【Linux】常用工具(下)
Linux常用工具
- 一、Linux 项目自动化构建工具 - make/Makefile
-
- 1. 依赖关系和依赖方法
- 2. 伪目标
- 3. make/Makefile 具有依赖性的推导能力(语法扩展)
- 4. 编写一个进度条代码
-
- (1)缓冲区
- (2)\n 和 \r
- (3)进度条代码
- 二、Linux 版本控制器 - git
-
- 1. git clone
- 2. git config
- 3. git add
- 4. git commit
- 5. git push
- 6. git pull
- 三、Linux 调试器 - gdb
-
- 1. 查看指令
- 2. 断点
- 3. 开始调试
- 4. 其他指令
- 5. 总结
一、Linux 项目自动化构建工具 - make/Makefile
一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile 定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作。
在 windows 操作系统中,比如 vs2019 这款编译器,有了图形化界面,我们可以直接一键生成解决方案,即编译;但在 Linux 系统中,需要我们使用 gcc 或 g++ 手动进行编译工作,当我们需要编译的文件多起来时,就降低了我们的工作效率。
所以,我们接下来学习一个工具 make 和 Makefile
- Makefile 带来的好处就是 ——“自动化编译”,一旦写好,只需要一个 make 命令,整个工程完全自动编译,极大的提高了软件开发的效率;
- make是一个命令工具,是一个解释 Makefile 中指令的命令工具,一般来说,大多数的 IDE 都有这个命令。
1. 依赖关系和依赖方法
我们先简单看一看 make 和 Makefile 的使用;我们先 touch 一个 Makefile 文件和一个普通文件:

我们在 test.c 文件中随便写一些代码:

随后我们进入 Makefile 文件中写入依赖关系和依赖方法:

其中 mytest:test.c 表明 mytest 这个将要生成的可执行程序依赖于test.c 文件;而 gcc test.c -o mytest 则是相应依赖关系的依赖方法,即解决方法,即怎样才能让 test.c 得到 mytest.
.PHONY 是定义一个伪目标 clean,伪目标的特性是总是被执行的,这个特性我们稍后再介绍。
随后 clean: 表明 clean 没有依赖关系,其依赖方法是 rm -f mytest ,这一步即进行了项目的清理工作。
我们看使用,我们在命令行中执行 make,即进行了项目的编译工作:

随后我们执行这个程序观察:

可以看到是正常执行的;然后我们对这个项目进行清理工作:

这样就完成了项目的编译和清理工作;注意我们使用 make 的时候默认执行第一个依赖关系和方法,往后的需要我们自行指定;例如我们将上面的编译和清理的依赖关系和依赖方法反过来,如图:
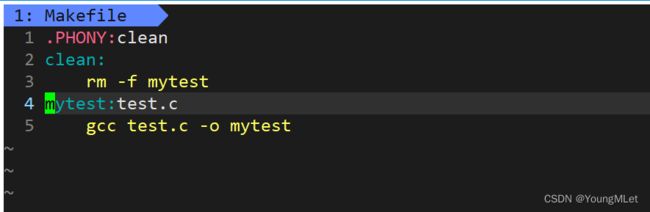
随后我们执行 make 观察结果:

可以看到默认是执行了第一个依赖关系,随后我们执行编译的依赖关系和方法:

这样也可以正常使用,但是我们通常使用的是第一种,即编译放在前面,清理放在最后。
2. 伪目标
我们上面所说的 .PHONY: 后面所跟的就是伪目标,一般我们这种 clean 的目标文件,我们将它设置为伪目标,用 .PHONY 修饰,伪目标的特性是:总是被执行的。
- (1)如何理解总是被执行呢?
首先我们尝试多次执行 make 观察:

我们观察到,只有在第一次执行 make 的时候,程序进行了编译,后面都没有进行编译;我们再对程序进行多次清理呢?我们观察结果:

我们可以观察到,执行 make clean 的时候每一次都进行了程序的清理,这就是应该如何理解总是被执行, 因为 clean 是伪目标,所以它总是被执行。
- (2)那么为什么不是伪目标就不能总是被执行呢?
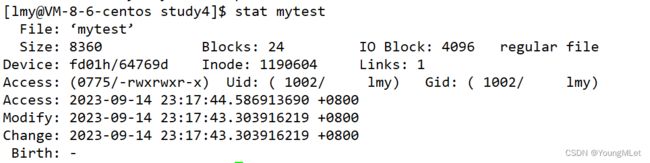
首先我们理解一下文件的 ACM 时间,stat + 文件名 可以查看文件的 ACM 时间,如下图:

