C/C++算法编写细节总结
文章目录
- 前言
- 易错点
-
- 审题
- ASCLL码
- 取模%运算
- 字符数组
-
- 存字符串
- 输入
-
- cin输入
- scanf输入
- scanf返回值
- cin读入加速
- 优先级
- 编译器报错解释
-
- 左值
- i < A.size()类型报错
- 逗号报错
- 知识点Q&A语法
-
- min_element()与max_element()
- sort
- int取值范围(C++:4Byte = 32bit)
- 绝对值
- 判断语句
- 循环语句
- Leetcode答案代码执行案例
-
- 实际刷题仅需编写类中功能函数,返回答案,即可
- set与unordered_set
- str.substr()
- 书.摘要
-
- 常用头文件函数
- folat 、double、long long格式
- long long 4字节(64位)
- class类定义
- for(auto i: s)
- 字符串string.size()
- 编写典例
-
- 闰年
- 日期数组,BFS方向向量
- 质数
- 编写分类
-
- 字符型
- `竞赛编写技巧-超重点-考前必看`
- STL容器遍历方法
- 补充算法思想
-
- 约瑟夫环
- 竞赛必备语法
-
- string类【常用】
- set
- 习惯养成
-
- pair
- 错误检查
- 常见报错
前言
为什么编程常有BUG,且常有一个BUG就让我们停滞不前,消耗精力,消耗时间,其实都是因为平时的代码细节问题。
✏️本篇文章从平时的bug中总结,不断完善,争取把编程中最容易犯的错都总结出
✏️熟悉这些细节,让编程不再容易出现bug,或是快速解决bug,争做优秀的程序员!!!
如果对您有帮助的话还请动动小手 点赞,收藏⭐️,关注❤️
易错点
审题
给出数组的元素数据是否包含负数【结合正负号选取】
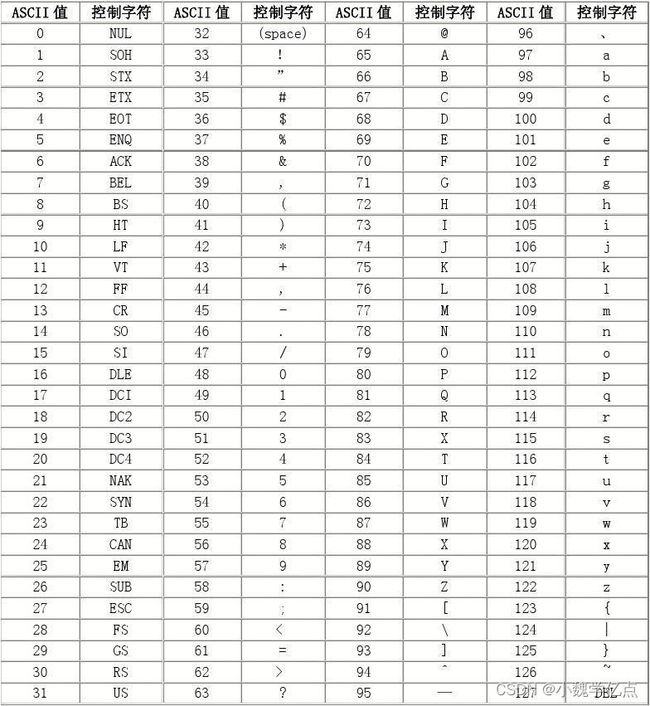
ASCLL码
字符中的数字和实际的数字相差48
ASCLL码 --> (int)‘a’ == 97 ,(int)‘A’ == 65 , (int)‘0’ == 48
cout << (int)'a' << endl << (char)97; // 分别输出 97 和 a
数字转ASCLL字符输出:【0-9对应ASCLL编号48-57】
①拆分每个位数 依次转换 (char)(各个位数+'0') //或者(char)各个位数+48
大小写转换 printf("%c",'a'+32 ); // A
易错点: '1'*'2' = 2450
我们想要的是 : (int)('1'-'0') * (int)('2'-'0') = 2
取模%运算
C语言实现不同于数学
C语言: -1 % 5 = -1 ; -6%5 = -1 【x % n 取值范围 [-n + 1 , n - 1] 】
字符数组
指针传入字符数组(字符数组每单元只能放1个字符,字符串赋值需占用多个单元格,借用指针赋值)
存字符串
简单法:
string str[] = {"0","Monday","Tuesday","Wednesday","Thursday","Friday","Saturday","Sunday"};
char型写法:
char s[][10] = {{"0"},{"Monday"},{"Tuesday"},{"Wednesday"},{"Thursday"},{"Friday"},{"Saturday"},{"Sunday"} }; char二维数组赋初始值列的数量一定要写,行可以省略
可去括号(char型推荐写法):
char s[][10] = {"0","Monday","Tuesday","Wednesday","Thursday","Friday","Saturday","Sunday"};
char型:
s[i][j]:单个字符
s[i] :可表示一个字符串
s : 字符串的首地址 (或&s[0][0] )
输入
cin输入
输入数据达到20万以上时非常明显,在100万时cin读入就会
超时
加速
#include 使用cin的情况
①string输入输出
cin >> str; cout << str << endl << cout << str << endl;
②读入多组数据以0结束:(也可以scanf但是不能while中判断结束条件)
scanf是返回读入的个数:有读入一个0也算1个
while(cin >> a >> b >> c , a || b || c) w[a][b] = c;
scanf输入
scanf("%d %c", &x, &c); 读入数据中间要有空格scanf(“%d%d”, &n, &m);则不影响 (此时cin >> x >> c; 会简单些)
double型 scanf(“%lf”,&x);
输入有换行就换行 scanf(“%d\n%c”,&x,&c);
while(scanf(“%d”,&x),x–) //读入x次
while(scanf(“%d%d”,&x,&y) && x > 0 && y > 0) //最后一行结束有一个为非正整数
【竞赛cout控制小数点需要记一些格式控制,此时printf更简单】
如日期格式:printf(“%d-%02d-%02d”,y,m,d); // y-dd-mm 不足量位的用0补齐
忘记加&://没有加& ==>输入中断
scanf返回值
输入停止时,scanf返回值为-1,若有变量输入则scanf返回值为成功读入的变量个数
