使用python进行数据分析
1.数据分析步骤
数据分析五个步骤
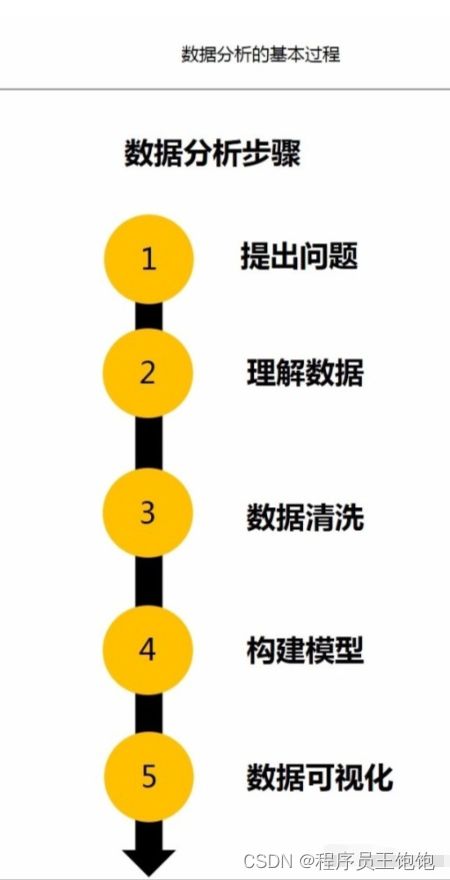
数据分析步骤
提出问题
提出一个好问题,是成功的一半。面对一堆数据,同样也需要提出问题,这样才能为后面的具体步骤找到方向和侧重点。
如某游戏公司想找一位明星为其新开发的游戏进行代言。明星那么多,如何才能话最少的钱,起到最大的宣传的效果呢?问题一旦提出来,就会从明星拥有粉丝的数量,最近的活跃度,明星的代言大概价位这个方面进行重点分析。
理解数据
包括三个方面:第一,采集数据。从定义的问题开始,采集相关的数据。第二,导入数据。要分析的数据会存储数据库或者excel文件中,也有可能在web的api的接口中。第三,查看数据集信息。包括数据统计信息。对数据整理理解,会数据分析建立一个宏观的认识。
数据清洗
数据清洗,也成数据预处理。因为数据在采集或存储过程中,有些数据不符合要求,不方面的后续的处理。因此需要对数据进行处理,变成能够被我们使用的格式。
构建模型
构建模型,也就是数学建模。根据问题难易程度,那么建模也有差异。简单的数据,如果一个餐馆一年的消费总金额,客单价,月均收入等。还有一些复杂的,需要利用机器学习,进行数据建模。
数据可视化
数据的分析,一定会有数据分析报告。我们既要会做,也要会说。为了更好的表达自己,那么展示的自己的成果的方式就是图标。通过可视化的方式,把自己的成果展示给自己的领导或客户看。
2. 要点总结
数据分析我们会用到numpy和pandas相关的库。对其中核心的要点总结如下
numpy
- ndarray 是一个通用的同构数据多维容器,也就是说,其中的所有元素必须是相同的类型。每个数组都有一个shape(一个表示各维度大小的元组)和一个dtype(一个用于说明数组数据类型的对象)。
- 认为np.empty会返回全0数组的想法是不安全的。如下述例子

