Flink DataStream API使用(含实例)
本文主要通过代码练习熟悉Flink DataStream相关API的功能和使用。读者可完成简单的准备工作后跟着一起完成练习
准备
一台装有 Docker 的 Linux 或 MacOS 计算机。
使用 Docker Compose 启动容器
通过 wget 命令自动下载该 docker-compose.yml 文件,也可以手动下载
mkdir flink-service; cd flink-service;
wget https://gitee.com/WX_in_gitee/flink_learn/raw/master/note/docker-compose/flink-service/docker-compose.yml
启动容器:
docker-compose up -d
另外:停止容器的命令
docker-compose down
启动 Flink-Scala-Shell
docker-compose exec taskmanager ./bin/start-scala-shell.sh local
该命令会在容器中启动 Flink Shell 客户端。你应该能在 CLI 客户端中看到如下的环境界面。
Starting Flink Shell:
Starting local Flink cluster (host: localhost, port: 8081).
Connecting to Flink cluster (host: localhost, port: 8081).
▒▓██▓██▒
▓████▒▒█▓▒▓███▓▒
▓███▓░░ ▒▒▒▓██▒ ▒
░██▒ ▒▒▓▓█▓▓▒░ ▒████
██▒ ░▒▓███▒ ▒█▒█▒
░▓█ ███ ▓░▒██
▓█ ▒▒▒▒▒▓██▓░▒░▓▓█
█░ █ ▒▒░ ███▓▓█ ▒█▒▒▒
████░ ▒▓█▓ ██▒▒▒ ▓███▒
░▒█▓▓██ ▓█▒ ▓█▒▓██▓ ░█░
▓░▒▓████▒ ██ ▒█ █▓░▒█▒░▒█▒
███▓░██▓ ▓█ █ █▓ ▒▓█▓▓█▒
░██▓ ░█░ █ █▒ ▒█████▓▒ ██▓░▒
███░ ░ █░ ▓ ░█ █████▒░░ ░█░▓ ▓░
██▓█ ▒▒▓▒ ▓███████▓░ ▒█▒ ▒▓ ▓██▓
▒██▓ ▓█ █▓█ ░▒█████▓▓▒░ ██▒▒ █ ▒ ▓█▒
▓█▓ ▓█ ██▓ ░▓▓▓▓▓▓▓▒ ▒██▓ ░█▒
▓█ █ ▓███▓▒░ ░▓▓▓███▓ ░▒░ ▓█
██▓ ██▒ ░▒▓▓███▓▓▓▓▓██████▓▒ ▓███ █
▓███▒ ███ ░▓▓▒░░ ░▓████▓░ ░▒▓▒ █▓
█▓▒▒▓▓██ ░▒▒░░░▒▒▒▒▓██▓░ █▓
██ ▓░▒█ ▓▓▓▓▒░░ ▒█▓ ▒▓▓██▓ ▓▒ ▒▒▓
▓█▓ ▓▒█ █▓░ ░▒▓▓██▒ ░▓█▒ ▒▒▒░▒▒▓█████▒
██░ ▓█▒█▒ ▒▓▓▒ ▓█ █░ ░░░░ ░█▒
▓█ ▒█▓ ░ █░ ▒█ █▓
█▓ ██ █░ ▓▓ ▒█▓▓▓▒█░
█▓ ░▓██░ ▓▒ ▓█▓▒░░░▒▓█░ ▒█
██ ▓█▓░ ▒ ░▒█▒██▒ ▓▓
▓█▒ ▒█▓▒░ ▒▒ █▒█▓▒▒░░▒██
░██▒ ▒▓▓▒ ▓██▓▒█▒ ░▓▓▓▓▒█▓
░▓██▒ ▓░ ▒█▓█ ░░▒▒▒
▒▓▓▓▓▓▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒░░▓▓ ▓░▒█░
F L I N K - S C A L A - S H E L L
NOTE: Use the prebound Execution Environments and Table Environment to implement batch or streaming programs.
Batch - Use the 'benv' and 'btenv' variable
* val dataSet = benv.readTextFile("/path/to/data")
* dataSet.writeAsText("/path/to/output")
* benv.execute("My batch program")
*
* val batchTable = btenv.fromDataSet(dataSet)
* btenv.registerTable("tableName", batchTable)
* val result = btenv.sqlQuery("SELECT * FROM tableName").collect
HINT: You can use print() on a DataSet to print the contents or collect()
a sql query result back to the shell.