仅-1取反为0 【补码】 , 所以 while(scanf(“%d”,&n) != 0) 等效为 : while(~scanf(“%d”,&n) )
cin读入加速
竞赛循环读入就用scanf,字符串cin ,也可以scanf (“%s”,str);
取消同步 : ios::sync_with_stdio(false);
ios::sync_with_stdio(false);这条语句关掉scanf 和cin 的同步加快效率。
但是即使是这样cin 还要慢 5倍左右,而且一旦使用了这条语句,scanf和cin 混用可能就会造成一些奇怪的问题。
优先级
编程也容易出错,怎么办呢?
其实很简单:【分步骤写 ,加括号】
优先级黑色版
超详细的优先级

编译器报错解释
左值
赋值号"=" 左边的值(如定义的变量,本身值为一个地址)
好文解释1
好文解释2
i < A.size()类型报错
解决此error:a,b类型改为string
warning: comparison of integer expressions of different signedness: ‘int’ and ‘std::vector::size_type’ {aka ‘long unsigned int’} [-Wsign-compare]
for (int i = 0; i < A.size(); i ++ )
逗号报错
[调用一个函数或者用break等不能’,'隔开,并列执行]
正确写法举例
①auto b = num.top(); num.pop();
②for(i = 30; ~i; i --)
{
if(i == 10)
{
printf("%d", i);
break; //或者return 0
}
}
知识点Q&A语法
min_element()与max_element()
Algorithm库
"*"取元素值
函数返回地址值 - 首地址 = 数组中下标
min_element与max_element
【目前似乎不能起始a+ Δ \Delta Δ,只能参数 (数组首地址begin(), begin() + Δ \Delta Δ或end())】
#include #include sort
C中的qsort()采用的是快排算法,C++的sort()则是改进的快排算法。两者的时间复杂度都是n*(logn),sort()一般更快,一般都用sort()。
sort包含在头文件 < algorithm > 中 ,语法描述为 sort(begin,end) 【起始地址,结尾地址】
int cmp(int a,int b)
{
return a > b; //从大到小
}
int a[3];
sort(a,a+3,cmp); //默认从小到大
int取值范围(C++:4Byte = 32bit)
C++中,int占用4字节,32比特
数据范围为:-2147483648~2147483647 [- 231, 231-1]
约: -2e9到2e9
绝对值
abs( )主要用于对求int的绝对值,被包含在< cstdlib >头文件里。
而fabs( )主要是求double ,float 型的绝对值,被包含在< cmath >头文件里。
判断语句
两种情况分支: if-else
if(条件)
else 其他情况执行(不用加条件,即不是if,就是else)
简单暴力枚举
if
else if
…
else【最后可以不加else】 //还可以全部if的暴力枚举
循环语句
do while语句与while语句非常相似。唯一的区别是,do while语句限制性循环体后检查条件。不管条件的值如何,我们都要至少执行一次循环。
break终止一层循环【最内层for/while】,continue跳过一次循环
效率递推斐波那契额f[n] = f[n-1] + f[n - 2]
if(n <= 2) return 1; //f[1] == f[2] == 1
else for(int a,b,c;;)
{
}
Leetcode答案代码执行案例
构造Solution类,main函数–>调用类中函数
实际刷题仅需编写类中功能函数,返回答案,即可
#include set与unordered_set
区别:
set基于红黑树实现,红黑树具有自动排序的功能,因此map内部所有的数据,在任何时候,都是有序的。
unordered_set基于哈希表,数据插入和查找的时间复杂度很低,几乎是常数时间,而代价是消耗比较多的内存,无自动排序功能。底层实现上,使用一个下标范围比较大的数组来存储元素,形成很多的桶,利用hash函数对key进行映射到不同区域进行保存。
set中常用函数:
(1) insert(x) : O(logN),其中N是set中元素的数量。
(2) find(x)返回set中对应值为x的迭代器:O(logN),N为set内元素的个数。
(3) erase(),erase有两种用法:删除单个元素,删除一个区间内的所有元素。
删除单个元素有两种方式,erase(it)删除该迭代器对应的元素,时间复杂度O(1),erase(x)删除该元素,时间复杂度O(logN)
删除一个区间的元素,erase(st,ed),删除区间[st,ed)内的元素,时间复杂度O(ed-st)
(4) size(),用来获得set内元素的个数,时间复杂度O(1)
(5) clear(),用来清空set中所有元素,复杂度O(N),其中N为set内元素的个数。
