【leetcode】146.LRU缓存机制 (哈希表+双向链表,java实现)
146. LRU缓存机制
难度中等
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。
获取数据 get(key) - 如果关键字 (key) 存在于缓存中,则获取关键字的值(总是正数),否则返回 -1。
写入数据 put(key, value) - 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字/值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
进阶:
你是否可以在 O(1) 时间复杂度内完成这两种操作?
示例:
LRUCache cache = new LRUCache( 2 /* 缓存容量 */ );
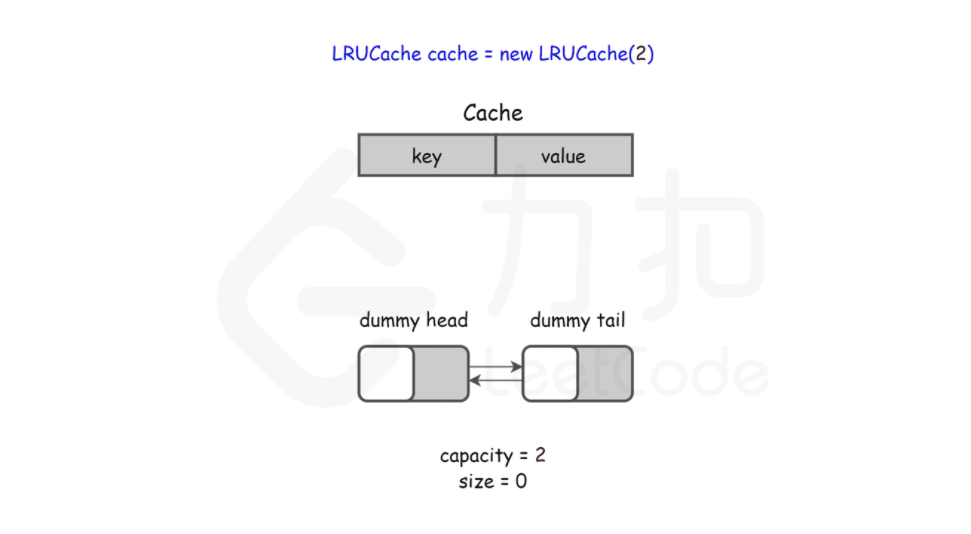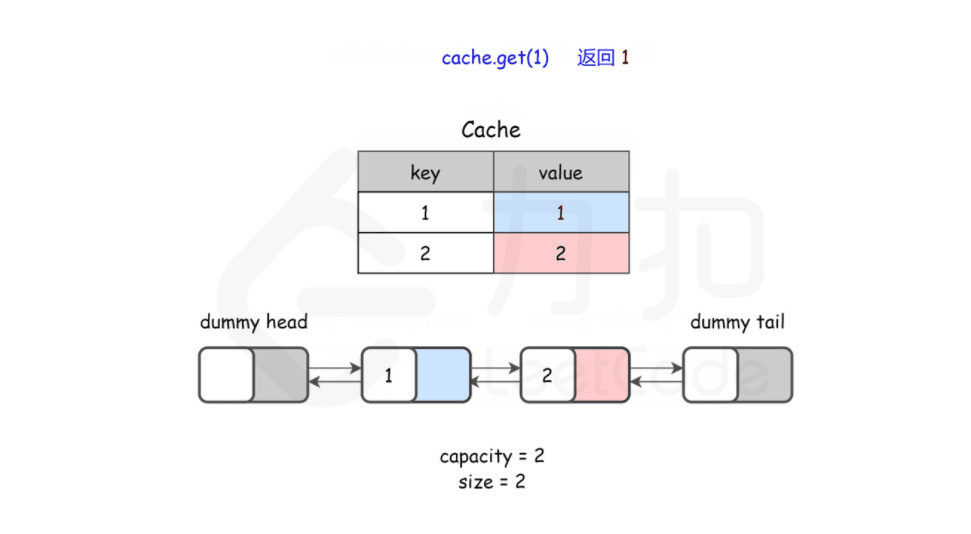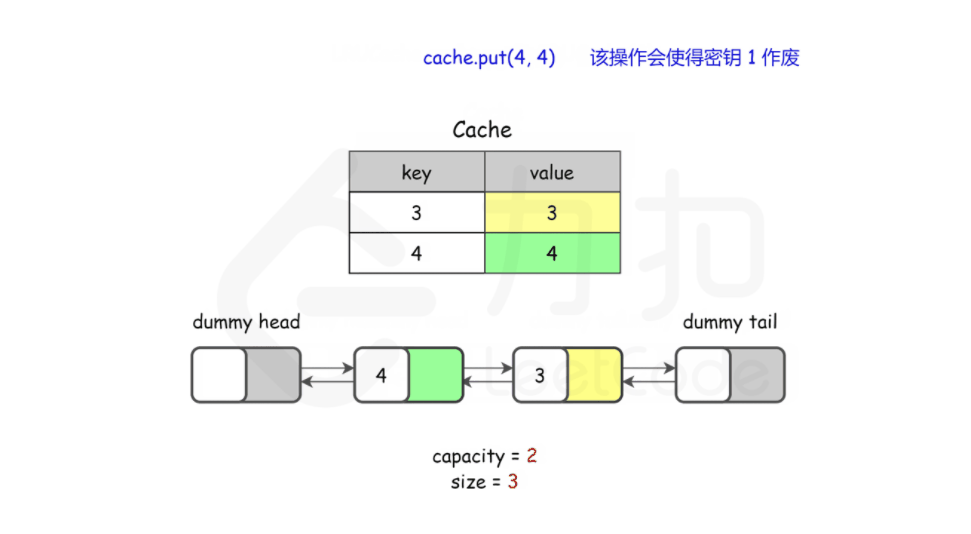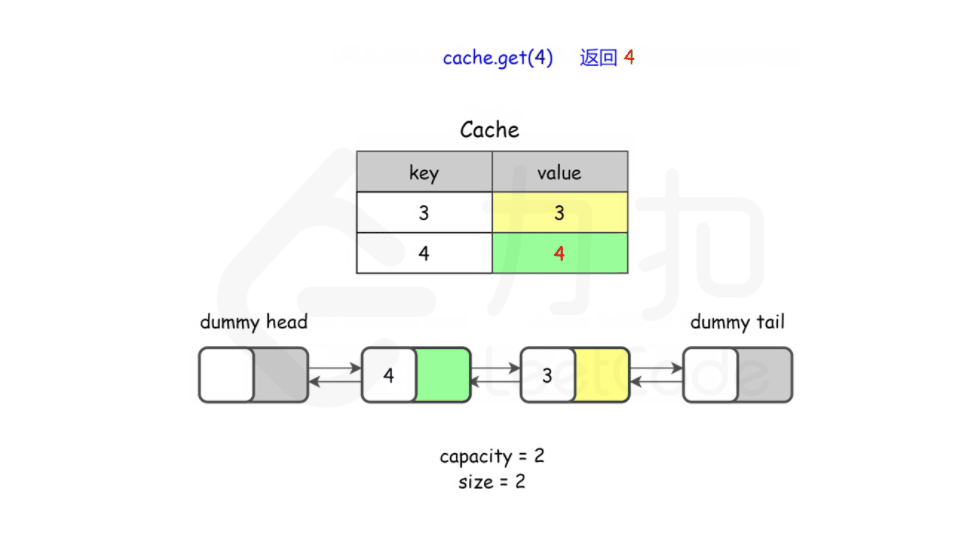
cache.put(1, 1);
cache.put(2, 2);
cache.get(1); // 返回 1
cache.put(3, 3); // 该操作会使得关键字 2 作废
cache.get(2); // 返回 -1 (未找到)
cache.put(4, 4); // 该操作会使得关键字 1 作废
cache.get(1); // 返回 -1 (未找到)
cache.get(3); // 返回 3
cache.get(4); // 返回 4
分析
方法一:哈希表 + 双向链表
算法
LRU 缓存机制可以通过哈希表辅以双向链表实现,我们用一个哈希表和一个双向链表维护所有在缓存中的键值对。
- 双向链表按照被使用的顺序存储了这些键值对,靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的。
- 哈希表即为普通的哈希映射(HashMap),通过缓存数据的键映射到其在双向链表中的位置。
这样以来,我们首先使用哈希表进行定位,找出缓存项在双向链表中的位置,随后将其移动到双向链表的头部,即可在 O(1)O(1) 的时间内完成 get 或者 put 操作。具体的方法如下:
- 对于
get操作,首先判断key是否存在:- 如果
key不存在,则返回 -1−1; - 如果
key存在,则key对应的节点是最近被使用的节点。通过哈希表定位到该节点在双向链表中的位置,并将其移动到双向链表的头部,最后返回该节点的值。
- 如果
- 对于
put操作,首先判断key是否存在:- 如果
key不存在,使用key和value创建一个新的节点,在双向链表的头部添加该节点,并将key和该节点添加进哈希表中。然后判断双向链表的节点数是否超出容量,如果超出容量,则删除双向链表的尾部节点,并删除哈希表中对应的项; - 如果
key存在,则与get操作类似,先通过哈希表定位,再将对应的节点的值更新为value,并将该节点移到双向链表的头部。
