Python爬虫——Ajax数据爬取
前言
有时候我们在用requests抓取页面的时候,得到的结果可能和在浏览器中看到的不一样,在浏览器中可以看到正常显示的页面数据,但使用requests得到的结果并没有。这是因为在requests获得的都是原始的HTML文档,而浏览器中的页面则是经过JavaScript处理数据后生成的结果,这些数据的来源有很多种,可能是通过Ajax加载的,可能是包含在HTML文档中的,也可能是经过JavaScript和特定的算法计算后生成的。
本文将讲解什么是Ajax以及如何分析和抓取Ajax请求。
Ajax
Ajax即异步的JavaScript和XML,它不是一门编程语言,而是利用JavaScript在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。
对于前言的第一种情况,数据加载是一种异步加载方式,原始的页面最初不会包含某些数据,原始页面加载完后,会再向服务器请求某个接口获得数据,然后数据才被处理从而呈现到网页上,这其实就是发送了一个Ajax请求。
对于传统的网页,如果想更新其内容,那么必须要刷新整个页面,但有了Ajax,便可在页面不被全部刷新的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行了数据交换,获取到数据之后,再利用JavaScript改变网页,这样网页内容就会更新了。
Ajax应用场景
浏览网页的时候,我们会发现很多网页都有下滑查看更多的选项。
例如进入微博(https://weibo.com/),下滑几个微博之后,再向下就没有了,转而会出现一个加载动画的,不一会就会刷线新的微博内容,整个过程其实就是Ajax加载的过程。
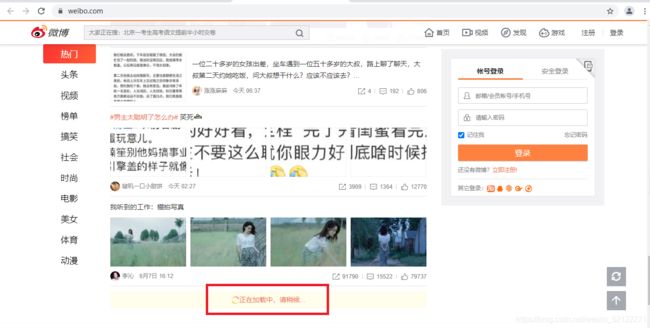
我们注意到页面其实并没有整个刷新,也就意味着页面的链接没有变化,但是网页中却多了新内容,也就是后面刷出来的新微博。这就是通过Ajax获取新数据并呈现出来的过程。
Ajax分析方法
我们知道真实的数据其实都是一次次Ajax请求得到的,如果想要抓取这些数据,需要知道这些请求到底是怎么发送的,发往哪里,发了哪些参数,如果我们知道了这些,不就可以用python模拟这个发送操作,获取到其中的结果了吗?
查看请求
我们知道拖动刷新的内容由Ajax加载,而且页面的URL没有变化,那么应该到哪里去查看这些Ajax请求呢?这里以知乎-发现(https://www.zhihu.com/special/all)为例,借助Chrome浏览器的开发者工具来介绍。
首先,用Chrome浏览器打开知乎-发现(https://www.zhihu.com/special/all),随后在页面中右击鼠标,从弹出的快捷菜单中选择“检测”选择,此时便会弹出开发者工具。如下图:
