深度学习(四十七)——Flow-based Model, Diffusion Model, Autoregressive Model
Flow-based Model

Flow-based Model是GAN和VAE之外的另一大类生成模型方法。
从表面来看,Flow-based Model和VAE非常类似,无非把Encoder和Decoder换成了Flow和它的Inverse,但是实际上两者不仅数学原理不同,具体的训练方法也有极大差异。上图说是照骗也不为过。
以下内容主要参考了李宏毅老师的课件:
http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2019/Lecture/FLOW%20(v7).pdf
还有以下笔记:
http://www.seeprettyface.com/pdf/Note_Flow.pdf

Flow-based Model的训练过程是用图片x通过网络 f ( x ) f(x) f(x)生成随机数z。由于这个经过巧妙构造的 f ( x ) f(x) f(x)具有可直接得到的可逆函数 f − 1 ( z ) f^{-1}(z) f−1(z),所以在推理阶段,无需任何额外处理,即可直接由 f − 1 ( z ) f^{-1}(z) f−1(z),从随机数z得到图片x。
随机数z可以是任意分布,但通常为了理论推导的简单,而使用正态分布,即所谓的Normalizing Flow。
Flow-based Model的理论不算复杂,难点主要在于如何构造可逆的函数G。目前已经有了一些成熟的构造方法,但相对于网络结构的千变万化,构造方法的种类就少的太多了。主流的大概也就是NICE、RealNVP和GLOW。
最初的NICE实现了从A分布到高斯分布的可逆求解;后来RealNVP实现了从A分布到条件非高斯分布的可逆求解;而最新的GLOW,实现了从A分布到B分布的可逆求解,其中B分布可以是与A分布同样复杂的分布,这意味着给定两堆图片,GLOW能够实现这两堆图片间的任意转换。
我们以NICE为例,介绍一下Flow-based Model的基本套路。
首先, G − 1 G^{-1} G−1必须是存在的且能被算出,这意味着G的输入和输出的维度必须是一致的并且G的行列式不能为0。因此,z和x的形状必须完全一致。
作为一个生成模型自然希望自己产生的数据的概率越高越好。因此这里的优化目标就是:
G ∗ = arg max G ∑ i = 1 m log p G ( x i ) G^*=\arg \max_{G} \sum_{i=1}^m\log p_{G}(x^i) G∗=argGmaxi=1∑mlogpG(xi)
这里不加证明的给出结论:
log p G ( x i ) = log π ( G − 1 ( x i ) ) + log ∣ d e t ( J G − 1 ) ∣ \log p_{G}(x^i)=\log \pi(G^{-1}(x^i))+\log |det(J_{G^{-1}})| logpG(xi)=logπ(G−1(xi))+log∣det(JG−1)∣
这里的第一项实际上就是 log π ( z i ) \log \pi(z^i) logπ(zi)。显然,当z为0时,正态分布的概率最大。
然而这会导致 d e t ( J G − 1 ) = 0 det(J_{G^{-1}})=0 det(JG−1)=0,也就是第二项为 − ∞ -\infty −∞。
所以z必须在两项之间平衡,才能得到最大值。这个平衡点就是我们的优化目标。
NICE采用了一种称为耦合层(Coupling Layer)的设计,如下图所示:

z和x都会被拆分成两个部分,分别是前1 ~ d维和后d+1 ~ D维。
z的1 ~ d维直接复制(copy)给x的1 ~ d维;z的d+1 ~ D维分别通过F和H两个神经网络,通过仿射计算(affine)传递给x。
由于F和H的结果仅仅是系数,所以对于从 G − 1 G^{-1} G−1构建G,也就是计算 d e t ( J G − 1 ) det(J_{G^{-1}}) det(JG−1)没有什么影响。

如果一层变换的表现力不足的话,我们也可以多做几层变换。需要注意的是,z的1 ~ d维直接复制(copy)给x的1 ~ d维的方式中的copy操作,对于生成模型的表现力会有影响。(总不可能生成图片的一部分还是随机噪声吧。)所以多层变换的话,需要使用交错的方式,组合copy操作和affine操作。

