、char、class、continue、default、do、double、else、enum、extends、final、finally、float、for、if、implements、import、int、interface、instanceof、long、native、new、package、private、protected、public、return、short、static、strictfp、super、switch、synchronized、this、throw、throws、transient、try、void、volatile、while。
2)2个保留字(现在没用以后可能用到作为关键字):goto、const。
3)3个特殊直接量:true、false、null。
277、Java是一门支持反射的语言,基于反射为Java提供了丰富的动态性支持,下面关于Java反射的描述,哪些是错误的:( )
A、Java反射主要涉及的类如Class, Method, Filed,等,他们都在java.lang.reflet包下
B、通过反射可以动态的实现一个接口,形成一个新的类,并可以用这个类创建对象,调用对象方法
C、通过反射,可以突破Java语言提供的对象成员、类成员的保护机制,访问一般方式不能访问的成员
D、Java反射机制提供了字节码修改的技术,可以动态的修剪一个类
E、Java的反射机制会给内存带来额外的开销。例如对永生堆的要求比不通过反射要求的更多
F、Java反射机制一般会带来效率问题,效率问题主要发生在查找类的方法和字段对象,因此通过缓存需要反射类的字段和方法就能达到与之间调用类的方法和访问类的字段一样的效率
解析:
A:Class类在java.lang包下,错;
B:动态代理可以通过接口与类实现,通过反射形成新的代理类,这个代理类增强了原来类的方法。对;
C:反射可以强制访问private类型的成员,对;
D:反射并不能对类进行修改,只能对类进行访问,错;
E:反射机制对永生堆要求较多,对;
F:即使使用换成,反射的效率也比调用类的方法低,错;
278、以下哪些方法可以取到http请求中的cookie值()?
A、request.getAttribute
B、request.getHeader
C、request.getParameter
D、request.getCookies
解析: 下面的方法可用在 Servlet 程序中读取 HTTP 头。这些方法通过 HttpServletRequest 对象可用:
1)Cookie[] getCookies()
返回一个数组,包含客户端发送该请求的所有的 Cookie 对象。
2)Object getAttribute(String name)
以对象形式返回已命名属性的值,如果没有给定名称的属性存在,则返回 null。
3)String getHeader(String name)
以字符串形式返回指定的请求头的值。Cookie也是头的一种;
4)String getParameter(String name)
以字符串形式返回请求参数的值,或者如果参数不存在则返回 null。
279、Java语言中,下面哪个语句是创建数组的正确语句?( )
A、float f[][] = new float[6][6];
B、float []f[] = new float[6][6];
C、float f[][] = new float[][6];
D、float [][]f = new float[6][6];
E、float [][]f = new float[6][];
解析:二维数组定义,一维长度必须定义,二维可以后续定义
280、关于Java中的数组,下面的一些描述,哪些描述是准确的:( )
A、数组是一个对象,不同类型的数组具有不同的类
B、数组长度是可以动态调整的
C、数组是一个连续的存储结构
D、一个固定长度的数组可类似这样定义: int array[100]
E、两个数组用equals方法比较时,会逐个便利其中的元素,对每个元素进行比较
F、可以二维数组,且可以有多维数组,都是在Java中合法的
解析:数组是一种引用数据类型 那么他肯定是继承Object类的 所以里面有equals() 方法 但是肯定没有重写过 因为他并不是比较数组内的内容
使用Arrays.equals() 是比较两个数组中的内容。
281、 下列描述中,错误的是( )
A、java要求编程者管理内存
B、java的安全性体现在多个层次上
C、java中没有指针机制
D、java有多线程机制
解析:Java与C++的区别在于:Java去除了指针的概念,使用引用,并且Java的内存管理不需要程序员来管理,由Java虚拟机来完成对内存的管理
282、java语言中的数组元素下标总是从0开始,下标可以是整数或整型表达式。()
正确
解析:
283、一个以”.java”为后缀的源文件
A、只能包含一个类,类名必须与文件名相同
B、只能包含与文件名相同的类以及其中的内部类
C、只能有一个与文件名相同的类,可以包含其他类
D、可以包含任意类
284、针对下面的代码块,哪个equal为true:()
String s1 = "xiaopeng" ;
String s2 = "xiaopeng" ;
String s3 =new String (s1);
A、s1 == s2
B、s1 = s2
C、s2 = = s3
D、都不正确
解析:String s 1 = “xiaopeng”,这种定义字符串的方式,首先看看字符串常量池中是否有“xiaopeng"如果有就就直接从常量池中取,没有则将“xiaopeng"放到常量池中。String s2 = 'xiaopeng",常量池中有”xiaopeng",直接取值。string s3 = new String(“xiaopeng”);直接在堆中产生一个字符串“xiaopeng”.所以s1和s2地址一样,和s3地址不一样
285、下列关于异常处理的描述中,错误的是()。
A、程序运行时异常由Java虚拟机自动进行处理
B、使用try-catch-finally语句捕获异常
C、可使用throw语句抛出异常
D、捕获到的异常只能在当前方法中处理,不能在其他方法中处理
解析:
编译时异常必须显示处理,运行时异常交给虚拟机。
运行时异常可以不处理。当出现这样的异常时,总是由虚拟机接管。比如我们从来没有人去处理过Null Pointer Exception异常,它就是运行时异常,并且这种异常还是最常见的异常之一。出现运行时异常后,系统会把异常一直往上层抛,一直遇到处理代码。如果没有处理块,到最上层,如果是多线程就由Thread.run()抛出,如果是单线程就被main()抛出。抛出之后,如果是线程,这个线程也就退出了。如果是主程序抛出的异常,整个程序也就退出了。运行时异常是Exception的子类,也有一般异常的特点,是可以被Catch块处理的。只不过往往不对它处理罢了。也就是说,如果不对运行时异常进行处理,那么出现运行时异常之后,要么是线程中止,要么是主程序终止。
286、语句:char foo=‘中’,是否正确?(假设源文件以GB2312编码存储,并且以javac – encoding GB2312命令编译)
正确
解析:
287、已知如下类说明:
public class Test{
private float f=1.0f;
int m=12;
static int n=1;
public static void main(String args[]){
Test t=new Test();
}
}
A、t.f = 1.0
B、this.n
C、Test.m
D、Test.n
解析:A:编译不成功,因为float浮点类型默认是double类型 所以float f=1.0f;(必须加上f 强调定义的是float)此处是精度由高(double)向低(float)转型所以会报错 但是若是float f=1;这里是默认类型是Int 类型 精度由低(int)向高转型(float)不丢失精度不会报错。
B:this的使用时针对在方法内部使局部变量等值于实例变量而使用的一个关键字,此处的n是静态变量而非实例变量 所以this的调用会出错(试想一下,static本来是全类中可以使用的,是全局的,你非得this去调用,这不是区分局部变量和实例变量的分水线吗?但是此处是全局的,不需要区分)
C:m是实例变量,什么是实例变量:就是需要new 一个对象出来才能使用的,这里直接用类名就调用了,jvm怎么知道m是谁?
D:类变量可以通过类直接调用
288、要求匹配以下16进制颜色值,正则表达式可以为: #ffbbad #Fc01DF #FFF #ffE
A、/#([0-9a-f]{6}|[0-9a-fA-F]{3})/g
B、/#([0-9a-fA-F]{6}|[0-9a-fA-F]{3})/g
C、/#([0-9a-fA-F]{3}|[0-9a-f]{6})/g
D、/#([0-9A-F]{3}|[0-9a-fA-F]{6})/g
解析:
以#开头,后面是数字和a-f的字符(大写或小写),这个值是6位或3位。要匹配一个3位是为了符合16进制颜色的简写规则
289、有以下类定义:
abstract class Animal{
abstract void say();
}
public class Cat extends Animal{
public Cat(){
System.out.printf("I am a cat");
}
public static void main(String[] args) {
Cat cat=new Cat();
}
}
A、I am a cat
B、Animal能编译,Cat不能编译
C、Animal不能编译,Cat能编译
D、编译能通过,但是没有输出结果
解析:B 当一个实体类集成一个抽象类,必须实现抽象类中的抽象方法,抽象类本身没有错误,但是cat类编译通不过
290、下面哪种流可以用于字符输入:
A、java.io.inputStream
B、java.io.outputStream
C、java.io.inputStreamReader
D、java.io.outputStreamReader
291、下列说法正确的是
A、java中包的主要作用是实现跨平台功能
B、package语句只能放在import语句后面
C、包(package)由一组类(class)和接口(interface)组成
D、可以用#include关键词来标明来自其它包中的类
292、以下哪一个正则表达式不能与字符串“https://www.tensorflow.org/”(不含引号)匹配?()
A、[a-z]+://[a-z.]+/
B、https[/]www[.]tensorflow[.]org[/]
C、[htps]+://www.tensorflow.org/
D、[a-zA-Z.]+
解析:
293、面向对象的基本特征是()
封装、继承、多态
294、Java中的集合类包括ArrayList、LinkedList、HashMap等类,下列关于集合类描述正确的是()
A、ArrayList和LinkedList均实现了List接口
B、ArrayList的访问速度比LinkedList快
C、添加和删除元素时,ArrayList的表现更佳
D、HashMap实现Map接口,它允许任何类型的键和值对象,并允许将null用作键或值
解析:
ArrayList插入和现有项的删除开销很大,除非在末端
LinkedList插入和删除开销很小
ArrayList和LinkedList都是实现了List接口
HashMap可以用null值和空字符串作为K,不过只能有一个
295、关于equals和hashCode描述正确的是 ()
A、两个obj,如果equals()相等,hashCode()一定相等(符合代码规范的情况下)
B、两个obj,如果hashCode()相等,equals()不一定相等
C、两个不同的obj, hashCode()可能相等
D、其他都不对
解析:
“= =”:作用是判断两个对象的地址是否相等,即,判断两个对象是不是同一个对象,如果是基本数据类型,则比较的是值是否相等。
“equal”:作用是判断两个对象是否相等,但一般有两种使用情况
1.类没有覆盖equals()方法,则相当于通过“==”比较
2.类覆盖equals()方法,一般,我们都通过equals()方法来比较两个对象的内容是否相等,相等则返回true,如String
地址比较是通过计算对象的哈希值来比较的,hashcode属于Object的本地方法,对象相等(地址相等),hashcode相等,对象不相等,hashcode()可能相等,哈希冲突
296、Choose the correct ones from the following statements:
A、A class can implement more than one interfaces
B、A class can extend more than one class
C、An interface has at least one method declared.