- 如果
上述各项操作中,访问哈希表的时间复杂度为 O(1)O(1),在双向链表的头部添加节点、在双向链表的尾部删除节点的复杂度也为 O(1)O(1)。而将一个节点移到双向链表的头部,可以分成「删除该节点」和「在双向链表的头部添加节点」两步操作,都可以在 O(1)O(1) 时间内完成。
小贴士
在双向链表的实现中,使用一个伪头部(dummy head)和伪尾部(dummy tail)标记界限,这样在添加节点和删除节点的时候就不需要检查相邻的节点是否存在。
public class LRUCache {
class DLinkedNode {
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode() {}
public DLinkedNode(int _key, int _value) {key = _key; value = _value;}
}
private Map<Integer, DLinkedNode> cache = new HashMap<Integer, DLinkedNode>();
private int size;
private int capacity;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
// 使用伪头部和伪尾部节点
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.prev = head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node == null) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 添加进哈希表
cache.put(key, newNode);
// 添加至双向链表的头部
addToHead(newNode);
++size;
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode tail = removeTail();
// 删除哈希表中对应的项
cache.remove(tail.key);
--size;
}
}
else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
node.value = value;
moveToHead(node);
}
}
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
}
复杂度分析
- 时间复杂度:对于
put和get都是 O(1)O(1)。 - 空间复杂度: O ( capacity ) O(\text{capacity}) O(capacity),因为哈希表和双向链表最多存储 capacity + 1 \text{capacity} + 1 capacity+1 个元素。
方法二:调用封装数据结构LinkedHashMap,源码分析
简单介绍LinkedHashMap(跟题目有关的知识点)
