【操作系统笔记】进程和线程
进程的组成
进程要读取 ELF 文件,那么:
- ① 要知道文件系统的信息,
fs_struct - ② 要知道打开的文件的信息,
files_struct
一个进程除了需要读取 ELF 文件外,还可以读取其他的文件中的数据。

进程中肯定有一个 mm_struct 实例,每个进程都有自己的虚拟地址空间,用于进程访问内存的。

进程中肯定得知道下一条需要执行指令的内存地址,这个内存地址存储在 CPU 的程序计数器中。
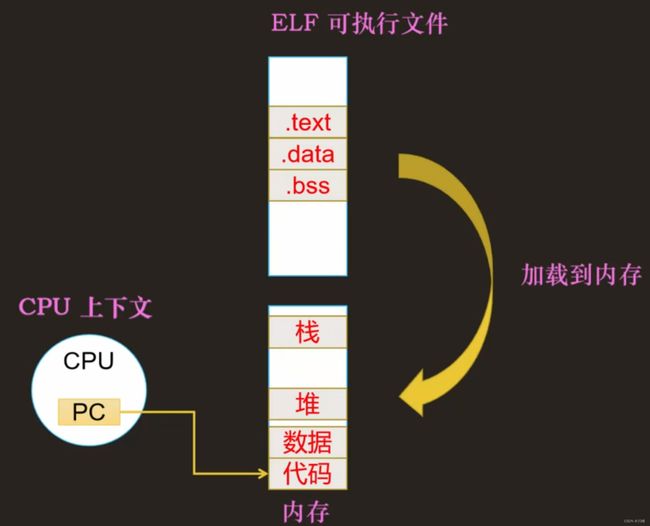
每个进程都可以运行在:用户态和内核态,所以,每个进程都应该有:
- ① 一个用户栈
- ② 一个内核栈
总结:
-
每个进程中有一个
mm_struct实例,其中包含vm_area_struct管理进程的虚拟地址空间、页表(pgd) -
每个进程还包括一组寄存器中的值,即进程运行时的CPU上下文(指令指针计数器、通用寄存器、标志位寄存器、段寄存器)
-
每个进程都可以运行在 用户态 和 内核态,所以每个进程都有一个用户栈和一个内核栈
CPU上下文切换(系统调用)
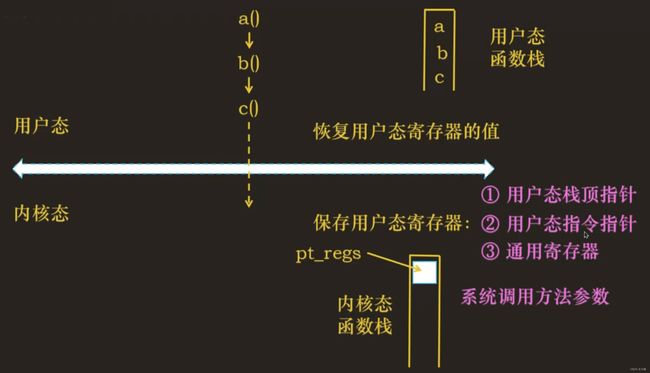

当发生系统调用时,进程从用户态陷入内核态,会发生一次 CPU 上下文切换,首先系统将用户态的 CPU 上下文信息保存在内核栈中,然后将 CPU 寄存器中的值更新为内核态的相关值,开始执行内核态的程序代码指令,系统调用结束以后,再将内核栈中保存的用户态 CPU 上下文信息恢复到 CPU 寄存器中,从内核态切换回用户态,继续执行用户态的进程的,此时又发生了一次 CPU 上下文的切换,所以一次系统调用会发生 2 次 CPU 上下文切换。
系统调用如何实现从用户态切换到内核态?
-
① 32 位系统通过 80 中断 实现
-
② 64 位系统通过汇编指令 syscall
中断可以打断用户态进程,进入内核态执行对应的中断处理程序,所以当中断发生时,也会发生 CPU 上下文切换。因此,如果中断发生的次数太多的话,会严重降低操作系统的性能。
进程切换与时钟中断
一个 CPU 在同一个时刻能执行一个程序的指令,只也就说,同一时刻,只有一个进程可以执行。
如何在只有一个 CPU 的情况下同时运行多个进程呢?
- 基本思想:运行一个进程一段时间,然后再运行另一个进程,如此轮换
- 通过时分共享的方式,实现对 CPU 的虚拟化,使得每个进程都觉得自己拥有一个CPU
- 通过虚拟地址空间,实现对内存的虚拟化,使得每个进程都觉得自己拥有全部的内存

