MySQL正则函数
-
正则函数
-
正则函数概念:正则表达式(Regular Expression)是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。
**注意:**MySQL 8.0+才引入regexp_replace,regexp_like,regexp_instr,regexp_substr四个函数,
在低于此版本的MySQL客户端执行这四个函数,报错:FUNCTION regexp_xxx does not exist -
主要函数
常用
1、REGEXP(匹配)/NOT REGEXP(不匹配) 可以用来匹配和不匹配,相当于正则方式的模糊查询,
符合返回1、不符合返回0
8.0之后
2、REGEXP_REPLACE regexp_replace()函数用于通过匹配字符来替换给定的字符串
3、REGEXP_LIKE regexp_like()函数用于比较给定的字符串,如果字符串相同则返回 1,否则返回 0。
4、REGEXP_SUBSTR 用于从给定的字符串中返回子字符串,有就返回子字符串,没有返回null。
5、REGEXP_INSTR 函数返回与正则表达式模式匹配的子字符串的起始索引。索引从 1 开始。如果不匹配,则返回 0。
-
正则表达式
元字符 功能说明 ^ 匹配字符串的开始位置,例如:‘^abc’,表示匹配字符串是否以abc开头。 $ 匹配字符串的结束位置,例如:‘abc$’,表示匹配字符串是否以abc结尾。 . 匹配任何单个字符,但不可以匹配’\n’,如果需要匹配包括’\n’在内的任何字符,需要使用’[.\n]'。 […] 匹配’[]‘中包含的任意一个字符,例如:’[abc]'可以匹配 ‘a’或’b’或’c’。 [^…] [^abc] 可以匹配除abc以外的任何字符。 匹配未包含的任意字符。 (…) 匹配’()‘中的所有字符,例如:’(abc)‘可以匹配’abcdefg’,但是不可以匹配’a’,‘ab’。 (^…) 匹配未包含在’()‘中的所有字符,例如:’(^abc)‘可以匹配’abdefg’,‘bcdefg’,但是不可以匹配’abcdefg’。 a|b|c 匹配’a’或’b’或’c’,例如:'f|good’可以匹配 ‘f’或 ‘good’,但是’(f|g)ood’则匹配 'food’或 ‘good’。 * 匹配表达式0~n次,例如:'go*'可以匹配 ‘g’,‘go’,‘goo’。 + 匹配表达式1~n次,例如:'go+'可以匹配 ‘go’,‘goo’,但不可以匹配 ‘g’。 {n} 匹配表达式n次。 {n,m} 匹配表达式最少匹配 n次且最多匹配 m次。
列如: 纯数字正则表达式:^[0-9]*$
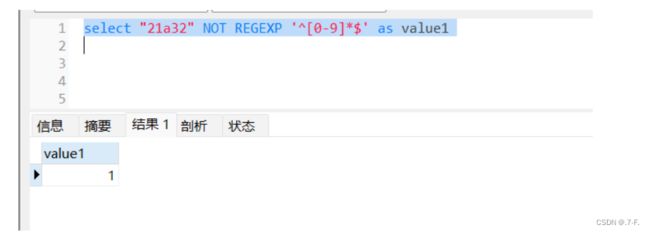
公式:REGEXP(匹配)/NOT REGEXP(不匹配)
判断:21a32,是否为纯数字;
返回值为0,因为其中包含a

同理:
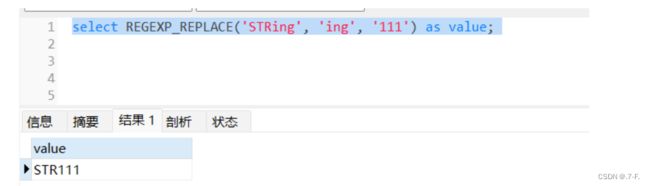
公式:regexp_replace(str, character, new_character) 用于通过匹配字符来替换给定的字符串
公式:regexp_like(str1, str2) 用于比较给定的字符串,如果字符串相同则返回 1,否则返回 0;这里不区分大小写

公式: regexp_substr(source_char,pattern,position,occurrence,match_parameter) 返回符合正则表表达式的字符串
-
source_char是目标字符串。必选参数。它通常是表中的一个字符列,可以是任何数据类型CHAR,VARCHAR2, NCHAR, NVARCHAR2, CLOB, 或NCLOB。
-
pattern是正则表达式。必选参数。它通常是一个文本文字。
-
position是一个正整数。可选参数。指示应从source_char的何处开始搜索满足正则表达式的字符串。默认值为 1,这意味着从source_char 的第一个字符开始搜索。
