DataOps不是工具,而是帮助企业实现数据价值的最佳实践
2008年,“大数据”一词在《大数据时代》中被首次提出,距今已有整整14个年头。在这14年中,许多人亲眼见证了数据的力量,以及目睹它如何改变世界。大部分企业的决策者都明白了一个道理:数据才是企业中最有价值的商品,它可以被人为选择成就还是破坏业务。
然而,自流行词“大数据”出现的14年后,如何获得更高质量的数据,以及更智能的数据管理,帮助企业做出明智和及时的决策,仍然是许多企业的“疑难杂症”。每个人的嘴里都在谈论数据治理和数据管理,却没有人真正知道该怎么办。
幸运的是,一种帮助企业提升数据分析质量和效率的方法论正在兴起,它就是DataOps。基于DataOps,企业数据中台可以实现数据利用率最大化,加快生产周期,及针对结果优化的数据管道。
今天,我们将展开说说DataOps,以及为什么它对于每一个想要真正实现数据赋能业务的企业都很重要。
一、DataOps是什么
DataOps(Data Operations)并不是一个新的概念,根据维基百科的说明,早在2014年就被IBM(Lenny Liebmann)提出,在2017年得到大范围关注,并在2018年正式被纳入Gartner的数据管理技术成熟度曲线当中。
今年,中国信通院正式牵头启动了DataOps的标准建设工作,以此为基础推动我国大数据产业的多元化发展,为企业经营决策提供数据支持。
同时需注意的一点,DataOps不是一个工具或产品,可以理解成一种「方法论,或者最佳实践」,类似软件开发中的「敏捷方法」。不能以功能的视角去看待DataOps,而是以「我应该如何做」的视角来看待此问题。
DataOps的目标是提供工具、过程以及结构化的方式来应对快速增长的数据,对企业内的数据团队赋能,能够使企业内的数据团队更高效、高质量的完成数据分析,它强调交流、协作、多系统集成以及自动化流程,并配套具备对应的度量方式。
二、DataOps的涵盖内容
下图为标准的DataOps涵盖的内容,主要包括数据技术、数据管道、数据处理3个方面,最终为商业用户输出价值。

原图出自:https://www.eckerson.com/articles/diving-into-dataops-the-underbelly-of-modern-data-pipelines
三、数栈DataOps实践
从发展上看,自2018年被纳入Gartner的数据管理技术成熟度曲线中以来,DataOps的热度逐年上升;从实践上看,欧美企业对于DataOps的探索和发展要早于中国,DataOps在我国仍处于一个从萌芽期到爆发期的关键过渡阶段。
数栈依据多年经验,通过敏锐的嗅觉快人一步开始探索DataOps的实践,总结出DataOps的3个层次+4个核心能力,助力企业加快数据洞察的步伐,具体分析如下:

1、基础层:多环境(集群)管理
在基础层,数栈支持多环境多集群管理,支持一套统一的平台来对接多套不同规模、不同类型的集群,支持Cloudera Hadoop、华为FusionInsight、华为MRS、星环Inceptor、Greenplum、GaussDB、MySQL等各类数据库作为计算引擎,提供统一的开发与应用体验,具备跨云部署以及对跨云EMR的兼容能力,面向多云场景提供统一开发、统一管控能力,用户可在不同的集群环境中(同类型引擎)实现代码及相关资源的无缝发布。

2、开发层:数据开发全链路
按照数据开发的基本过程,分为:模型设计、数据开发、部署上线、质量稽核4个步骤,日常用户的主要操作均是在这4个步骤之中,下面详细阐述:
1)模型设计
按照标准的数据中台建设模式,分为「制定标准」、「模型设计」2大部分。制定标准、模型的在线设计均可在数栈中在线进行,无需线下维护单独的数据标准文档、数据模型文档等内容,普通开发人员完成模型设计后,需提交管理员审核,模型经审核后允许上线/变更操作。
模型设计及标准制定可细分为6个单元,如下图所示:

