Flink CDC MongoDB Connector 的实现原理和使用实践
本文整理自 XTransfer 资深 Java 开发工程师、Flink CDC Maintainer 孙家宝在 Flink CDC Meetup 的演讲。主要内容包括:
- MongoDB Change Stream 技术简介
- MongoDB CDC Connector 业务实践
- MongoDB CDC Connector 生产调优
- MongoDB CDC Connector 并行化 Snapshot 改进
- 后续规划
点击查看直播回放 & 演讲PDF
一、MongoDB Change Stream 技术简介

MongoDB 是一种面向文档的非关系型数据库,支持半结构化数据存储;也是一种分布式的数据库,提供副本集和分片集两种集群部署模式,具有高可用和水平扩展的能力,比较适合大规模的数据存储。另外, MongoDB 4.0 版本还提供了多文档事务的支持,对于一些比较复杂的业务场景更加友好。

MongoDB 使用了弱结构化的存储模式,支持灵活的数据结构和丰富的数据类型,适合 Json 文档、标签、快照、地理位置、内容存储等业务场景。它天然的分布式架构提供了开箱即用的分片机制和自动 rebalance 能力,适合大规模数据存储。另外, MongoDB 还提供了分布式网格文件存储的功能,即 GridFS,适合图片、音频、视频等大文件存储。

MongoDB 提供了副本集和分片集两种集群模部署模式。
副本集:高可用的部署模式,次要节点通过拷贝主要节点的操作日志来进行数据的复制。当主要节点发生故障时,次要节点和仲裁节点会重新发起投票来选出新的主要节点,实现故障转移。另外,次要节点还能分担查询请求,减轻主要节点的查询压力。
分片集:水平扩展的部署模式,将数据均匀分散在不同 Shard 上,每个 Shard 可以部署为一个副本集,Shard 中主要节点承载读写请求,次要节点会复制主要节点的操作日志,能够根据指定的分片索引和分片策略将数据切分成多个 16MB 的数据块,并将这些数据块交给不同 Shard 进行存储。Config Servers 中会记录 Shard 和数据块的对应关系。

MongoDB 的 Oplog 与 MySQL 的 Binlog 类似,记录了数据在 MongoDB 中所有的操作日志。Oplog 是一个有容量的集合,如果超出预设的容量范围,则会丢弃先前的信息。

与 MySQL 的 Binlog 不同, Oplog 并不会记录变更前/后的完整信息。遍历 Oplog 的确可以捕获 MongoDB 的数据变更,但是想要转换成 Flink 支持的 Changelog 依然存在一些限制。
首先,订阅 Oplog 难度较大。每个副本集会维护自己的 Oplog, 对于分片集群来说,每个 Shard 可能是一个独立的副本集,需要遍历每个 Shard 的 Oplog 并按照操作时间进行排序。另外, Oplog 没有包含变更文档前和变更后的完整状态,因此既不能转换成 Flink 标准的 Changelog ,也不能转换成 Upsert 类型的 Changelog 。这亦是我们在实现 MongoDB CDC Connector 的时候没有采用直接订阅 Oplog 方案的主要原因。
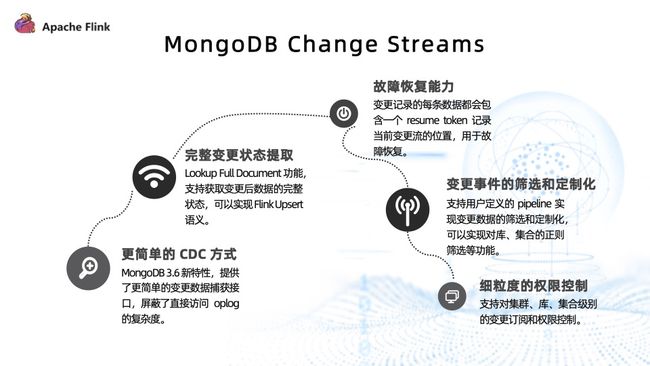
最终我们选择使用 MongoDB Change Streams 方案来实现 MongoDB CDC Connector。
Change Streams 是 MongoDB 3.6 版本提供的新特性,它提供了更简单的变更数据捕获接口,屏蔽了直接遍历 Oplog 的复杂度。Change Streams 还提供了变更后文档完整状态的提取功能,可以轻松转换成 Flink Upsert 类型的 Changelog。它还提供了比较完整的故障恢复能力,每一条变更记录数据都会包含一个 resume token 来记录当前变更流的位置。故障发生后,可以通过 resume token 从当前消费点进行恢复。
另外, Change Streams 支持变更事件的筛选和定制化的功能。比如可以将数据库和集合名称的正则过滤器下推到 MongoDB 来完成,可以明显减少网络开销。它还提供了对集合库以及整个集群级别的变更订阅,能够支持相应的权限控制。
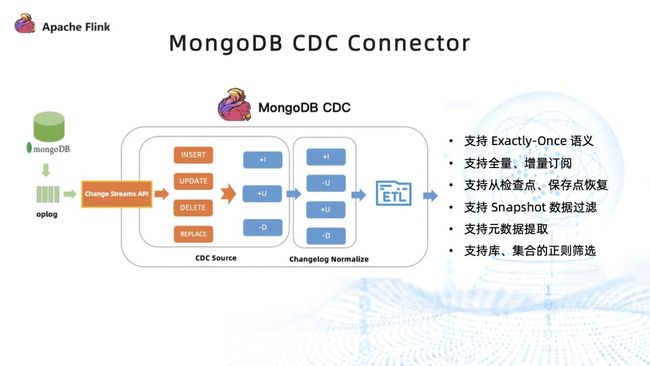
使用 MongoDB Change Streams 特性实现的 CDC Connector 如上图所示。首先通过 Change Streams 订阅 MongoDB 的变更。比如有 insert、update、delete、replace 四种变更类型,先将其转换成 Flink 支持的 upsert Changelog,便可以在其之上定义成一张动态表,使用 Flink SQL 进行处理。
目前 MongoDB CDC Connector 支持 Exactly-Once 语义,支持全量加增量的订阅,支持从检查点、保存点恢复,支持 Snapshot 数据的过滤,支持数据库的 Database、Collection 等元数据的提取,也支持库集合的正则筛选功能。
二、MongoDB CDC Connector 业务实践

