被老师夸了的汇报,2023计算机视觉最新论文自监督
CVPR 2023 Top-Down Visual Attention from Analysis by Synthesis
Baifeng Shi UC Berkeley Trevor Darrell UC Berkeley Xin Wang Microsoft Research
The focus of recent thinking has been on improving the attention module.This paper present a novel perspective on how AbS entails top-down attention.
First, introduce the top-down attention
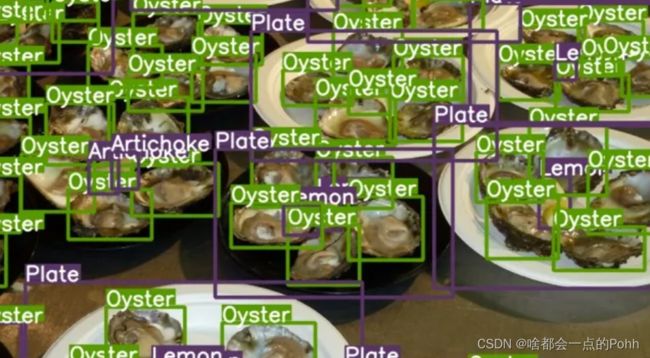
What is the top-down attention?
When there are multiple objects in a scene, the normal vision transformer will highlight all the objects. However, in real life, when we perform a task, we only focus on the objects related to the current task, which means that human attention is not only related to the bottom up attention of the image itself, but also regulated by the top down attention of the high-level task/goal.
That's right, ViT will highlight all the oysters. This is because the attention of ViT is bottom up attention, which is determined only by the input image. This kind of attention will circle all objects in the input.
However, we cannot eat all the oysters in one bite, we have to eat them one by one. And we may still come with tasks to eat, such as selecting the largest and fattest ones first.
At this point, we need another type of attention, called top down attention, which means that we don't want to focus on all the objects in the image, but only on the objects related to the current task (such as the oyster that bears the brunt).
So, from its introduction, it is very suitable for downstream tasks to improve the performance of image classification, semantic segmentation, and model robustness.
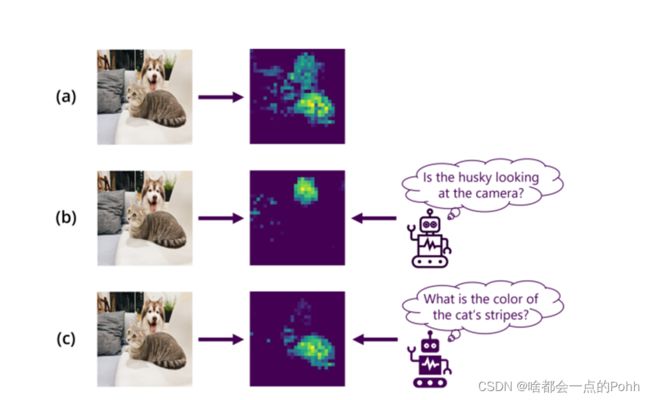
The paper highlights:
propose AbSViT, a ViT [18] model with prior-conditioned top-down modulation trained to approximate AbS in a variational way. AbSViT contains a feedforward (encoding) and a feedback (decoding) pathway. The feedforward path is a regular ViT, and the feedback path contains linear decoders for each layer. Each inference starts with an initial feedforward run. The output tokens are manipulated by the prior and fed back through the decoders to each self-attention module as top-down input for the final feedforward pass .
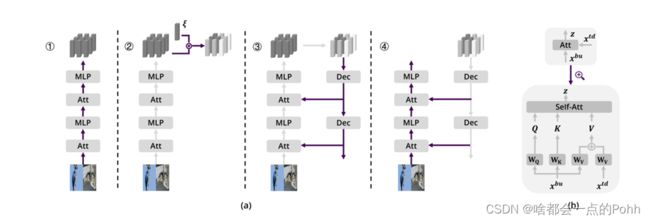
(a) Four steps to every single inference. The operations in each step are colored as purple and others as gray.AbSViT first passes the image through the feedforward path. The output tokens are then reweighted by their similarity with the prior vectorξ and fed back through the decoders to each self-attention module as the top-down input for the final feedforward run. (b) The top-down input to self-attention is added to the value matrix while other parts stay the same.
Although the paper section involves many formulas, it can be seen from the structural diagram he provided. Structurally, only top-down attention modules were added to the value matrix, while other structures remained unchanged. Similar to the structure of residuals.
(It should be noted that the ξ used here is a token, but it is only used to filter tokens that are highly similar to ξ later. This article still uses supervised learning.)
Shortcomings: This article is in the field of visual language tasks, and I hope to directly apply it to the field of video action recognition. So I focused on introducing the processing process of the model in the feedforward path process, as well as the insertion position of the top-down attention module.
MAR: Masked Autoencoders for Efficient Action Recognition
Zhiwu Qing, Shiwei Zhang, Ziyuan Huang, Xiang Wang, Yuehuan Wang, Yiliang Lv, Changxin Gao, Nong Sang
At the same time, in the code implementation of MAR, and the overall framework is the same as MAE. Here is one point.
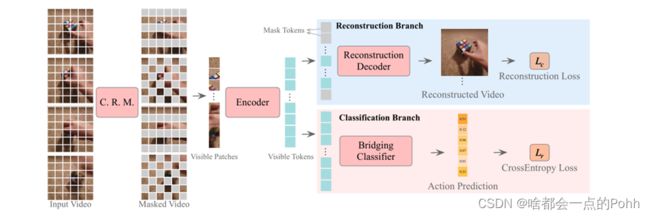
A specified proportion (e.g., 50% here) of patches is first discarded by cell running masking (C.R.M.), which retains sufficient spatio-temporal correlations. Next, the remaining visible patches are fed into the encoder to extract their spatio-temporal features (i.e., visible tokens in the figure). Finally, the reconstruction
decoder receives mask tokens and visible tokens to reconstruct the masked patches. In contrast, the bridging classifier in the classification branch receives only visible tokens from performing the action classification task. Note that the reconstruction branch is only performed in training, which is used to preserve the completion capability of the encoders for invisible patches.
In essence, it is supervised learning. Some supervised learning is added to the framework of the self supervised model, which leads to better model effect and robustness. Designed a classification module using supervised learning.
I think this is also a method of designing models. For example, combining top-down attention modules with classification bridging modules. Add supervised learning auxiliary module in the process of self supervision.