numpy 中empty的用法
- 跟列表最重要的一个区别就是数组切片是原始数组的视图,意味数据不会被赋值,视图上的任何修改都反应到源数组上。但是需要注意,切片的数组,其地址并不是和说原数组的地址一样。
- 花式索引。可以整数数组的方式进行索引。索引值可以整数数组列表或ndarray。使用负数,可以从尾部进行索引数组每行数组。但是返回的是一维数组,对应每个索引元组。
- 使用np.ix_函数,也可以将两个一维整数数组转换为一个用于选取方形区域的索引器。花式索引跟切片不一样,它总是将数据复制到新数组中。
- 转置和轴对换。 转置是重塑的一种特殊形式,它返回的是源数据的视图(不会进行任何复制操作)。数组不仅有transpose方法,还有一个特殊的T属性。对于高维数组,transpose需要得到一个由轴编号组成的元组才能对这些轴进行转置。
- 通用函数(即ufunc)是一种对ndarray 中的数据执行元素级运算的函数。你可以将其看做简单函数(接受一个或多个标量值,并产生一个或多个标量值)的矢量化包装器。
许多ufunc是简单的元素级变体,如sqrt,exp
- 一些函数,如rint,四舍五入取最近的整数。modf,将数组的小数和整数部分分成两个独立数组。
- NumPy 数组使你可以将许多种数据处理任务表述为简洁的数组表达式。用数组表达式代替循环的做法,通常称为矢量化。矢量化数组运算要比等价的纯python方式快上一两个数量级,尤其是各种数值计算。
- numpy.where函数是三元表达式x if condition else y 的矢量化版本。np.where 的第二个和第三个参数不必是数组,它们都可以标量值。在数据分析工作中,where通常用于根据另一个数组而产生一个新的数组。
- 布尔值会被强制转换为1(True)和0(False)。因此,sum可以用来对布尔型数组中的True 值进行计数。
- 布尔数组还有两个方法any,all,它们对布尔型数组非常有用。any用于测试数组中是否存在一个或多个True,而all则检查数组中所有值是否都是True
- 跟python 内置的列表类型一样,Numpy数组也可以通过sort 方法就地排序。顶级方法np.sort返回的是数组已排序副本,而就地排序则会修改数组本身。计算数组分位数最简单的办法是对其进行排序,然后选取特定位置的值。
- Numpy 提供了一些针对一维ndarray 的基本集合运算。最常用的可能要数np.unique。它用于找出数组中的唯一值并返回已排序的结果。
- np.in1d用于测试一个数组中的值在另个一个数组中的成员资格,返回一个布尔型数组。
- np.save 和np.load是读写磁盘数组数据的两个主要函数,默认情况下,数组是以未压缩的原始二进制格式保存在扩展名为.npy的文件中。
- 通过np.savez可以将多个数组保存到一个压缩文件中,将数组以关键字参数的形式传入即可。
- dot函数,用于实现矩阵的点积。任何一个二维矩阵和一个合适的一维数组进行点积,得到是一个一维数组。x。dot(y) = np.dot(x,y)
- 矩阵论中,行列式,本征值,本征向量,矩阵的逆,QR分解,奇异值分解,最小二乘解,线性方程求解,需要再复习
- 随机数生成。numpy.random模块对python 内置random进行补充,可以生成多种概率分布的样本值函数。用normal 得到一个标准正太分布。而python的random函数只能一次只能生产一个。
pandas
-
Series, DataFrame,是pandas两种常用的数据类型;
-
Series 类似于一维数组的对象,数据类型包含numpy的数据类型,以及与之相对的数据标签构成
-
将Series 看成是一个定长的有序字典,因为他是索引值到数据值的一个映射。它可以用在许多原本需要字典参数的函数中。可以将数据存放在一个python的字典中,也可以直接通过这个字典来创建Series。
-
pandas 中有函数isnull,notnull 用于判断数组中数据是否为空,可以用于检测缺失数据。
-
Series最重要的功能在算术运算中将不同索引的数据进行自动对齐。
-
series 数组进行加法运算,两个数组都有的数据,那么会对里面的数据进行加法运算。没有的数据,会进行集合运算,但是对应的数据是NAN。
-
Series 对象本身及其索引都一个name的属性。该属性跟pandas其它的关键功能关系非常密切。
-
Series 的索引可以通过赋值来进行就地修改。
-
DataFrame是一个表格型数据结构,它含有一组有序的列,每列可以是不同的值类型。既有行索引,也有列索引,它可以被看做是Series 组成的字典。DataFrame 中面向行和面向列的操作基本上是平衡的。
-
DataFrame列用 columns,index 用于行索引
-
对DataFrame 的数据进行修改时,必须保证列表或数字和DataFrame的长度相匹配。
-
如果用Series进行赋值,就会精确匹配DataFrame的索引,所有的空位都将被填上缺失值。
-
DataFrame常见的数据形式是嵌套字典,就是字典中中的字典。对应的DataFrame,键的外层对是DataFrame的列,内层对应的是DataFrame的行索引。