Streaming - Use the 'senv' and 'stenv' variable
* val dataStream = senv.fromElements(1, 2, 3, 4)
* dataStream.countWindowAll(2).sum(0).print()
*
* val streamTable = stenv.fromDataStream(dataStream, 'num)
* val resultTable = streamTable.select('num).where('num % 2 === 1 )
* resultTable.toAppendStream[Row].print()
* senv.execute("My streaming program")
HINT: You can only print a DataStream to the shell in local mode.
scala>
从提示信息看,flink-scala-shell一共初始化了四个ExecutionEnvironment,分别是Stream API流处理和批处理以及Table API 的流处理和批处理,本文主要讨论Stream API的使用。
在REPL页面内可以直接执行代码,比如执行以下内容引入隐式转换:
import org.apache.flink.api.scala._
1. DataStream Transformation (数据流转换)
基于单数据处理: DataStream → DataStream
Map/FlatMap/Fliter
比较简单,直接看例子:
val dataStream = senv.fromElements(1, 2, 3, 4)
dataStream.map { x => x * 2 }.print
senv.execute("map Test Execution")
val dataStream2 = senv.fromElements("hello world hello flink")
dataStream2.flatMap { str => str.split(" ") }.print
senv.execute("flatMap Test")
dataStream.filter { _ != 1 }
senv.execute("Fliter Test")
keyby()/sum()/reduce()…
同样比较简单
Window 操作:DataStream → WindowStream/AllWindowedStream
以作者的理解,目前的Flink Window API 可以从触发方式以及是否带Key分为四类
-
以触发方式区分可以分为
TimeWindow和CountWindow。-
TimeWindow()是到时间就触发窗口,`CountWindow() 是到数量就触发。 -
从源码看,不管是
timeWindow()还是countWindow(),底层实际上都是执行的window(WindowAssigner assigner)方法 ,DataStream API 替我们进行了一层易用的封装,如图:

-
Window() 和 WindowAll()主要用于自定义窗口,如定义
WindowAssigner(窗口属性)WindowTrigger(窗口触发时机),WindowEvictor(窗口内数据的处理和剔除),WindowFunction(窗口内执行的操作)等,语法如下:Keyed Windows
stream .keyBy(...) <- keyed versus non-keyed windows .window(...) <- required: "assigner" [.trigger(...)] <- optional: "trigger" (else default trigger) [.evictor(...)] <- optional: "evictor" (else no evictor) [.allowedLateness(...)] <- optional: "lateness" (else zero) [.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data) .reduce/aggregate/apply() <- required: "function" [.getSideOutput(...)] <- optional: "output tag"Non-Keyed Windows
stream .windowAll(...) <- required: "assigner" [.trigger(...)] <- optional: "trigger" (else default trigger) [.evictor(...)] <- optional: "evictor" (else no evictor) [.allowedLateness(...)] <- optional: "lateness" (else zero) [.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data) .reduce/aggregate/apply() <- required: "function" [.getSideOutput(...)] <- optional: "output tag"
-
-
以是否携带键值可以分为
KeyedStream和NonKeyedStream- 带键值的DataStream转换的流为
WindowedStream,想把dataStream转换为WindowedStream,需要先通过keyBy()方法进行GroupBy动作,将dataStream转换为KeyedStream,然后在通过KeyedStream.timeWindow()/.countWindow()/window()方法转换; - 不带键值的DataStream转换的流为
AllWindowedStream,转换时直接通过dataStream.timeWindowAll()/.countWindowAll()/windowAll()即可转换为AllWindowedStream,值得注意的是:windowAll()在很多情况下都是非并行的,所有记录都将被收集到一个Task中进行处理
- 带键值的DataStream转换的流为
NonKeyedWindowStream :countWindowAll()/timeWindowAll()/windowAll()
val dataStream = senv.fromElements(1, 2, 3, 4)
