Shell 正则表达式及综合案例及文本处理工具
目录
一、常规匹配
二、常用特殊字符
三、匹配手机号
四、案例之归档文件
五、案例之定时归档文件
六、Shell文本处理工具
1. cut工具
2. awk工具
一、常规匹配
一串不包含特殊字符的正则表达式匹配它自己
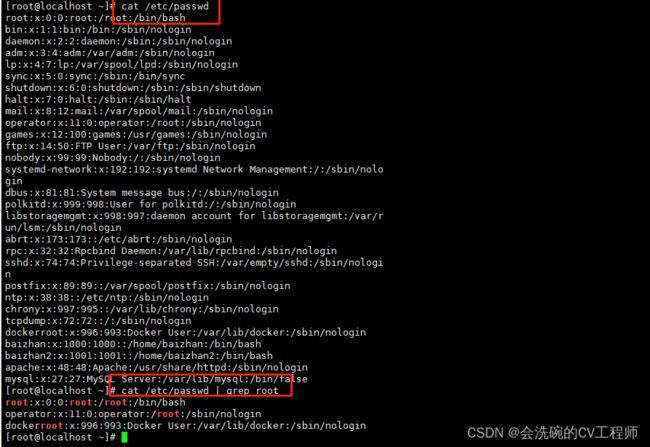
例子,比如说想要查看密码包含root字符串的,可以这样写
cat /etc/passwd | grep root
二、常用特殊字符
| 特殊字符 | 作用 |
| ^ | 匹配一行的开头 |
| $ | 匹配一行的结束 |
| . |
匹配任意一个字符 |
| * | *不单独使用,他和上一个字符连用,表示匹配上一个字符0次或者多次 |
| [] | []表示匹配某个范围内的一个字符 |
| \ | 表示转义字符,一般和特殊字符连用表示特殊字符本身 |
例1:匹配以a字符开头的:
cat /etc/passwd | grep ^a

例子2:匹配以e字符结尾
cat /etc/passwd | grep e$

例子3:匹配任一个字符
cat /ect/passwd | grep r.t
cat /ect/passwd | grep r..t

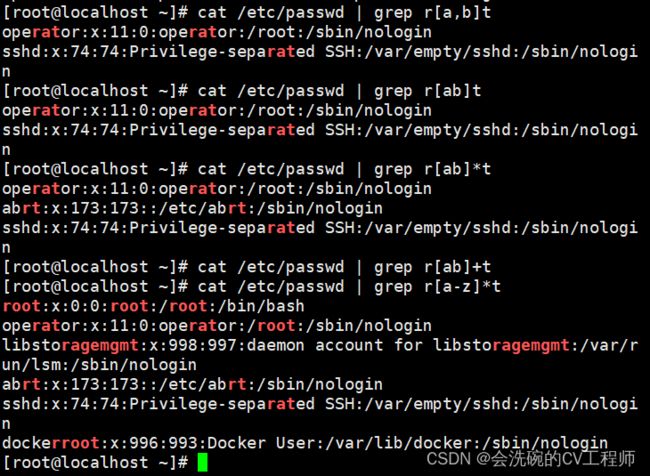
例子4:查询包含以字符r开头,t结尾的字符串
cat /etc/passwd | grep r.*t

[6,8] ------匹配6或者8
[0-9] ------匹配一个0-9 的数字
[0-9]* ------匹配任意长度的数字字符串
[a-z] ------匹配一个 a-z 之间的字符
[a-z]* -----匹配任意长度的字母字符串
[a-c,e-f] ---匹配 a-c 或者 e-f之间的任意字符
用法例子看下图吧:
例子6:假如说我们想查找n_test.sh文件包含$符的那这就需要用到转义字符
cat /scripts/n_test.sh | grep '\$'