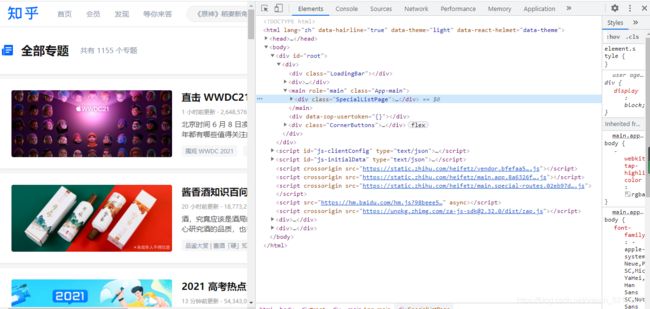
此时在Elements选项卡中便会观察到网页的源代码,但这不是我们想要寻找的内容。切换到Network选项卡,随后重新刷新页面,可以发现这里出现了非常多的条目,如下图:
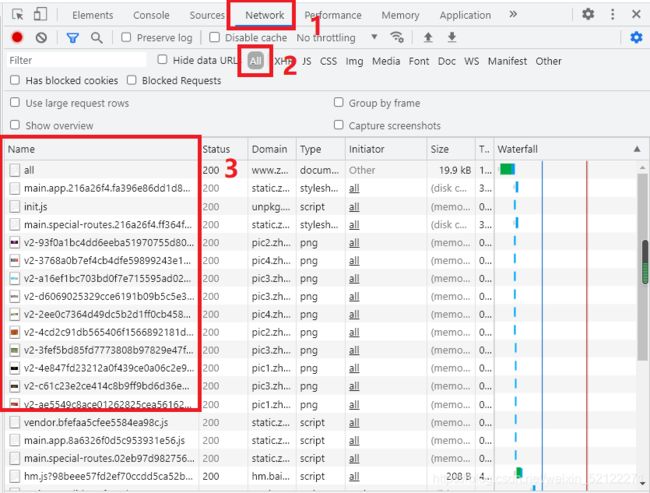
Ajax其实有其特殊的请求类型,它叫作xhr。我们发现有个名称list?limit=10&offset=20的请求,这就是一个Ajax请求,用鼠标点击这个请求,可以查看到这个请求的详细信息。
右侧可以观察到其Request Headers、URL和Respouse Headers等信息。其中Request Headers中有一个信息为X-Requested-with:fetch,这个就是标记了此请求是Ajax请求。
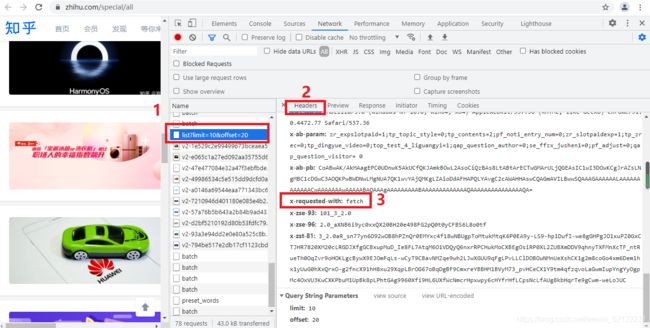
随后点击一下Preview,即可看到响应的内容,它是JSON格式的。观察可以发现,这里返回结果是专题的信息,如:标题、点击量和介绍等,这也是用来渲染个人主页所使用的数据。JavaScript接收到这些数据之后,再执行相应的渲染方法,整个页面就渲染出来了。如下图:
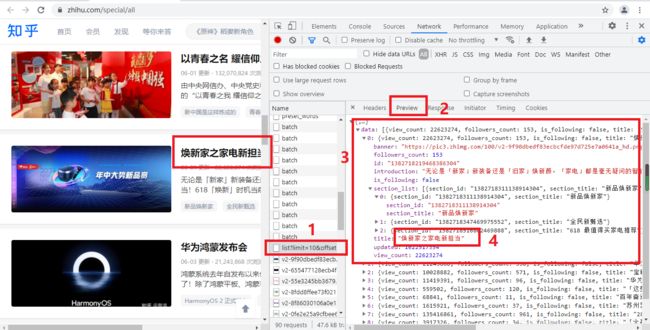
另外,也可以切换到Respouse选项卡,从中观察到真实的返回数据,如下图:

接下来,切回到第一个请求,观察一下它的Respouse是什么,如下图:
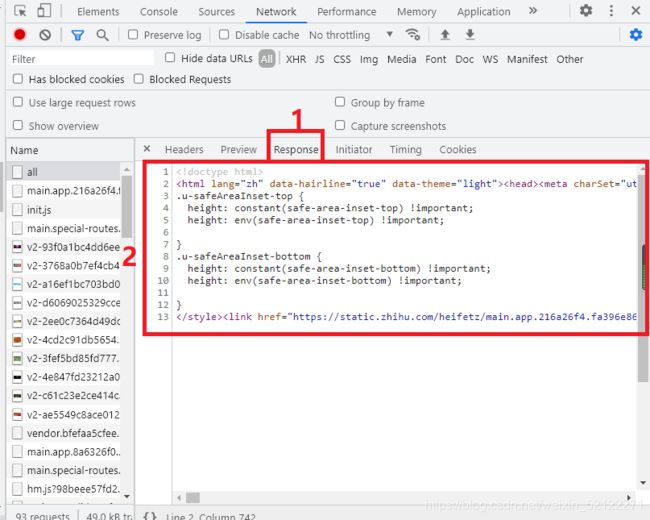
这是最原始的链接(https://www.zhihu.com/special/all)返回的结果,其代码只有不到20行,结构也非常简单,只是执行了一些JavaScript。
所以我们看到的知乎-发现的真实数据并不是最原始的页面返回的,而是后来执行JavaScript后再次向后台发送了Ajax请求,浏览器拿到数据后再进一步渲染出来的。
过滤请求
使用Chrome开发者工具筛选功能筛选出所有的Ajax请求。如下图:
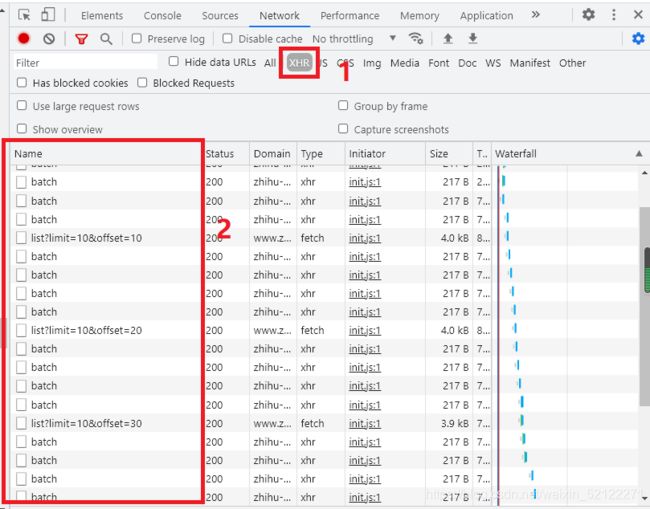
不断滑动页面,可以看到页面底部有一条条新的专题被刷新出,而开发者工具下方也一个个地出现Ajax请求,这样我们就可以捕获到所有的Ajax请求了。
随意点开一条目,都可以清楚地看到其Request URL、Request Headers、Respouse Headers、Respouse Body等内容,此时想要模拟请求和提取就非常简单了。如下图:

Ajax结果提取
接下来用Python来模拟这些Ajax请求,把知乎-发现-全部专题的部分内容爬取下来。