//基于个数的窗口:每两个记录数统计sum值
dataStream.countWindowAll(2).sum(0).print()
senv.execute("NonKeyedWindowStream program")
KeyedWindowStream :countWindow()/timeWindow()/window()
我们采用StreamEnviroment.socketTextStream方法建立socket连接测试windowStream
由于是部署在docker中,我们先获取容器内映射的宿主机IP,新开终端执行以下命令,获取映射的IP
ifconfig |grep 'docker0' -A 1
#docker0: flags=4099 mtu 1500
# inet 172.17.0.1 netmask 255.255.0.0 broadcast 0.0.0.0
↑↑↑ 上面的IP就是映射的宿主机IP
val text = senv.socketTextStream("172.17.0.1", 9997) //上面命令中获取到的IP
val counts = text.flatMap(_.toLowerCase.split("\\W+")).filter(_.nonEmpty).map((_,1)).keyBy(0).timeWindow(Time.seconds(5), Time.seconds(3)).sum(1)
counts.print
senv.execute("Window Stream WordCount")
新开终端执行端口监听命令
nc -lk 9997
在终端中隔断时间输入单词,即可看到窗口统计的效果,如图:
多流合并
Flink 针对多流的合并,提供了 join connect coGroup union intervalJoin几种方式
共同点
join
-
侧重于pair ;按照一定条件抽取两个流的Key ,对同一个key上的每对元素进行操作,所以要求必须全部匹配上
-
相当于 inner join 语义,必须要两个流的数据都存在才会输出否则不输出
-
操作的数据流类型允许不一致,但是用作匹配的Key必须一致
-
只能在window中使用
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows
import org.apache.flink.streaming.api.scala.CoGroupedStreams
import org.apache.flink.streaming.api.windowing.triggers.CountTrigger
import org.apache.flink.util.Collector
import org.apache.flink.api.scala._
val stream1 = senv.socketTextStream("172.17.0.1", 9000).map(s => s.split(" ")).map(arr => (arr(0), arr(1)))
val stream2 = senv.socketTextStream("172.17.0.1", 9001).map(s => s.split(" ")).map(arr => (arr(0), arr(1)))
stream1.join(stream2)
.where(_._1).equalTo(_._1)
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(30)))
.trigger(CountTrigger.of(1))
.apply((t1, t2, out: Collector[String]) => {
out.collect(t1._2 + "<=>" + t2._2)
})
.print() //注意把方法挪到一行执行
senv.execute("Join Demo")
代码解释:
为方便测试,这里建立了一个
session window,当一个窗口在大于Session gap的时间内没有接收到新数据时,窗口即关闭,Windows Size是可变的
指定一个windowTrigger覆盖了Session Window 的WindowAssigner中trigger,随便在两个窗口中输入一条数据即可触发窗口
在terminal1中输入,1 a,然后在terminal2中输入2 b。观察程序console,发现没有输出。这两条数据不满足匹配条件,因此没有输出。
在30秒之内输入1 c,发现程序控制台输出了结果a<=>c。再输入1 d,控制台输出a<=>c和a<=>d两个结果。
等待30秒之后,在terminal2中输入1 e,发现控制台无输出。由于session window的效果,该数据和之前stream1中的数据不在同一个window中。因此没有匹配结果,控制台不会有输出。
coGroup
- 侧重于group,是对同一个key上的两组集合进行操作,即使没有匹配上另一个流
- 类比 outer join 语义,只要触发了窗口,即便另一个流没有数据,也会被纳入计算中
- 只能在window中使用
val stream1 = senv.socketTextStream("172.17.0.1", 9000).map(line => (line, line))
val stream2 = senv.socketTextStream("172.17.0.1", 9001).map(line => (line, line))
def myCoGroupFunc(in1:Iterator[(String,String)],in2:Iterator[(String,String)],out:Collector[String]):Unit = {
val stringBuilder = new StringBuilder("Data in stream1: \n")
for (i1 <- in1) {
stringBuilder.append(i1._1 + "<=>" + i1._2 + "\n")
}
stringBuilder.append("Data in stream2: \n")
for (i2 <- in2) {
stringBuilder.append(i2._1 + "<=>" + i2._2 + "\n")
}
out.collect(stringBuilder.toString)
}