三、匹配手机号
我们都知道手机号是由第一位数字是0,第二位是3,4,5,7,8,9;其余数字随便。总共十一位数字,因此我们可以得出
"1569656955" | grep ^1[3,4,5,7,8,9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]$
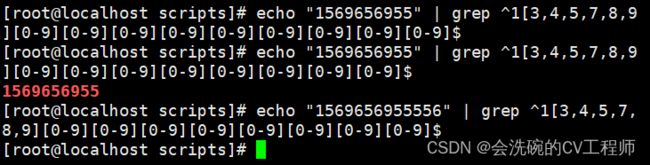
看上图可以得知,第一个数字符合手机号形式,而第二个明显不符合。但是这样【0-9】太多了,比较繁琐,我们就可以在后面用一个大括号表示出现次数来代替重复的0-9;但是要在正则表达式之前加入-E选项,如下:
grep -E ^1[3,4,5,7,8,9][0-9]{9}$
 大于小于11位数字都是不符合的
大于小于11位数字都是不符合的
四、案例之归档文件
实际生产应用中,往往需要对重要的数据进行归档备份
需求:实现一个目录归档备份的脚本,输入一个目录名称,将目录下所有文件按天归档保存,并将归档日期附加在文档文件名上,放在根目录下(/archive)
这里用到的归档命令: tar
后面可以加上 -c 选项表示归档,加上 -z 选项表示同时进行压缩得到的文件后缀名为 .tar.gz;不过要注意的是可能还是需要加上P选项代表允许我们使用绝对路径进行归档。
#!/bin/bash
# 首先判断输入的参数个数是否为1
if [ $# -ne 1 ]
then
echo "参数个数错误!应该输入一个参数作为归档目录名"
exit
fi# 从参数中获取目录名称,查看目录名称是否存在
if [ -d $1 ]
then
echo
else
echo
echo "目录不存在!"
echo
exit
fi# 获取绝对路径
DIR_NAME=$(basename $1)
DIR_PATH=$(cd $(dirname $1);pwd)# 获取当前日期,归档文件名拼接成日期
DATE=$(date +%y%m%d)# 订阅生成归档文件名称
FILE=archive_${DIR_NAME}_$DATE.tar.gz# 订阅生成归档文件的路径
DEST=/archive/$FILE# 开始归档目录文件
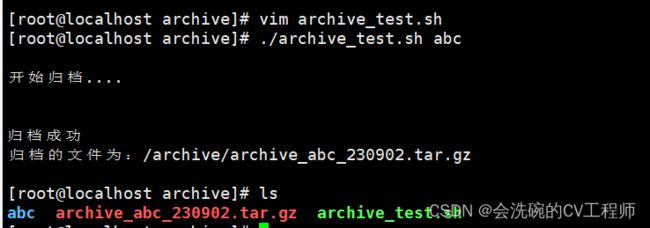
echo "开始归档...."
echo# -c 归档 z 压缩 f可视化
tar -czPf $DEST $DIR_PATH/$DIR_NAME# 判断上面文件归档文件操作是否成功
if [ $? -eq 0 ]
then
echo
echo "归档成功"
echo "归档的文件为:$DEST"
echo
else
echo "归档出现问题"
echo
fiexit
五、案例之定时归档文件
比如说我们想要1分钟归档文件一次;就可以设置定时器如下:
*/1 * * * * /archive/archive_test.sh /scripts
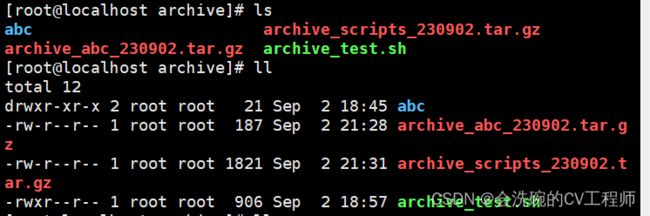
可以看得出确实添加了一个归档文件
六、Shell文本处理工具
1. cut工具
cut 的工作就是“剪”,具体的说就是在文件中负责剪切数据用的。
cut 命令从文件的每行剪切字节、字符和字段并将这些字节、字符和字段输出
基本用法
cut [选项参数] filename
选项参数
| 选项参数 | 功能 |
| -f | 列号,提取第几列 |
| -d | 分隔符,按照指定分隔符分割列,默认是制表符"\t" |
| -c | 按字符进行切割,后加n表示取第几列 比如-c 1 |
比如一个文本文件有以下诗歌:
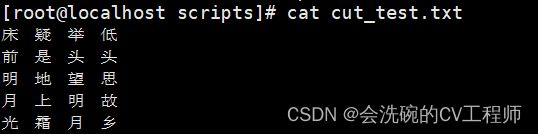
比如说我们需要提取第一列,那应该这样写,按空格指定分割第一列;如下:
cut -d " " -f 1 cut_test.txt

假如我们想要提取第一和第四列,可以这样写:
cut -d " " -f 1,4 cut_test.txt

比如说我们想知道ens33网卡的所有IP,那么首先应该是ifconfig ens33,然后管道符|,再然后正则表达式获取ip 最后利用管道符切割。
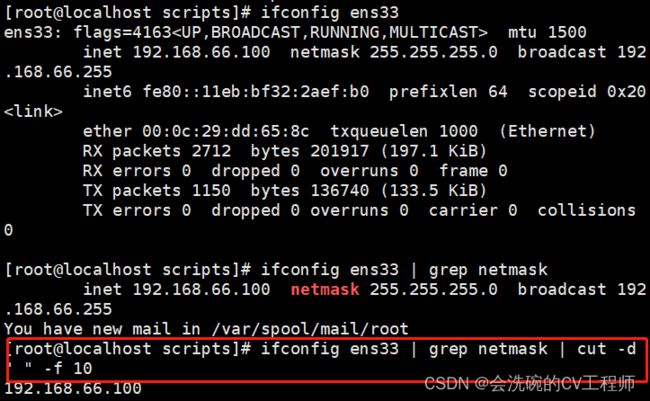
因为ip在第十列,因此-f后面跟10;整体写法如下:
ifconfig ens33 | grep netmask | cut -d " " -f 10
2. awk工具
一个强大的文本分析工具,把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理
基本用法
awk [选项参数] '/pattern1/{action1}/pattern2/{action2}...' filename
pattern:表示awk 在数据中查找的内容,就是匹配模式
action:在找到匹配内容时所执行的一系列命令
| 选项参数 | 功能 |
|---|---|
| -F | 指定文件分割符 |
| -v | 分支一个用户定义变量 |
不过有些版本的系统是不支持awk工具的,那么如何查看自己系统是否支持awk只需要输入以下句子即可:
which awk

