【Linux详解】——进程地址空间
前言:本节将以新的视角看的地址空间的特点,与以前对指针的认识做区分。
目录
- 1. C/C++ 地址空间回顾
- 2. 进程地址空间
-
- 2.1 感性理解概念
- 2.2 如何“画饼”
- 2.3 区域划分
- 3. 进程地址空间与内存
-
- 3.1 虚拟地址和物理地址
- 3.2 多进程的映射关系
- 4. 地址空间存在的意义
-
- 4.1 保证安全性
- 4.2 保证独立性
- 4.3 保证统一性
1. C/C++ 地址空间回顾
我们以前在学习 C/C++ 的动态内存管理的时候,通常把地址空间划分为如下几个区域:

那么这个C/C++地址空间是什么,是内存吗?我们以一个例子来测试:
# Makefile
mytest:mytest.c
gcc -o $@ $^ #-std=c99
.PHONY:clean
clean:
rm -f mytest
// mytest.c
#include 输出结果:
I'm a parent process, pid: 26634, ppid: 23075 | global_value: 100, &global_value: 0x60105c
I'm a child process, pid: 26635, ppid: 26634 | global_value: 100, &global_value: 0x60105c
I'm a child process, pid: 26635, ppid: 26634 | global_value: 100, &global_value: 0x60105c
I'm a parent process, pid: 26634, ppid: 23075 | global_value: 100, &global_value: 0x60105c
I'm a child process, pid: 26635, ppid: 26634 | global_value: 100, &global_value: 0x60105c
I'm a child process, pid: 26635, ppid: 26634 | global_value: 100, &global_value: 0x60105c
...当cnt=10后...
The child process has changed the global value
I'm a child process, pid: 26635, ppid: 26634 | global_value: 300, &global_value: 0x60105c
I'm a child process, pid: 26635, ppid: 26634 | global_value: 300, &global_value: 0x60105c
I'm a parent process, pid: 26634, ppid: 23075 | global_value: 100, &global_value: 0x60105c
I'm a child process, pid: 26635, ppid: 26634 | global_value: 300, &global_value: 0x60105c
I'm a child process, pid: 26635, ppid: 26634 | global_value: 300, &global_value: 0x60105c
I'm a parent process, pid: 26634, ppid: 23075 | global_value: 100, &global_value: 0x60105c
观察结果,对于值,子进程改变成300,父进程仍然是100可以理解,但是我们惊讶的发现,两个进程中global_val的都指向同一个地址。与我们之前理解的指针大相径庭。指针是内存中变量的地址,我们现在打印的地址同样是以指针的形式打印的,那么只能说明我们之前理解的指针是错误的,指针指向的位置并不是物理内存。因为如果是物理内存,那么不可能发生同一个地址的变量的值不相同的情况。