(6) count(x),返回set中x的数量
str.substr()
substr有2种用法:
假设:string s = "0123456789";
【只写一个参数则默认截取到结尾(最后一个元素下标:str.size()-1)】
string sub1 = s.substr(5); //只有一个数字5表示从下标为5开始一直到结尾:sub1 = "56789"
【下标位置从0开始,下标5为第6个元素】
string sub2 = s.substr(5, 3); //从下标为5开始截取长度为3位:sub2 = "567"
书.摘要
如果在执行过程中始终没有return语句,则会返回一个不确定的值。 幸好,-Wall可以捕捉到这一可疑情况并产生警告
常用头文件函数
有待改进,抽空自己整理
swap 直接用就行 , 空间 — std::swap
解释using namespace std 【适用多个同名同参函数:】
比起C语言,c++有一个新内容:using namespace std。这是什么意思呢?C++中有一个“名称空间”(namespace)的概念,用来缓解复杂程序的组织问题。例如张三写了一个函数叫 my_good_function(意思是“我的优秀函数”),李四也写了这样一个函数,但作用和张三的不 同。如果有一天需要把他们的程序合在一起用,就会出问题:函数不能重名。虽然后面会讲 到C++支持函数重载,但如果这两个函数的参数类型也完全相同,则是不能重载的。一个解决方案是分别把函数写在各自的名称空间里,然后就可以用zhang3:my_good_function() 和 li4:my_good_function( )这样的方式进行调用了。
folat 、double、long long格式
float: %f, 默认保留6位小数,double: %lf, 默认保留6位小数
%-8.3f ,表示最小宽度为8,保留3位小数,当宽度不足时在后面补上空格
%08.3f, 表示最小宽度为8,保留3位小数,当宽度不足时在前面补上0
long long int —>scanf( %lld,&变量名);
long long 4字节(64位)
int
(4个字节,32位)
unsigned int 0~4294967295
int -2147483648~2147483647
_int32
(4个字节,32位)
unsigned _int32 0~4294967295
_int32 -2147483648 ~ 2147483647
long
(4个字节,32位)
unsigned long 0~4294967295
long -2147483648~2147483647
long long
(8个字节,64位)
unsigned long long:0~1844674407370955161
long long:-9223372036854775808~9223372036854775807
_int64
(8个字节,64位)
unsigned _int64的最大值:0~18446744073709551615
_int64:-9223372036854775808~9223372036854775807
class类定义
typeder struct (结构体)(重命名名称) == struct + 结构体
== class 类名 【类似】
typeder struct node {},LNode[N],* Link; //专坑新手 , 难理解(取了两个别名,重命名两次,构造节点数组和指向节点的指针)
一篇有助于理解的文章
如果新定义类有多种成员变量,那么所有运算符使用均需要重新定义
如 ++ , – , !, >> , ±*/ , > , < , =
for(auto i: s)
for( 类型 取名称: 要遍历的首地址 ) for(auto i: s) i与s的类型相同
如q[N],会遍历N个元素,包括未赋值的部分【若只遍历赋值部分则不要用】
1.for(auto 解释实例运用版
2.简单解释清晰版
3.官方文档
字符串string.size()
复杂度不一定O(1)
两种必为O(1)写法:
调用一次size函数后将函数值进行存储,避免重复调用的开销:int len = s.size();
逆序遍历(此时只需要调用一次size函数): for(int i = s.size()-1;i>=0;i--)
string类型就用cout输出
编写典例
闰年
闰年被4整除同时不被100整除 :
if(( years%4==0&&years%100!= 0 ) || (years % 400)) 执行if值非0
日期数组,BFS方向向量
日期数组,dfs方向向量递归
记:强迫症-1开头-1结束:int dx[] = {-1, 0, 1, 0}, dy[] = {0, 1, 0, -1};
d = (d + 1) % 4;
int a = x + dx[d],b = y + dy[d] [蛇形矩阵]
int mm[13] = {31,28,31,30,31,30,31,31,30,31,30,31};//还可以第一位加0,下标从1开始
算天数注意二月:if(闰年) mm[二月下标] ++ ; 或者总天数+1
质数
bool is_prim(int x) //is_ 具有某种性质命名
{
for(int i = 2;i < n / i ; i++)
if(n % i == 0) return false;
return true;
}
编写分类
字符型
①审题:输入输出处理很重要!