在 Linux 操作系统中,使用一个叫 task_struct 的结构体来描述进程相关的一组抽象信息
如何实现一个 CPU 同时运行多个进程:时钟中断,每次 CPU 发生时钟中断时,由操作系统的进程调度算法选择一个进程运行。
0 号进程、1 号进程以及 2 号进程
0 号进程(idle 进程)
0 号进程是一个内核进程。内核进程 VS 普通进程:
-
① 内核进程只运行在内核态,而普通进程既可以运行在内核态,也可以运行用户态
-
② 内核进程只能用大于
PAGE_OFFSET的虚拟地址空间,而普通进程可以用所有的虚拟地址空间
0 号进程是所有进程的祖先,由于历史原因也叫 swapper 进程。
这个祖先进程使用下列静态分配的数据结构:
- ①
task_struct存放在init_task中, 包含init_mm、init_fs、init_files等 - ② 主内核页全局目录存放在
swapper_pg_dir
start_kernal() 函数:初始化内核需要的所有数据结构、激活中断,创建 1 号内核进程(init 进程)。

注:只有当没有可运行的进程的时候,才会运行 0 号进程。0 号进程不是一个实实在在可以看到的进程,所谓的 0 号进程是单用户、单任务的系统启动代码。
1 号进程(init 进程)
1 号进程 由 0 号进程创建,它的 PID = 1 并且共享 0 号进程所有的数据结构,包括 init_mm 和页表等。
1 号进程也叫 systemd 进程,所有普通进程都由它来创建。

在系统关闭之前,init 进程一直存活,因为它创建和监控在操作系统外层执行的所有进程的活动。
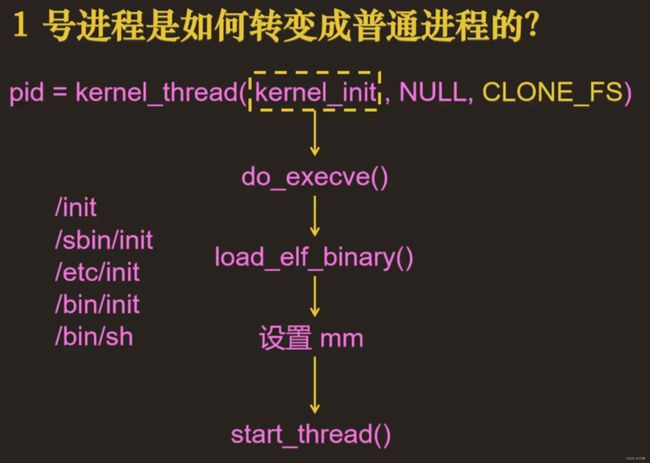
1 号进程一开始是内核进程,先执行init()函数完成内核初始化,然后调用 execve() 装入可执行程序 init, 这样,init 进程就变为一个普通进程了。
2 号进程(kthreadd 进程)
2 号进程是所有内核进程的祖先
- kswapd:执行物理页面的回收,交换出不用的页帧
- pdflush:刷新 “脏” 缓冲区的内容到磁盘以回收内存

2 号进程也是由 0 号进程创建的,因此它的 active_mm 也指向 init_mm,共享 0 号进程的所有资源。
总结
-
0 号进程是所有进程的祖先,它是一个内核进程,0 号进程创建了 1 号进程和 2 号进程,0 号进程是唯一一个不需要通过 fork 创建的进程。
-
1 号进程是所有普通进程的祖先,它开始是一个内核进程,启动完主线程后,它从内核态切换到用户态变成一个普通进程,在系统关闭之前,1 号进程一直存活,1 号进程又叫 init 进程。
-
2 号进程是所有内核进程的祖先,2 号进程又叫 kthreadd 进程。
只有没有可运行进程的时候才会运行 0 号进程,0 号进程是系统启动代码,1 号和2 号进程的 active_mm 都指向 0 号进程的 init_mm,共享 0 号进程的所有资源。
进程的创建 (fork 和 exec 系统调用)