D、An abstract class which has no abstract methods declared is legal
解析:
297、下面哪些情况可以引发异常:
A、数组越界
B、指定URL不存在
C、使用throw语句抛出
D、使用throws语句
解析:1、throws出现在方法头,throw出现在方法体 2、throws表示出现异常的一种可能性,并不一定会发生异常;throw则是抛出了异常,执行throw则一定抛出了某种异常。 3、两者都是消极的异常处理方式,只是抛出或者可能抛出异常,是不会由函数处理,真正的处理异常由它的上层调用处理。
298、以下关于final关键字说法错误的是()
A、final是java中的修饰符,可以修饰类、接口、抽象类、方法和属性
B、final修饰的类肯定不能被继承
C、final修饰的方法不能被重载
D、final修饰的变量不允许被再次赋值
解析:
1.final修饰变量,则等同于常量
2.final修饰方法中的参数,称为最终参数。
3.final修饰类,则类不能被继承
4.final修饰方法,则方法不能被重写。
5.final 不能修饰抽象类
6.final修饰的方法可以被重载 但不能被重写
299、CMS垃圾回收器在那些阶段是没用用户线程参与的
A、初始标记
B、并发标记
C、重新标记
D、并发清理
解析:
300、在Java语言中,下列关于字符集编码(Character set encoding)和国际化(i18n)的问题,哪些是正确的?
A、每个中文字符占用2个字节,每个英文字符占用1个字节
B、假设数据库中的字符是以GBK编码的,那么显示数据库数据的网页也必须是GBK编码的。
C、Java的char类型,通常以UTF-16 Big Endian的方式保存一个字符。
D、实现国际化应用常用的手段是利用ResourceBundle类
解析:
301、 下列程序段执行后t3的结果是()。
int t1=2, t2=3, t3;
t3=t1<t2?t1:(t2+t1);
2
解析:三目运算符的使用
302、 Java 源程序文件的扩展名为()
A、.java
B、.class
C、.exe
D、.jar
解析:
.class 编译后的Java文件
.java是未编译的程序
.jsp是页面程序
.xml配置程序
.jar是.calss的集合
303、 如果一个接口Cow有个方法drink(),有个类Calf实现接口Cow,则在类Calf中正确的是? ( )
A、void drink() { …}
B、protected void drink() { …}
C、public void drink() { …}
D、以上语句都可以用在类Calf中
解析:子类重写父类方法时,方法的访问权限不能小于原访问权限,在接口中,方法的默认权限就是public,所以子类重写后只能是public
304、运行代码,结果正确的是:
Boolean flag = false;
if(flag = true){
System.out.println("true");
}else{
System.out.println("false");
}
A、编译错误
B、TRUE
C、FALSE
D、什么也没有输出
解析:if(flag = true)的时候flag已经是true了,所以输出true;
要是为if(flag == true)输出才为false
305、以下声明合法的是
A、default String s
B、public final static native int w( )
C、abstract double d
D、abstract final double hyperbolicCosine( )
解析: A:java的访问权限有public、protected、private和default的,default不能修饰变量
C:普通变量不能用abstract修饰,abstract一般修饰方法和类
D:被定义为abstract的类需要被子类继承,但是被修饰为final的类是不能被继承和改写的
306、下面程序段的时间复杂度是()
i = k = 0;
while( k < n ){
i ++ ;
k += i ;
}
A、O(n)
B、O(n^1/2)
C、O(n*i)
D、O(n+i)
解析:
307、Given the following code:
public class Test {
private static int j = 0;
private static Boolean methodB(int k) {
j += k;
return true;
}
public static void methodA(int i) {
boolean b;
b = i < 10 | methodB(4);
b = i < 10 || methodB(8);
}
public static void main(String args[]) {
methodA(0);
System.out.println(j);
}
}
What is the result?
A、The program prints”0”
B、The program prints”4”
C、The program prints”8”
D、The program prints”12”
E、The code does not complete.
解析:
308、下面哪一项不是加载驱动程序的方法?
A、通过DriverManager.getConnection方法加载
B、调用方法 Class.forName
C、通过添加系统的jdbc.drivers属性
D、通过registerDriver方法注册
解析:DriverManager.getConnection方法返回一个Connection对象,这是加载驱动之后才能进行的
309、单例模式中,两个基本要点是
A、构造函数私有
B、静态工厂方法
C、以上都不对
D、唯一实例
解析:
310、java中关于继承的描述正确的是()
A、一个子类只能继承一个父类
B、子类可以继承父类的构造方法
C、继承具有传递性
D、父类一般具有通用性,子类更具体
解析:
- java中只有单继承没有多继承
- java中一个父类可以有多个子类,每个子类只能有一个父类
- 继承具有传递性
- 子类是父类的更加具体化
311、(C#、JAVA)扩展方法能访问被扩展对象的public成员(能)
解析:题目的含义是问:子类方法是否能够访问父类中的public成员。
答:可以
312、 以下关于继承的叙述正确的是
A、在Java中类只允许单一继承
B、在Java中一个类不能同时继承一个类和实现一个接口
C、在Java中接口只允许单一继承
D、在Java中一个类只能实现一个接口
解析:
1、java中类只有单继承,没有多继承;但是接口和接口之间可以是多继承关系。
2、普通类可以实现接口,并且可以实现多个接口,但是只能继承一个类,这个类可以是抽象类也可以是普通类,如果继承抽象类,必须实现抽象类中的所有抽象方法,否则这个普通类必须设置为抽象类。
3、抽象类可以实现接口,可以继承具体类,可以继承抽象类,也可以继承有构造器的实体类。
313、 下列修饰符中与访问控制权限无关的是?( )
A、private
B、public
C、protected
D、final
解析:
java常见修饰符
权限修饰符:
private : 修饰私有变量
默认修饰符default(不用把default写出来): 比private限制更少,但比protected限制更多
protected: 修饰受保护变量
public : 修饰公有变量
状态修饰符:
final 最终变量(final修饰类,该类不能被继承,final修饰方法,该方法不能被重写,final修饰变量,该变量不能被重新赋值(相当于常量))
static 静态变量(随着类的加载而加载,优先于对象存在,被所有对象所共享,可以通过类名调用)
抽象修饰符:
abstract 抽象类&抽象方法(抽象类不能被实例化,抽象类中不一定有抽象方法,但有抽象方法的类必须定义为抽象类)
314、以下哪个接口的定义是正确的?( D)
A、interface B
{ void print() { } ;}
B、interface B
{ static void print() ;}
C、abstract interface B extends A1, A2 //A1、A2为已定义的接口
{ abstract void print(){ };}
D、interface B
{ void print();}
解析:
A,接口中方法的默认修饰符时public abstract,抽象方法可是没有方法体的,没有大括号{}
B,JDK8中,接口中的方法可以被default和static修饰,但是!!!被修饰的方法必须有方法体。
C,注意一下,接口是可以多继承的。整个没毛病,和A选项一样,抽象方法不能有方法体
315、关于AOP错误的是?