分析请求
打开Ajax的XHR过滤器,然后一直滑动页面以加载新的专题内容,可以看到,会不断有Ajax请求发出。
选定其中一个请求,分析它的参数信息。点击该请求,进入详情页面,如下图:
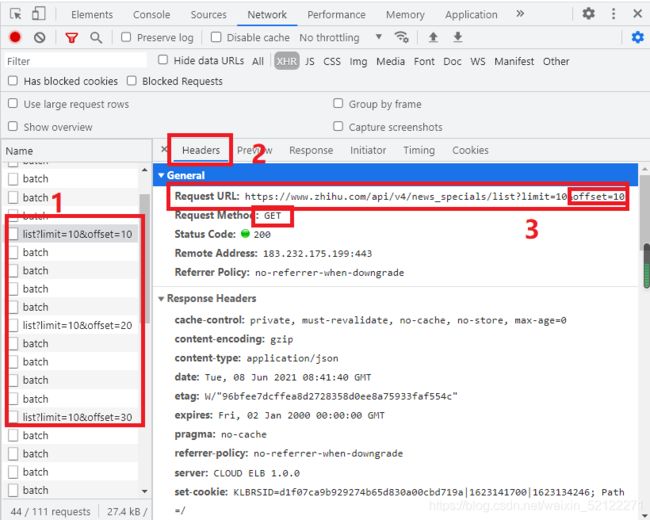
可以发现,这是一个GET类型的请求,请求链接为:https://www.zhihu.com/api/v4/news_specials/list?limit=10&offset=10,请求的参数有2个:limit和offset。看看其他请求,可以发现,它们的limit没有改变,改变的值就是offset,很明显这个参数就是用来控制分页的,offset=1代表第一页,offset=2代表第二页,以此类推。
分析响应
观察这个请求的响应内容,如下图:
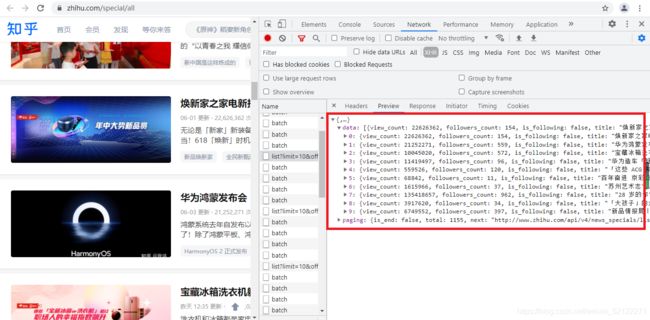
这个内容是JSON格式的,浏览器开发者工具自动做了解析以方便我们查看,最关键的两部分信息就是data和paging:前者是一个列表,包含10个元素,展开其中一个看一下。后者包含一个比较重要的信息total,它是专题的总个数,我们可以根据这个数字来估算分页数。如下图:
可以发现,它包含了知乎-发现-全部专题的一些信息,例如:banner(图片链接),id(发帖者id)、introdunction(简介)、title(标题)、updated(更新时间)、view_count(点击量)等,而且它们都是一些格式化的内容。
这样我们请求一个接口,这样就可以得到10个专题,而且请求时只需要改变offset参数即可。
这样的话,我们只需要简单一个循环,就可以获得所有专题了。
实战演练
这里我们用程序模拟这些Ajax请求,将全部专题爬取下来。
爬取首页信息数据
首先,定义一个方法来获取每次请求的结果,在请求时,offset是一个可变参数,所以我们将它作为方法的参数传递进来,相关代码如下:
from urllib.parse import urlencode
import requests
base_url='https://www.zhihu.com/api/v4/news_specials/list?'
headers={
'Host':'www.zhihu.com',
'Referer':'https://www.zhihu.com/special/all',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36',
'X-Requested-With':'fetch'
}
#获取网页的响应并返回json格式的数据
def get_offset(offset):
params={
'limit':'10',