stream1.coGroup(stream2).where(_._1).equalTo(_._1).window(ProcessingTimeSessionWindows.withGap(Time.seconds(30))).trigger(CountTrigger.of(1)).apply((in1,in2,o: Collector[String])=> myCoGroupFunc(in1,in2,o)).print()
senv.execute("coGroup Test")
分别在两个终端输入数据,可以发现即使另一个窗口没有数据,也会输出相关数据
注释
.trigger(),将Session Gap调整到10秒,terminal1中输出1和3terminal2中输入2和3,等待10秒,也可以看到没有关联的数据也会被输出
connect
- 可以connect2个类型不同的流,输出流也可以不一样,
ConnectedStreams的类型由两个输出流决定,如果输出流中的数据类型不一致,会返回DataStream[Any]的数据 - connect可以不用放在Window中使用,也不需要指定
Key,仅仅将两个流放在一起用CoMap/CoFlatMap或分别用两个map函数处理,侧重于数据的组装,比join和Cogroup更加灵活
val stream1 = senv.socketTextStream("172.17.0.1", 9000)
val stream2 = senv.socketTextStream("172.17.0.1", 9001)
stream1.connect(stream2).map(in1=>in1+"--in1",in2=>in2.toInt+20).print()
senv.execute("connectStream Test")
union
- 单纯的合并流,支持多个流合并成一个:
DataStream* → DataStream - 类似于SQL的 union 语义:不去重,但是要求合并的流的数据类型必须一致
- 比较简单,这里贴出来union的定义,没有代码例子:
def union(dataStreams: org.apache.flink.streaming.api.scala.DataStream[T]*): org.apache.flink.streaming.api.scala.DataStream[T]
intervalJoin
Flink中基于DataStream的join,只能实现在同一个窗口的两个数据流进行join,但是在实际中常常会存在数据乱序或者延时的情况,导致两个流的数据进度不一致,就会出现数据跨窗口的情况,那么数据就无法在同一个窗口内join。Flink基于KeyedStream提供的interval join机制,intervaljoin 连接两个keyedStream, 按照相同的key在一个相对数据时间的时间段内进行连接。
如果数据时间戳为10s,upperBound为5s,lowerBound为1s,左边流时间戳+1s<=右边时间戳<=左边流时间戳+5s 的数据均可以被匹配上,且包含上下界
样例代码如下:
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction
import org.apache.flink.util.Collector
import java.sql.Timestamp
import org.apache.flink.api.scala._
case class OrderEvent(uid: Int,pdId: Long, eventTime: Long)
case class OrderPrice(pdId: Long, price: Int, eventTime: Long)
val orderStream = senv.fromCollection(List(
OrderEvent(1, 1,1631932423),
OrderEvent(2, 1,1631932424),
OrderEvent(3, 2,1631932425)
)).assignAscendingTimestamps(_.eventTime*1000)
val priceStream = senv.fromCollection(List(
OrderPrice(1,10, 1631932422),
OrderPrice(1,15, 1631932423),
OrderPrice(1,20, 1631932430),
OrderPrice(2,20, 1631932420),
OrderPrice(2,25, 1631932430)
)).assignAscendingTimestamps(_.eventTime*1000)
val intervalJoinStream = orderStream.keyBy(_.pdId)
.intervalJoin(priceStream.keyBy(_.pdId))
.between(Time.seconds(-5),Time.seconds(5))
.process(new ProcessJoinFunction[OrderEvent,OrderPrice,String] {
override def processElement(left: OrderEvent, right: OrderPrice, ctx: ProcessJoinFunction[OrderEvent, OrderPrice, String]#Context, out: Collector[String]): Unit = {
out.collect(s"user${left.uid} parchased product${left.pdId} on price ${right.price} (ordertime : ${new Timestamp(left.eventTime*1000).toString},priceTime: ${new Timestamp(right.eventTime*1000).toString}) !" )
}
})
intervalJoinStream.print
senv.execute("intervalJoin Test")
执行结果如图:
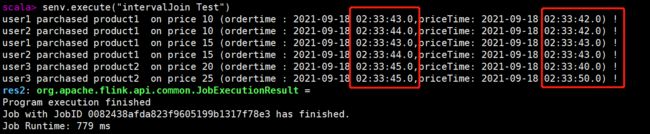
可以看到满足时间上下界条件的数据都会被匹配到且不满足上下界(price为20的product1)的数据会被清除
关于Interval Join的一些补充:
-
使用Interval Join时,必须要指定的时间类型为EventTime
-
实际底层是将KeyedStream通过connect连接起来,对每个连接的数据进行处理
如果要关注实现原理,可以[参考](Flink Interval Join 使用和原理分析 - 云+社区 - 腾讯云 (tencent.com))这篇文章
