c++之模板初阶详解!
c++之模板初阶详解
文章目录
- c++之模板初阶详解
-
- 泛型编程
- 函数模板
-
- 函数模板概念
- 函数模板格式
- 模板的原理
- 函数模板的实例化
- 模板实例化的个数
- 对于同不同类型的传参!
-
- 如何处理这个问题呢?
- 关于具体存在的函数和模板函数的优先级问题!
- 类模板
-
- 类模板的用法!
- 类模板的实例化!
- 模板的范围
- 类模板的运用实例!
- 模板的缺陷!
-
- 解决方法!
泛型编程
我们以前是如何实现一个通用的函数呢?
void swap(int& x, int& y) { int temp = x; x = y; y = temp; } void swap(double& x, double& y) { double temp = x; x = y; y = temp; } void swap(char& x, char& y) { double temp = x; x = y; y = temp; }使用函数重载来实现一个通用的函数!但是函数重载也有很多的问题!
- .重载的函数仅仅是类型不同,代码复用率比较低,只要有新类型出现时,就需要用户自己增加对应的函数
- 代码的可维护性比较低,一个出错可能所有的重载均出错
所以有没有一个方法能够解决以上的缺点,同时又保留优点呢?
所以C++提供了模板作为手段来解决这些问题!
泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础。


函数模板
函数模板概念
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定类型版本。
函数模板格式
template
或者 template
template <class T>
void swap(T& left, T& right)
{
T temp = left;
left = right;
right = temp;
}
int main()
{
int a = 0, b = 1;
swap(a, b);
double c = 1.11, d = 1.2222;
swap(c, d);
char e = 'a', f = 'b';
swap(e, f);
}
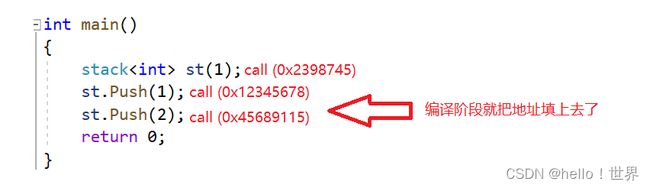
模板的原理
那么这三个调用的swap函数是同一个函数吗
答案是错误的!这三个swap函数是三个不同的函数!
而且从函数创建的角度来看!我们调用函数都要创建栈帧!这三个函数的栈帧大小都是不一样的!所以也就不可能是同一个函数!
我们还可以看看反汇编下的代码

可以看到这三个函数的地址都是不一样!
所以调用的不是模板!模板是无法生成指令!因为类型不确定所以导致了栈帧大小无法确定!
但是函数是编译器通过模板来生成的!
函数模板是一个蓝图,它本身并不是函数,是编译器用使用方式产生特定具体类型函数的模具。所以其实模板就是将本来应该我们做的重复的事情交给了编译器

在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供 调用。比如:当用double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然 后产生一份专门处理double类型的代码,对于字符类型也是如此。
函数模板的实例化
用不同类型的参数使用函数模板时,称为函数模板的实例化。模板参数实例化分为:隐式实例化和显式实例 化。
和对象的实例化是有区别的!类的实例化是编译器通过类的对齐规则计算类的大小有多大,类的内存分布规则是怎么样的,然后开一块空间出来!给对象!最后去调用构造函数!
但是模板的实例化是比编译器通过我们传的参数类型,使用函数模板来替换对应的T生成对应的具体函数!
模板实例化的个数
上面的代码我们看出来模板一共实例化的三个函数!
template <class T>
void swap(T& left, T& right)
{
T temp = left;
left = right;
right = temp;
}
int main()
{
int a = 0, b = 1;
swap(a, b);
int a =0
double c = 1.11, d = 1.2222;
swap(c, d);
char e = 'a', f = 'b';
swap(e, f);
}