出现上面那段话说明你的系统是支持awk工具的
实例操作
1. 搜索passwd文件以root关键字开头的所有行,并输出该行的第7列
cat /etc/passwd | awk -F ":" '/^root/ {print $7}'

2. 搜索passwd文件以root关键字开头的所有行,并输入该行的第1列和第7列,中
间以","分割
cat /etc/passwd | awk -F ":" '/^root/ {print $1 "," $7}'

3. 只显示/etc/passwd 的第一列和第七列,以逗号分割,且在所有行前面添加列
名"start"在最后一行添加"over"
cat /etc/passwd | awk -F ":" '/^root/ {print $1"," $7} END{print "over"}'

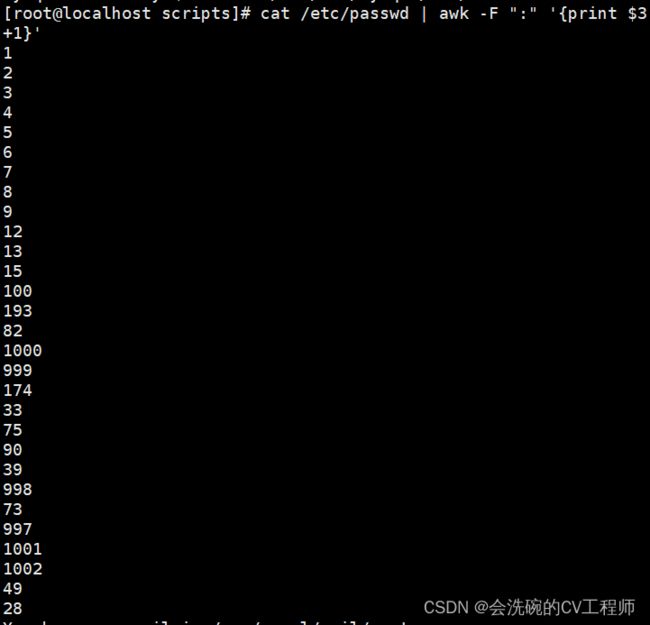
4. 将passwd文件中的用户id增加数值1并输出
cat /etc/passwd | awk -F ":" '{print $3+1}'
内置变量
| 变量 | 说明 |
|---|---|
| FILENAME | 文件名 |
| NR | 已读记录数(行号) |
| NF | 浏览记录的域的个数(切割后,列的个数) |
示例操作
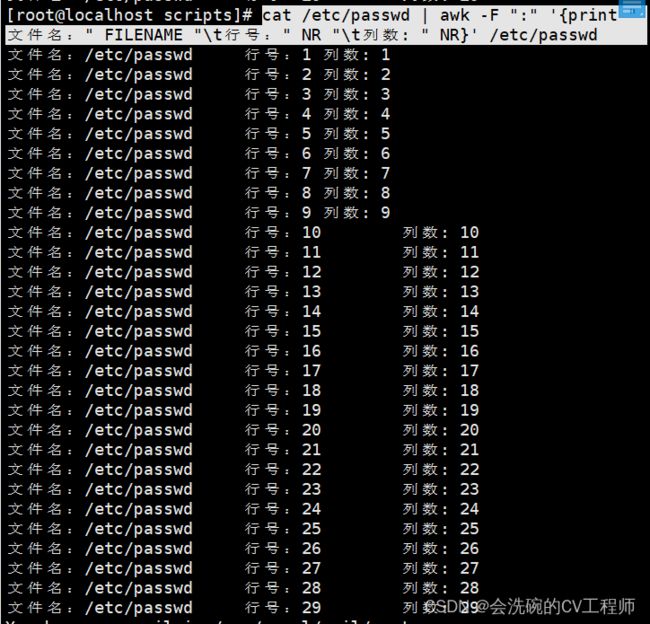
1. 统计passwd文件名,每行的行号,每列的列数
cat /etc/passwd | awk -F ":" '{print " 文件名:" FILENAME "\t行号:" NR "\t列数: " NR}' /etc/passwd
2. 查询ifconfig命令输出结果中的空行所在行号
ifconfig | awk '/^$/ {print"空行: " NR}'
