spring相关的源码面试题
正文:
1.谈谈你对springIOC的理解?
2.简单描述下SpringBean的生命周期?
3.BeanFactory和FactoryBean有什么区别?
4.Spring中用到过哪些设计模式(最起码5种)?
5.BeanFactory和ApplicationContext的区别
6.谈谈你对循环依赖的理解
7.Spring的AOP的底层实现原理
8.Spring事务是如何回滚的?
9.谈谈Sptig事务传播特性的理解
正文:
1.谈谈你对springIOC的理解?
答案:
IoC是控制反转的意思,是一种面向对象编程的设计思想。在不采用这种思想的情况下,我们需要自己维护对象与对象之间的依赖关系,很容易造成对象之间的耦合度过高。尤其是在一个大型的项目中,对象与对象之间的关系是十分复杂的,这十分不利于代码的维护。IoC则可以解决这种问题,它可以帮我们维护对象与对象之间的依赖关系,并且降低对象之间的耦合度。
说到IoC就不得不说DI,DI是依赖注入的意思,它是IoC实现的实现方式。由于IoC这个词汇比较抽象而DI比较直观,所以很多时候我们就用DI来代替它,在很多时候我们简单地将IoC和DI划等号,这是一种习惯。
常用的DI注入就是 @Autowired @Resource
还会用一个方法就是: populateBean方法来完成属性注入
容器: 存储对象,使用map结构来存储对象;
在spring中存储对象的一般有:
1.一级缓存(singletonObjcts)存放完整对象
2.二级缓存(earlySingletonObjects)存放半成品对象
3.三级缓存(singletonFactory)存放lambada表达式和对象名称的yingshe
整个bean的声明周期,从创建到使用到销毁,各个环节都是由容器来帮我们控制的.
实现依赖注入的关键是IoC容器,它的本质就是一个工厂。
拓展:
Spring中所有的Bean都是通过反射生成的,bonstructor,newInstance
在整个流程中还包含了很多扩展点;
比如还有两个非常重要的接口:BeanFactoryPostProcessor,BeanPostProcessor用来实现扩展功能,aop就是在ioc的基础上的一个扩展实现,是通过BeanPostProcessor实现的.
ioc中除了创建对象之后还有一个重要的点,就是填充属性,(对接SpringBean的生命周期)
2.简单描述下SpringBean的生命周期?
先贴图(最好背下来):
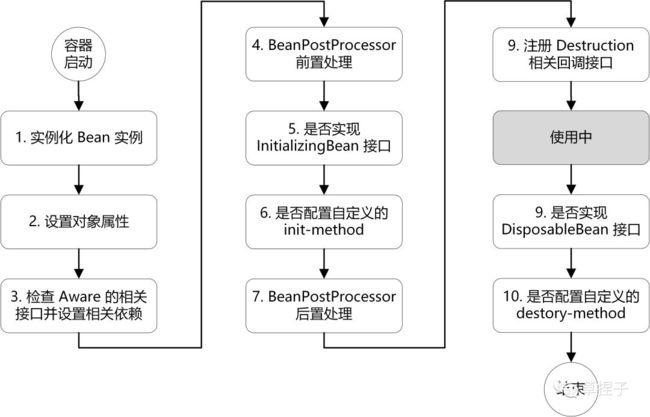
spring容器帮助我们去管理对象,从对象的产生到销毁的环节都有容器来控制.
其中主要包括实例化和初始化两个关键环节,
当然在整个过程中,会有一些扩展点的存在,下面来详细描述下各个环节和步骤:
1.实例化Bean对象,通过反射的方式来生成,在源码中有一个createBeanInstance的方法是专门来生成Bean对象的.
2.当Bean对象创建完成之后,对象的属性值都是默认值,所以要开始给Bean填充属性,通过populateBean方法来完成对象属性的填充,中间会升级到循环依赖的问题,后面详细说明.
3. 向Bean对象中设置容器属性,会调用ivokeAwareMethods方法来将容器对象设置到具体的Bean对象中.
4.调用BeanPostProcessor中的前置处理方法来进行bean对象的扩展工作,
ApplicationContextPostProcessor
EmbeddValueResolver等对象
5.调用invokelnitMethods方法来完成初始化方法的调用,在此方法处理过程中,需要判断当前Bean对象是否实现了InitializingBean接口,如果实现了调用afterPropertiesSet方法来最后设置Bean对象
6.调用BeanPOSTProcess的后置处理方法,完成对Bean对象的后置处理工作,aop就是在此处实现的,实现的接口实现名字叫做AbstractAutoProxyCreator
7.获取到完整对象,通过getBean的方式去进行对象的获取和使用
8.当对象使用完成之后,容器在关闭的时候,会销毁对象,调用首先会判断是否实现了DispoableBean
接口,然后去调用destroyMerhod方法.
3.BeanFactory和FactoryBean有什么区别?
BeanFactory和FactoryBean都可以用来创建对象,只不过创建的流程和方式不同
当使用BeanFactory的时候,必须严格遵守Bean的生命周期,经过一系列复杂的步骤之后才可以创建出单例对象,是流水式的创建过程.