答案是生成3个!当有相同的参数类型的函数调用的时候!如果之前已经生成过,那么就会调用之前生成的那个函数!
函数没有销毁这个概念!函数只是一串命令!只是函数每一次调用的栈帧有销毁的概念!
对于同不同类型的传参!
template <class T>
void swap(T& left, T& right)
{
T temp = left;
left = right;
right = temp;
}
int main()
{
int a = 0, b = 1;
double c = 1.11, d = 1.2222;
char e = 'a', f = 'b';
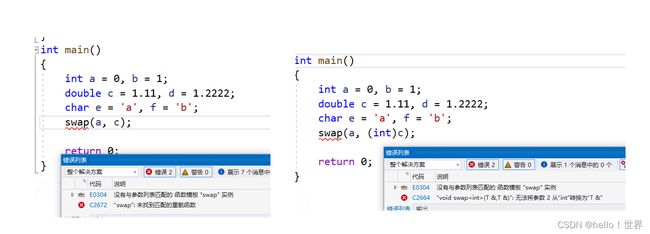
swap(a, c);//这个会报错!表面上看是因为类型不同导致的!
//但是有没有想过一个问题?
//我们平时在将double 赋值个int 的时候往往会出现隐式类型转换,为什么这次就出现不了了
//那如果我们使用强制类型转换呢?
return 0;
}
如何处理这个问题呢?
使用const类型的参数去接收强转之后的具有常性的临时变量!不过这样就意味着该变量无法修改所以接下里了我们将使用add函数来进行演示!
刚刚都是一种隐式的去让编译器自己推演生成对应的函数!我们也可以自己指定让编译器去生成我们想要的函数!直接跳过推演的阶段!
多定一个模板参数即可!
template <class T>
T add(T& left, T& right)
{
return left + right;
}
template <class T>
T add2(const T& left, const T& right)
{
return left + right;
}
template <class T,class T2>
T add3(const T& left,const T2& right)
{
return left + right;
}
int main()
{
int a = 0, b = 1;
double c = 1.11, d = 1.2222;
char e = 'a', f = 'b';
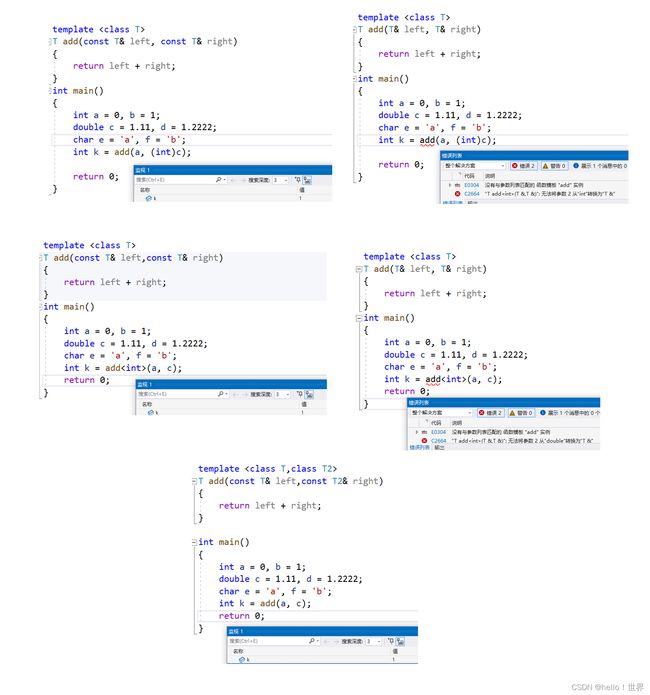
add(a, (int)c);
//还是会报错!因为这样子函数是成功的生成了!
//但是强制类型转换必然会是生成一个具有常性的临时变量变量!
//将T& 接收 const T是不可以的!
//发生了权限的放大!
int k = add2(a, (int)c);
//这样子就可以成功的使用该函数了!
//上面的我们都要是要让编译器进行推演然后得到对应的类型函数!
//但是我们也可以直接跳过这个阶段!我们可以显示的去指定让编译器去生成对应的类型函数!
int k1 = add<int>(a, c);
//会报错!函数虽然已经生成了!但是理由同同上,因为发生了权限的放大!
int k2 = add2<int>(a,c);
int k3 = add<double>(a,c);
//这样子就可以使用了!
//使用两个模板参数!
int k4 = add3(a,c);
return 0;
}
关于具体存在的函数和模板函数的优先级问题!
当模板函数和具体的类型函数同时存在的时候会先调用那个呢?
template <class T>
T add(T& left,T& right)
{
return left + right;
}
int add(int left, int right)
{
return left + right;
}
int main()
{
int a = 0, b = 1;
double c = 1.11, d = 1.2222;
char e = 'a', f = 'b';
int k = add(a,b);
int k1 = add<int>(a,b);
return 0;
}
答案是若是隐性的去生成对应的类型类型,那么编译器回去优先调用已经存在的对应类型的函数!
只有显性的去要求生成的时候,编译器才会去生成!
从这个我们也可以看处理模板名的函数名修饰规则和普通的函数名修饰规则是不一样的!