进程创建是通过系统调用 sys_fork() 实现的:
- 目的:创建一个新的进程
- 本质:在内核中创建一个
task_struct实例/对象,然后将task_struct维护到各种链表队列(用于管理和调度进程)中。但并不是创建全新的task_struct,而是拷贝父进程的task_struct。
因为新创建的进程的 task_struct 是完全拷贝的父进程的,所以此时代码段、数据段、函数栈等完全跟父进程一样,所以fork()方法会返回 2 次,根据返回的 pid 来区分当前是父进程还是子进程,如果返回的 pid > 0 则认为当前是父进程,那么应该等待子进程结束,如果返回的 pid == 0 则认为当前是运行的子进程,那么应该调用 execve() 方法启动子进程(加载子进程的代码程序 ELF 文件)。
fork() 系统调用流程参考图:
父进程与子进程结构:

execve() 系统调用流程参考图:
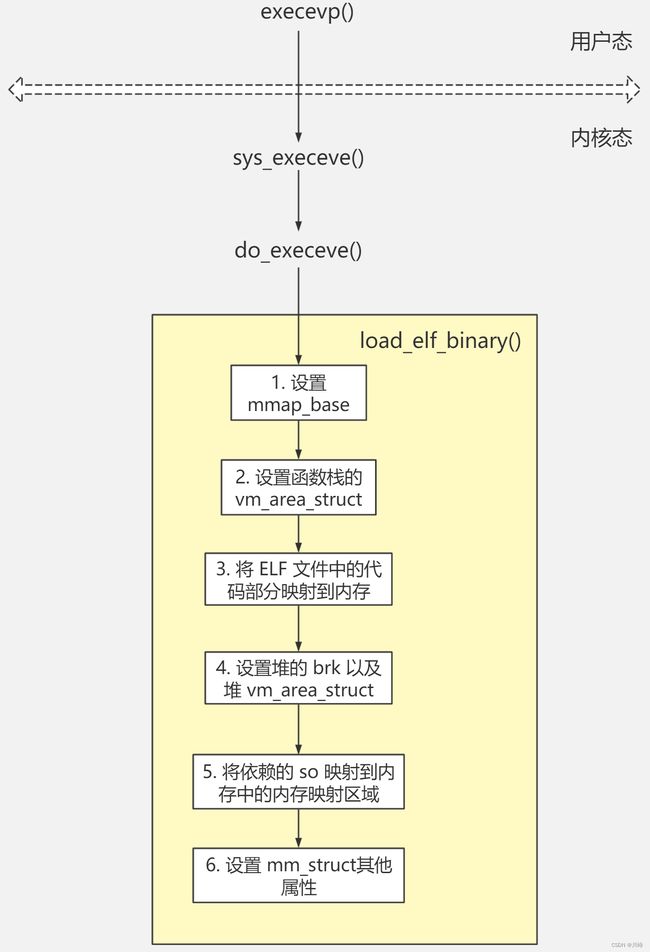
创建进程的详细流程图:https://www.processon.com/view/link/624573275653bb072bd0363a
exec 比较特殊,它是一组函数:
- ① 包含
p的函数(execvp,execlp) 会在PATH路径下面寻找程序; - ② 不包含
p的函数需要输入程序的全路径; - ③ 包含
v的函数(execv,execvp,execve)以数组的形式接收参数; - ④ 包含
l的函数(execl,execlp,execle)以列表的形式接收参数; - ⑤ 包含
e的函数(execve,execle)以数组的形式接收环境变量。
总结
-
用户态调用
fork()方法,陷入到内核态调用sys_fork()方法, -
内核态中主要是创建一个全新的
task_struct实例,并从父进程中拷贝task_struct需要的各种信息,然后为子进程分配新的PID,并将新的task_struct加入到双向链表中,接着唤醒进程,将进程设置为TASK_RUNNING状态,将task_struct加入调度队列,等待 CPU 调度 -
由于子进程的
task_struct是完全拷贝父进程的,所以子进程的代码段、数据段、函数栈等完全跟父进程一样,所以fork()方法会返回2次,对于父进程,返回的PID是子进程的PID,也就是父进程创建子进程时分配的PID,对于子进程,返回的PID是0,因为子进程根本没有执行fork方法,直接从函数栈返回处开始执行,因此PID是0。 -