结论:我们所看到的打印出来的地址空间分布都是虚拟地址(又叫线性地址、逻辑地址)。 我们称这种地址为虚拟地址空间。它并不是真正的物理内存上的空间。
2. 进程地址空间
2.1 感性理解概念
设计进程的理念——进程它会认为自己是独占系统资源的(事实上并不是)
我们以虚拟机来举例子,假设我们的物理机有16G内存,预先分配给虚拟机是4G,那么这个虚拟机自己就会认为这4G就是全部,使用它浏览网页、安装软件,这些操作都不会影响到物理机因为我们的虚拟机管理软件会控制它不会干扰到物理机。同理对于一个进程,它认为自己需要16G空间,操作系统会直接给你16G的空间吗?那是不可能的,因为操作系统还要兼顾其他的进程,但每一个进程被操作系统拒绝后,也仍然会认为自己拥有全部的内存的使用权。因此,操作系统给进程画的大饼,就是进程(虚拟)地址空间。
生活中也有这样的例子,比如银行存钱,我们所存的钱一定是在银行原封不动的存放着吗?事实上是不可能的,你的钱可能会被放贷,也可能会被用来理财,但你的余额在你看来仍是那些没有变化。但如果有人说银行要倒闭,这时候一旦所有人都去取钱,也就是挤兑,这时银行是不能实现将每一个人的钱都取出来的。
2.2 如何“画饼”
我们以迅雷为例
struct 进程信息
{
char* name; // 迅雷
char* when; // 什么时候运行与结束
char* target; // 下载完一部电影
char* memory; // 需要多少内存(假设100M)
// 程序运行
}
地址空间的本质:是内核的一种数据结构。
在Linux中这种数据结构叫mm_struct,操作系统会为每个进程创建一个 mm_struct 对象,然后通过管理结构体对象来间接管理进程地址空间。
2.3 区域划分
在此之前,我们需要一些预备知识:
- 地址空间描述的基本空间大小是字节。
32位下,有232个地址。232×1字节 = 4GB的空间范围- 每一个字节都有唯一的一个地址,并且都是虚拟地址(unsigned int (32bits))
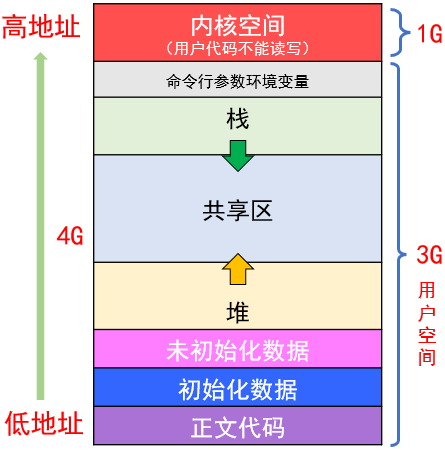
根据上图我们知道,对于区域划分,就是通过改变边界的大小,从而实现地址空间的动态分配。
struct mm_struct {
//uint32_t:32位系统下的无符号整型
uint32_t code_start, code_end;
uint32_t date_start, code_end;
uint32_t heap_start, heap_end;
unit32_t stack_start, stack_end;
...
};
我们上面也提到过,操作系统会给进程画大饼,也就是说,每一个进程被创建出来,形成对应的task_struct(进程控制块),都会有232次方个空间(4GB)里面包括进程的pid、ppid、进程优先级、进程属性等,每个task_struct都会对应一个mm_struct(每一个都是大饼),task_struct通过其中的指针变量指向对应的mm_struct。
查阅源码后可以印证我们的结论,我们之前一直所谈的C/C++地址空间实际上是进程的地址空间。
3. 进程地址空间与内存
3.1 虚拟地址和物理地址
通过上面知识我们知道,虚拟地址是连续的,因此我们也称之为线性地址。而物理地址是数据在内存与磁盘间传输的过程(即IO),IO的单位是4KB,那么我们就将内存中4KB的大小空间看成一个page,因此对于内存的数据来说,如果内存的全部大小为4GB,那么我们可以把内存分割成4GB/4KB个page,即我们可以将内存想象为一个结构体数组:struct page mem[4GB/4KB],通过偏移量就可以访问内存中所有的page,也就可以访问到内存的所有数据。
对于这些虚拟地址,作为数据来说,也需要存放在物理地址的某一个位置,因此这就会与内存产生关联。而虚拟地址与物理地址产生关联的媒介就产生了,我们将这个媒介称之为页表。