XTransfer 成立于 2017 年,聚焦于 B2B 跨境支付业务,为从事跨境电商出口的中小微企业提供外贸收款以及风控服务。跨境 B 类业务结算场景涉及的业务链路很长,从询盘到最终的成交,过程中涉及物流条款、支付条款等,需要在每个环节上做好风险管控,以符合跨境资金交易的监管要求。
以上种种因素对 XTransfer 的数据处理安全性和准确性都提出了更高的要求。在此基础上,XTransfer 基于 Flink 搭建了自己的大数据平台,能够有效保障在跨境 B2B 全链路上的数据能够被有效地采集、加工和计算,并满足了高安全、低延迟、高精度的需求。
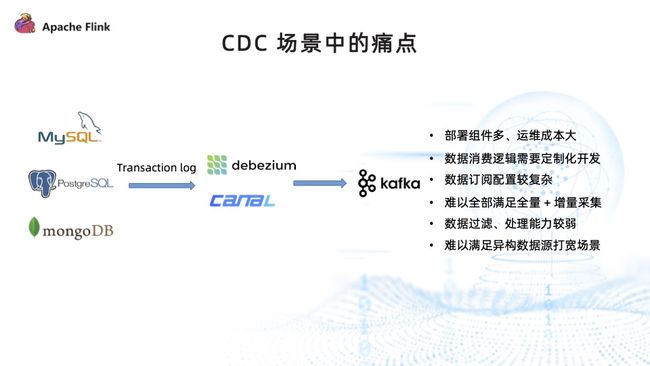
变更数据采集 CDC 是数据集成的关键环节。在没有使用 Flink CDC 之前,一般使用 Debezium、Canal 等传统 CDC 工具来抽取数据库的变更日志,并将其转发到 Kafka 中,下游读取 Kafka 中的变更日志进行消费。这种架构存在以下痛点:
- 部署组件多,运维成本较高;
- 下游数据消费逻辑需要根据写入端进行适配,存在一定的开发成本;
- 数据订阅配置较复杂,无法像 Flink CDC 一样仅通过 SQL 语句便定义出一个完整的数据同步逻辑;
- 难以全部满足全量 + 增量采集,可能需要引入 DataX 等全量采集组件;
- 比较偏向于对变更数据的采集,对数据的处理过滤能力较为薄弱;
- 难以满足异构数据源打宽的场景。
目前我们的大数据平台主要使用 Flink CDC 来进行变更数据捕获,它具有如下优势:
1. 实时数据集成