'offset':offset
}
url=base_url+urlencode(params)
try:
response=requests.get(url,headers=headers)
if response.status_code==200:
return response.json()
except requests.ConnectionError as e:
print('Error',e.args)这里定义了base_url来表示请求的URL的前半部分。接下来,构造参数字典,其中limit是固定参数,page是可变参数,再调用urlencode()方法将参数转化为URL的GET请求参数,随后base_url与参数拼合形成一个新的URL。接着,我们用requests请求这个链接,加入headers参数。当响应码为200,则调用json()方法将内容解析为JSON返回,否则不返回任何信息。如果出现异常,则捕获并输出其异常信息。
提取我们需要的数据
首先定义一个解析方法,用来从结果中提取想要的信息,例如想保存全部专题中的图片链接,id、点击量和标题这几个内容。先遍历data,然后获取里面的各个信息并赋值为一个新的字典返回即可:
from pyquery import PyQuery as pq
def parse_page(json):
if json:
items=json.get('data')
for item in items:
zhihu={}
zhihu['banner']=item.get('banner')
zhihu['id']=item.get('id')
zhihu['view_count']=item.get('view_count')
zhihu['title']=pq(item.get('title')).text()
yield zhihu使用了pyquery库将正文中的HTML标签去掉。
遍历offset将输出打印:
if __name__=='__main__':
for offset in range(1,110):
json=get_offset(offset)
results=parse_page(json)
for result in results:
print(result)这样,我们就顺利通过分析Ajax并编写爬虫爬取下来知乎-发现-全部专题的部分内容了。
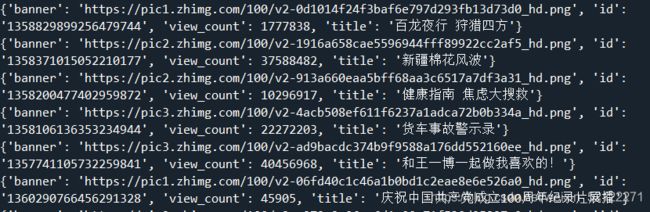
部分数据展示:
最后
本文的目的是为了演示Ajax的模拟请求的过程,爬取结果不是重点,该程序仍有很多可以完善的地方,大家觉得哪里可以改正完善的地方,可以在评论区或者私信我,我们一起讨论讨论。
好了,Python爬虫——Ajax数据爬取的知识讲解到这来了,感谢观看!!!