A、AOP将散落在系统中的“方面”代码集中实现
B、AOP有助于提高系统可维护性
C、AOP已经表现出将要替代面向对象的趋势
D、AOP是一种设计模式,Spring提供了一种实现
解释:
AOP和OOP都是一套方法论,也可以说成设计模式、思维方式、理论规则等等。
AOP不能替代OOP,OOP是obejct abstraction,而AOP是concern abstraction,前者主要是对对象的抽象,诸如抽象出某类业务对象的公用接口、报表业务对象的逻辑封装,更注重于某些共同对象共有行为的抽象,如报表模块中专门需要报表业务逻辑的封装,其他模块中需要其他的逻辑抽象 ,而AOP则是对分散在各个模块中的共同行为的抽象,即关注点抽象。一些系统级的问题或者思考起来总与业务无关又多处存在的功能,可使用AOP,如异常信息处理机制统一将自定义的异常信息写入响应流进而到前台展示、行为日志记录用户操作过的方法等,这些东西用OOP来做,就是一个良好的接口、各处调用,但有时候会发现太多模块调用的逻辑大都一致、并且与核心业务无大关系,可以独立开来,让处理核心业务的人专注于核心业务的处理,关注分离了,自然代码更独立、更易调试分析、更具好维护。
核心业务还是要OOP来发挥作用,与AOP的侧重点不一样,前者有种纵向抽象的感觉,后者则是横向抽象的感觉, AOP只是OOP的补充,无替代关系。
316、 导出类调用基类的构造器必须用到的关键字: ( )
A.this
B.final
C.super
D.static
解析:
基类就是父类,也叫超类。导出类就是子类,也叫派生类。
子类调用父类的构造器使用super(),放在子类构造函数的首行
317、静态内部类不可以直接访问外围类的非静态数据,而非静态内部类可以直接访问外围类的数据,包括私有数据。√
解析:
- 静态内部类:
- 静态内部类本身可以访问外部的静态资源,包括静态私有资源。但是不能访问非静态资源,可以不依赖外部类实例而实例化。
- 成员内部类:
- 成员内部类本身可以访问外部的所有资源,但是自身不能定义静态资源,因为其实例化本身就还依赖着外部类。
- 局部内部类:
- 局部内部类就像一个局部方法,不能被访问修饰符修饰,也不能被static修饰。
- 局部内部类只能访问所在代码块或者方法中被定义为final的局部变量。
- 匿名内部类:
- 没有类名的内部类,不能使用class,extends和implements,没有构造方法。
- 多用于GUI中的事件处理。
- 不能定义静态资源
- 只能创建一个匿名内部类实例。
- 一个匿名内部类一定是在new后面的,这个匿名类必须继承一个父类或者实现一个接口。
- 匿名内部类是局部内部类的特殊形式,所以局部内部类的所有限制对匿名内部类也有效。
318、对于以下代码段,4个输出语句中输出true的个数是(3)。
class A{}
class B extends A{}
class C extends A{}
class D extends B{}
A obj = new D();
System.out.println(obj instanceof B);
System.out.println(obj instanceof C);
System.out.println(obj instanceof D);
System.out.println(obj instanceof A);
解析:instanceof是判断前者是否可以类型可以转化为后者,可以转化即为true,分为向上转型和向下转型B D都是A的子类向下转型,。
A
| |
B C
|
D
D属于B,D属于A,D属于D,D不属于C
所以选C
319、在jdk 1.7中,以下说法正确的是( )。
A.Java中所有的非抽象方法都必须在类内定义
B.Java中主方法可以不在类内定义,其他方法都必须定义在类内
C.Java中主方法必须定义在类内,其他方法可以不必定义在类内
D.Java中所有方法都不必在类内定义
320、Java表达式"13 & 17"的结果是什么?()
A.30
B.13
C.17
D.1
解析:
&运算符:两个数都转为二进制,然后从两个数的最高位进行与运算,两个都为真(1),结果才为真(1),否则为假(0)
13:01101
17:10001
结果:00001,既为1
321、在Java图形用户界面编程中,如果需要显示信息,一般是使用__________类的对象来实现。
A.JLabel
B.JButton
C.JTextArea
D.JtextField
解析:四个选项都是Swing组件。JTextField输入单行文本,JTextArea输入多行文本,JButton显示按钮,JLebel提示信息
322、以下哪个类包含方法flush()?()
A.InputStream
B.OutputStream
C.A 和B 选项都包含
D.A 和B 选项都不包含
解析:
flush()函数强制将缓冲区中的字符流、字节流等输出,原因是如果输出流输出到缓冲区完成后,缓冲区并没有填满,那么缓冲区将会一直等待被填满。所以在关闭输出流之前要调用flush()。
323、面向对象方法的多态性是指()
A.一个类可以派生出多个特殊类
B.一个对象在不同的运行环境中可以有不同的变体
C.针对一消息,不同的对象可以以适合自身的方式加以响应
D.一个对象可以是由多个其他对象组合而成的
解析:相同类型的变量、调用同一个方法时呈现出多种不同的行为特征,这就是多态。
324、如何获取ServletContext设置的参数值?
A.context.getParameter()
B.context.getInitParameter()
C.context.getAttribute()
D.context.getRequestDispatcher()
解析:
etParameter()是获取POST/GET传递的参数值;
getInitParameter获取Tomcat的server.xml中设置Context的初始化参数
getAttribute()是获取对象容器中的数据值;
getRequestDispatcher是请求转发。
325、下面关于程序编译说法正确的是()
A.java语言是编译型语言,会把java程序编译成二进制机器指令直接运行
B.java编译出来的目标文件与具体操作系统有关
C.java在运行时才进行翻译指令
D.java编译出来的目标文件,可以运行在任意jvm上
326、以下代码段执行后的输出结果为 1,3,2
public class Test {
public static void main(String[] args) {
System.out.println(test());
}
private static int test() {
int temp = 1;
try {
System.out.println(temp);
return ++temp;
} catch (Exception e) {
System.out.println(temp);
return ++temp;
} finally {
++temp;
System.out.println(temp);
}
}
}
解析:
执行顺序为:
输出try里面的初始temp:1;
temp=2;
保存return里面temp的值:2;
执行finally的语句temp:3,输出temp:3;
返回try中的return语句,返回存在里面的temp的值:2;
输出temp:2。
327、下面有关java类加载器,说法正确的是?
A.引导类加载器(bootstrap class loader):它用来加载 Java 的核心库,是用原生代码来实现的
B.扩展类加载器(extensions class loader):它用来加载 Java 的扩展库。
C.系统类加载器(system class loader):它根据 Java 应用的类路径(CLASSPATH)来加载 Java 类
D.tomcat为每个App创建一个Loader,里面保存着此WebApp的ClassLoader。需要加载WebApp下的类时,就取出ClassLoader来使用
328、下列代码片段中,存在编译错误的语句是(语句1,3,4)
byte b1=1,b2=2,b3,b6,b8;
final byte b4=4,b5=6,b7;
b3=(b1+b2); /*语句1*/
b6=b4+b5; /*语句2*/
b8=(b1+b4); /*语句3*/
b7=(b2+b5); /*语句4*/
System.out.println(b3+b6);
解析: Java表达式转型规则由低到高转换:
1、所有的byte,short,char型的值将被提升为int型;
2、如果有一个操作数是long型,计算结果是long型;
3、如果有一个操作数是float型,计算结果是float型;
4、如果有一个操作数是double型,计算结果是double型;
5、被fianl修饰的变量不会自动改变类型,当2个final修饰相操作时,结果会根据左边变量的类型而转化。
--------------解析--------------
语句1错误:b3=(b1+b2);自动转为int,所以正确写法为b3=(byte)(b1+b2);或者将b3定义为int;
语句2正确:b6=b4+b5;b4、b5为final类型,不会自动提升,所以和的类型视左边变量类型而定,即b6可以是任意数值类型;
语句3错误:b8=(b1+b4);虽然b4不会自动提升,但b1仍会自动提升,所以结果需要强转,b8=(byte)(b1+b4);
语句4错误:b7=(b2+b5); 同上。同时注意b7是final修饰,即只可赋值一次,便不可再改变。
329、下面哪个不是Java的关键字?