fork()返回PID > 0时,父进程会等待子进程执行完,返回PID == 0时,会执行调用execve()方法启动子进程(execve()就是将子进程的 ELF 可执行目标文件加载到内存,进行内存映射等)。
线程
线程解决进程开销大的问题:
-
① 线程直接共享进程的所有资源(比如
mm_struct),所以线程就变轻了,创建线程比创建进程要快到 10~100 倍 -
② 线程之间共享相同的地址空间(
mm_struct),这样利于线程之间数据高效的传输 -
③ 可以在一个进程中创建多个线程,实现程序的并发执行
-
④ 多 CPU 系统中,多线程可以真正的并行执行
重新认识进程:
-
从资源管理的角度来看,进程把一组相关的资源管理起来,构成了一个资源平台,这些资源包括地址空间(用于存储代码、数据等的内存)、打开的文件等磁盘资源,可能还会有网络资源等。
-
从程序运行的角度来看,进程的执行功能以及执行状态都交给线程来管理了,也就是说,代码在进程提供的这个资源平台上的一条执行流程,就是线程了。
-
线程成了进程的一个重要的组成部分,进程除了完成资源管理的功能之外,它还需要一系列的线程来完成执行的过程。
-
进程由两部分组成:一部分是资源管理;一部分是线程
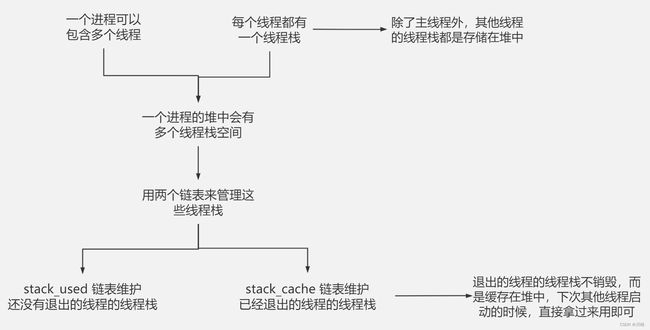
如何创建一个线程呢?— pthread
这里可以理解为 Java 中线程的 ThreadLocal 类。
线程创建流程图:
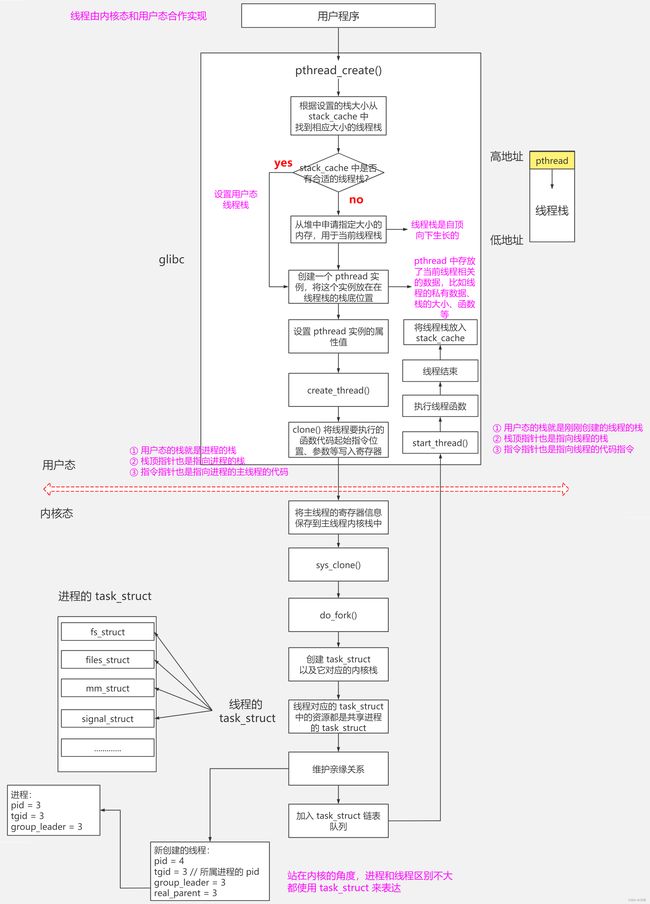
线程创建虽然由用户态 pthread_create() 发起,但是陷入内核态时,最终仍然是调用的 do_fork() 方法直接拷贝进程的 task_struct 结构体来描述,只是描述上有些字段区分线程和进程。在内核看来,线程和进程的区别不大,都是使用 task_struct 结构体来描述的。
总结:
-
所有线程共享进程的资源,包括进程的
mm_struct, 全局变量和全局数据等 -
每个线程可以有自己的私有数据
-
主线程栈默认就是进程的函数栈,而其他线程的栈存放在进程的堆里
-
用户态通过
pthread_create()创建线程,陷入内核态调用do_fork()方法创建task_struct实例和对应的内核栈,task_struct中的信息都是直接共享使用进程的 -
在内核态,线程和进程信息都是使用
task_struct结构体来描述的,只不过是通过某些字段上的区分
用户级线程 VS 内核级线程


