YOLOv8常见报错集合(ModuleNotFoundError、NameError、KeyError、nan值及map全为0、 CUDA out of memory、[WinError 145)
目录
1.ModuleNotFoundError: No module named ‘ultralytics‘+
解决方法:
2.KeyError: 'GAM_Attention'
2.1原因
2.2解决办法
3.NameError: name 'GAM' is not defined
3.1 原因
3.2解决办法
4.训练时出现loss出现nan值或者测试时P\R\map全部为0值
4.1原因一:
4.2原因二
4.3原因三
4.4原因四
GTX16xx用户的大坑,基本上每个GTX16xx用户使用YOLO系列算法,都会遇到这些问题。
5.[WinError 1455] 页面文件太小,无法完成操作
5.1原因
5.2解决方案
6.RuntimeError: CUDA out of memory
6.1 原因
6.2 解决方案
1.ModuleNotFoundError: No module named ‘ultralytics‘+
解决方法:
在train.py 最前面加入以下代码
import sys
sys.path.append("/home/shares/myproj/other_tasks/yolov8/")
# 即 ultralytics文件夹 所在绝对路径
执行后又报错在 task.py 中没有 ultralytics 模块, 同样在 task.py 前加入上述代码
如果执行后仍然出现该报错,则同样在出现报错的代码前加入该段代码即可
2.KeyError: 'GAM_Attention'
当我们在yolov8中添加一些注意力机制,改进网络结构时经常会遇到Key Error报错
2.1原因
使用了 pip install ultralytics
2.2解决办法
打开pycharm的终端,就是最底下的一行
![]()
选择这一个
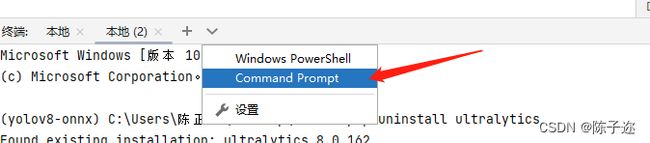
卸载pip uninstall ultralytics
 运行python setup.py install.
运行python setup.py install.
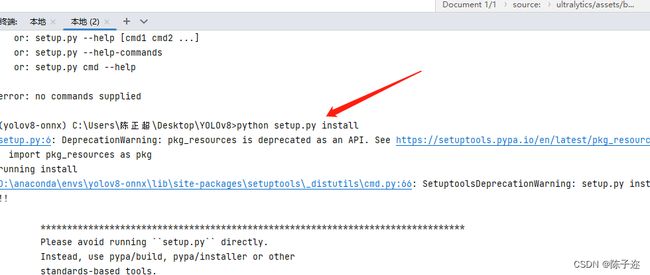
不用管中间出现啥
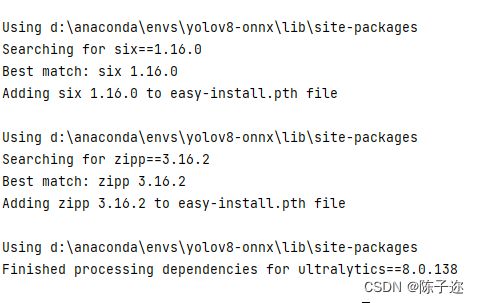
怎么判断自己是否安装成功,主要是看最后输出是否有Finished processing dependencies for ultralytics即可.
如此即可按照自己的修改后的model运行。
3.NameError: name 'GAM' is not defined
3.1 原因
模块注册出现错误
3.2解决办法
conv中添加模块

在init和task中注册及引用
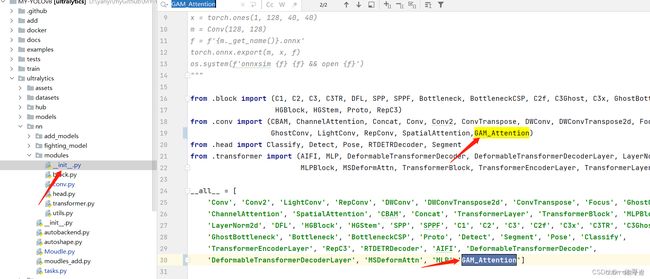

填写调用方式
 配置yaml文件
配置yaml文件
# Ultralytics YOLO , GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8-SPPCSPC.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 3, GAM_Attention, [1024]]
- [-1, 1, SPPF, [1024, 5]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
4.训练时出现loss出现nan值或者测试时P\R\map全部为0值
4.1原因一:
数据集问题
解决办法:
数据集标签和图片对应不上,或者数据集txt文件中存在中文。
4.2原因二
batchsize设置问题
解决办法:
batchsize设置处于电脑显存的临界位置,运行过程不稳定,可能前期没有问题,后期出现map为
0 的情况
4.3原因三
环境配置问题
解决办法:
建议按照下面从新配置
YOLOV8从零搭建一套目标检测系统(修改model结构必看)附一份工业缺陷检测数据集_陈子迩的博客-CSDN博客
4.4原因四
GTX16xx用户的大坑,基本上每个GTX16xx用户使用YOLO系列算法,都会遇到这些问题。
解决办法:
这个没办法,唯一的解决办法是使用cuda10.2的配置
CUDA 10.2
pip install torch==1.12.0+cu102 torchvision==0.13.0+cu102 --extra-index-url https://download.pytorch.org/whl/cu102
可能训练速度慢一点,但是也勉强能用吧,亲测是有效的
5.[WinError 1455] 页面文件太小,无法完成操作
![]()
5.1原因
虚拟内存不足。
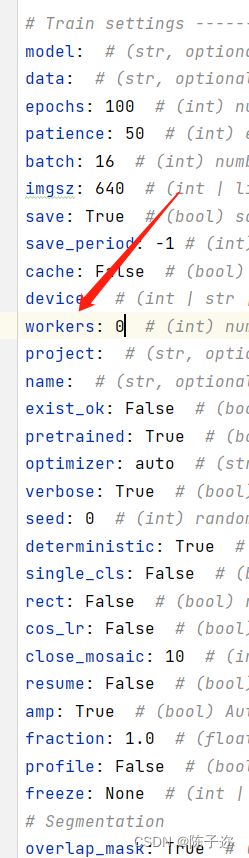
5.2解决方案
在utils文件下的datasets的第81行,将workers=nw改为=0即可:
6.RuntimeError: CUDA out of memory
6.1 原因
显卡的显存不够
6.2 解决方案
这个问题在于gpu显存,将batch改小一点就好了