类模板
以前我们想让一个类可以在多个类型复用我们可能会使用!typedef
typedef int STDateType;
class stack
{
public:
stack(STDateType newcapcacity)
{
STDateType* temp = (STDateType*)malloc(sizeof(STDateType) * newcapcacity);
if (temp == nullptr)
{
perror("malloc fail");
exit(-1);
}
_a = temp;
_top = 0;
_capacity = newcapcacity;
}
~stack()
{
free(_a);
_a = nullptr;
_top = 0;
_capacity = 0;
}
stack& operator=(stack& st)
{
if (this != &st)
{
_a = (T*)malloc(sizeof(T) * st._capacity);
if (_a == nullptr)
{
perror("malloc fail");
exit(-1);
}
memcpy(_a, st._a, st._top * sizeof(T));
_capacity = st._capacity;
_top = st._top;
}
return *this;
}
void Push(STDateType x)
{
//...
}
private:
STDateType* _a;
int _top;
int _capacity;
};
但是这是有缺点的那就是万一我要同时使用的多个类型的类呢?那不就只能重新复制粘贴一份,而且因为了类名不能相同我们还得重新取名而且即使是单个类型的重复,我们也要反复的修改typedef!
typedef真正解决的是可维护性!方便在我们修改的时候只要修改一次!不是真正的泛型!
int main() { //整形! stack st1; st1.Push(1); //浮点型 stack st2; st2.Push(1.1); return 0; }
类模板的用法!
template<class T> class stack { public: stack(T newcapcacity = 4) { T* temp = (T*)malloc(sizeof(T) * newcapcacity); if (temp == nullptr) { perror("malloc fail"); exit(-1); } _a = temp; _top = 0; _capacity = newcapcacity; } ~stack() { free(_a); _a = nullptr; _top = 0; _capacity = 0; } stack& operator=(stack& st) { if (this != &st) { _a = (T*)malloc(sizeof(T) * st._capacity); if (_a == nullptr) { perror("malloc fail"); exit(-1); } memcpy(_a, st._a, st._top * sizeof(T)); _capacity = st._capacity; _top = st._top; } return *this; } void Push(const T& x) { //... } //使用T以后 push推荐使用引用!因为以前使用内置类型,类型大小不大!不怎么占用空间! //以后万一遇到类似于日期类,时间类或者其他比较大,更复杂的类的时候,那么使用传值传参就不怎么好了! private: T* _a; int _top; int _capacity; };
类模板的实例化!
类模板和函数模板不一样!函数模板可以通过实参推演形参来产生特定的类型函数!
但是类模板不一样!类模板没有时机去推演类型!所以这就导致了,类模板只能显示的去调用!
所以类模板统一显示实例化!
int main() { stack<int> st1; st1.Push(1); stack<double> st2; st2.Push(1.2222); return 0; }如果不显示实例化
类模板和函数模板一样,只是一个模板,不能当做真正的类去使用!
stack<int> st1;、 stack<double> st2;这两个类是不同的类型!因为这两个的类的大小都是可能不一样的!成员变量的大小也可能不一样!
它们是同一个类模板实例化出来的,但是它们不是同一个类型的类!
可以认为是同一个妈生的双胞胎!但是双胞胎肯定不是同一个人!
st1 = st2; //这个会报错! //赋值重载只限定在同一个类! //st1和st2压根不是同一个类!