Masked Autoregressive Flow
Inverse Autoregressive Flow
参考:
https://zhuanlan.zhihu.com/p/44304684
Normalizing Flow小结
https://www.jianshu.com/p/66393cebe8ba
标准化流(Normalizing Flow)教程(一)
https://www.jianshu.com/p/db72c38233f3
标准化流(Normalizing Flow)(二):现代标准化流技术
https://mp.weixin.qq.com/s/oUQuHvy0lYco4HsocqvH3Q
Normalizing Flows入门(上)
https://mp.weixin.qq.com/s/XtlK3m-EHgFRKrtcwJHZCw
Normalizing Flows入门(中)
https://mp.weixin.qq.com/s/TRgTFBz_NmBJygQjOYwdqw
GAN/VAE地位难保?Flow在零样本识别任务上大显身手
https://mp.weixin.qq.com/s/xMO9jhzQH6P5NEA_D-uyIA
这个模型的脑补能力比GAN更强,ETH提出新型超分辨率模型SRFlow
https://zhuanlan.zhihu.com/p/351479696
基于流的生成模型-Flow based generative models
https://mp.weixin.qq.com/s/KrvW16GAxSGAPOCYYKbGUg
生成模型:标准化流(Normalized Flow)
https://lilianweng.github.io/posts/2018-10-13-flow-models/
Flow-based Deep Generative Models
Diffusion Model
Diffusion Model也是一类生成模型方法。
Diffusion Model主要通过采样的方法,不断逼近模型的数据分布,从而生成数据。基本原理和VAE一样仍然是Markov Chain Monte Carlo。
以下以Stable Diffusion模型为例,介绍一下Diffusion Model的套路。

我们首先来看一下Stable Diffusion的流水线:
1.输入是一段文字,或者是一段文字+一张背景图片,输出是一张生成的图片。
2.Text Encoder用于NLP。
3.Image Decoder用于生成图片。
4.上述这些部分都是很常规的,中间的Image Information Creator才是Stable Diffusion的关键。

如上图所示,Image Information Creator的输入是一个随机的噪声,而输出是一个information tensor。无论是噪声,还是information tensor都属于Information World,而最后生成的图片属于Visual World。
早期的原始Diffusion Model并没有这种World的划分,而是直接由噪声得到图片,所以很不Stable。
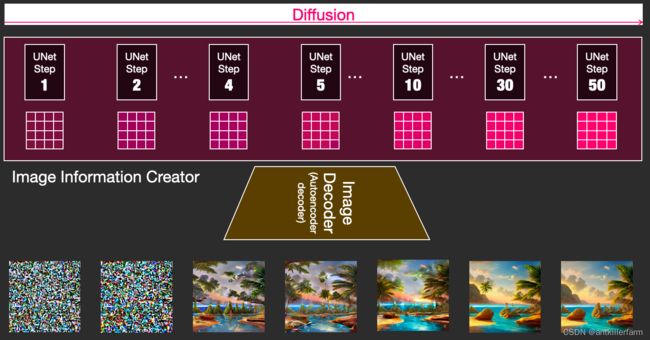
从上图可以看出:Diffusion Model由于天生就是渐变的迭代过程,因此在流程的可控性上很有优势。
当时间宽裕时可以通过高轮次的迭代获得高质量的合成样本,同时较低轮次的快速合成也可以得到没有明显瑕疵的合成样本。(仍以上图为例,实际上Step 4的图片就已经相当OK了。)而高低轮次迭代之间完全不需要重新训练模型,只用手动调整一些轮次相关的参数。
因此,很自然的又有了Cascaded Diffusion Models。
论文:
《Cascaded Diffusion Models for High Fidelity Image Generation》
回到Stable Diffusion本身,我们先看一下没有两种World划分的Diffusion Model是怎么训练的。

首先我们生成一堆的随机噪声,然后随机选择其中一种噪声,添加到图片上。这样就得到了一组数据集:
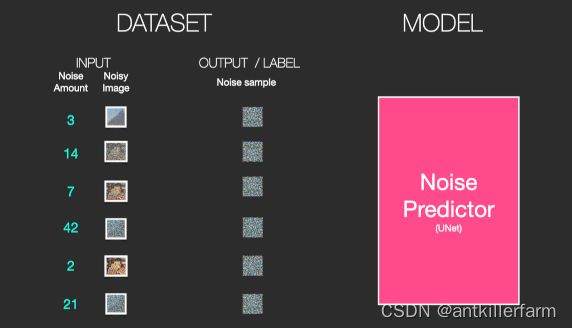
我们的目标就是训练一个噪声预测模型。

用预测的噪声和原始生成的噪声做对比,计算loss。

推理的时候,首先生成一组噪声图片,放入Noise Predictor,生成预测的噪声。然后用噪声图片-预测的噪声就得到了生成的图片。这个去噪过程,也可以进行多个Step。显然Step越多,图片质量越高。
使用两种World划分的Stable Diffusion,还要再复杂一些,但也不多了。
Image Decoder部分使用传统的AutoEncoder进行训练。
这样Diffusion过程就可以在Information World中进行了。