举个例子,如果内存中的某一个位置a=10,当我们编写代码时,代码的数据首先会被加载到虚拟地址中,通过页表的映射,映射到了相应的物理地址,之后就会将原有的数据修改为新的数据。
因此我们能做的,就是编辑代码让其在虚拟地址上保存,而通过页表映射到内存等其他的所有工作,都是由操作系统自动帮你完成的。
3.2 多进程的映射关系

这两个进程只能看到自己所对应的mm_struct(虚拟地址空间),就像我们前面提到的大饼,操作系统在处理这两个进程时将其编译到虚拟地址空间以及页表的过程就是操作系统给进程画的大饼,因为mm_struct都对应着2^32个地址,对于进程而言似乎可以使用全部,实际上操作系统并不允许任何一个进程完全占用所有的内存空间。
4. 地址空间存在的意义
4.1 保证安全性
进程直接访问物理内存可能会出现越界、恶意进程读取信息等非法操作,通过页表可以对非法的虚拟地址进行拦截,相当于变相的保护物理内存。
4.2 保证独立性
还是开篇那个例子,为什么相同地址下父进程和子进程的数值不同呢?
当我们编译完代码生成.c文件时,数据已经存储在磁盘了,当程序运行时,其数据会被加载到物理内存中,global_val=100也就被存放在了内存的某一块地址,由于父进程和子进程都需要访问global_val,于是global的内存中的地址就会通过页表映射到虚拟空间的某一个地址中,从而正常访问global_val,并且对应的虚拟地址也是相同的,因此开始时我们能看到父进程和子进程对应的global_val的数值和地址都相同。
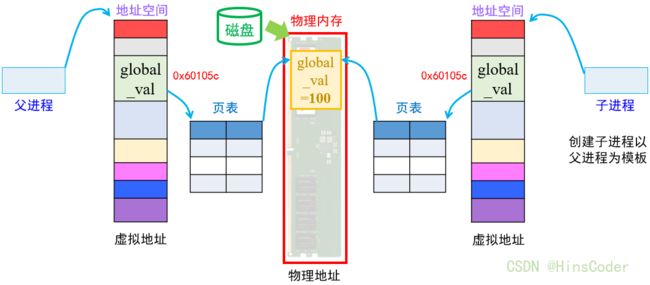
当子进程要改变global_val的值,由于进程与进程之间的独立性,子进程一旦要改变global_val,操作系统就会将子进程页表与内存的物理地址之间的联系断开,并在物理内存的另一个位置将原来物理地址的数据拷贝过来,这一操作被称为写时拷贝。 这样子进程改变global_val的值也不会影响到父进程的global_val。因此我们所看到的子进程与父进程的虚拟地址仍是相同的地址。

进程 = 内核数据结构 + 进程对应的代码和数据
内核数据结构是独立的,不同进程对应的代码和数据也是不一样的,因此进程就是独立的。因此我们也得出结论:地址空间的存在,可以更方便的进行进程和进程的数据代码的解耦,保证了进程的独立性。
4.3 保证统一性
- 在程序编译链接的时候,磁盘中的程序就有了地址,这个地址也被我们称为逻辑地址(虚拟地址)(在Linux下,虚拟地址和逻辑地址是一样的)
- 虚拟地址空间的规则不仅OS需要遵守,编译器同样需要遵守!也就是说在编译链接的过程中,编译器在编译你的代码的时候,就是按照虚拟地址空间的方式进行编址的。

假设这个exe是以32位地址空间编址的。在编译时,main中的fun()会通过逻辑地址跳转到定义的fun()函数,当代码加载到内存时,这个逻辑地址仍然存在,也就是程序内部使用的地址在加载到内存中时仍然存在,但当我们将代码加载到内存时,代码既然也是数据,那么就一定需要在物理内存中的某个物理地址进行保存,此时这段代码既有外部的物理地址,也有内部的逻辑地址,相当于有了两套地址。
那么,当这段代码通过页表的映射加载到进程的mm_struct时,这段代码就被存放在这个进程对应的进程地址空间中,这个过程就是物理地址通过映射传输的,那么当CPU的寄存器通过指令读取此代码时,出来的一定是虚拟地址。
当CPU找到了虚拟地址之后,就会通过页表的映射,按照来时的路线去寻找内存中的main()函数的代码,将这个实际存在的代码通过CPU读取。
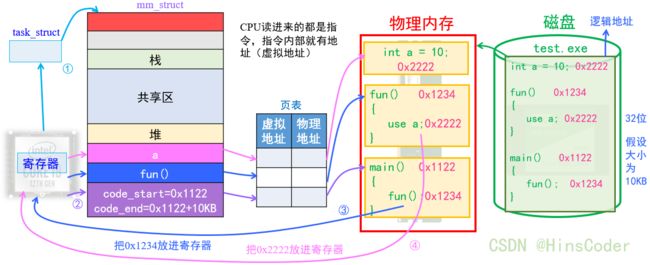
由此可以得出结论:地址空间让进程以统一的视角,来看待进程对应的代码和数据等各个区域,方便编译器也以统一的视角来进行编译代码(使用和编译的统一是指都是在虚拟地址空间的统一,因为规则一样,所以编完即可使用。)
OK,以上就是本期知识点“进程地址空间”的知识啦~~ ,感谢友友们的阅读。后续还会继续更新,欢迎持续关注哟~
如果有错误❌,欢迎批评指正呀~让我们一起相互进步
如果觉得收获满满,可以点点赞支持一下哟~