A.null
B.true
C.sizeof
D.implements
E.instanceof
解析:
1、null、true、false 是 Java 中的显式常量值,并不是关键字 或 保留字
2、sizeof 是 C/C++ 中的方法,Java 中并没有这个方法,也没有该关键字 或 保留字
3、implements 和 instanceof 都是 Java 中的关键字
330、下列那些方法是线程安全的(所调用的方法都存在)
A.
public class MyServlet implements Servlet {
public void service (ServletRequest req, ServletResponse resp) {
BigInteger I = extractFromRequest(req);
encodeIntoResponse(resp,factors);
}
}
B.
public class MyServlet implements Servlet {
private long count =0;
public long getCount() {
return count;
}
public void service (ServletRequest req, ServletResponse resp) {
BigInteger I = extractFromRequest(req);
BigInteger[] factors = factor(i);
count ++;
encodeIntoResponse(resp,factors);
}
}
C.
public class MyClass {
private int value;
public synchronized int get() {
return value;
}
public synchronized void set (int value) {
this.value = value;
}
}
D.
public class Factorizer implements Servlet {
private volatile MyCache cache = new MyCache(null,null);
public void service(ServletRequest req, ServletResponse resp) {
BigInteger i = extractFromRequest(req);
BigInteger[] factors = cache.getFactors(i);
if (factors == null) {
factors = factor(i);
cache = new MyCache(i,factors);
}
encodeIntoResponse(resp,factors);
}
ACD
331、以下有关构造方法的说法,正确的是:(A)
A.一个类的构造方法可以有多个
B.构造方法在类定义时被调用
C.构造方法只能由对象中的其他方法调用
D.构造方法可以和类同名,也可以和类名不同
解析:本题考查的是构造函数的特点:
A、一个类的构造函数可以分为无参的构造函数和带参的构造函数。
当一个类没有写出其构造函数时,类中会存在一个默认的无参构造函数。
而当创建了带参的构造函数时,默认无参的构造函数就会消失。但可以在类中构建无参的构造函数。根据类中成员变量的个数不同,可以创建至少一个带参的构造函数,多个构造函数是重载的表现,重载参数列表不同。
B、构造函数在类的对象被创建时就被调用,用来对类中的成员变量进行初始化。
C、构造方法只能有对象来调用,创建时便被调用。
D、构造函数必须要与类同名。
332、以下程序的输出结果是A
public class Print{
static boolean out(char c){
System.out.println(c);
return true;
}
public static void main(String[] argv){
int i = 0;
for(out('A');out('B') && (i<2);out('C')){
i++;
out('D');
}
}
}
A.ABDCBDCB
B.BCDABCD
C.编译错误
D.运行错误
解析:
本题考查的是for循环的执行顺序:
for(初始化语句;条件判断语句;最后执行){
循环体
}
第一次循环
题目中给出的初始化语句为out函数,首先执行会输出字符A;
条件判断语句为调用out函数输出字符B,同时判断i = 0,i < 2;
接下来执行循环体中的内容,先i++,此时i = 1,然后out函数输出字符D
接着执行out函数调用输出字符C第一次循环结束
第二次循环
从条件判断语句开始,调用out函数输出字符B,同时判断i = 1,i < 2;
接下来执行循环体中的内容,先i++,此时i = 2,然后out函数输出字符D
接着执行out函数调用输出字符C第二次循环结束
第三次循环
从条件判断语句开始,调用out函数输出字符B,同时判断i = 2,i !< 2;循环终止
此处注意短路与运算,前面为false,则后面不需要再执行。但是前面为true,后面还需要执行来判断。
所以最后的结果为:ABDCBDCB
333、在 main() 方法中给出的字节数组,如果将其显示到控制台上,需要(A )。
A.标准输出流System.out.println()。
B.建立字节输出流。
C.建立字节输入流。
D.标准输入流System.in.read()。
解析:输出的内容是main方法中已经给出的数组,不需要从文件中读取数据,如果需要从文件中读取数据则要建立输入流后再系统输出,因此out作为java.lang.System类中的一个字段,out是“标准“”输出流,public static final PrintStream out,out是PrintStream类型,PrintStream是包装流,可以输出一切。
334、以下哪个I / O类可以附加或更新文件(A)
A.RandomAccessFile()
B.OutputStream()
C.DataOutputStream()
D.None of the above
解析:
RandomAccessFile 可以通过 seek(long pos) 方法去移动文件指针进行追加更新写入.
OutputStream() 是一个抽象类 不能直接实例化去写入 输出流
DataOutputStream() 也无法追加写入
335、Math.floor(-8.5)=(D )
A.(float)-8.0
B.(long)-9
C.(long)-8
D.(double)-9.0
解析:本题考查对floor函数的应用
Math.floor() 表示向下取整,返回double类型 (floor—地板)
Math.ceil() 表示向上取整,返回double类型 (ceil—天花板)
Math.round() 四舍五入,传入的是double类型,则返回long; 如果是float 类型,则返回int
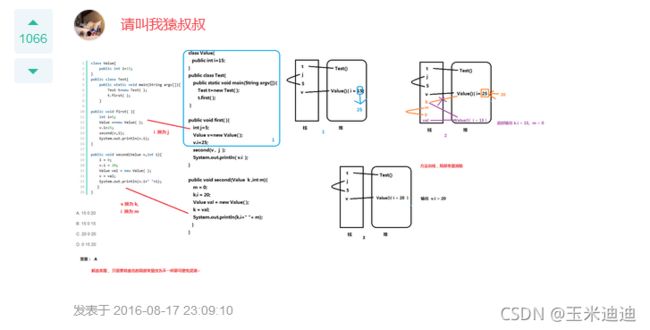
336、下面代码运行结果是?(A)
class Value{
public int i=15;
}
public class Test{
public static void main(String argv[]){
Test t=new Test( );
t.first( );
}
public void first( ){
int i=5;
Value v=new Value( );
v.i=25;
second(v,i);
System.out.println(v.i);
}
public void second(Value v,int i){
i = 0;
v.i = 20;
Value val = new Value( );
v = val;
System.out.println(v.i+" "+i);
}
}
A.15 0 20
B.15 0 15
C.20 0 20
D.0 15 20
解析:

337、以下哪个式子有可能在某个进制下成立()?
A.13*14=204
B.1234=568
C.1414=140
D.1+1=3
解析:
x表示x进制。以A为例:
1314=204
=>(1x1+3x0)(1x1+4x0) = 2x2+4x0
=>(x+3)(x+4)=2x2+4
=>x^2-7x-8=0
=>(x-8)(x+1)=0
=> x=8或者x=-1
338、jdk1.8版本之前的前提下,接口和抽象类描述正确的有()
A.抽象类没有构造函数
B.接口没有构造函数
C.抽象类不允许多继承
D.接口中的方法可以有方法体
339、Java是一门支持反射的语言,基于反射为Java提供了丰富的动态性支持,下面关于Java反射的描述,哪些是错误的:( )
A.Java反射主要涉及的类如Class, Method, Filed,等,他们都在java.lang.reflet包下
B.通过反射可以动态的实现一个接口,形成一个新的类,并可以用这个类创建对象,调用对象方法
C.通过反射,可以突破Java语言提供的对象成员、类成员的保护机制,访问一般方式不能访问的成员
D.Java反射机制提供了字节码修改的技术,可以动态的修剪一个类
E.Java的反射机制会给内存带来额外的开销。例如对永生堆的要求比不通过反射要求的更多
F.Java反射机制一般会带来效率问题,效率问题主要发生在查找类的方法和字段对象,因此通过缓存需要反射类的字段和方法就能达到与之间调用类的方法和访问类的字段一样的效率
解析:
A选项Class类位于lang包下面
D选项反射的本质就是从字节码中查找,动态获取类的整容结构,包括属性,构造器,动态调用对象的方法,而不是修剪类
F选项使用了反射的效率都会降低,就算加了缓存
340、以下哪几种方式可用来实现线程间通知和唤醒:( )
A.Object.wait/notify/notifyAll
B.ReentrantLock.wait/notify/notifyAll
C.Condition.await/signal/signalAll
D.Thread.wait/notify/notifyAll
解析:
wait()、notify()和notifyAll()是 Object类 中的方法
从这三个方法的文字描述可以知道以下几点信息:
1)wait()、notify()和notifyAll()方法是本地方法,并且为final方法,无法被重写。
2)调用某个对象的wait()方法能让当前线程阻塞,并且当前线程必须拥有此对象的monitor(即锁)
3)调用某个对象的notify()方法能够唤醒一个正在等待这个对象的monitor的线程,如果有多个线程都在等待这个对象的monitor,则只能唤醒其中一个线程;
4)调用notifyAll()方法能够唤醒所有正在等待这个对象的monitor的线程;
有朋友可能会有疑问:为何这三个不是Thread类声明中的方法,而是Object类中声明的方法
(当然由于Thread类继承了Object类,所以Thread也可以调用者三个方法)?其实这个问
题很简单,由于每个对象都拥有monitor(即锁),所以让当前线程等待某个对象的锁,当然
应该通过这个对象来操作了。而不是用当前线程来操作,因为当前线程可能会等待多个线程
的锁,如果通过线程来操作,就非常复杂了。
上面已经提到,如果调用某个对象的wait()方法,当前线程必须拥有这个对象的monitor(即
锁),因此调用wait()方法必须在同步块或者同步方法中进行(synchronized块或者
synchronized方法)。
调用某个对象的wait()方法,相当于让当前线程交出此对象的monitor,然后进入等待状态,
等待后续再次获得此对象的锁(Thread类中的sleep方法使当前线程暂停执行一段时间,从
而让其他线程有机会继续执行,但它并不释放对象锁);
notify()方法能够唤醒一个正在等待该对象的monitor的线程,当有多个线程都在等待该对象
的monitor的话,则只能唤醒其中一个线程,具体唤醒哪个线程则不得而知。
同样地,调用某个对象的notify()方法,当前线程也必须拥有这个对象的monitor,因此调用
notify()方法必须在同步块或者同步方法中进行(synchronized块或者synchronized方法)。
nofityAll()方法能够唤醒所有正在等待该对象的monitor的线程,这一点与notify()方法是不同的。
Condition是在java 1.5中才出现的,它用来替代传统的Object的wait()、notify()实现线程间的协作,相比使用Object的wait()、notify(),使用Condition1的await()、signal()这种方式实现线程间协作更加安全和高效。因此通常来说比较推荐使用Condition,在阻塞队列那一篇博文中就讲述到了,阻塞队列实际上是使用了Condition来模拟线程间协作。
Condition是个接口,基本的方法就是await()和signal()方法;
Condition依赖于Lock接口,生成一个Condition的基本代码是lock.newCondition()
调用Condition的await()和signal()方法,都必须在lock保护之内,就是说必须在lock.lock()和lock.unlock之间才可以使用Conditon中的await()对应Object的wait(); Condition中的signal()对应Object的notify(); Condition中的signalAll()对应Object的notifyAll()
341、 有以下代码片段:
String str1=“hello”;
String str2=“he”+ new String(“llo”);
System.out.println(str1==str2);
请问输出的结果是:
A.true
B.都不对
C.null
D.false
解析:
String str1=“hello”; 这样创建字符串是存在于常量池中
String str2=new String(“hello”); str2存在于堆中,
==是验证两个对象是否是一个(内存地址是否相同)
用+拼接字符串时会创建一个新对象再返回。
342、请问以下代码运行结果是:

try catch finally
解析:
throws:写在方法声明之后,表示方法可能抛出异常,调用者需要处理这个异常。
throw:写在方法体中,表示方法一定会抛出一个异常,要么try…catch处理,要么throws抛出。
本题中,在执行到try代码块中,首先输出try,然后抛出异常,直接跳转到catch中,输出catch,然后跳转到finally块中,输出finally。
343、以下代码执行的结果显示是多少()?