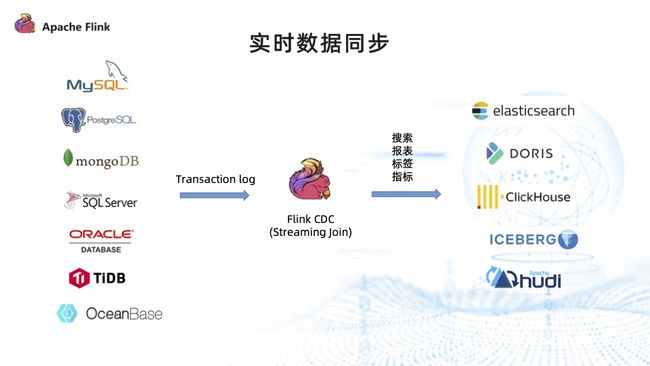
- 无须额外部署 Debezium、Canal、Datax 等组件,运维成本大幅降低;
- 支持丰富的数据源,也可复用 Flink 既有的 connectors 进行数据采集写入,可以覆盖大多数业务场景;
- 降低了开发难度,仅通过 Flink SQL 就可以定义出完整的数据集成工作流程;
- 数据处理能力较强,依托于 Flink 平台强大的计算能力可以实现流式 ETL 甚至异构数据源的 join、group by 等。
2. 构建实时数仓
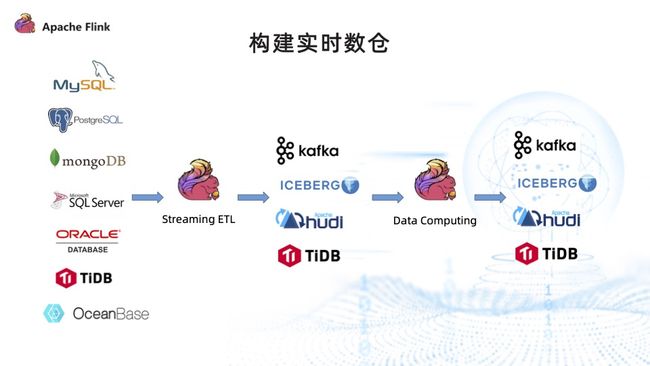
- 大幅简化实时数仓的部署难度,通过 Flink CDC 实时采集数据库的变更,并写入 Kafka、Iceberg、Hudi、TiDB 等数据库中,即可使用 Flink 进行深度的数据挖掘和数据处理。
- Flink 的计算引擎可以支持流批一体的计算模式,不用再维护多套计算引擎,可以大幅降低数据的开发成本。
3. 实时风控
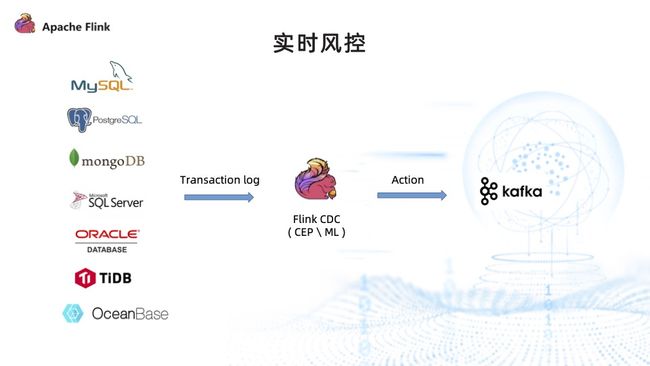
- 实时风控以往一般采取往 Kafka 中发业务事件的方式实现,而使用 Flink CDC 之后,可以直接从业务库中捕获风控事件,然后通过 Flink CDC 来进行复杂的事件处理。
- 可以运行模型,以通过 Flink ML、Alink 来丰富机器学习的能力。最后将这些实时风控的处置结果回落进 Kafka,下达风控指令。
三、MongoDB CDC Connector 生产调优