HashMap 大家都清楚,底层是 数组 + 红黑树 + 链表 (不清楚也没有关系),同时其是无序的,而 LinkedHashMap 刚好就比 HashMap 多这一个功能,就是其提供 有序,并且,LinkedHashMap的有序可以按两种顺序排列,一种是按照插入的顺序,一种是按照读取的顺序(这个题目的示例就是告诉我们要按照读取的顺序进行排序),而其内部是靠 建立一个双向链表 来维护这个顺序的,在每次插入、删除后,都会调用一个函数来进行 双向链表的维护 ,准确的来说,是有三个函数来做这件事,这三个函数都统称为 回调函数 ,这三个函数分别是:
- void afterNodeAccess(Node
其作用就是在访问元素之后,将该元素放到双向链表的尾巴处(所以这个函数只有在按照读取的顺序的时候才会执行),之所以提这个,是建议大家去看看,如何优美的实现在双向链表中将指定元素放入链尾! - void afterNodeRemoval(Node
其作用就是在删除元素之后,将元素从双向链表中删除,还是非常建议大家去看看这个函数的,很优美的方式在双向链表中删除节点! - void afterNodeInsertion(boolean evict) { }
这个才是我们题目中会用到的,在插入新元素之后,需要回调函数判断是否需要移除一直不用的某些元素!
其次,我再介绍一下 LinkedHashMap 的构造函数!
其主要是两个构造方法,一个是继承 HashMap ,一个是可以选择 accessOrder 的值(默认 false,代表按照插入顺序排序)来确定是按插入顺序还是读取顺序排序。
- Java
/**
* //调用父类HashMap的构造方法。
* Constructs an empty insertion-ordered LinkedHashMap instance
* with the default initial capacity (16) and load factor (0.75).
*/
public LinkedHashMap() {
super();
accessOrder = false;
}
// 这里的 accessOrder 默认是为false,如果要按读取顺序排序需要将其设为 true
// initialCapacity 代表 map 的 容量,loadFactor 代表加载因子 (默认即可)
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
思路 & 代码
下面是我自己在分析 LinkedHashMap 源码时做的一些笔记,应该是比较清楚的,主体意思就是我们要继承 LinkedHashMap,然后复写 removeEldestEntry()函数,就能拥有我们自己的缓存策略!
- Java
// 在插入一个新元素之后,如果是按插入顺序排序,即调用newNode()中的linkNodeLast()完成
// 如果是按照读取顺序排序,即调用afterNodeAccess()完成
// 那么这个方法是干嘛的呢,这个就是著名的 LRU 算法啦
// 在插入完成之后,需要回调函数判断是否需要移除某些元素!