其中数仓层级、规范设计、模型元素属于表级别定义,数据词表、词根、码表属于字段级别定义,数栈将6个单元以产品化的形式进行梳理、组合,便于企业建立自己的数据治理体系。
3)数据开发
数据开发环节,通过丰富的任务类型、代码的版本管理、责任人机制等,实现数据开发、数据分析的可持续发展,具体内容如下:
● 20+种丰富的任务类型
支持离线同步、实时同步、离线计算、实时计算、关系型数据库计算、管理节点、脚本任务等5大类,20+种不同的任务类型。用户可将企业内的数据采集、加工的各类离线、实时处理过程统一由数栈进行管理,实现一体化的数据开发平台。
● 数据测试
支持上传样本数据,模拟测试,进行数据逻辑验证与测试。

● 代码预检查
提交代码之前进行「预检查」,防止上线后发生问题。
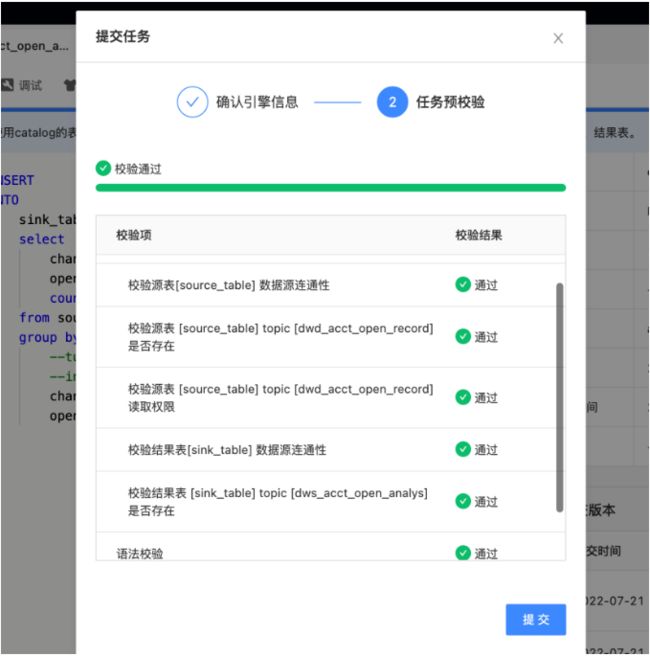
未来数栈将在系统规则的基础上,支持自定义校验规则,用户可基于数栈暴露的接口进行自定义开发,例如代码JOIN次数限制、分区表禁止全表扫描、禁止跨数仓层级访问等规则,可通过自定义开发Jar包的方式进行自定义规则校验。
3)部署上线
用户完成开发后,需将代码从测试环境发布至生产环境,平台需支持快速的任务发布,将开发/测试环节的代码及其依赖资源快速发布至生产环境。
数栈的部署发布分为两种模式:
● 双项目模式
可将一个项目中开发的任务发布至另一个项目。双项目模式可以在代码层和底层数据层面实现很好的隔离性,保障数据安全。
● 导入导出式发布
对于物理环境隔离的场景,可将开发的任务代码、依赖的UDF函数、Jar包等关联资源一起导出为zip包,并在生产环境执行一键导入。
除了代码发布外,还支持代码的版本管理、版本对比、快速回滚能力。数栈能记录每次提交发布的任务代码和运行参数,并标注每个版本的修改内容,帮助定位代码问题,同时可支持一键版本回滚。

3)治理层:统一元数据 质量稽核
治理层主要包括统一元数据及质量稽核两块能力:
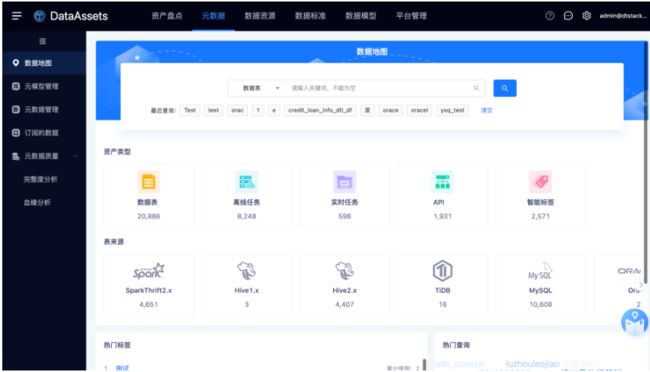
统一元数据
支持将数栈平台内的各类元数据汇聚、展示、打通、分析等,包括:元数据基础属性、离线表/任务、实时表/任务、API、标签、指标等各类元数据。
● 全域血缘打通
根据数据在中台内的采集、流转、对外服务等各环节的处理方式,自动建立全平台的血缘关系,基于核心的智能化SQL血缘解析能力,实现平台内跨应用的血缘打通,可视化展示数据的流转影响链路。
● 资产分析
可支持资产的版本变更记录/对比、数据产出分析、使用分析、质量分析等统计内容。
质量稽核
支持对数据进行质量校验,帮助企业及时发现数据问题。通过事前规则配置、事中规则校验、事后分析报告的流程化方式,对数据的完整性、准确性、规范性、唯一性、一致性等方面进行多维度评估,保障企业数据质量服务,支持规则配置、任务查询、实时校验等。