用户级线程的缺点:
-
① 如果进程中的一个用户级线程因为发起了一次系统调用而阻塞,那么这个用户线程所在的整个进程会处于等待状态(其他任何用户级线程都不能运行)
-
② 当一个用户级线程运行后,除非它主动的交出 CPU 的使用权,否则它所在的进程当中的其他线程将无法运行
-
③ 因为只有用户级线程,而操作系统又看不到用户级线程,所以操作系统只会将时间片分配给进程
用户级线程 vs 内核级线程
线程的实现方式主要有两种,分别是用户级线程、内核级线程
- 用户级线程:在用户空间实现的线程,操作系统看不到的线程,用户级线程是由一些应用程序中的线程库来实现,应用程序可以调用线程库的 API 来完成线程的创建、线程的结束等操作。
- 内核级线程:在内核空间实现的线程,由操作系统管理的线程,内核级线程管理的所有工作都是由操作系统内核完成,比如内核线程的创建、结束、是否占用 CPU 等都是由操作系统内核来管理。
总结:
-
用户级线程是在用户空间实现的线程,由应用程序的一些线程库的 API 来完成创建和管理,操作系统内核看不到用户级线程。
-
内核级线程是在内核空间实现的线程,由操作系统的内核来管理线程的创建和使用等。
-
用户级线程和内核级线程关系是 N : 1,将多个用户级线程映射到同一个内核级线程,优点是用户空间管理方便高效,缺点是一个用户级线程被阻塞则该进程内所有线程都被阻塞,因为用户级线程对操作系统不可见,操作系统只能感知到进程单位。
-
用户级线程和内核级线程关系是 1 : 1,将每一个用户级线程映射到一个内核级线程,优点是并发能力强,一个线程被阻塞其他线程可以继续执行,缺点是资源开销比较大,影响性能,因为每创建一个用户线程都需要创建一个内核线程与之对应,pthread 和 Java 的线程都属于这种实现。
-
用户级线程和内核级线程关系是 m : n,特点是前两种对应关系的折中,go 中的协程是这种实现。
内核线程
fork、clone 系统调用


