监督学习---集成模型
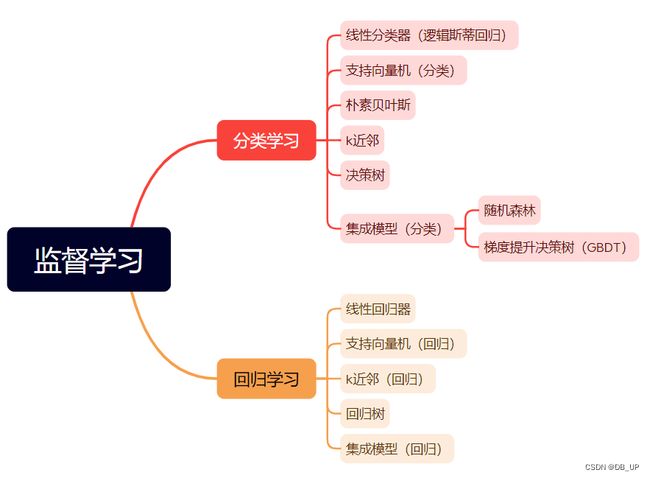
机器学习中监督学习模型的任务重点在于根据已有经验知识对未知样本的目标/标记进行预测。根据目标预测变量的类型不同,把监督学习任务大体分为分类学习和回归预测两类。
一、集成模型算法原理
集成分类/回归模型是综合考量多个分类/回归器的预测结果,从而做出决策,这种综合考量的方式大体分为两类:一种是利用相同模型训练数据同时搭建多个独立的分类/回归模型,然后通过投票的方式,以少数服从多数的原则作出最终的分类/回归决策。比较具有代表性的模型随机森林分类/回归器。另一种则是按照一定次序搭建多个分类/回归模型。这些模型之间彼此存在依赖关系。一般而言,每一个后续模型的加入都需要对现有集成模型的综合性能有所贡献,进而不断提出更新后的集成模型性能,并最终期望借助整合多个分类/回归能力较弱的分类/回归器,搭建出具有更强分类/回归能力的模型。比较具有代表性的当属梯度提升决策树。
import pandas as pd
#使用Titanic数据集,通过特征筛选的方法一步步提升决策树的预测性能
from sklearn.model_selection import train_test_split #用于分割数据集
from sklearn.feature_extraction import DictVectorizer #特征转换器
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
titanic = pd.read_csv('titanic.csv')
x=titanic[['Pclass','Age','Sex']]
y=titanic['Survived']
#对缺失数据进行填充
x['Age'].fillna(x['Age'].mean(),inplace=True)
#分割数据,采样25%用于测试
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.25)
#类别特征向量化
vec=DictVectorizer(sparse=False) #会返回一个one-hot编码矩阵
#转换特征后,凡是类别型的特征都单独剥离出来,独成一列特征,数值型的则保持不变
X_train = vec.fit_transform(x_train.to_dict(orient='record')) #将DataFrame转换为一个字典列表,其中每个字典的键是DataFrame的列名,值是相应的行值。
X_test=vec.transform(x_test.to_dict(orient='record'))
#使用决策树分类器
dtc=DecisionTreeClassifier()
dtc.fit(X_train,y_train)
dtc_y_predict=dtc.predict(X_test)
#使用随机森林分类器
rfc = RandomForestClassifier()
rfc.fit(X_train,y_train)
rfc_y_predict=rfc.predict(X_test)
#使用梯度提升决策树
gbc=GradientBoostingClassifier()
gbc.fit(X_train,y_train)
gbc_y_predict=gbc.predict(X_test)
print('the Accuracy of dtc decision tree is:',dtc.score(X_test,y_test))
print(classification_report(y_test,dtc_y_predict))
print('the Accuracy of random forest classifier is:',rfc.score(X_test,y_test))
print(classification_report(y_test,rfc_y_predict))
print('the Accuracy of gradient tree boosting is:',gbc.score(X_test,y_test))
print(classification_report(y_test,gbc_y_predict))

在相同的训练和测试数据条件下,仅仅使用模型的默认配置,梯度提升决策树(0.7937)具有最佳的预测性能,其次随机森林(0.7892),最后单一决策树(0.7803)。
二、集成模型回归
随机森林模型的另一种变种:极端随机森林。
与普通随机森林模型不同的是,极端随机森林在每当构建一棵树的分裂节点的时候,不会任意地选取特征,而是先随机收集一部分特征,然后利用信息熵和基尼不纯性等指标挑选最佳的节点特征。
import pandas as pd
from sklearn.preprocessing import StandardScaler # 归一化
from sklearn.ensemble import RandomForestRegressor,ExtraTreesRegressor,GradientBoostingRegressor
from sklearn.metrics import r2_score,mean_absolute_error,mean_squared_error
boston = pd.read_excel('boston_house_price.xlsx')
x=np.array(boston.iloc[:,:-1])