MongoDB CDC Connector 的使用有如下几点要求:
- 鉴于使用了 Change Streams 的特性来实现 MongoDB CDC Connector, 因此要求 MongoDB 的最小可用版本是 3.6,比较推荐 4.0.8 及以上版本。
- 必须使用集群部署模式。由于订阅 MongoDB 的 Change Streams 要求节点之间能够进行相互复制数据,单机 MongoDB 无法进行数据的互相拷贝,也没有 Oplog,只有副本集或分片集的情况下才有数据复制机制。
- 需要使用 WireTiger 存储引擎,使用 pv1 复制协议。
- 需要拥有 ChangeStream 和 find 用户权限。

使用 MongoDB CDC Connector 时要注意设置 Oplog 的容量和过期时间。MongoDB oplog 是一个特殊的有容量集合,容量达到最大值后,会丢弃历史数据。而 Change Streams 通过 resume token 来进行恢复,太小的 oplog 容量可能会导致 resume token 对应的 oplog 记录不再存在,即 resume token 过期,进而导致 Change Streams 无法被恢复。
可以使用 replSetResizeOplog 设置 oplog 容量和最短保留时间,MongoDB 4.4 版本之后也支持设置最小时间。一般而言,生产环境中建议 oplog 保留不小于 7 天。

对一些变更较慢的表,建议在配置中开启心跳事件。变更事件和心跳事件可以同时向前推进 resume token,对于变更较慢的表,可以通过心跳事件来刷新 resume token 避免其过期。
可以通过 heartbeat.interval.ms 设置心跳的间隔。
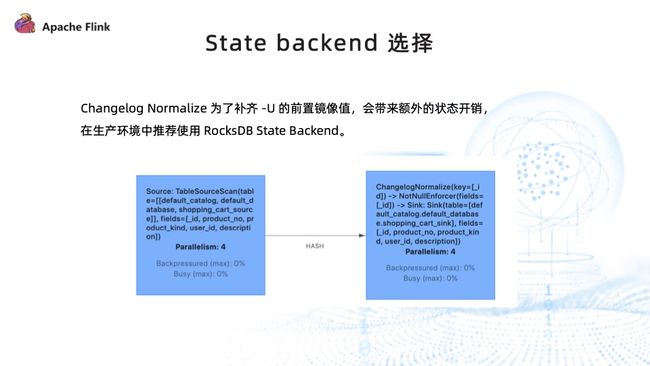
由于只能将 MongoDB 的 Change Streams 转换成 Flink 的 Upsert changelog,它类似于 Upsert Kafka 形式,为了补齐 –U 前置镜像值,会增加一个算子 ChangelogNormalize,而这会带来额外的状态开销。因此在生产环境中比较推荐使用 RocksDB State Backend。

当默认连接的参数无法满足使用需求时,可以通过设置 connection.options 配置项来传递 MongoDB 支持的连接参数。
比如连接 MongoDB 的用户创建的数据库不在 admin 中,可以设置参数来指定需要使用哪个数据库来认证当前用户,也可以设置连接池的最大连接参数等,MongoDB 的连接字符串默认支持这些参数。

正则匹配多库、多表是 MongoDB CDC Connector 在 2.0 版本之后提供的新功能。需要注意,如果数据库名称使用了正则参数,则需要拥有 readAnyDatabase 角色。因为 MongoDB 的 Change Streams 只能在整个集群、数据库以及 collection 粒度上开启。如果需要对整个数据库进行过滤,那么数据库进行正则匹配时只能在整个集群上开启 Change Streams ,然后通过 Pipeline 过滤数据库的变更。可以通过在 Ddatabase 和 Collection 两个参数中写入正则表达式进行多库、多表的订阅。
四、MongoDB CDC Connector 并行化 Snapshot 改进

为了加速 Snapshot 的速度,可以使用 Flip-27 引入的 source 来进行并行化改造。首先使用一个 split 枚举器,根据一定的切分策略,将一个完整的 Snapshot 任务拆分成若干个子任务,然后分配给多个 split reader 并行做 Snapshot ,以此提升整体任务的运行速度。
但是在 MongoDB 里,大多情况下组件是 ObjectID,其中前面四个字节是 UNIX 描述,中间五个字节是一个随机值,后面三个字节是一个自增量。在相同描述里插入的文档并不是严格递增的,中间的随机值可能会影响局部的严格递增,但从总体来看,依然能够满足递增趋势。
因此,不同于 MySQL 的递增组件,MongoDB 并不适合采用 offset + limit 的切分策略对其集合进行简单拆分,需要针对 ObjectID 采用针对性的切分策略。