其中,Access 时间是最近访问这个文件的时间;Modify 时间是最近修改这个文件内容的时间;Change 是最近修改这个文件属性的时间。
其实,Makefile 和 make 通过一个文件的内容修改时间不让我们重新重复编译我们的代码,因为我们的文件已经是最新了,没有必要再进行编译。
详细的解释如下:假设我们有一个源文件 test.c 和一个 Makefile 文件:

我们第一次编译的时候,一定是先有源文件(如上的 test.c),这时候还没有编译,一定没有我们的目标文件(mytest 文件),所以一定能编译成功,如下:

当我们出现了 mytest 文件,mytest 文件的修改时间 > test.c 文件的修改时间;

当我们第 n 次 编译的时候,如果我们没有对 test.c 进行修改,那么 mytest 文件的修改时间还是大于 test.c 文件的修改时间,此时编译不通过,如下图:

当我们对 test.c 文件进行修改,更新了它的修改时间,此时 test.c 的修改时间 > mytest 的修改时间,此时重新编译可以通过,如下:


- (3)Access 时间的特性
我们有以下现象,当我们第一次编译的时候:

当我们想单独查看 test.c,修改它的 Acess 时间,如下:

我们发现,它的 Access 时间并没有修改,这是为什么呢?
一般而言,一个文件被查看的频率是非常高的;我们所看到的文件,都在磁盘中存放,而文件 = 内容 + 属性,所以更改文件时间的本质其实是访问磁盘,而访问磁盘的效率是很低的,所以,Linux 为了提高效率,更改了 Access 时间访问间隔,或者添加了次数限制;所以如果我们想立即更新 Access 时间,可以直接 touch + 文件,如下:

3. make/Makefile 具有依赖性的推导能力(语法扩展)
make/Makefile 具有依赖性的推导能力,我们在 Makefile 文件中有如下代码,其实就是程序的编译过程:

编译之后如下:

可以看出就是我们编译程序的过程,我们执行观察一下:

但是并不推荐用这种方法编译,因为我们可以直接使用 gcc 直接形成可执行程序。
我们还有其他的语法扩展,如下:

其中 gcc -o $@ $^ 中,$@ 代表依赖关系中冒号左边的所有文件;$^ 代表依赖关系中冒号右边的所有文件;我们编译出来后会替换成以下:

4. 编写一个进度条代码
(1)缓冲区
我们看以下的代码:
1 #include
2 #include
3
4 int main()
5 {
6 printf("hello, world\n");
7 sleep(3);
8 return 0;
9 }
我们打印了 “hello, world”,随后换行,执行 sleep(3);,是让程序停下来三秒钟再继续往下执行,我们观察一下结果:
首先执行是这样的:

过了三秒钟后:

我们观察到,程序是过了三秒之后才重新显示出命令行。
我们再观察以下代码:
1 #include
2 #include
3
4 int main()
5 {
6 printf("hello, world");
7 sleep(3);
8 return 0;
9 }
上面的代码我们将第一段代码中的 \n 删除了,随后我们执行这段代码观察结果:
执行后:

过了三秒后:

我们观察到执行程序后屏幕上并没有打印出 hello, world,过了三秒后才打印出来;首先程序是从上往下执行的,printf 语句肯定是先执行了的,但是并没有先打印出来,这是为什么呢?下面我们引出一个概念- - -缓冲区。
其实上面的现象中,在程序执行 printf 后,printf 打印的内容被存放到缓冲区中,在 C/C++ 中,会针对标准输出,给我们提供默认的缓冲区,而在缓冲区没有被刷新之前,我们的内容就不会被输出。
而 \n 就是一种刷新的策略 - - - 行刷新。所以我们加了 \n 后缓冲区被刷新,随即便打印出内容。
而我们没有使用 \n 的时候缓冲区并没有被刷新,但是我们可以使用 fflush(stdout) 强制刷新缓冲区,从而打印出内容,例如:
1 #include
2 #include
3
4 int main()
5 {
6 printf("hello, world");
7 fflush(stdout);
8 sleep(3);
9 return 0;
10 }
输出结果:

三秒后:

我们可以看到,缓冲区的内容被强制刷新出来了。
(2)\n 和 \r
我们首先编写一个简单的倒计数程序,例如:
1 #include
2 #include
3
4 int main()
5 {
6 int cnt = 10;
7 while(cnt >= 0)
8 {
9 printf("%d\n", cnt);
10 cnt--;
11 sleep(1);
12 }
13
14 return 0;
15 }
观察结果:

但是这并不是我们想要的倒计时,我们是期望在同一行中显示出来,所以我们不应该用 \n,其实 \n 就是我们所说的回车,就是使光标换行并回到那一行的最初位置;这时候我们就应该使用 \r,\r 就仅仅让光标回到当前行的最初位置,我们对上面的代码修改,如下:
1 #include
2 #include
3
4 int main()
5 {
6 int cnt = 10;
7 while(cnt >= 0)
8 {
9 printf("%d\r", cnt);
10 fflush(stdout);
11 cnt--;
12 sleep(1);
13 }
14
15 return 0;
16 }
执行结果如下:


从上面的结果可看出,我们的倒计时虽然在同一行了,但是输出的格式还是有问题,因为默认 %d 是按照一个字符的形式打印的,我们是要按照两个字符打印,所以我们仅需将第9行修改即可,如下:
9 printf("%2d\r", cnt);
结果如下:


这时候就基本完成我们的倒计时了,但是倒计时到个位数的时候,前面空了一个字符,不太美观,这是因为 %2d 是默认右对齐,我们在前面加上负号,就是左对齐了,所以我们继续修改:
9 printf("%-2d\r", cnt);
结果如下:


到此我们的倒计数就完成了。
(3)进度条代码
- 简单版本:
首先我们在一个新目录下创建 Makefile 文件,和 ProgressBar 头文件,函数实现文件和主函数文件,如下:

我们先编辑 Makefile 文件,建立依赖关系和依赖方法:
1 ProgressBar:main.c ProgressBar.c
2 gcc -o $@ $^
3 .PHONY:clean
4 clean:
5 rm -f ProgressBar
随后创建主函数,主函数中只要调用我们的进度条函数即可,如下:
#include "ProgressBar.h"
int main()
{
ProgressBar_v1();
return 0;
}
然后我们进入函数的声明部分,声明需要用到的变量和函数:
1 #include
2 #include
3 #include
4
5 void ProgressBar_v1();
6 #define SIZE 101 //数组大小
7 #define MAX_RATE 100 //加载进度最大值
8 #define STYLE '#' //加载符号
9 #define STIME 1000*40 //时间
我们声明好所有变量后,进入函数的实现部分:
1 #include "ProgressBar.h"
2 const char *str = "|/-\\"; // 加载光标
3
4 void ProgressBar_v1()
5 {
6 // 当前进度
7 int rate = 0;
8 char bar[SIZE];
9 memset(bar, '\0', sizeof(bar));
10
11 // 加载光标的数组长度
12 int num = strlen(str);
13
14 // 当进度没有加载满
15 while(rate <= MAX_RATE)
16 {
17 printf("[%-100s][%d%%][%c]\r", bar, rate, str[rate % num]);
18 fflush(stdout);
19 usleep(STIME);
20 bar[rate++] = STYLE;
21 }
22 printf("\n");
23 }
其中我们在使用延时函数的时候使用了 usleep 函数,它与 sleep 相比就是,sleep 中以 s 为单位;usleep 中以 us 为单位。
下面我们 make 生成可执行程序,然后运行,观察结果:
![]()
加载完成后就是上图这样子。这是简单的实现了一个进度条的版本,下面我们进一步改进这个进度条。
- 进阶版本(实际应用)
在实际应用中我们的进度条一般都应用在下载软件中,下面我们就简单以下载一个软件为例,简单实现一下这个代码:
首先我们实现函数的实现部分:
// 不能一次将进度条打印完毕,否则无法平滑的和场景结合
// 该函数,应该根据rate,自动的打一次
void ProgressBar_v2(int rate)
{
// 设置为静态数组,每次进来不会清零
static char bar[SIZE] = {0};
// 加载光标的数组长度
int num = strlen(str);
// 当进度没有加载满
if(rate >= 0 && rate <= MAX_RATE)
{
printf("[%-100s][%d%%][%c]\r", bar, rate, str[rate % num]);
fflush(stdout);
bar[rate] = STYLE;
}
}
我们再看声明部分,其中,我们增加了下载目标的大小和每次的下载速度:
1 #include
2 #include
3 #include
4
5 void ProgressBar_v1();
6 void ProgressBar_v2(int);
7 #define SIZE 101 //数组大小
8 #define MAX_RATE 100 //加载进度最大值
9 #define STYLE '#' //加载符号
10 #define STIME 1000*40 //时间
11
12 #define TARGET_RATE 1024*1024 //下载目标的大小 1MB
13 #define DSIZE 1024*10 //下载速度
最后看主函数部分:
1 #include "ProgressBar.h"
2
3 void download()
4 {
5 int target = TARGET_RATE;
6 int total = 0;
7 while(total < target)
8 {
9 // 用简单的休眠时间,模拟本轮下载花费的时间
10 usleep(STIME);
11
12 // 每次加上下载速度
13 total += DSIZE;
14
15 // 按百分比传入 v2 函数
16 int rate = total*100/target;
17 ProgressBar_v2(rate);
18 }
19 printf("\n");
20 }
21
22 int main()
23 {
24 // 下载的软件
25 download();
26 return 0;
27 }
这就是简单的一个实际应用的进度条代码;其中主函数部分我们还可以使用回调函数进行优化,如下:
我们先在函数声明处加上函数指针的声明:
typedef void (*callback_t)(int); // 函数指针
随后修改主函数部分:
1 #include "ProgressBar.h"
2
3 void download(callback_t cb)
4 {
5 int target = TARGET_RATE;
6 int total = 0;
7 while(total < target)
8 {
9 // 用简单的休眠时间,模拟本轮下载花费的时间
10 usleep(STIME);
11
12 // 每次加上下载速度
13 total += DSIZE;
14
15 int rate = total*100/target;
16 cb(rate); // 回调函数
17 }
18 printf("\n");
19 }
以上的进度条运行结果都如下图所示:
![]()
二、Linux 版本控制器 - git
所谓的版本控制器,简单地说,就是将被管理的内容(文本)或者程序,按照变化来进行管理的软件;最终达到的目标是,我们想要哪一个版本的文本或者程序,都可以为我们提供。
我们常用的 gitee / github 都是基于 git,软件搭建的网站,目的是让版本可视化。
如果我们的 Linux 中没有安装 git,可以执行 sudo yum install -y git 进行安装。
1. git clone
我们使用 git 主要是将自己的代码存放到远程仓库中,这里我们以 gitee 为远程仓库,在Linux中上传自己的代码;首先我们要在gitee中创建一个仓库,如下:
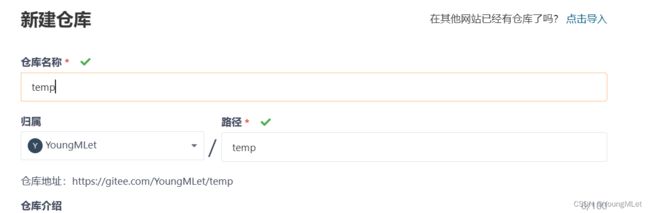
随后我们将仓库的地址复制,在Linux中运行以下命令:
git clone https://gitee.com/YoungMLet/temp
如下:
![]()
随即需要我们输入邮箱地址以及用户名,所以我们下面介绍一下如何配置邮箱地址和用户名。
2. git config
我们可以使用命令 git config 配置我们的邮箱地址和用户名,例如我们需要配置用户名:
git config --global user.name "xxx"
如果需要配置邮箱地址,可以执行以下命令:
git config --global user.email "[email protected]"
注意,这里的用户名和邮箱地址需要和远程仓库中的用户名和邮箱地址一致。
我们可以使用以下指令查看我们当前的配置信息:
git config -l
如果我们需要修改我们的邮箱地址和用户名,也是有办法的,首先我们先需要删除邮箱地址和用户名,删除用户名:
git config --global --unset user.name
删除邮箱地址:
git config --global --unset user.email
下面我们学习git 三板斧。
3. git add
首先我们先简单认识三个名词:工作区、暂存区、版本库。
工作区就是我们写代码的目录;暂存区就是我们使用 git add 后代码暂存的区域;版本库就是从暂存区提交后(即git commit)所在的区域。
当我们在工作区需要将我们的代码送到远程仓库时,首先先要将我们的代码 git add 到暂存区,此时我们需要执行 git add 命令,如下图:
![]()
仅需要执行这一句命令,就可以使工作区中的 study5 送到暂存区中,此时我们可以使用命令 git status 查看此时仓库的状态,如下:

说明已经 add 成功,此时需要将我们的代码提交到版本库中。
4. git commit
当我们的代码已经在暂存区后,我们需要将它提交到版本库中,此时就需要执行以下命令:
git commmit -m "这里写上日志"
注意这里必须加上 -m.
假设我们将上面所写的进度条提交到版本库中,如下:

我们还可以使用 git log 命令查看我们所提交的日志;当我们将代码提交到版本库后,我们此时还有最后一步就可以将我们的代码上传到远程仓库了。
5. git push
此时我们只需要执行以下命令即可将代码上传到远程仓库中:
git push
此时需要我们输入用户名和密码,我们输入即可:

此时就完成我们的代码上传到远程仓库了。
6. git pull
有些情况当我们多人协作写项目的时候,我们提交的代码和别人提交的代码可能会导致我们的本地仓库与远程仓库不同步,此时需要我们执行 git pull 即可同步。
三、Linux 调试器 - gdb
程序的发布方式有两种,debug 模式和 release 模式;Linux gcc/g++ 编译出来的二进制程序,默认是 release 模式;要使用 gdb 调试,必须在源代码生成二进制程序的时候, 加上 -g 选项;如下我们在编辑 Makefile 文件时,在建立依赖方法时需要给可执行程序加上 -g 选项:

此时我们退出 Makefile,执行 make,然后对 mytest 可执行文件执行 gdb mytest 即可进行调试,如下:

如上图,即进入了 gdb 调试模式,退出调试 q 或 quit,下面我们开始使用 gdb 进行调试;
1. 查看指令
在 gdb 中,list(简写 l )可以查看源代码;其中,l + number 可以查看从第 number 行代码;另外 gdb 会记录最近的历史命令,直接回车就是上一个命令;所以我们直接回车,会接着上次的位置往下列,每次列10行。例如查看我们的代码:

此时继续按回车:

查看我们完整的代码:

这就是查看指令。
2. 断点
打断点(Breakpoint)的指令是:b + number 或者 b + function,其中 number 为行号,function 为函数名,例如我们以上面的代码为例,在某一行打断点:

此时查看我们的打的断点指令是:info b,如下:

删除断点的指令是d + 序号,其中序号是查看断点中前面的那个 Num,例如我们先多打几个断点:

如上,每个断点前都有对应的序号,假设我们需要删除某一个断点:

3. 开始调试
开始调试的指令是:run 简写 r,如果有断点,程序遇到断点就会停下,否则程序会直接运行到结束。
在 vs 中,我们可以使用 F10 和 F11 进行逐过程和逐语句的调试,在gdb 中我们也可以使用这样的操作,其中逐过程是 n,即 vs 中的 F10;逐语句是 s,即 vs 中的 F11.
例如我们现在只有一个断点,我们使用逐过程和逐语句依次调试:

先 run 起来,程序会停在 16 行,此时我们按下 n:


此时我们遇到一个函数,按下 s 进行逐语句:

此时程序跳到函数的入口处,如果我们继续向往下走,继续 n 即可;假设我们想在调试中查看变量名和变量的地址,可以使用 display 指令,直接使用 display + 变量 即可,例如我们当前进入循环体内,想要查看当前 ret 的值 :

如果想查看 ret 的地址:

如果想要取消显示某个变量,可以使用 undisplay + 序号 即可,其中序号是 display 前面显示的序号,如下:

当前就取消了 &ret 的显示。
除此之外,我们还可以对断点进行开启和关闭,如下图,在 Enb 这一列中,y 表示当前断点是开启的:

如果我们想关闭这个断点,可以执行指令 disable + 序号,如下:

重新打开这个断点可以执行指令:enable + 序号:

4. 其他指令
当我们进入了一个循环体,但是这个循环次数非常多,我们想直接跳过这个循环,可以使用指令:until + 行号,运行至指定的位置;
还可以使用 finish,运行到当前函数的结尾;
我们还可以进行断点之间的运行,从一个断点直接运行到下一个断点,对应的指令:continue(简写c).
bt 可以查看堆栈;
set var 可以改变变量的值,例如 set var i = xxx;
5. 总结
我们使用的 gdb 指令都是以常见的为主,其他的请大家自主学习,下面我们总结一下我们的 gdb 指令:
查看代码:l + number
打断点:b + number
删断点:d + 序号
查看断点:info b
开始调试:r
禁止断点:disable + 序号
开启断点:enable + 序号
逐过程:n
逐语句:s
查看变量:display + 变量
取消查看变量:undisplay + 序号
运行至指定的位置:until + number
运行到当前函数的结尾:finish
从一个断点运行至下一个断点:c
查看调用堆栈:bt
更改变量的值:set var + 需改变量 = 改的值
退出gdb:q