// LinkedHashMap 函数部分源码
/**
* 插入新节点才会触发该方法,因为只有插入新节点才需要内存
* 根据 HashMap 的 putVal 方法, evict 一直是 true
* removeEldestEntry 方法表示移除规则, 在 LinkedHashMap 里一直返回 false
* 所以在 LinkedHashMap 里这个方法相当于什么都不做
*/
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
// 根据条件判断是否移除最近最少被访问的节点
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
// 移除最近最少被访问条件之一,通过覆盖此方法可实现不同策略的缓存
// LinkedHashMap是默认返回false的,我们可以继承LinkedHashMap然后复写该方法即可
// 例如 LeetCode 第 146 题就是采用该种方法,直接 return size() > capacity;
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
通过上述代码,我们就已经知道了只要复写 removeEldestEntry() 即可,而条件就是 map 的大小不超过 给定的容量,超过了就得使用 LRU 了!然后根据题目给定的语句构造和调用:
- Java
/**
* LRUCache 对象会以如下语句构造和调用:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/
很明显我们只需要直接继承父类的put函数即可,因为题目没有特殊要求,故可以不写!至于 get() 函数,题目是有要求的!
获取数据 get(key) - 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。
所以我们可以调用 LinkedHashMap 中的 getOrDefault(),完美符合这个要求,即当key不存在时会返回默认值 -1。
至此,我们就基本完成了本题的要求,只要写一个构造函数即可,答案的 super(capacity, 0.75F, true);,没看过源码的小伙伴可能不太清楚这个构造函数,这就是我上文讲的 LinkedHashMap 中的常用的第二个构造方法,具体大家可以看我上面代码的注释!
至此,大功告成!
- Java
class LRUCache extends LinkedHashMap<Integer, Integer>{
private int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75F, true);
this.capacity = capacity;
}
public int get(int key) {
return super.getOrDefault(key, -1);
}
// 这个可不写
public void put(int key, int value) {
super.put(key, value);
}
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
}
最后,附上我最开始讲的那两个函数的源码以及部分自己的解析
//标准的如何在双向链表中将指定元素放入队尾
// LinkedHashMap 中覆写
//访问元素之后的回调方法
/**
* 1. 使用 get 方法会访问到节点, 从而触发调用这个方法
* 2. 使用 put 方法插入节点, 如果 key 存在, 也算要访问节点, 从而触发该方法
* 3. 只有 accessOrder 是 true 才会调用该方法
* 4. 这个方法会把访问到的最后节点重新插入到双向链表结尾
*/
void afterNodeAccess(Node<K,V> e) { // move node to last
// 用 last 表示插入 e 前的尾节点
// 插入 e 后 e 是尾节点, 所以也是表示 e 的前一个节点
LinkedHashMap.Entry<K,V> last;
//如果是访问序,且当前节点并不是尾节点
//将该节点置为双向链表的尾部
if (accessOrder && (last = tail) != e) {
// p: 当前节点
// b: 前一个节点
// a: 后一个节点
// 结构为: b <=> p <=> a
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 结构变成: b <=> p <- a
p.after = null;
// 如果当前节点 p 本身是头节点, 那么头结点要改成 a
if (b == null)
head = a;
// 如果 p 不是头尾节点, 把前后节点连接, 变成: b -> a
else
b.after = a;
// a 非空, 和 b 连接, 变成: b <- a
if (a != null)
a.before = b;
// 如果 a 为空, 说明 p 是尾节点, b 就是它的前一个节点, 符合 last 的定义
// 这个 else 没有意义,因为最开头if已经确保了p不是尾结点了,自然after不会是null
else
last = b;
// 如果这是空链表, p 改成头结点
if (last == null)
head = p;
// 否则把 p 插入到链表尾部
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
void afterNodeRemoval(Node<K,V> e) { // 优美的一笔,学习一波如何在双向链表中删除节点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 将 p 节点的前驱后后继引用置空
p.before = p.after = null;
// b 为 null,表明 p 是头节点
if (b == null)
head = a;
else
b.after = a;
// a 为 null,表明 p 是尾节点
if (a == null)
tail = b;
else
a.before = b;
}
(LinkedHashMap.Entry)e, b = p.before, a = p.after;
// 将 p 节点的前驱后后继引用置空
p.before = p.after = null;
// b 为 null,表明 p 是头节点
if (b == null)
head = a;
else
b.after = a;
// a 为 null,表明 p 是尾节点
if (a == null)
tail = b;
else
a.before = b;
}