public class Demo{
public static void main(String[] args){
System.out.print(getNumber(0));
System.out.print(getNumber(1));
System.out.print(getNumber(2));
System.out.print(getNumber(4));
}
public static int getNumber(int num){
try{
int result = 2 / num;
return result;
}catch (Exception exception){
return 0;
}finally{
if(num == 0){
return -1;
}
if(num == 1){
return 1;
}
}
}
}
-1110
解析:本题考点异常处理
当num = 0时,会出现java.lang.ArithmeticException异常,return result不执行,直接跳转到catch执行return 0,finally无论如何都一定会执行,此处num = 0,满足条件,所以return -1;
当num = 1,2,4时,程序不会抛出异常,因此均会执行return result,但是当num == 1时,finally中return 1;
所以最后的结果是-1110
结论:finally中的return 最后一个执行会覆盖前面的reuturn。
344、设int x=1,float y=2,则表达式x/y的值是:()
解析:
①float x = 1;与float x = 1.0f,这两种对于float类型的变量来说定义的方式都是正确的,第一种情况是将低精度int向上转型到float,由于java的特性导致而不需要进行强制转换,而第二种情况则是比较正式的对于float变量的定义,由于这种类型本身在工作项目中并不常见,常用的带小数的数字我们一般都直接使用double类型,而double类型直接定义是没有问题的:double x = 1.0。而由于float的精度没有double类型高,因此必须对其进行显示的格式书写,如果没有这个f,就默认是double类型了。当然double x = 1.0d也是正确的命名。②当多个精度的数字同时进行运算时,最终结果以最高精度为准。在多数情况下,整数和小数的各级混合运算中,一般结果都是double类型的。但就本题而言,结果是float类型的,因为x,y两个数字精度最高的就是float,所以最终结果是0.5,float转换成double不需要任何提示。
345、下面程序的结果是
public class Demo {
public static String sRet = "";
public static void func(int i)
{
try
{
if (i%2==0)
{
throw new Exception();
}
}
catch (Exception e)
{
sRet += "0";
return;
}
finally
{
sRet += "1";
}
sRet += "2";
}
public static void main(String[] args)
{
func(1);
func(2);
System.out.println(sRet);
}
}
1201
解析:先执行try,如果报错不管try中报错后的内容直接执行catch,且因为catch中有return,会使函数直接结束,便不再执行其他内容,而finally无论什么情况一定都会被执行。如果不报错先执行try,然后执行finally,接着按顺序执行函数内的其他内容。
最后打印拼接字符串sRet。
所以结果为1201
346、哪个类可用于处理 Unicode?
A.InputStreamReader
B.BufferedReader
C.Writer
D.PipedInputStream
解析:Unicode是由两个字节组成的,而InputStreamReader是将字节流转换成字符流供我们使用。同时InputStreamReader也可以指定字符集的编码。
347、要使某个类能被同一个包中的其他类访问,但不能被这个包以外的类访问,可以( )
A.让该类不使用任何关键字
B.使用private关键字
C.使用protected关键字
D.使用void关键字
解析:
default和protected的区别是:
前者只要是外部包,就不允许访问。
后者只要是子类就允许访问,即使子类位于外部包。
总结:default拒绝一切包外访问;protected接受包外的子类!
348、运行代码,输出的结果是()
public class P {
public static int abc = 123;
static{
System.out.println("P is init");
}
}
public class S extends P {
static{
System.out.println("S is init");
}
}
public class Test {
public static void main(String[] args) {
System.out.println(S.abc);
}
}
A.P is init
123
B.S is init
P is init
123
C.P is init
S is init
123
D.S is init
123
解析: 属于被动引用不会出发子类初始化
1.子类引用父类的静态字段,只会触发子类的加载、父类的初始化,不会导致子类初始化
2.通过数组定义来引用类,不会触发此类的初始化
3.常量在编译阶段会进行常量优化,将常量存入调用类的常量池中, 本质上并没有直接引用到定义常量的类,因此不会触发定义常量的类的初始化。
349、 下面哪些具体实现类可以用于存储键,值对,并且方法调用提供了基本的多线程安全支持:( )
A.java.util.ConcurrentHashMap
B.java.util.Map
C.java.util.TreeMap
D.java.util.SortMap
E.java.util.Hashtable
F.java.util.HashMap
解析:线程安全的类有hashtable concurrent HashMap synchronizedMap
350、mysql数据库,game_order表表结构如下,下面哪些sql能使用到索引()?

A.select * from game_order where plat_game_id=5 and plat_id=134
B.select * from game_order where plat_id=134 and
plat_game_id=5 and plat_order_id=’100’
C.select * from game_order where plat_order_id=’100’
D.select * from game_order where plat_game_id=5 and
plat_order_id=’100’ and plat_id=134
E.select * from game_order where plat_game_id=5 and plat_order_id=’100’
解析:
351、下面程序段执行完成后,则变量sum的值是( )。
int b[][]={{1}, {2,2}, {2,2,2}};
int sum=0;
for(int i=0;i<b.length;i++) {
for(int j=0;j<b[i].length;j++) {
sum+=b[i][j];
}
}
11
解析:二维数组的遍历求和
352、定义类中成员变量时不可能用到的修饰是()
A.final
B.void
C.protected
D.static
解析:void是修饰方法的,没有返回值,final是修饰常量的,protected是保护的,static是静态的
353、建立Statement对象的作用是?
A.连接数据库
B.声明数据库
C.执行SQL语句
D.保存查询结果
解析:
1、Statement对象用于执行不带参数的简单SQL语句。
2、Prepared Statement 对象用于执行预编译SQL语句。
3、Callable Statement对象用于执行对存储过程的调用。
354、根据以下接口和类的定义,要使代码没有语法错误,则类Hero中应该定义方法( )。
interface Action{
void fly();
}
class Hero implements Action{ //…… }
A.private void fly(){}
B.void fly(){}
C.protected void fly(){}
D.public void fly(){}
解析:接口方法默认是public abstract的,且实现该接口的类中对应的方法的可见性不能小于接口方法的可见性,因此也只能是public的。
355、一个Java源程序文件中定义几个类和接口,则编译该文件后生成几个以.class为后缀的字节码文件。
正确
356、关于ASCII码和ANSI码,以下说法不正确的是()?