单流切分
filter: 直接对流进行多次filter也可以实现流拆分的需求,缺点是多次执行对性能有较大影响
split
splitdataStream调用.split(fun: Long => TraversableOnce[String])方法,实现select()方法,将数据放在不同的Tag中,生成SplitStream,调用.select(outputNames: String*)在多个Tag中筛选出需要的数据,1.12版本后已废弃
val splitedStream = senv.generateSequence(1,10).split(num => (num % 2 ) match{
case 0 => List("even")
case 1 => List("odd")
})
splitedStream.select("odd").print
splitedStream.select("even").print
senv.execute("Split Stream Test")
side Output
1.12.0 版本后,官方更推荐使用Side Outputs(旁路分流)进行流拆分
import org.apache.flink.util.Collector
import org.apache.flink.streaming.api.functions.ProcessFunction
//定义Output Tag
val outputTag = OutputTag[String]("side-output")
val ds = senv.generateSequence(1,10).process(new ProcessFunction[Long,Long]{
override def processElement(
value: Long,
ctx: ProcessFunction[Long, Long]#Context,
out: Collector[Long]): Unit = {
out.collect(value)
ctx.output(outputTag, "sideout-" + String.valueOf(value))
}
})
ds.print
//通过Output Tag获取侧流输出
ds.getSideOutput(outputTag).print
senv.execute("side Output Test")
以下是可以用于数据拆分的特殊处理函数
- ProcessFunction
- KeyedProcessFunction
- CoProcessFunction
- KeyedCoProcessFunction
- ProcessWindowFunction
- ProcessAllWindowFunction
2. 其他算子
broadcast
使用方法:
- 创建descriptor,用来描述了用于存储规则名称与规则本身的 map 存储结构,如果流结构不是map的,则可以
Types.VOID代替key - 对广播流调用
.broadcast(descriptor),通过非广播流调用eventStream.connect(broadcastedStream)生成BroadcastConnectedStream,调用process方法处理
注意:
- 对于
规则流,它应该被广播到所有的下游 task 中,下游 task 应当存储这些规则并根据它寻找满足规则的图形对。 --官方文档
- 注意DataStream的connect()有两种实现,一个是生成
ConnectedStreams,用于流合并的,一个是生成BroadcastConnectedStream,用于进行process()处理的 - 非广播流可以是keyed和non-keyed,分别采用
BroadcastProcessFunction和KeyedBroadcastProcessFunction来处理
iterate
process
KeyBy: DataStream → KeyedStream
dataStream.keyBy(_.someKey)
dataStream.keyBy(_._1)
注意,以下数据类型不能作为Key:
POJO对象没有 重写
hashCode()方法的任何类型的数组
3 DataStream 物理分区
Flink的并行度可以在一个Flink作业的执行环境层面统一设置,这样将设置该作业所有算子并行度,也可以对某个算子单独设置其并行度。如果不进行任何设置,默认情况下,一个作业所有算子的并行度会依赖于这个作业的执行环境。如果一个作业在本地执行,那么并行度默认是本机CPU核心数。当我们将作业提交到Flink集群时,需要使用提交作业的客户端,并指定一系列参数,其中一个参数就是并行度。
并行度在架构上的体验就是有多少个Task Slot,也即多少个subTask。
- 并行度设置
// 获取当前执行环境的默认并行度
val defaultParallelism = senv.getParallelism
// 设置所有算子的并行度为4,表示所有算子的并行执行的实例数为4
senv.setParallelism(4)
//也可以对某个流单独设置并行度
dataStream.setParallelism(defaultParallelism * 2)
- 数据重分区(shuffle)
shuffle():底层实际上是通过java.util.Random 生成的随机数保证的分配的随机
rebalance():采用轮询的方式随机均分,保证下游算子
rescale()与rebalance()类似,区别是该算子性能开销较小,因为并不是轮询分配,而是就近分配
broadcast():将数据均匀的广播到下游的所有实例上
global():将所有数据下发到下游算子的第一个分区,谨慎使用避免性能问题!
partitionCustom():自定义分区器
4 算子链和资源组
算子链:Flink 默认会将能链接的算子尽可能地进行链接(例如, 两个 map 转换操作),而Flink提供了对链接更细粒度控制的 API
-
disableChaining()切断算子链 -
startNewChain()切断算子链开始新的算子链:someStream.filter(...).map(...).startNewChain().map(...) -
StreamExecutionEnvironment.disableOperatorChaining(): 执行环境层面禁用算子链
5 常见Connector的使用
TODO
5 窗口的补充
5.1 窗口的分类
滚动、滑动、会话…
5.2 时间和水位线
参考《2.DataStreamAPI.md》