最终,我们采取了以下三种 MongoDB 切分策略:
- Sample 采样分桶:原理是利用 $sample 命令对 collection 进行随机采样,通过平均文档大小和每个 chunk 的大小来预估需要的分桶数。要求相应集合的查询权限,其优点是速度较快,适用于数据量大但是没有分片的集合;缺点是由于使用了抽样预估模式,分桶的结果不能做到绝对均匀。
- SplitVector 索引切分:SplitVector 是 MongoDB 计算 chunk 分裂点的内部命令,通过访问指定的索引计算出每个 chunk 的边界。要求拥有 SplitVector 权限,其优点是速度快,chunk 结果均匀;缺点是对于数据量大且已经分片的集合,不如直接读取 config 库中已经分好的 chunks 元数据。
- Chunks 元数据读取:因为 MongoDB 在 config 数据库会存储分片集合的实际分片结果,因此可以直接从 config 中读取分片集合的实际分片结果。要求拥有 config 库读取权限,仅限于分片集合使用。其优点是速度快,无须重新计算 chunk 分裂点,chunk 结果均匀,默认情况下为 64MB;缺点是不能满足所有场景,仅限分片场景。

上图为 sample 采样分桶示例。左侧是一个完整的集合,从完整的集合中设定样本数量,然后将整个样本缩小,并根据采样以后的样本进行分桶,最终结果就是我们希望的 chunks 边界。
sample 命令是 MongoDB 采样的一个内置命令。在样本值小于 5% 的情况下,使用伪随机算法进行采样;样本值大于 5% 的情况下,先使用随机排序,然后选择前 N 个文档。它的均匀度和耗时主要取决于随机算法和样本的数量,是一种均匀程度和切分速度的折中策略,适合于要求切分速度快,但可以容忍切分结果不太均匀的场景。
在实际测试中,sample 采样的均匀程度有着不错的表现。
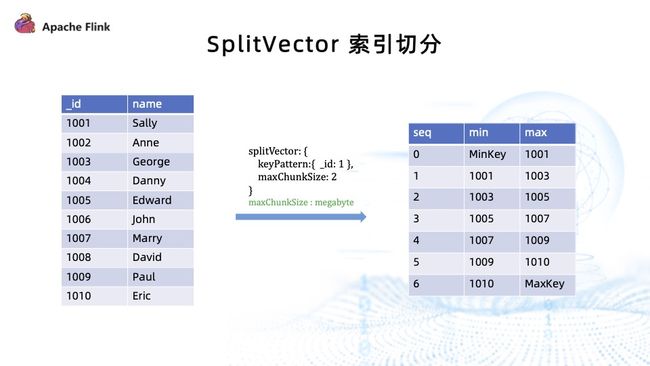
上图为 SplitVector 索引切分示例。左侧是原始集合,通过 SplitVector 命令指定需要访问的索引,为 ID 索引。可以设置每个 chunk 的大小,单位为 MB,然后使用 SplitVector 命令访问索引,并通过索引计算每个块的边界。
它速度快,chunk 结果也很均匀,适用于大部分场景。

上图为 config.chuncks 读取示例,即直接读取 MongoDB 已经分好的 chunks 元数据。在 Config Server 中会存储每个 Shard、其所在机器以及每个 Shard 的边界。对于分片集合,可以直接在 chunks 中读取它的边界信息,无须重复计算这些分裂点,也可以保证每一个 chunk 的读取在单台机器上就能完成,速度极快,在大规模的分片集合场景下有着很好的表现。
五、后续规划

Flink CDC 的后续规划主要分为以下五个方面:
- 第一,协助完善 Flink CDC 增量 Snapshot 框架;
- 第二,使用 MongoDB CDC 对接 Flink CDC 增量 Snapshot 框架,使其能够支持并行 Snapshot 改进;
- 第三,MongoDB CDC 支持 Flink RawType。对于一些比较灵活的存储结构提供 RawType 转换,用户可以通过 UDF 的形式对其进行自定义解析;
- 第四,MongoDB CDC 支持从指定位置进行变更数据的采集;
- 第五,MongoDB CDC 稳定性的优化。
问答
Q:MongoDB CDC 延迟高吗?是否需要通过牺牲性能来降低延迟?
A:MongoDB CDC 延迟不高,在全量采集的时候经过 changelog normalize 可能会对于 CDC 的增量采集造成一些背压,但是这种情况可以通过 MongoDB 并行化改造、增加资源的方式来避免。
Q:默认连接什么时候无法满足要求?
A:MongoDB 的用户可以在任何数据库、任何子库中进行创建。如果不是在 admin 的数据库中创建用户,认证的时候需要显示地指定要在哪个数据库中认证用户,也可以设置最大的连接大小等参数。
Q:MongoDB 目前的 DBlog 支持无锁并发读取吗?
A:DBlog 的无锁并发拥有增量快照的能力,但是因为 MongoDB 难以获取当前 changelog 的位点,所以增量快照无法立刻实现,但无锁并发的 Snapshot 即将支持。