A.标准ASCII只使用7个bit
B.在简体中文的Windows系统中,ANSI就是GB2312
C.ASCII码是ANSI码的子集
D.ASCII码都是可打印字符
解析:
A、标准ASCII只使用7个bit,扩展的ASCII使用8个bit。
B、ANSI通常使用 0x00~0x7f 范围的1 个字节来表示 1 个英文字符。超出此范围的使用0x80~0xFFFF来编码,即扩展的ASCII编码。不同 ANSI 编码之间互不兼容。在简体中文Windows操作系统中,ANSI 编码代表 GBK 编码;在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码。
C、ANSI通常使用 0x00~0x7f 范围的1 个字节来表示 1 个英文字符,即ASCII码
D、ASCII码包含一些特殊空字符
357、java程序内存泄露的最直接表现是( )
A.频繁FullGc
B.jvm崩溃
C.程序抛内存控制的Exception
D.java进程异常消失
解析:
java是自动管理内存的,通常情况下程序运行到稳定状态,内存大小也达到一个 基本稳定的值
但是内存泄露导致Gc不能回收泄露的垃圾,内存不断变大.
最终超出内存界限,抛出OutOfMemoryExpection
358、下列语句中,正确的是
A.float x=0.0
B.boolean b=3>5
C.、char c=“A”
D.double =3.14
解析:
在java里面 float类型数据类型初始化时必须使用后缀f 因为java默认浮点型是double 用后缀f表示为float类型;
A应为:float x = 0.0f;
布尔值可以是一个表达式的值,但必须是一个true或者false值
B正确
char只能是一个字符 而不是一个字符串
C应为:char c=‘A’;
D没变量名
359、以下关于final关键字说法错误的是()
A.final是java中的修饰符,可以修饰类、接口、抽象类、方法和属性
B.final修饰的类不能被继承
C.final修饰的方法不能被重载
D.final修饰的变量不允许被再次赋值
解析:
1.final修饰变量,则等同于常量
2.final修饰方法中的参数,称为最终参数。
3.final修饰类,则类不能被继承
4.final修饰方法,则方法不能被重写。
final 不能修饰抽象类
final修饰的方法可以被重载 但不能被重写
360、关于volatile关键字,下列描述不正确的是?
A.用volatile修饰的变量,每次更新对其他线程都是立即可见的。
B.对volatile变量的操作是原子性的。
C.对volatile变量的操作不会造成阻塞。
D.不依赖其他锁机制,多线程环境下的计数器可用volatile实现。
解析:
所谓 volatile的措施,就是
- 每次从内存中取值,不从缓存中什么的拿值。这就保证了用 volatile修饰的共享变量,每次的更新对于其他线程都是可见的。
- volatile保证了其他线程的立即可见性,就没有保证原子性。
3.由于有些时候对 volatile的操作,不会被保存,说明不会造成阻塞。不可用与多线程环境下的计数器。
361、下面有关JDK中的包和他们的基本功能,描述错误的是?
A.java.awt: 包含构成抽象窗口工具集的多个类,用来构建和管理应用程序的图形用户界面
B.java.io: 包含提供多种输出输入功能的类
C.java.lang: 包含执行与网络有关的类,如URL,SCOKET,SEVERSOCKET
D.java.util: 包含一些实用性的类
解析:
java.awt: 包含构成抽象窗口工具集的多个类,用来构建和管理应用程序的图形用户界面
java.lang: 提供java编成语言的程序设计的基础类
java.io: 包含提供多种输出输入功能的类,
java.net: 包含执行与网络有关的类,如URL,SCOKET,SEVERSOCKET,
java.applet: 包含java小应用程序的类
java.util: 包含一些实用性的类
362、接口不能扩展(继承)多个接口。( )
错误
解析: java类是单继承的。classB Extends classA
java接口可以多继承。Interface3 Extends Interface0, Interface1, interface……
不允许类多重继承的主要原因是,如果A同时继承B和C,而b和c同时有一个D方法,A如何决定该继承那一个呢?
但接口不存在这样的问题,接口全都是抽象方法继承谁都无所谓,所以接口可以继承多个接口。
363、上述代码返回结果为:
Integer a = 1;
Integer b = 1;
Integer c = 500;
Integer d = 500;
System.out.print(a == b);
System.out.print(c == d);
A.true、true
B.true、false
C.false、true
D.false、false
解析:
Integer类型在-128–>127范围之间是被缓存了的,也就是每个对象的内存地址是相同的,赋值就直接从缓存中取,不会有新的对象产生,而大于这个范围,将会重新创建一个Integer对象,也就是new一个对象出来,当然地址就不同了,也就不等于了。
364、假设num已经被创建为一个ArrayList对象,并且最初包含以下整数值:[0,0,4,2,5,0,3,0]。 执行下面的方法numQuest(),最终的输出结果是什么?
private List<Integer> nums;
//precondition: nums.size() > 0
//nums contains Integer objects
public void numQuest() {
int k = 0;
Integer zero = new Integer(0);
while (k < nums.size()) {
if (nums.get(k).equals(zero))
nums.remove(k);
k++;
}
}
A.[3, 5, 2, 4, 0, 0, 0, 0]
B.[0, 0, 0, 0, 4, 2, 5, 3]
C.[0, 0, 4, 2, 5, 0, 3, 0]
D.[0, 4, 2, 5, 3]
解析:

365、以下 _____ 不是 Object 类的方法
A.clone()
B.finalize()
C.toString()
D.hasNext()
解析:

366、以下代码的输出的正确结果是
public class Test {
public static void main(String args[]) {
String s = "祝你考出好成绩!";
System.out.println(s.length());
}
}
8
解析:length得到的是字符,不是字节。
367、在Java中,关于HashMap类的描述,以下错误的是()?
A.HashMap能够保证其中元素的顺序
B.HashMap允许将null用作值
C.HashMap允许将null用作键
D.HashMap使用键/值得形式保存数据
解析:
HashMap的底层是由数组加链表实现的,对于每一个key值,都需要计算哈希值,然后通过哈希值来确定顺序,并不是按照加入顺序来存放的,因此可以认为是无序的,但不管是有序还是无序,它都一个自己的顺序。故A错。
最开始有Hashtable,Hashtable是不允许key和value的值为空的,但后来开发者认为有时候也会有key值为空的情况,因为可以允许null为空,通过查看HashMap的源代码就知道:if(key = null) {putForNullKey(value);};
Map底层都是用key/value键值对的形式存放的
368、从以下哪一个选项中可以获得Servlet的初始化参数?
A.Servlet
B.ServletContext
C.ServletConfig
D.GenericServlet
解析:
通过ServletConfig接口的getInitParameter(java.lang.String name)方法
369、下面代码运行结果是?
public class Test
{
static boolean foo(char c)
{
System.out.print(c);
return true;
}
public static void main( String[] argv )
{
int i = 0;
for ( foo('A'); foo('B') && (i < 2); foo('C'))
{
i++ ;
foo('D');
}
}
}
A.ABDCBDCB
B.ABCDABCD
C.Compilation fails.
D.An exception is thrown at runtime.
解析:同332题
370、 在 Java 中,属于整数类型变量的是()
A.single
B.double
C.byte
D.char
解析:
java中四类八种基本数据类型考察
整型变量:byte,short,int,long,一般输入的整数都默认为整型int;
浮点型变量:float,double,浮点型常量默认为double;
字符型:char;
布尔型:boolean
371、以下哪一项正则能正确的匹配网址: http://www.bilibili.com/video/av21061574 ()

解析:
对于正则表达式的考察
^表示匹配输入的开始,$表示匹配输入的结束
每个选项从前向后看,http都能够严格匹配
?表示匹配某元素0次或1次,这里四个选项都没有问题,能够匹配0次或1次字符s
接下来:严格匹配,//严格匹配两个//
接着往下看,[]表示字符集合,它用在正则表达式中表示匹配集合中的任一字符
A D 选项中的 [a-zA-Z\d] 表示匹配一个小写字母 或者 大写字母 或者 数字
B C 选项中的 \w 表示匹配字母数字或下划线(注意这里比A D中能多匹配下划线类型)
+表示匹配某元素1次或多次,到这里四个选项都能够完美匹配字符www
.可以匹配除了换行符\n \r外的任何字符
接下来我们看选项A,bilibili com video av都严格匹配,而 \D 表示匹配一个非数字字符而非数字字符,av后的数字是无法匹配成功的,A错误
B选项,\d匹配数字,{m,n}表示最少匹配m次,最多匹配n次,/?能匹配末尾的0个或1个/字符,B正确
C选项,*表示匹配某元素0次或多次,但 \w 并不能匹配字符 /,C错误
D选项,前面都对,错在最后的/+至少要匹配一个/,而原字符串最后并没有/
372、类A1和类A2在同一包中,类A2有个protected的方法testA2,类A1不是类A2的子类(或子类的子类),类A1可以访问类A2的方法testA2。(√ )
解析:
public:可以被所有其他类所访问
private:只能被自己访问和修改
protected:自身、子类及同一个包中类可以访问
default:同一包中的类可以访问,声明时没有加修饰符,认为是friendly。
方法test2被protested保护,只能由类本身或其子类或同一个包中的类保护,正好类1和类2在同一个包下,满足条件可以被访问。
*373、输出结果为:
String str = "";
System.out.print(str.split(",").length);
1
解析:本题是对String字符串中的split方法的考察。
题目定义了一个空串str,并使用字符串的split方法,根据分隔符“,”去拆分str。但因为是空串不包括分隔符,String split 这个方法默认返回一个数组,如果没有找到分隔符,会把整个字符串当成一个长度为1的字符串数组返回到结果, 所以此处结果就是1。
374、下面代码将输出什么内容:()
public class SystemUtil{
public static boolean isAdmin(String userId){
return userId.toLowerCase()=="admin";
}
public static void main(String[] args){
System.out.println(isAdmin("Admin"));
}
}
A.true
B.false
C.1
D.编译错误
解析:
= = 比较的是两个引用变量的地址是否相同;
equals 比较的是两个变量的内容是否相同。
此处 在源码中 toLowerCase 是重新 new String() ;

所以为 == 是比较对象是否是同一个对象,所以为 false 。
375、以下代码结果是什么?