-
occurrence是一个正整数。可选参数。指示返回第几个满足正则的字符串。默认值为 1,这意味着返回第一次出现的pattern。
说明:当满足正则表达式的不止一处时,该参数才有意义 -
match_parameter是一个文本文字。可选参数。可让您更改函数的默认匹配行为。有以下几个取值:
1. 'i' (默认值)表示不区分大小写的匹配。 2. 'c' 表示区分大小写的匹配。 3. 'm'将源字符串视为多行。MySQL将^和$分别解释为源字符串中任意行的开头和结尾,而不是仅在整个源字符串的开头或结尾处。如果省略此参数,MySQL会将源字符串视为单行。 除了以上取值较为常用之外,还有'u','n'等不常用的取值列如: 开头结尾包含数字正则表达式:([0-9]+\\.?)?[0-9]
公式 REGEXP_INSTR(expr ,pat ,pos ,occurrence ,return_option ,match_type ) 返回符合正则表表达式的位置
- expr 为源字符串。
- pat 为正则表达式。
- pos 为可选参数,标识开始匹配的位置,默认为 1。
- occurrence 为可选参数,标识匹配的次数,默认为 1。
- return_option 为可选参数,指定返回值的类型。如果为 0,则返回匹配的第一个字符的位置。如果为 1,则返回匹配的最后一个位置,默认为0。
- match_type 为可选参数,允许优化正则表达式,可包含以下字符:
c:匹配区分大小写
i:匹配不区分大小写
m:多行模式。识别字符串中的行终止符。默认是仅在字符串表达式的开头和结尾匹配行终止符
n:与.行终止符匹配
u:仅匹配 Unix 的行结尾。只有换行符被识别为以 .,^和$结尾的行
-- REGEXP(匹配)/NOT REGEXP(不匹配)
select '123' REGEXP '^[0-9]*$';
select '123' not REGEXP '^[0-9]*$';
-- regexp_replace
select REGEXP_REPLACE('STRing', 'ing', '111');
-- regexp_like
select regexp_like('MCA', 'mca') as value;
-- regexp_substr
select
REGEXP_SUBSTR('qqq2622qqq3123','([0-9]+\\.?)?[0-9]') as '默认参数,第一次出现数字,并返回',
REGEXP_SUBSTR('qqq2622qqq3123','([0-9]+\\.?)?[0-9]',5) as '从指定位置开始匹配,第一次出现数字,并返回',
REGEXP_SUBSTR('qqq2622qqq3123','([0-9]+\\.?)?[0-9]',5,2) as '从指定位置开始匹配,第二次出现数字,并返回';
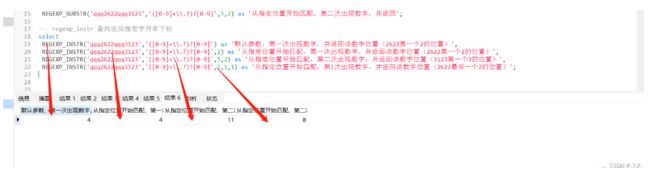
-- regexp_instr 查找返回指定字符串下标
select
REGEXP_INSTR('qqq2622qqq3123','([0-9]+\\.?)?[0-9]') as '默认参数,第一次出现数字,并返回该数字位置(2622第一个2的位置)',
REGEXP_INSTR('qqq2622qqq3123','([0-9]+\\.?)?[0-9]',2) as '从指定位置开始匹配,第一次出现数字,并返回该数字位置(2622第一个2的位置)',
REGEXP_INSTR('qqq2622qqq3123','([0-9]+\\.?)?[0-9]',5,2) as '从指定位置开始匹配,第二次出现数字,并返回该数字位置(3123第一个3的位置)',
REGEXP_INSTR('qqq2622qqq3123','([0-9]+\\.?)?[0-9]',1,1,1)-1 as '从指定位置开始匹配,第1次出现数字,并返回该数字位置(2622最后一个2的位置)';