而FactoryBean是用户可以自定义的Bean对象的创建流程,不需要按照Bean的生命周期来创建,在此接口中包含了三个方法.
1. isSingleton:判断是否是单例对象
2. getObjectType:获取对象的类型
3. getObject:在此方法中可以自己创建对象,使用new的方式或者使用代理的方式都可以,用户可以按照自己的需求随意去创建.在很多框架继承的时候都会实现FactoryBean接口,比如Feign.
4.Spring中用到过哪些设计模式(最起码5种)?
1.单例模式:spring中bean都是单例模式
2.工厂模式:BeanFactory
3.模板方法:postProcessorBeanFactory, onRefresh
4.观察者模式:listener,event,multicast
5.适配器模式:Adapter
6.装饰者模式:BeanWrapper
7.责任链模式:使用aop的时候会有一个责任链模式
8.代理模式:aop动态代理
9.委托者模式:delegate
10.建造者模式:buider
11.策略模式:XmlBeanDefinitionReader, PropertiesBeanDefinitionReader(替换if-else分支)
5.BeanFactory和ApplicationContext的区别
八股文:
BeanFactory是访问Spring容器的根接口,里面只是提供了某些基本方法的约束和规范,为了满足更多的需求.
ApplicationContext实现了此接口,在此接口的基础上做了某些扩展功能,提供了更加丰富的api调用,一般我们在使用的时候有applicationContext更多
牛客网:
BeanFactory:是基础类型的IoC容器,提供完整的IoC服务支持。如果没有特殊指定,默认采用延 迟初始化策略。只有当客户端对象需要访问容器中的某个受管对象的时候,才对该受管对象进行初始化以及依赖注入操作。所以,相对来说,容器启动初期速度较快,所需要的资源有限。对于资源有限,并且功能要求不是很严格的场景,BeanFactory是比较合适的IoC容器选择。
ApplicationContext:它是在BeanFactory的基础上构建的,是相对比较高级的容器实现,除了拥有BeanFactory的所有支持,ApplicationContext还提供了其他高级特性,比如事件发布、国际化信息支持等。
ApplicationContext所管理的对象,在该类型容器启动之后,默认全部初始化并绑定完成。所以,相对于BeanFactory来说,ApplicationContext要求更多的系统资源,同时,因为在启动时就完成所有初始化,容 器启动时间较之BeanFactory也会长一些。在那些系统资源充足,并且要求更多功能的场景中,ApplicationContext类型的容器 是比较合适的选择。
6.谈谈你对循环依赖的理解
什么是循环依赖?
A依赖B,B依赖A
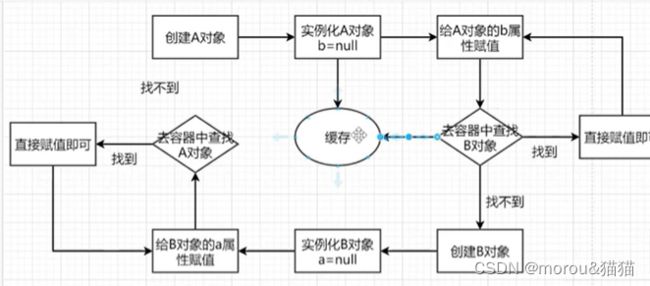
Spring中Bean对象的创建都要经历实例化,初始化(属性填充)的过程,通过将对象的状态分开,存在半成品和成品对象的方式,来分别进行初始化和实例化,成品和半成品在存储的时候需要分不同的缓存进行存储
1.只有一级缓存行不行? (singletonObjects 返回值: Map
不行,会把成品状态的Bean对象和半成品状态的Bean对象放到一起,而半成品对象是无法暴露给外部使用的,所以要将成品和办成品分开,一级缓存放成品对象,二级缓存存放半成品对象
2.只有二级缓存行不行? (earlySingletanObjects 返回值: Map
如果整个应用程序中不涉及Aop的存在,那么二级缓存中足以解决循环依赖的问题,
如果aop中存在了循环依赖,那么就必须要使用三级缓存才能解决,因为找不到代理对象了,需要用到三级缓存中的lambda表达式生成代理对象.
3.为什么需要三级缓存? (singletonFactories 返回值: Map
三级缓存的value类型是ObjectFactory,是一个函数接口,不是直接调用的,只有在调用getObject方法的时候才会去调用里面存储的lambda表达式,存在的意义是保证整个容器运行的过程中同名的Bean对象只能有一个.
拓展:
如果一个对象被代理或者锁需要生成代理对象,那么要不要先生成一个原始对象?
要
当创建出创建出代理对象后,会同时存在代理对象和普通对象,那么此时我应该用哪一个?
程序是死的,不知道用哪个对象
当需要代理对象的时候,或者说代理生成的时候必须要覆盖原始对象,也就是说 整个容器中有且只有一个Bean对象.