DataFrame 的行列索引 -
如果有读取execl 文件,需要装载 xlrd 或openpyxl 安装包
3.遇到的问题
- 数据清洗时,出现告错
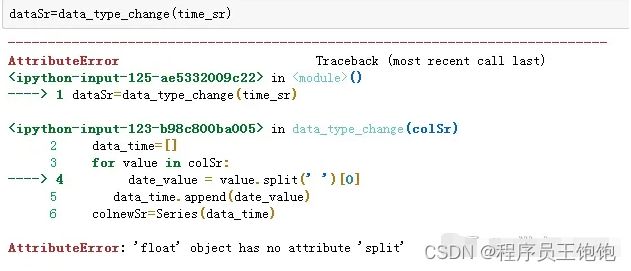
出现float 没有split属性的告警
当时出现这个告警时,一直没有找到原因。‘销售时间’,本来的数据是string,怎么会变成float的呢?打开数据表格,发现‘销售时间’这一列空的数据。而python中,空的数据是用NaN表示。NaN 和None 型是有差别的。差别如下
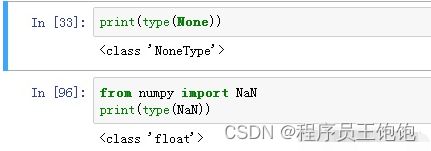
NaN型,对应的float的数据格式,所以他不具有split()这个方法。
因此需要‘销售时间’这一列数据进行清洗,把含有NaN的数据项清除出去。因此在前面执行如下命令行
salesDf=salesDf.dropna(subset=[ ],how=‘any’)
在dropna的函数中,sunset 设定为空集。以为不指定,表示对所有范围进行清除。但是实际执行时,如果为空,表示不执行数据集任何为空的行。因此需要重新制定,才能被正确清除。正确的代码如下:
salesDf=salesDf.dropna(subset=[‘销售时间’,‘社保卡号’],how=‘any’)
。执行的上述,后面的告警才正式消除。
- 数据索引的方式
DataFram 的数据进行索引时,经常使用loc的属性。加入要索引某列,使用的代码如下
data1.loc[:,列号索引]。而在实际应用中,如果写成data1[列号索引],是否有问题?
实际应用中,没有发现问题。而且通过id函数,发现这个两个指向是一个内存单元,可以理解为这两种索引方式是等价。
如下:

4.总结
本次主要学习《利用python进行数据分析》的知识学习。书中有对numpy,pandas,还有文件的读写进行初步讲解。由于主要进行基础性入门的讲解,对这两种数据格式有一个初步了解,对文件的操作,有一个大概认识。而要加深了解,还需要持续的学习和实践。
学习一个东西真的有难度,可能刚开始有一腔热血,但是能够在长期的枯燥中,还能不停的进步,不停的学习,这个才是难的。但是,也正是这样,人与人之间才能拉开距离。希望自己的通过不停的闯关,不停的进步,成为真正入门人工智能的人。或许因为是人工智能魅力,吸引着我往前走。
读者福利:知道你对Python感兴趣,便准备了这套python学习资料
[[CSDN大礼包:《python兼职资源&全套学习资料》免费分享]](安全链接,放心点击)
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习等习教程。带你从零基础系统性的学好Python!
零基础Python学习资源介绍
- ① Python所有方向的学习路线图,清楚各个方向要学什么东西
- ② 600多节Python课程视频,涵盖必备基础、爬虫和数据分析
- ③ 100多个Python实战案例,含50个超大型项目详解,学习不再是只会理论
- ④ 20款主流手游迫解 爬虫手游逆行迫解教程包
- ⑤ 爬虫与反爬虫攻防教程包,含15个大型网站迫解
- ⑥ 爬虫APP逆向实战教程包,含45项绝密技术详解
- ⑦ 超300本Python电子好书,从入门到高阶应有尽有
- ⑧ 华为出品独家Python漫画教程,手机也能学习
- ⑨ 历年互联网企业Python面试真题,复习时非常方便
Python学习路线汇总
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)

Python必备开发工具

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
Python学习视频600合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

100道Python练习题
检查学习结果。

面试刷题

python副业兼职与全职路线

上述这份完整版的Python全套学习资料已经上传CSDN官方,朋友们如果需要可以微信扫描下方CSDN官方认证二维码 即可领取↓↓↓
