数据库与缓存的数据一致性
先更新数据库,还是先更新缓存?
在客户端请求数据时,如果能在缓存中命中数据,那就直接查询缓存,不用再去查询数据库,从而减轻数据库的压力,提高服务器的性能。
但是由于引入了缓存,那么在数据更新时,不仅要更新数据库,而且还要更新缓存,这两个更新操作存在前后顺序问题。
先更新数据库,再更新缓存
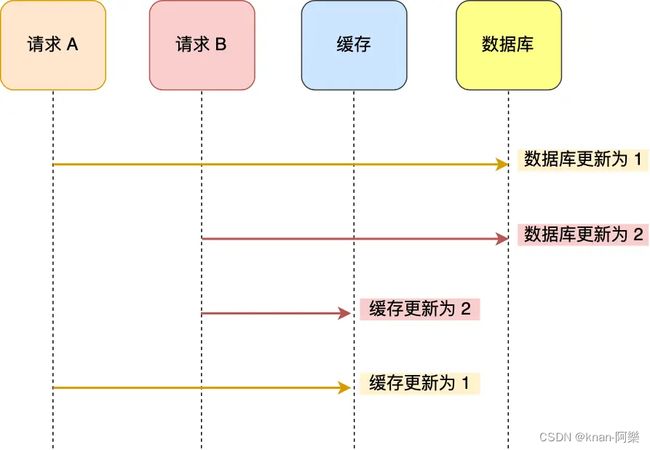
请求 A 先将数据库的数据更新为 1,然后在更新缓存前,请求 B 将数据库的数据更新为 2,紧接着也把缓存更新为 2,然后请求 A 更新缓存为 1。
此时,数据库中的数据是 2,而缓存中的数据却是 1,出现了缓存和数据库中的数据不一致的现象。
先更新缓存,再更新数据库
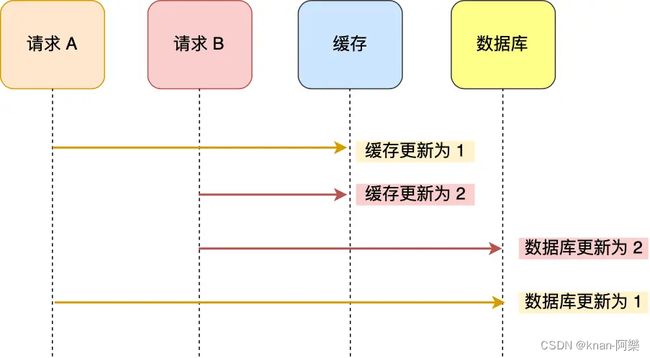
请求 A 先将缓存的数据更新为 1,然后在更新数据库前,请求 B 将缓存的数据更新为 2,紧接着也把数据库更新为 2,然后请求 A 将数据库的数据更新为 1。
此时,数据库中的数据是 1,而缓存中的数据却是 2,出现了缓存和数据库中的数据不一致的现象。
所以,无论是「先更新数据库,再更新缓存」,还是「先更新缓存,再更新数据库」,这两个方案都存在并发问题,当两个请求并发更新同一条数据的时候,可能会出现缓存和数据库中的数据不一致的现象。
先更新数据库,还是先删除缓存?