4)关键能力
数栈DataOps包括以下四大能力:
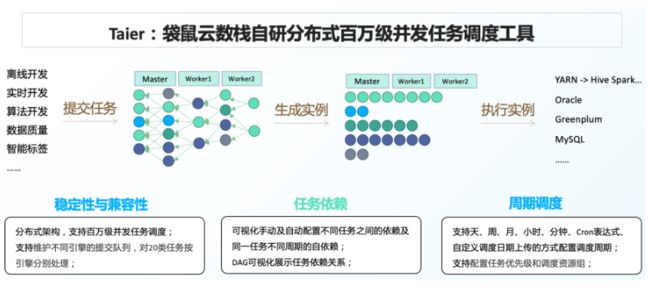
统一调度编排
数栈内置分布式调度引擎Taier,支持百万级别复杂依赖调度。调度平台在数栈内为底层通用能力,离线、实时、质量校验、标签、指标等各任务均使用统一的调度能力。
在此基础上,各产品模块之间可进行灵活的相互依赖,例如离线完成数据抽取+计算后,自动触发标签任务的计算等场景。
统一监控/告警
数栈支持统一的告警通道,不同的产品模块内可能都会使用告警能力,例如离线任务突破基线、实时任务失败、API调用失败、质量校验未通过等。针对某个告警通道仅需开发一次,即可再各个产品内使用此告警方式,例如短信、邮件,企业微信、钉钉、电话告警等。

模型设计
数栈在数据安全层面可分为如下几个方面:
● 系统安全
通过服务高可用部署、数据定期备份等策略保障服务安全。登录密码可按照长度、复杂度、强制定期更换等方式支持多种安全策略,密码采用国密加密传输+加密存储。
● 数据安全
底层可集成LDAP+Ranger+Kerberos数据安全组件。在Hadoop体系内可支持库、表、列、行级数据权限控制。在服务安全方面,可支持行、列权限控制、多种认证方式、国密加密等特性,保障用户数据安全。
● 安全审计
自动记录用户的关键操作行为、数据访问行为,可由管理员进行用户操作行为审计,排查异常行为。

团队协作
● 责任人机制
每个任务、表、标签、API、指标、告警配置等「资源」均建立责任人机制,当发生异常需配合排查时,可快速获取相关负责人,便于线下沟通。
● 一键交接
当发生人员变动时,支持一键交接,可批量将当前负责人的全部资源自动替换,便于工作交接。
● 用户组
当开发团队规模较大,需要再次细分时,可按照用户组的方式进行管理,例如按用户组批量添加用户、分配功能权限/数据权限、发送告警等场景,无需反复操作。

四、结语
随着时间的推移,数据的数量、频率、多样性都在增加,在一个万物皆可被度量的时代,数据积累的速度超过大部分企业跟上其脚步的速度。这也意味着能够帮助企业完成自动化日常任务,提高数据质量,促进不同团队之间的协作,带来更准确的洞察和分析,以及助力企业进入敏捷、自动化和加速的数据供应链环境的DataOps,未来将会在企业的数智化蜕变中,发挥不可小觑的作用。
企业实现 DataOps 有赖于一系列广泛的技术和流程,数栈目前已经在采集、加工、治理的核心流程上,通过版本控制、团队协同、一键发布、质量稽核、数据安全等能力实践了基本的DataOps理念,但依然有很多方面亟需改善,例如:利用AI/ML技术降低人为操作的成本与失误、对研发效能增加更多的的度量指标(Metric),以数据化的方式来衡量研发效能的增减等方面,均需要数栈团队,以及全行业一起努力。
原文来源:VX公众号“数栈研习社” 袋鼠云开源框架钉钉技术交流群(30537511),欢迎对大数据开源项目有兴趣的同学加入交流最新技术信息,开源项目库地址:https://github.com/DTStack