进程包含的 mm_struct
问题一:内核线程和内核级线程到底有什么区别?
-
答:首先,它俩在内核中都会有对应的
task_struct实例,但是内核线程的
task_struct的mm属性的值是空的,也就是内核线程的话不会使用用户态虚拟地址空间,而只是使用内核态虚拟地址空间。而内核级线程的
task_struct的mm属性的值不是空的,也就是说内核级线程除了可以访问内核态虚拟地址空间,也是可以访问用户态虚拟地址空间。以上就是内核态线程和内核级线程之间的本质区别。
问题二:什么时候需要内核线程,什么时候需要内核级线程呢?
-
答:当用户应用程序需要创建线程的时候,就需要有内核级线程与之对应。
内核线程用于执行只和内核有关的任务,一般运行在后台,和用户程序没有任何关系。
相信你还记得 2 号进程实际上就是由 0 号进程创建出来的内核进程吧,我们也可以将 2 号进程称为是内核线程,它是所有内核线程的父亲。
由 2 号内核线程创建出来的 kswap 就是一个内核线程,它主要是实时的监控整个物理内存的使用情况,如果物理内存不够了,kswap 内核线程需要回收一部分物理页帧,将这部分的物理页中的数据交换到磁盘中。
kswap 这种线程干的事情和用户程序没有任何关系,只是为内核服务,帮内核干事情的,所以,我们称这种线程为内核线程。
在内核中,可以通过函数
kernel_thread()来创建一个内核线程。
总结
-
一个进程的
task_struct实例中的mm_struct分为两部分:mm和active_mm,其中mm用于访问用户虚拟地址空间,active_mm是动态的,它指向进程当前所处的虚拟地址空间,如果进程当前是运行在用户态,那么active_mm = mm,如果进程当前是运行在内核态,那么active_mm = init_mm(init_mm就是当前进程从父进程拷贝来的,而所有进程的init_mm最终都拷贝自 0 号进程) -
内核线程是指那些只为内核服务的线程,它只运行的内核空间,只能使用内核虚拟地址空间,因此它的
active_mm永远指向init_mm, 它的mm永远是空 -
内核线程和内核级线程的区别:内核级线程是用户创建线程的时候,需要有一个内核级线程与之对应,内核级线程可以同时访问用户虚拟地址空间和内核虚拟地址空间,内核级线程的
mm不是空的,内核线程只能访问内核虚拟地址空间,内核线程的mm是空的,内核线程和用户程序没有任何关系。 -
2 号进程是所有内核进程的父亲,可以把 2 号进程的主线程称为是一个内核线程,它是所有内核线程的父亲,由 2 号内核线程创建出来的所有线程都属于内核线程。
线程状态 / 线程的生命周期
线程从创建到结束可能会经历的阶段包括:
-
① 线程创建: 就绪线程,可能同时存在多个就绪线程,调度算法选择一个就绪线程
-
② 线程运行:得到了 CPU 的执行权线程等待
-
③ 线程等待:线程阻塞,线程等待其他线程执行结果,该线程需要的数据还没到达,一旦线程处于等待的时候,就不会占用 CPU 了,这个时候 CPU 可以去执行其他就绪线程了。
注意:线程只能自己阻塞自己,因为只有线程自身才能知道何时需要等待某种事件的发生。而处于等待的线程只能被其他的线程或者操作系统唤醒。线程处于等待状态时,只是线程本身自己被阻塞,但是此时 CPU 不是阻塞的,CPU 可以执行其他线程任务,直到某个线程唤醒被阻塞等待的线程。
-
④ 线程唤醒:被阻塞线程需要的资源被满足,或者说被阻塞线程等到的事件到达了。一旦线程被唤醒,那么它就从等待状态变成就绪状态,这样也就意味着这个线程可以被操作系统调度占用 CPU 执行了。
-
⑤ 线程结束

线程挂起状态发生在:当线程需要的内存数据所在的物理内存页帧被内存置换算法 LRU 置换到了磁盘中,此时进入挂起状态,只有当内存数据被重新从磁盘换回物理内存时,才会恢复解挂状态。
Linux 中线程阻塞分为了 可中断阻塞 和 不可中断阻塞 两种。