模板的范围
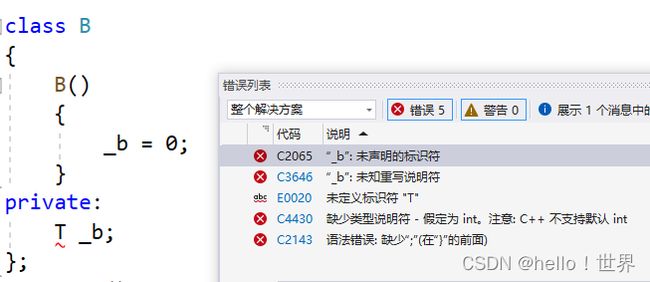
模板只能给模板一个函数或在类使用,不可以同时给两个!
在那个类或者函数里面,模板可以在任意范围生效!
template<class T>
class A
{
A()
{
_a = 0;
}
private:
T _a
};
class B
{
B()
{
_b = 0;
}
private:
T _b
};
//要一个模板对应一个类!
template<class T>
class A
{
A()
{
_a = 0;
}
private:
T _a
};
template<class T>
class B
{
B()
{
_b = 0;
}
private:
T _b
};
//函数模板也是同理!
类模板的运用实例!
c++中很少再去使用数组,取而代之的是array和vector!因为数组不安全!
当我们对数组进行访问的时候,因为对于数组的检查是抽查!编译器是不一定报错的!
对于原声的数组越界写可能会被检查到,但是越界读几乎检查不到!
但是在array中这个检查就是绝对的!
#define N 10 template<class T> class array { public: T& operator[] (size_t i) { assert(i<N) return _a[i]; } private: T _a[N]; }; int main() { array<int> a; for (int i = 0; i < N; i++) { a[i] = i; //a[i]相当于 a.operator[] (i); } for (int i = 0; i < N; i++) { cout << " " << a[i]; } cout << endl; for (int i = 0; i < N; i++) { a[i]++; } for (int i = 0; i < N; i++) { cout << " " << a[i]; } return 0; }虽然使用array会因为调用建立栈帧导致性能损失!但是因为类里面定义的都均为内联,所其实性能损失并没有多少!
模板的缺陷!
模板也是存在缺陷的!——那就是模板不支持分离编译!
就是说将声明放在.h文件中,将定义放在.cpp文件中!
//template.h #includeusing std::cout; using std::endl; template<class T> class stack { public: stack(int newcapcacity); ~stack(); void Push(const T& x); private: T* _a; int _top; int _capacity; }; //template.cpp #include "template.h" template<class T> stack<T>::stack(T newcapcacity) { T* temp = (T*)malloc(sizeof(T) * newcapcacity); if (temp == nullptr) { perror("malloc fail"); exit(-1); } _a = temp; _top = 0; _capacity = newcapcacity; } template<class T> stack<T>::~stack() { free(_a); _a = nullptr; _top = 0; _capacity = 0; }//这个虽然没有用T但是也要加上声明!说明这是属于类模板的! template<class T> void Push(const T& x) { //... } //test.h #include"template.h" int main() { stack<int> st(1); st.Push(1); st.Push(2); return 0; }

**然后我们发现了出现了这个这个不是编译错误这个是链接链接错误!出现链接错误就说明声明没有找到定义!**这是为什么!?
首先我们要先悉知一下编译链接的流程!


解决方法!
-
在定义的地方进行显示实例化!
这样的话就可以在定义的地方生成函数了!
#include "template.h" template<class T> stack<T>::stack(T newcapcacity) { T* temp = (T*)malloc(sizeof(T) * newcapcacity); if (temp == nullptr) { perror("malloc fail"); exit(-1); } _a = temp; _top = 0; _capacity = newcapcacity; } template class stack<int>; class stack<double>; //......但是这个方法失去了模板的优势!我们每使用一种就要在定义的地方显式实例化一次!这样其实很麻烦!
-
方法二将定义和声明都放在同一个源文件下面
//template.h
#include这样能解决的原因是因为,声明和定义都是在同一个文件下面所以自然就不需要进行链接了!
因为声明和定义都是在同一个文件里面,所以在编译阶段call的地址就自然就可以找到了!
读者可能会有疑惑,那为什么不直接写在类里面?还要多此一举!答案是为了有更好的可读性!在工程中,有的类的成员函数可能多达上千行!这样会导致可读性很差!不能方便快速的浏览类的成员函数和成员变量!