在实际调用的过程中,没有办法来确定什么时候对象需要被调用,因此当某个对象被调用的时候,优先判断当前对象是否需要被代理,类似于回调机制,当获取对象之后,根据传入的lambda表达式来确定返回的是哪一个确定的对象
如果条件符合,返回代理对象;
如果不符合,返回原始对象;
7.Spring的AOP的底层实现原理
AOP面向切面编程,将代码中重复的部分抽取出来,使用动态代理技术,在不修改源码的基础上对方法进行增强。
如果目标对象实现了接口,默认采用JDK动态代理,也可以强制使用CGLib,如果目标对象没有实现接口,采用CGLib的方式。
常用的场景包括权限认证、自动缓存、错误处理、日志、调试和事务等
8.Spring事务是如何回滚的?
spring的事务是由aop来实现的,首先要生成具体的代理对象,然后按照aop的整套流程来执行具体的操作逻辑,正常情况下要通过通知来完成核心功能,但是事务不能通过通知来实现的,而是通过一个TransactionInterceptor来实现的,然后调用invoke来实现具体的逻辑。
1.先做准备工作,解析各个方法上事务相关的属性,根据具体的属性来判断是否开启新事务。
2.当需要开启的时候,获取数据库连接,关闭自动提交功能,开启事务。
3.执行具体的sql逻辑操作
4.在操作的过程中,如果执行失败了,那么会通过completeTransactionAfterThrowing来完成事务的回滚操作,回滚具体的逻辑是通过doRollBack方法来实现的,实现的时候也是先获取连接对象,通过连接对象来回滚。
5.如果执行过程中,没有发生任何异常,那么会通过commitTransactionAfterReturning来完成事务的提交操作,提交的具体逻辑是通过doCommit方法来实现的,实现的时候也是先获取连接对象,通过连接对象提交。
6.当事务执行完毕之后需要清除相关的事务信息cleanupTransactionInfo
如果想要聊得更加细致的话,需要知道TransactionInfo,TransactionStatus
9.谈谈Sptig事务传播特性的理解
7种事务的传播机制:
REQUIRED(Spring默认的事务传播类型 required:需要、依赖、依靠):
如果当前没有事务,则自己新建一个事务,如果当前存在事务则加入这个事务
当A调用B的时候:如果A中没有事务,B中有事务,那么B会新建一个事务;如果A中也有事务、B中也有事务,那么B会加入到A中去,变成一个事务,这时,要么都成功,要么都失败。(假如A中有2个SQL,B中有两个SQL,那么这四个SQL会变成一个SQL,要么都成功,要么都失败)
SUPPORTS(supports:支持;拥护):
当前存在事务,则加入当前事务,如果当前没有事务,就以非事务方法执行
如果A中有事务,则B方法的事务加入A事务中,成为一个事务(一起成功,一起失败),如果A中没有事务,那么B就以非事务方式运行(执行完直接提交);
MANDATORY(mandatory:强制性的):
当前存在事务,则加入当前事务,如果当前事务不存在,则抛出异常。
如果A中有事务,则B方法的事务加入A事务中,成为一个事务(一起成功,一起失败);如果A中没有事务,B中有事务,那么B就直接抛异常了,意思是B必须要支持回滚的事务中运行
REQUIRES_NEW(requires_new:需要新建):
创建一个新事务,如果存在当前事务,则挂起该事务。
B会新建一个事务,A和B事务互不干扰,他们出现问题回滚的时候,也都只回滚自己的事务;
NOT_SUPPORTED(not supported:不支持):
以非事务方式执行,如果当前存在事务,则挂起当前事务
被调用者B会以非事务方式运行(直接提交),如果当前有事务,也就是A中有事务,A会被挂起(不执行,等待B执行完,返回);A和B出现异常需要回滚,互不影响
NEVER(never:从不):
如果当前没有事务存在,就以非事务方式执行;如果有,就抛出异常。就是B从不以事务方式运行
A中不能有事务,如果没有,B就以非事务方式执行,如果A存在事务,那么直接抛异常
NESTED(nested:嵌套的)
嵌套事务:如果当前事务存在,则在嵌套事务中执行,否则REQUIRED的操作一样(开启一个事务)
如果A中没有事务,那么B创建一个事务执行,如果A中也有事务,那么B会会把事务嵌套在里面。
拓展:
什么叫嵌套呢?
A是父事务,B是子事务
什么是事务?
事务就是用户定义的一系列数据库操作,这些操作可以视为一个完成的逻辑处理工作单元,要么全部执行,要么全部不执行,是不可分割的工作单元。对数据库的增删改查操作
传播机制是什么?
当A调用B的时候,两个事务是怎么运行的?
A出现异常,或者B出现异常,A回不回滚,B回不回滚?还是A回滚,B不回滚?
这些问题
事务 以非事务性方式运行是什么意思?
非事务的方式运行,其实就是设置为自动提交了,如果一个方法中有多个操作,则每个操作都会在不同事务中完成,不会保证他们的原子性。
事务挂起是什么意思?
在方法A开始运行时,系统为它建立Transaction(“全赞可凶弄”),方法A中对于数据库的处理操作,会在该Transaction的控制之下。
这时,方法A调用方法B,方法A打开的 Transaction将挂起,方法B中任何数据库操作,都不在该Transaction的管理之下。
当方法B返回,方法A继续运行,之前的Transaction回复,后面的数据库操作继续在该Transaction的控制之下 提交或回滚。