影响接下来的做题思路和处理
如读入一行句子,判单词是否满足某特性,可以用getchar()读取每个字符
getchar()可以读入单个字符包括空格跟换行符
cin 或 scanf 读到空格结束
scanf 可进化:
scanf("%[\^\n]", 变量名); 换行才停止: 等效读取一行
while(scanf("%c", &ch) != -1); 单个字符读取,过滤空格【只有读到EOF结尾才返回-1】
#includegets() : 遇到回车结束
cin.get(s,strlen(s)) : 遇到回车结束
多个句子(一行多个单词):二维字符串数组读入
char ch[100][100];
while(scanf("%s",&ch[i])); 遇到空格,回车存入一串单词
string s;
while(cin >> s);
进阶技巧:scanf("%[^c]")当c就是遇到这个字符就结束 【相同异或为0】
更多进阶技巧
cin.getline(a,50,'#') 可接收空格,回车符。字符数读到最大值或遇指定字符'#'结束
scanf("%[格式字符组合]",a)//只读入格式字符规定的字符,遇其它字符或回车符结束
(“格式字符组合”,可以是单个字符,也可以是ASCII码中连续的字符,组合之间用 逗号号分开)
只读入小写字母:scanf("%[a-z]",a)
只读入小写字母和数字及大写字母A:scanf("%[a-z,0-9,A]",a)
竞赛编写技巧-超重点-考前必看
Q&A
问:字典序
答:如dfs多个从小到大枚举的形参,即可满足字典序
问:从0开始和从1开始
答:总结一些下标从1开始的情况和从0开始的情况 【 根据题目 : 如0开始下标(x,y)更好求 , 从1开始边界不用特判 ,如前缀和 以及路径用到的值就是从1开始, 没有0
求max都可以从1开始边界初始值为0不影响max,只影响min
问:输入输出 选 int 还是 char
答:看题目空间限制大小和数据范围
sqrt与 x,y类型 的选取
开根号:结构体类型double : 而且要考虑精度问题如:x-y= Δ \Delta Δ < 1e-6 就认为相等
STL容器遍历方法
以vector可变长数组举例:
①【使用容器-配套for(auto x: 首地址) 遍历】
注意这时不能用vectorres[N]指定长度
②vector< int > res , int len = res.size() 用res[i]
③for(vector< int >::iterator it = res.begin() ; it != res.end(); it++) printf("%d, *it); 【迭代器类比指针】
补充算法思想
约瑟夫环
好文章1
好文章2
最简版【需理解】
int f(int n, int m)
{
if(n == 1) return n;
return (f(n - 1, m) + m - 1) % n + 1;
}
队列
#include 异或 :
由 x ^ 0 = x 推出: x ^ x ^ y = 0 ^ y = y
共11个元素含有1-10,其中一个数重复出现思想-代码过于简单
树的遍历-dfs
递归-找重复子问题-找变化-找边界思想-代码过于简单
换酒问题-不错
int numWaterBottles(int numBottles, int numExchange){ //numExchange交换一瓶需要的空瓶子数量
int bottle = numBottles;//空瓶子的数量
int ans = numBottles;//总共喝的酒
while(bottle >= numExchange)//空瓶子只要大于numExchange,循环就要继续
{
bottle -= numExchange;
ans++;
bottle++;
}
return ans;
}
竞赛必备语法
string类【常用】
string str("abc"); //构造函数
string str(3, 'a'); //aaa
string str2(str); //copy
string str3 = str1 + str2; //concat连接
str1 == str2 可直接运算符比较
str.append(str2);//末尾添加
str.append("abc");//末尾添加
string sub = str.substr(0,3); //第一个元素下标从0开始, 截取n个字符,不写第二个参数默认截取到结尾
getline(cin, str); //读取一行字符串
str.find() //size_type类型函数返回值: 找到返回首次出现下标(从0开始) , 没找到string::npos
str.rfind(字符串)//逆序查找 , 也是size_type类型 [有很多重载函数:参数不详细介绍]
str.back(); //获取字符串最后一个字符
str.back() = "z"; //修改字符串最后一个字符