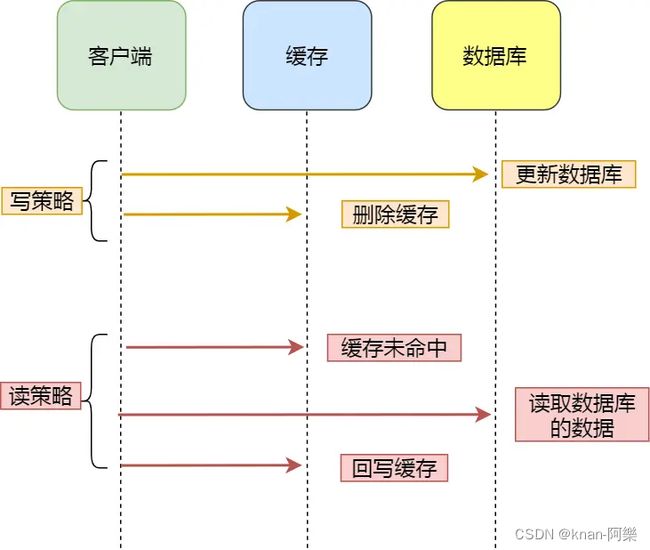
更新数据时,不更新缓存,而是删除缓存中的数据。然后,等到后续读取数据时,发现缓存中没有数据,再从数据库中读取数据,更新到缓存中。
这种策略即旁路缓存策略(Cache Aside),该策略又可以细分为「读策略」和「写策略」。
先删除缓存,再更新数据库
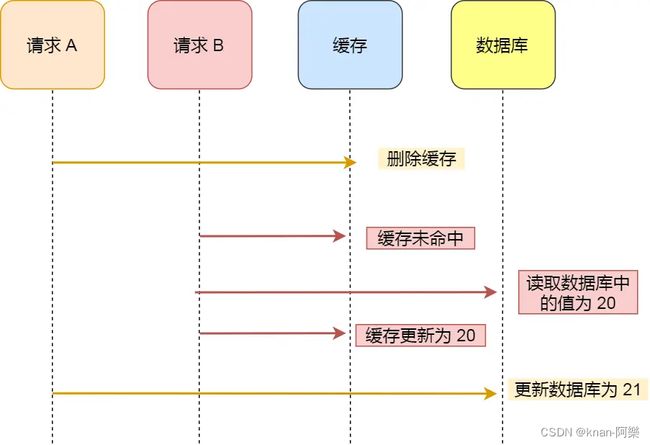
可以看到,先删除缓存,再更新数据库,在「读 + 写」并发的时候,还是会出现缓存和数据库的数据不一致的问题。
先更新数据库,再删除缓存

从理论上分析,先更新数据库,再删除缓存,也是会出现数据不一致的问题,但是在实际中,这个问题出现的概率并不高。
因为「缓存的写入通常要远远快于数据库的写入」,所以在实际中很难出现请求 B 已经更新了数据库并且删除了缓存,请求 A 才更新完缓存的情况。
而一旦请求 A 早于请求 B 删除缓存之前更新了缓存,那么后续的请求 C 就会因为缓存被删除而从数据库中重新读取数据,所以不会出现不一致的情况。
所以,「先更新数据库 + 再删除缓存」的方案,是可以保证数据一致性的。
为了确保万无一失,还可以给缓存数据加上「过期时间」,就算在这期间存在缓存数据不一致,有过期时间来兜底,这样也能达到最终一致。
优化
「先更新数据库,再删除缓存」的方案虽然保证了数据库与缓存的数据一致性,但是每次更新数据的时候,缓存的数据都会被删除,这样会对缓存的命中率带来影响。
所以,如果业务对缓存命中率有很高的要求,可以采用「更新数据库 + 更新缓存」的方案,因为更新缓存并不会出现缓存未命中的情况。
但是在两个更新请求并发执行的时候,会出现数据不一致的问题,因为更新数据库和更新缓存这两个操作是独立的,而程序又没有对操作做任何并发控制,那么当两个线程并发更新它们的话,就会因为写入顺序的不同,造成数据的不一致。
所以得增加一些手段来解决这个问题,这里提供两种做法。
- 在更新缓存前先加个分布式锁,保证同一时间只运行一个请求更新缓存,就不会产生并发问题了,当然引入了锁后,对于写入性能就会带来影响
- 在更新完缓存时,给缓存加上较短的过期时间,这样即使出现缓存不一致的情况,缓存的数据也会很快过期,对业务而言还是能接受的
针对「先删除缓存,再更新数据库」的方案,在「读 + 写」并发请求造成缓存不一致的解决办法是「延迟双删」。
# 删除缓存
redis.delKey(X)
# 更新数据库
db.update(X)
# 睡眠
Thread.sleep(N)
# 再删除缓存
redis.delKey(X)
通过加入睡眠时间,确保请求 A 在睡眠的时候,请求 B 能够在这一段时间内完成「从数据库读取数据,再把缺失的缓存写入缓存」的操作,然后请求 A 睡眠完毕,再删除缓存。
所以,请求 A 的睡眠时间就需要大于请求 B 「从数据库读取数据 + 写入缓存」的时间。