public class foo {
public static void main(String sgf[]) {
StringBuffer a=new StringBuffer(“A”);
StringBuffer b=new StringBuffer(“B”);
operate(a,b);
System.out.println(a+”.”+b);
}
static void operate(StringBuffer x,StringBuffer y) {
x.append(y);
y=x;
}
}
A.代码可以编译运行,输出“AB.AB”。
B.代码可以编译运行,输出“A.A”。
C.代码可以编译运行,输出“AB.B”。
D.代码可以编译运行,输出“A.B”。
解析:
StrinBuufer类作为参数传递时‘引用传递’,即传的是地址值;
y本来指向的是b所指向的对象,但是一个“=”,y就指向了x所指向的目标即是a指向的对象,因此原来b所指向的目标并没有发生任何改变。与y不同的是,x进行的是对象操作,此时此对象在内存中是真正的本质上的改变。
376、说明输出结果。
import java.util.Date;
public class SuperTest extends Date{
private static final long serialVersionUID = 1L;
private void test(){
System.out.println(super.getClass().getName());
}
public static void main(String[]args){
new SuperTest().test();
}
}
A.SuperTest
B.SuperTest.class
C.test.SuperTest
D.test.SuperTest.class
解析:
TestSuper和Date的getClass都没有重写,他们都是调用Object的getClass,而Object的getClass作用是返回的是运行时的类的名字。这个运行时的类就是当前类,所以
super.getClass().getName()
返回的是test.SuperTest,与Date类无关
要返回Date类的名字需要写
super.getClass().getSuperclass()
377、根据下面这个程序的内容,判断哪些描述是正确的:( )
public class Test {
public static void main(String args[]) {
String s = "tommy";
Object o = s;
sayHello(o); //语句1
sayHello(s); //语句2
}
public static void sayHello(String to) {
System.out.println(String.format("Hello, %s", to));
}
public static void sayHello(Object to) {
System.out.println(String.format("Welcome, %s", to));
}
}
A.这段程序有编译错误
B.语句1输出为:Hello, tommy
C.语句2输出为:Hello, tommy
D.语句1输出为:Welcome, tommy
E.语句2输出为:Welcome, tommy
F.根据选用的Java编译器不同,这段程序的输出可能不同
解析:
Java语言是静态多分派,动态单分派的。
如果是重载方法之间的选择,则是使用静态类型。
如果是父类与子类之间的重写方法的选择,则是使用动态类型。
如A a = new B(); 会使用类型B去查找重写的方法,使用类型A去查找重载的方法。
所以此题的输出分别为
Welcome, tommy
Hello, tommy
378、 String s=null;下面哪个代码片段可能会抛出NullPointerException?
A.if((s!=null)&(s.length()>0))
B.if((s!=null)&&(s.length()>0))
C.if((s= =null)|(s.length()= =0))
D.if((s= =null)||(s.length()= =0))
解析:
&左右两个条件都必须满足
&&只要左边的为false后边就不执行
| 和|| 同理
string为引用类型,对象为null表示对象不存在,此时调用对象的方法就不能够执行,会报错.
379、关于身份证号,以下正确的正则表达式为( )

解析:

380、下面语句正确的是()
A.x+1=5
B.i++=1
C.a++b=1
D.x+=1
解析:
赋值运算符左侧必须为变量 ,不能是表达式
381、已知如下类定义:
class Base {
public Base (){
//...
}
public Base ( int m ){
//...
}
public void fun( int n ){
//...
}
}
public class Child extends Base{
// member methods
}
如下哪句可以正确地加入子类中?
A.private void fun( int n ){ //…}
B.void fun ( int n ){ //… }
C.protected void fun ( int n ) { //… }
D.public void fun ( int n ) { //… }
解析:
子类对父类的继承,不能降低对父类的方法的可见性。即方法的重写必须遵守以下原则:
方法名相同,参数类型相同
子类返回类型小于等于父类方法返回类型,
子类抛出异常小于等于父类方法抛出异常,
子类访问权限大于等于父类方法访问权限。
382、能用来修饰interface的有()
A.private
B.public
C.protected
D.static
解析:
接口的修饰符可以是public 或者 abstract,其中public或abstract可以缺省。public 的含义与类修饰符是一致的。。但是缺省public或abstract修饰符时,定义的接口只能被同一个包中的其他类和接口使用。
383、在Web应用程序的文件与目录结构中,web.xml是放置在( )中。
A.WEB-INF目录
B.conf目录
C.lib目录
D.classes目录
解析:
web.xml文件是用来初始化配置信息
web.xml是放置在WEB-INF目录中
384、下面程序的运行结果:()
public static void main(String args[]) {
Thread t=new Thread(){
public void run(){
dianping();
}
};
t.run();
System.out.print("dazhong");
}
static void dianping(){
System.out.print("dianping");
}
A.dazhongdianping
B.dianpingdazhong
C.a和b都有可能
D.dianping循环输出,dazhong夹杂在中间
解析:
线程问题,主函数中创建线程对象,但并没有开启线程,之后通过创建的对象t去调用run函数,run函数调用dianping函数,第11行的静态函数,直接输出dianping;然后是第9行的输出dazhong。
*385、下面代码的执行结果是 :
class Chinese{
private static Chinese objref =new Chinese();
private Chinese(){}
public static Chinese getInstance() { return objref; }
}
public class TestChinese {
public static void main(String [] args) {
Chinese obj1 = Chinese.getInstance();
Chinese obj2 = Chinese.getInstance();
System.out.println(obj1 == obj2);
}
}
A.true
B.false
C.TRUE
D.FALSE
解析:
单例模式: 第一步,不让外部调用创建对象,所以把构造器私有化,用private修饰。 第二步,怎么让外部获取本类的实例对象?通过本类提供一个方法,供外部调用获取实例。由于没有对象调用,所以此方法为类方法,用static修饰。 第三步,通过方法返回实例对象,由于类方法(静态方法)只能调用静态方法,所以存放该实例的变量改为类变量,用static修饰。 最后,类变量,类方法是在类加载时初始化的,只加载一次。所以由于外部不能创建对象,而且本来实例只在类加载时创建一次。
386、以下程序段的输出结果为:
public class EqualsMethod
{
public static void main(String[] args)
{
Integer n1 = new Integer(47);
Integer n2 = new Integer(47);
System.out.print(n1 == n2);
System.out.print(",");
System.out.println(n1 != n2);
}
}
A.false,false
B.false,true
C.true,false
D.true,true
解析:
主函数中创建了两个integer类型的对象,且为引用数据类型
当= =用于基本数据类型时,比较的是值是否相同
当用于引用类型的时候,是比较对象是否相同。
"= =“和”!="比较的是地址 两次对象所创建后分配的地址不同
所以
System.out.print(n1 = = n2);返回 false
!=就返回true
387、 关于访问权限,说法正确的是? ( )
A.类A和类B在同一包中,类B有个protected的方法testB,类A不是类B的子类(或子类的子类),类A可以访问类B的方法testB
B.类A和类B在同一包中,类B有个protected的方法testB,类A不是类B的子类(或子类的子类),类A不可以访问类B的方法testB
C.访问权限大小范围:public > 包权限 > protected > private
D.访问权限大小范围:public > 包权限 > private > protected
解析:
AB选项同372题
CD选项
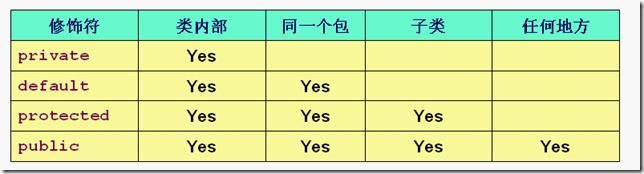
388、假设有以下代码String s = “hello”;String t = “hello”;char c [ ] = {‘h’,‘e’,‘l’,‘l’,‘o’};下列选项中返回false的语句是?