str.front(); //获取字符串第一个字符
str.front() = 'a'; //修改字符串第一个字符
string.pop_back() //删除字符串最后一个元素
str.at(0) //等效str[0]
str.size() // cstring库
str.insert(idx, string) ;//字符串插入位置(从0开始)
str.erase(idx, n); //下标从0开始, 删n个字符,不写此参数删到末尾
str.erase(it); // 把 s1 字符串中迭代器 it 处的字符删除 ,str.begin()或end() - 1 :指向头尾
str1.swap(str2); //字符串交换
高阶复合使用
s1.replace(pos, len, s2); // 把 s1 中从下标 pos 开始的长度为 len 的子串替换为 s2
s1.replace(s1.find(a), a.size(), b);
s1.erase(s1.begin()); //等效s1.erase(0, 1); 【删除首元素】
s1.erase(s1.end() - 1); //或者s1.erase(s1.size() - 1); 【删除最后一个元素】
判断是否为同一个字符的大小写:如A与a
如A与aASCLL码相差32: A ^ a == 二进制数100000
if(ch1 ^ ch2 == 32) puts("同一字符大小写"); //两个字符是否为同一个字母的大小写
set
set<int> a;
a.insert(x); 插入
a.insert(b.begin(),b.end()); 插入一个范围
a.erase(); 删除
for (auto i = a.begin() i != a.end() ; i++) cout << *i <<" ";
c.find(k); 返回一个迭代器,直线第一个关键字为k的元素,若k不在容器中返回尾迭代器
c.count(k); 返回关键字为k的元素的数量,对不允许重复关键字的容器来说,返回值是0或1
c.lower_bound(k); 返回一个迭代器,指向第一个关键字不为小于k的迭代器
c.upper_bound(k); 返回一个迭代器,指向第一个关键字不为大于k的迭代器
c.equal_range(k); 返回一个迭代器pair,指向第一个关键字等于k的迭代器对应元素范围(因为关键字是按顺序存储的)
习惯养成
代码风格
#include取名
bool is_性质
cnt, tot,total,count,sum
pair
声明命名空间: using namespace std;
或 using std::pair; pair
使用全名 std::pair
pair文章
pair<int, int> p1(1, 2);
pair<int, int> p2(p1); //用已有的对象初始化
pair<int, float> p3(1, 3.14);
pair<int, int> p4; //没有显示初始化,自动执行默认初始化操作。p4为(0,0)
强制类型转换
pair<int, int> p1(1, 2);
pair<int, int> p2;
p2 = pair<int, int> (1, 4);//赋值操作,强制类型转换为pair型
p2 = p1; //赋值操作
使用make_pair()函数
pair<int, int> p3;
p3 = make_pair(1, 4); //无需指明类型,可自动生成pair对象
pair有两个属性: first和 second。
但竞赛宏定义便捷
#define x first //x等效first
#definte y second
pair<int, int> p1(1, 2);
p1.x = 3, p1.y = 4;
cout << p1.x << " " << p1.y << endl;
cout << p1.first << " " << p1.second << endl;
错误检查
①scanf没有加& 或 数组越界, SF段错误
②类型检查如 LL :输入输出scanf(),printf()均为 %lld,运算过程全部(LL)
③命名冲突:如与库函数同名,开局部变量,需要全局的可以改用大写
④Segmentation Fault : 如 mid = tr[u].l + tr[u].r 线段树递归过程超出数组边界报错SF
常见报错
Time Limit Exceeded:死循环
SE :段错误 【如数组空间不够】
Memory Limit Exceeded: 一般是开数组过大超过存储空间限制
Wrong Answer: 结果错误
Compile Error:编译错误
Segmentation fault 一般开数组过小,内存访问越界 , 或死循环
Presentation Error:格式错误 (马上就可AC)
Float Point Exception [浮点数溢出] 【可能是因为除以0】
最后祝大家
AC