不可中断状态一般是内核进程使用的,内核进程正在执行某个必要且不可被打断的任务时,必须设置为不可中断,不响应中断退出信号,否则可能出现系统异常。
总结:
-
线程状态:线程创建、线程就绪、线程运行、线程阻塞等待、线程挂起、线程终止结束
-
处于就绪状态的线程可以被 CPU 调度算法选择进入运行状态,运行状态的线程获得了 CPU 的执行权
-
处于运行状态的线程可能因为 CPU 时间片用完进入就绪状态,也可能因为需要的资源被其他线程占用而进入阻塞等待状态
-
处于阻塞状态的线程不会占用 CPU,CPU 此时可以执行其他线程任务,线程只能自己阻塞自己,而处于阻塞等待的线程只能被其他线程或操作系统唤醒,阻塞的线程一旦被唤醒就进入就绪状态
-
在阻塞状态和就绪状态之上,可以出现线程挂起状态,线程挂起状态发生的根本原因是线程所需的内存数据因为物理页帧被内存置换算法(如LRU) 所回收,内存数据被置换到了磁盘当中,只有当内存数据从磁盘中再次换回到物理内存中时,才会恢复解挂状态,返回原来的阻塞状态或就绪状态
-
在 Linux 中,线程的就绪状态和运行状态合并为一个,线程的就绪和运行都使用
TASK_RUNNING来标识,但在运行时会有一个指针专门指向当前运行的任务 -
Linux中,线程阻塞状态分为可中断阻塞和不可中断阻塞,前者可以响应中断信号,执行对应的信号处理程序,后者不响应中断信号,这一般是内核线程执行某些重要任务如 DMA 拷贝内存数据,必须保证不可被打断。
线程和进程的不同
两者的定义:
- 进程:一个具有一定独立功能的程序在一个数据集合上的一次动态执行过程
- 线程:进程当中的一条执行流程
进程包含了线程,进程是由资源管理和线程组成。
-
① 进程是资源分配的单位,因为进程主要的任务还是管理一个程序运行过程中的资源
-
② 线程是 CPU 调度单位,CPU 是执行程序的,然后在一个进程中,程序的执行又是以线程为单位来进行的
线程比进程执行效率高:
-
① 首先,线程的创建需要的时间比进程短,因为进程在创建的时候,还需要去维护其他的一些管理信息,比如维护内存的管理,维护打开文件的关系等,而线程创建的时候它可以直接重用它所属进程已经管理好的资源即可
-
② 其次,和创建需要的时间一样,线程的终止需要的时间也比进程短,因为线程不需要考虑资源释放的问题
-
③ 由于同一进程的各线程间共享内存和文件资源,所以线程间数据交换是非常快的,不需要经过操作系统内核(也就是不需要切换到内核态),直接通过内存地址就可以访问共享数据
-
④ 最后,在同一进程中的线程切换的时间,比进程之间的切换时间要短。因为进程的切换需要切换进程对应的页表,需要 flush TLB,会影响性能,而进程中的所有线程是共享同一个页表的,所以线程切换的时候,不需要切换页表
线程和进程创建流程上的区别:

线程数量太多,会耗尽系统内存,影响系统的性能和稳定性。
总结:
-
线程的创建和销毁所需要的时间都比进程要短,线程需要考虑维护的资源比进程少
-
线程共享进程所有的内存和文件资源,所以线程之间交换数据非常快,不需要切换到内核态,通过内存地址就可以访问
-
同一进程内线程间的切换,要比不同进程间的切换时间短,因为进程间需要切换页表,线程不需要,同一进程中的线程共享同一个页表
-
每个线程/进程在内核都有一个
task_struct与之对应,每个task_struct中都有一个内核栈和用户栈,线程运行在用户态使用的是用户栈,线程运行在内核态使用的内核栈,每次创建线程都需要申请内存用来创建内核栈和用户栈,内存是有限的,所以线程是有上限的。 -
进程主线程的用户栈在
mm_struct中的函数栈,进程中子线程的用户栈保存在堆当中。 -
线程创建的性能损耗主要是发生在 CPU 的上下文切换(系统调用发生 2 次切换),而创建线程需要的内核栈的内存分配是很快的。
-
内核态是无法控制线程数量的,因此,只能在用户态控制线程的无限制使用,使用线程池技术,主要有两点优化:避免线程创建时的系统调用 CPU 上下文切换带来的性能损耗,避免线程数量创建过多。线程用完以后不还给操作系统(不销毁线程),后面重用。