A.s.equals (t);
B.t.equals ©;
C.s= =t;
D.t.equals (new String (“hello”));
解析:
题目定义了两个字符串,s会在栈中生成hello字符串并存入字符串常量池;t在创建时,会先在字符串常量池中寻找是否存在hello,找到以后,直接引用已有的,即地址和内容均相同。
所以A、C为true
B t,c根据equals源码发现不是string的对象,返回false
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
D 新建了对象,但equals比较内容,所以为true
*389、以下代码执行的结果显示是多少( )?
public class Demo {
class Super {
int flag = 1;
Super() {
test();
}
void test() {
System.out.println("Super.test() flag=" + flag);
}
}
class Sub extends Super {
Sub(int i) {
flag = i;
System.out.println("Sub.Sub()flag=" + flag);
}
void test() {
System.out.println("Sub.test()flag=" + flag);
}
}
public static void main(String[] args) {
new Demo().new Sub(5);
}
}
A.Sub.test() flag=1
Sub.Sub() flag=5
B.Sub.Sub() flag=5
Sub.test() flag=5
C.Sub.test() flag=0
Sub.Sub() flag=5
D.Super.test() flag=1
Sub.Sub() flag=5
解释:
我需要研究一下
*390、下面对静态数据成员的描述中,正确的是
A.静态数据成员可以在类体内进行初始化
B.静态数据成员不可以被类的对象调用
C.静态数据成员不受private控制符的作用
D.静态数据成员可以直接用类名调用
解析:
静态数据成员又称为类变量。
1.在内存分配的空间上,不同对象的同名类变量分配相同的内存空间,即多个对象共享类变量,改变其中一个对象的值会影响其他对象中相应地类变量的值。
2.在内存分配的时间上,当类的字节码文件被加载到内存时,类变量就分配了相应的内存空间。
3.类变量可以用类名访问,也可以用对象名访问。如果是访问权限是private就不能直接用类名访问。
391、下面哪些语法结构是正确的?
A.public class A extends B implements C
B.public class A implements A B
C.public class A implements B,C,D
D.public implements B
解析:
一个类可以实现多个接口,但只能有一个继承
392、final、finally、finalize三个关键字的区别是()
A.final是修饰符(关键字)可以修饰类、方法、变量
B.finally在异常处理的时候使用,提供finally块来执行任何清除操作
C.finalize是方法名,在垃圾收入集器将对象从内存中清除出去之前做必要的清理工作
D.finally和finalize一样都是用于异常处理的方法
解析:
final:可用来定义变量、方法传入的参数、类、方法。
finally:只能跟在try/catch语句中,并且附带一个语句块,表示最后执行。
finalize:是垃圾回收器操作的运行机制中的一部分,进行垃圾回收器操作时会调用finalize方法,因为finalize方法是object的方法,所以每个类都有这个方法并且可以重写这个方法,在这个方法里实现释放系统资源及其他清理工作,JVM不保证此方法总被调用。
393、下列关于JAVA多线程的叙述正确的是()
A.调用start()方法和run()都可以启动一个线程
B.CyclicBarrier和CountDownLatch都可以让一组线程等待其他线程
C.Callable类的call()方法可以返回值和抛出异常
D.新建的线程调用start()方法就能立即进行运行状态
解析:
A,start是开启线程,run是线程的执行体,run是线程执行的入口。
B,CyclicBarrier和CountDownLatch都可以让一组线程等待其他线程。前者是让一组线程相互等待到某一个状态再执行。后者是一个线程等待其他线程结束再执行。
C,Callable中的call比Runnable中的run厉害就厉害在有返回值和可以抛出异常。同时这个返回值和线程池一起用的时候可以返回一个异步对象Future。
D,start是把线程从new变成了runnable
394、下面有关Java的说法正确的是( )
A.一个类可以实现多个接口
B.抽象类必须有抽象方法
C.protected成员在子类可见性可以修改
D.通过super可以调用父类构造函数
E.final的成员方法实现中只能读取类的成员变量
F.String是不可修改的,且java运行环境中对string对象有一个常量池保存
解析:
A对:java类单继承,多实现
B错:被abstract修饰的类就是抽象类,有没有抽象方法无所谓
C错:描述有问题。protected成员在子类的可见性,我最初理解是子类(不继承父类protected成员方法)获取父类被protected修饰的成员属性或方法,可见性是不可能变的,因为修饰符protected就是描述可见性的。
这道题应该是要考察子类继承父类,并重写父类的protected成员方法,该方法的可见性可以修改,这是对的,因为子类继承父类的方法,访问权限可以相同或往大了改
D对。
E错:final修饰的方法只是不能重写,static修饰的方法只能访问类的成员变量
F对。
395、下列可作为java语言标识符的是()
A.a1
B.$1
C._1
D.11
解析:标识符以字母、下划线_、 $ 开头;由数字、字母、下划线_、 $ 组成。
396、下列说法正确的有( )
A.构造方法的方法名必须与类名相同
B.构造方法也没有返回值,但可以定义为void
C.在子类构造方法中调用父类的构造方法,super() 必须写在子类构造方法的第一行,否则编译不通过
D.一个类可以定义多个构造方法,如果在定义类时没有定义构造方法,则编译系统会自动插入一个默认的构造方法,这个构造方法不执行任何代码
解析:
关于B选项:Java:语法要求的构造函数只能那么写。如果写成public void 类名(){} 这种格式的话。此时就相当与你重新定义了一个函数,不能起到构造函数的作用,调用这个类的时候不能自动执行构造函数里的代码。
397、下面有关forward和redirect的描述,正确的是() ?
A.forward是服务器将控制权转交给另外一个内部服务器对象,由新的对象来全权负责响应用户的请求
B.执行forward时,浏览器不知道服务器发送的内容是从何处来,浏览器地址栏中还是原来的地址
C.执行redirect时,服务器端告诉浏览器重新去请求地
D.forward是内部重定向,redirect是外部重定向
E.redirect默认将产生301 Permanently moved的HTTP响应
解析:
1.从地址栏显示来说
forward是服务器请求资源,服务器直接访问目标地址的URL,把那个URL的响应内容读取过来,然后把这些内容再发给浏览器.浏览器根本不知道服务器发送的内容从哪里来的,所以它的地址栏还是原来的地址.
redirect是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址.所以地址栏显示的是新的URL.
2.从数据共享来说
forward:转发页面和转发到的页面可以共享request里面的数据.
redirect:不能共享数据.
3.从运用地方来说
forward:一般用于用户登陆的时候,根据角色转发到相应的模块.
redirect:一般用于用户注销登陆时返回主页面和跳转到其它的网站等.
4.从效率来说
forward:高.
redirect:低.
*398、关于运行时常量池,下列哪个说法是正确的
A.运行时常量池大小受栈区大小的影响
B.运行时常量池大小受方法区大小的影响
C.存放了编译时期生成的各种字面量
D.存放编译时期生成的符号引用
解析:
关于此题,自己对于内存相关的知识都还不大理解透彻,可以在牛客网上搜索此题,查看点赞最多的那个题解,很不错的回复!
399、下面有关值类型和引用类型描述正确的是()?
A.值类型的变量赋值只是进行数据复制,创建一个同值的新对象,而引用类型变量赋值,仅仅是把对象的引用的指针赋值给变量,使它们共用一个内存地址。
B.值类型数据是在栈上分配内存空间,它的变量直接包含变量的实例,使用效率相对较高。而引用类型数据是分配在堆上,引用类型的变量通常包含一个指向实例的指针,变量通过指针来引用实例。
C.引用类型一般都具有继承性,但是值类型一般都是封装的,因此值类型不能作为其他任何类型的基类。
D.值类型变量的作用域主要是在栈上分配内存空间内,而引用类型变量作用域主要在分配的堆上。
解析:
这个题让我想到了值引用和地址引用的区别。
暂时需要研究一下再解答。
400、 在java中,在同一包内,类Cat里面有个公有方法sleep(),该方法前有static修饰,则可以直接用Cat.sleep()。(对)
解析:对于静态成员方法,也可以称为类方法,
1.在内存分配时间上,,当类的字节码文件被加载到内存时,类方法就分配了相应的入口地址。
2.在操作对象上,类方法只能操作类变量,不能操作实例变量。
3.在访问方式上,类方法一般用类名访问,也可用对象名访问。
4.类方法只能调用类方法,不能调用实例方法。