具体睡眠多久很难评估,所以这个方案也只是尽可能保证一致性。在极端情况下,依然也会出现缓存不一致的现象。
因此,还是建议用「先更新数据库,再删除缓存」的方案。
此外,「先更新数据库,再删除缓存」的方案,由于是两个操作,前面的所有分析都是建立在这两个操作都能同时执行成功的前提下。而极端情况下有可能出现,在删除缓存(第二个操作)的时候失败了,导致缓存中的数据是旧值,而数据库是新值,造成数据库和缓存数据不一致的问题,会对敏感业务造成影响。
- 重试机制
可以引入消息队列,将第二个操作(删除缓存)要操作的数据加入到消息队列,由消费者来操作数据。
如果删除缓存失败,可以从消息队列中重新读取数据,然后再次删除缓存,即重试机制。如果重试次数超过阈值,就需要向业务层发送告警信息。
如果删除缓存成功,就要把数据从消息队列中移除,避免重复操作,否则就继续重试。
- 订阅 MySQL binlog,再操作缓存
「先更新数据库,再删除缓存」的方案,第一步是先更新数据库,那么更新数据库成功,就会产生一条变更日志,记录在 binlog 里。
于是就可以通过订阅 binlog 日志,拿到具体要操作的数据,然后再执行缓存删除,阿里巴巴开源的 Canal 中间件就是基于这个实现的。
Canal 模拟 MySQL 主从复制的交互协议,把自己伪装成一个 MySQL 的从节点,向 MySQL 主节点发送 dump 请求,MySQL 主节点收到请求后,就会开始推送 binlog 给 Canal,Canal 解析 binlog 字节流后,转换为便于读取的结构化数据,供下游程序订阅使用。
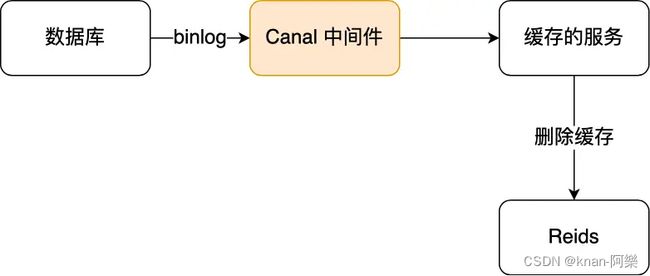
所以,如果要想保证「先更新数据库,再删除缓存」的第二个操作能执行成功,可以使用「消息队列来重试缓存的删除」,或者「订阅 MySQL binlog 再操作缓存」,这两种方法有一个共同的特点,都是采用异步操作缓存。
为什么是删除缓存,而不是更新缓存呢?
因为删除一个数据,比更新一个数据更加轻量级,出现问题的概率更小。
在实际业务中,缓存的数据可能不是直接来自于数据库表,也许是来自于多张底层数据表的聚合组装。从计算资源和整体性能的考虑,更新的时候删除缓存,等到下次查询命中再填充缓存,是一个更好的方案。
系统设计中有一个思想叫 Lazy Loading,适用于那些加载代价大的操作,删除缓存而不是更新缓存,就是懒加载思想的一个应用。
参考资料
- https://xiaolincoding.com/redis/architecture/mysql_redis_consistency.html#%E6%95%B0%E6%8D%AE%E5%BA%93%E5%92%8C%E7%BC%93%E5%AD%98%E5%A6%82%E4%BD%95%E4%BF%9D%E8%AF%81%E4%B8%80%E8%87%B4%E6%80%A7