参考:
https://jalammar.github.io/illustrated-stable-diffusion/
The Illustrated Stable Diffusion
https://lilianweng.github.io/lil-log/2021/07/11/diffusion-models.html
What are Diffusion Models?
https://zhuanlan.zhihu.com/p/366004028
另辟蹊径—Denoising Diffusion Probabilistic一种从噪音中剥离出图像/音频的模型
https://zhuanlan.zhihu.com/p/384144179
Denoising Diffusion Probabilistic Model(DDPM)
https://zhuanlan.zhihu.com/p/377603135
Diffusion Probabilistic Model
https://yang-song.github.io/blog/2021/score/
Generative Modeling by Estimating Gradients of the Data Distribution
https://www.zhihu.com/question/536012286
diffusion model最近在图像生成领域大红大紫,如何看待它的风头开始超过GAN?
https://www.zhihu.com/question/558475081
AI绘画过去也一直有研究,为什么会在最近几个月突然爆发?
https://mp.weixin.qq.com/s/G50p0SDQLSghTnMAOK6BMA
Diffusion Model
https://zhuanlan.zhihu.com/p/549623622
Diffusion Models:生成扩散模型
Autoregressive Model
自回归模型,是统计上一种处理时间序列的方法,用同一变数例如x的之前各期,亦即 x 1 x_1 x1至 x t − 1 x_{t-1} xt−1来预测本期 x t x_t xt的表现,并假设它们为一线性关系。因为这是从回归分析中的线性回归发展而来,只是不用x预测y,而是用x预测x自己,所以叫做自回归。
AR: Autoregressive Lanuage Modeling,又叫自回归语言模型。它指的是,依据前面(或后面)出现的tokens来预测当前时刻的token,代表模型有ELMO、GTP等。
forward: p ( x ) = ∏ t = 1 T p ( x t ∣ x < t ) \text{forward:}p(x)=\prod_{t=1}^Tp(x_t|x_{
backward: p ( x ) = ∏ t = T 1 p ( x t ∣ x > t ) \text{backward:}p(x)=\prod_{t=T}^1p(x_t|x_{>t}) backward:p(x)=t=T∏1p(xt∣x>t)
-
缺点:它只能利用单向语义而不能同时利用上下文信息。ELMO通过双向都做AR模型,然后进行拼接,但从结果来看,效果并不是太好。
-
优点:对自然语言生成任务(NLG)友好,天然符合生成式任务的生成过程。这也是为什么GPT能够编故事的原因。
AE:Autoencoding Language Modeling,又叫自编码语言模型。通过上下文信息来预测当前被mask的token,代表有BERT,Word2Vec(CBOW)。
p ( x ) = ∏ x ∈ M a s k p ( x t ∣ c o n t e x t ) p(x)=\prod_{x\in Mask}p(x_t|context) p(x)=x∈Mask∏p(xt∣context)
-
缺点:由于训练中采用了MASK标记,导致预训练与微调阶段不一致的问题。此外对于生成式问题,AE模型也显得捉襟见肘,这也是目前BERT为数不多没有实现大的突破的领域。
-
优点:能够很好的编码上下文语义信息,在自然语言理解(NLU)相关的下游任务上表现突出。
Autoregressive Model实际上是最古老的生成模型,比GAN/VAE/Flow/Diffusion都要古老。

这里以PixelCNN为例介绍一下AR Model的原理。

PixelCNN简单来说就是按照从左到右,从上到下的顺序依次生成图片。表面上和Diffusion Model差不多,也是若干step的生成过程。
但是有个问题就是中间步骤不能省略。比如一张28x28的图片,如果一次出1个点的话,一共就要28x28个step。少了其中的某一步,图片就不完整了。而且显然一次出1个点的模型一定和一次出2个点的模型是不一样的。
但Diffusion Model就无所谓了,少了某一步,无非少了一种Noise Predictor而已,不会对结果有什么根本性的影响。
PixelCNN训练和过程和Autoencoder差不多,也是最终生成的图片和训练图片做比较。但是为了表示没有偷看后面的数据,训练时需要用MASK遮住还未生成的那部分。
此外,PixelCNN还要给图片打分,用以表明生成的图片是那一类的。比如MNIST数据集的手写数字的10分类。
这样最终训练好之后,只要给出分类信息和seed,就可以生成图片了。
参考:
https://zhuanlan.zhihu.com/p/591881660
通俗形象地分析比较生成模型(GAN/VAE/Flow/Diffusion/AR)
https://mp.weixin.qq.com/s/YZcw5pnHzuACSvEmGZHnEQ
自回归模型:PixelCNN
https://www.microsoft.com/en-us/research/uploads/prod/2022/12/Generative-Models-for-TTS.pdf
Generative Models for TTS