二叉树顶上战争实战——手撕数据结构
目录
-
- 传统艺能
- 1.二叉树最大深度
- DFS
- 分治思想(法)
- 实现
- 2.单值二叉树
-
- Tree节点数
- 叶子节点个数
- 第K层节点数
- 三大遍历
-
- 前序遍历
- 中序遍历
- 后序遍历
传统艺能
小编是双非本科大一菜鸟不赘述,欢迎大佬指点江山(QQ:1319365055)
此前博客点我!点我!请搜索博主 【知晓天空之蓝】
乔乔的gitee代码库(打灰人 )欢迎访问,点我!
非科班转码社区诚邀您入驻
小伙伴们,打码路上一路向北,背后烟火,彼岸之前皆是疾苦
一个人的单打独斗不如一群人的砥砺前行
这是我和梦想合伙人组建的社区,诚邀各位有志之士的加入!!
社区用户好文均加精(“标兵”文章字数2000+加精,“达人”文章字数1500+加精)
直达: 社区链接点我
倾力打造转码社区微信公众号,等你加入

1.二叉树最大深度
链接:二叉树最大深度
给定一个二叉树,找出其最大深度,二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
示例:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回它的最大深度 3 。
思路: 从现在开始,给我记住谈到二叉树必须敏感俩个字: 递归!!
没错,很多二叉树的OJ题会把递归的思想体现的淋漓尽致,因为 Tree 的构成是利用递归去实现和定义的。
DFS
最大深度就是指最长路径的结点数,那问题就来到了如何确定最长路径,这里就要引入一个思想叫: DFS,即深度优先搜索。
和他类似的还有广度优先搜索,也是对一个连通图进行遍历的算法。它的思想是从一个顶点V0开始,沿着一条路一直走到底,如果发现不能到达目标解,那就返回到上一个节点,然后从另一条路开始走到底,这种尽量往深处走的概念即是深度优先的概念。
这个场景下 DFS 含义并不难理解,但我们需要知道如何去实现他。
分治思想(法)
我们很明确的一点就是二叉树的结构一共只有三个部分:根节点,左子树,右子树;不管是二叉树还是他的子树还是他的子树的子树,这个结构是雷打不动的,那么我们要统计一棵树上的要素,我们就可以让他们各司其职,这就引入了分治法这个概念

分治法含义就是将一个大的问题分解成若干个小的问题,并且这些小问题与大问题的问题性质保持一致,通过处理小问题从而处理大问题,这里又用到了递归的思想哈。
我们把二叉树硬掰成 “左子树+右子树” 结构,就好像皇上今天想算 1+1 ,但他就是懒,让我宰相和太尉来算,而两人也是懒狗,宰相交给他下面的尚书,太尉交给他下面的太傅……知道没有下级才开始返回结果,这么看来我们算 1+1 就相当于是统计 宰相+太尉 两条路的答案。
实现
那么要解决这道题就有三个关键点:明白 Tree 的构成,DFS思想找出深度以及考虑 root 节点为空的情况:
int maxDepth(struct TreeNode* root){
if(root==NULL)
{
return 0;
}
int m = maxDepth(root->left);//左子树遍历
int n = maxDepth(root->right);//右子树遍历
return m>n?m+1:n+1;//返回较大的一方(不要忘了加上根节点)
}
别看这简简单单几行代码,浓缩的信息量却是巨大的,大家可以画画图体会体会整个递归过程。