y=np.array(boston.iloc[:,-1])
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.25,random_state=33)
ss_x=StandardScaler()
X_train=ss_x.fit_transform(x_train) #x_train:(379, 13) X_train:(379, 13)
X_test=ss_x.transform(x_test) #x_test:(127, 13) X_test:(127, 13)
##说明一下:fit_transform与transform都要求操作2D数据,而此时的y_train与y_test都是1D的,因此需要调用reshape(-1,1),例如:[1,2,3]变成[[1],[2],[3]]
ss_y=StandardScaler()
Y_train=ss_y.fit_transform(y_train.reshape(-1,1))# y_train:(127,) Y_train:(127, 1)
Y_test=ss_y.transform(y_test.reshape(-1,1)) #y_test:(379,) Y_test:(379, 1)
rfr = RandomForestRegressor()
rfr.fit(X_train,Y_train)
rfr_y_predict =rfr.predict(X_test)
etr = ExtraTreesRegressor()
etr.fit(X_train,Y_train)
etr_y_predict =etr.predict(X_test)
gbr = GradientBoostingRegressor()
gbr.fit(X_train,Y_train)
gbr_y_predict =gbr.predict(X_test)
print('The r2 value of RandomForestRegressor is :',rfr.score(X_test,Y_test))
print('The mean squared error of RandomForestRegressor is :',mean_squared_error(y_test.reshape(-1,1),ss_y.inverse_transform(rfr_y_predict.reshape(-1,1)))) #(127, 1),#ss_y.inverse_transform(linear_svr_y_predict.reshape(-1,1)))(127, 1)
print('The mean absoluate error of RandomForestRegressor is :',mean_absolute_error(y_test.reshape(-1,1),ss_y.inverse_transform(rfr_y_predict.reshape(-1,1))))
print('--------------------------------------------------')
print('The r2 value of ExtraTreesRegressor is :',etr.score(X_test,Y_test))
print('The mean squared error of ExtraTreesRegressor is :',mean_squared_error(y_test.reshape(-1,1),ss_y.inverse_transform(etr_y_predict.reshape(-1,1)))) #(127, 1),#ss_y.inverse_transform(linear_svr_y_predict.reshape(-1,1)))(127, 1)
print('The mean absoluate error of ExtraTreesRegressor is :',mean_absolute_error(y_test.reshape(-1,1),ss_y.inverse_transform(etr_y_predict.reshape(-1,1))))
print('--------------------------------------------------')
print('The r2 value of GradientBoostingRegressor is :',gbr.score(X_test,Y_test))
print('The mean squared error of GradientBoostingRegressor is :',mean_squared_error(y_test.reshape(-1,1),ss_y.inverse_transform(gbr_y_predict.reshape(-1,1)))) #(127, 1),#ss_y.inverse_transform(linear_svr_y_predict.reshape(-1,1)))(127, 1)
print('The mean absoluate error of GradientBoostingRegressor is :',mean_absolute_error(y_test.reshape(-1,1),ss_y.inverse_transform(gbr_y_predict.reshape(-1,1))))