2.单值二叉树
链接:单值二叉树
如果二叉树每个节点都具有相同的值,那么该二叉树就是单值二叉树,只有给定的树是单值二叉树时,才返回 true;否则返回 false
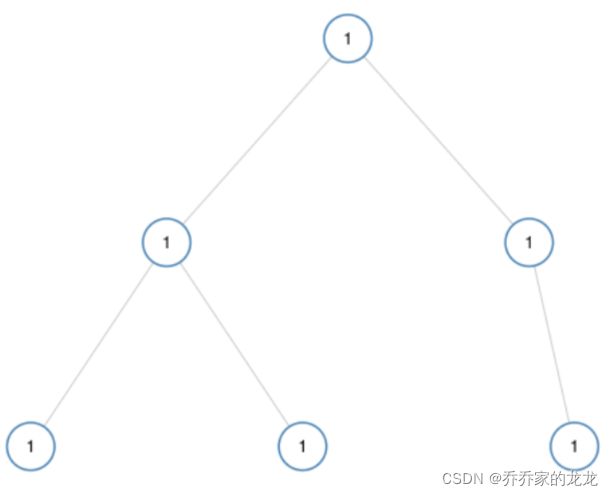
输入:[1,1,1,1,1,null,1]
输出:true
思路:如果上一道题摆弄明白了,这道题也就简单了,基本方法是分治法+对比判断,这里对比时注意我们判断为 true 的情况比较多,那我们可以转向去罗列 false 的情况。
bool dfs(struct TreeNode* root,int k)
{if(root == NULL)
{
return true;
}//排除空树
if(dfs(root->left,k)==false)
{
return false;//左子树节点不匹配
}
if(dfs(root->right,k)==false)
{
return false;//右子树节点不匹配
}
if(root->val!=k)
{
return false;//根节点节点不匹配
}
return true;
}
bool isUnivalTree(struct TreeNode* root){
return dfs(root,root->val);//递归调用遍历Tree
}

引申:
我们同样可以借助分治+递归的基本模型思想解决二叉树的一些衍生的基本操作
Tree节点数
同理于最大深度,不同点在于这是求和不是求最大值
int BinaryTreeSize(BTNode* root)
{
if (root == NULL)
{
return 0;
}
int m = BinaryTreeSize(root->left);
int n = BinaryTreeSize(root->right);
return m + n + 1;
}
叶子节点个数
明确叶子节点结构为 左孩子和右孩子为空,满足就返回1,递归进行计数即可:
int BinaryTreeLeafSize(BTNode* root)
{
if (root == NULL)
{
return 0;
}
if (root->left == NULL && root->right == NULL)
{
return 1;
}
int m = BinaryTreeLeafSize(root->left);
int n = BinaryTreeLeafSize(root->right);
return m + n;
}
第K层节点数
这个稍微需要思考一下,如何定位k层这个条件是题目唯一的难点,我们依然采用递归的形式去得到目标层数,在递归中增设一个条件为 (k-1),用作每次递归来逐渐接近层数,刚开始为 k 层,递归到子节点时为 (k-1),再递归到 (k-2),直到 k 为1时即证明到达了目标层:
int BinaryTreeLevelKSize(BTNode* root, int k)
{
if (root == NULL)
{
return 0;
}
if (k == 1)
{
return 1;//找到目标层所满足的K值
}
int m = BinaryTreeLevelKSize(root->left, k - 1);
int n = BinaryTreeLevelKSize(root->right, k - 1);
return m + n;
}
三大遍历
二叉树的深度优先遍历可细分为前序遍历、中序遍历、后序遍历,这三种遍历可以用递归实现,也可使用非递归实现(主要分析递归实现)。
前序遍历
前序遍历的特点为 根节点->左子树->右子树,注意看代码放入数据是放在两条递归语句之前的,所以先访问根节点 root,数据放入 root,然后访问左子树root->left,此时左子树又作为根节点放入数据,再访问此时根节点的左子树……
void BinaryTreePrevOrder(BTNode* root)
{
if (root == NULL)
{
return;
}
if (root)
{
putchar(root->data);
BinaryTreePrevOrder(root->left);
BinaryTreePrevOrder(root->right);
}
}
中序遍历
中序遍历的特点为 左子树->根节点->右子树,原理和前序遍历相同,不赘述:
void BinaryTreeInOrder(BTNode* root)
{
if (root == NULL)
{
return;
}
BinaryTreeInOrder(root->left);
putchar(root->data);
BinaryTreeInOrder(root->right);
}
后序遍历
中序遍历的特点为 左子树->右子树->根节点,原理和前序遍历相同,不赘述:
void BinaryTreePostOrder(BTNode* root)
{
if (root == NULL)
{
return;
}
BinaryTreePostOrder(root->left);
BinaryTreePostOrder(root->right);
putchar(root->data);
}
今天就先到这里吧,摸了家人们