【C++】-- STL之String详解
目录
一、STL简介
二、string类
1.string类定义
2.string类对象构造
3.string元素访问符
4.string迭代器
5.string插入和拼接
(1)string插入
(2)字符串拼接
6.string删除
7.string容量
(1)求字符串个数
(2)判空
(3)容量
(4)调整字符串大小
(5)调整字符串容量
8.string字符串操作
(1)获取c形式字符串
(2)查找
(3)查找子串
(4)反向查找
9.string字符串比较
三、string OJ题
1.仅仅反转字母 OJ链接
2.字符串里面最后一个单词的长度 OJ链接
3.验证回文串 OJ链接
4.字符串相加 OJ链接


一、STL简介
STL(standard template libaray-标准模板库):是C++标准库的重要组成部分,不仅是一个可复用的组件库,而且是一个包罗数据结构与算法的软件框架。
模板是C++程序设计语言中的一个重要特征,而标准模板库正是基于此特征。标准模板库使得C++编程语言在有了强大的类库的同时,保有了更大的可扩展性。
STL有6大组件:

其中,容器、算法、迭代器、函数是很重要的部分,有了STL,许多底层的数据结构以及算法都不需要自己重新造轮子,站在前人的肩膀上,肯定飞的更快嘛。
二、string类
1.string类定义
C语言中,字符串是以'\0'结尾的一些字符的集合。为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合面向对象的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。
因此C++的标准库中定义了string类:
(1)string是表示字符串的字符串类
(2)该类的接口与常规容器的接口基本相同,再添加了一些专门用来操作string的常规操作。
(3)string在底层实际是:basic_string模板类的别名,typedef basic_string
(4)不能操作多字节或者变长字符的序列。
2.string类对象构造
string()//构造空字符串
string(const char* s);//拷贝s所指向的字符串序列
string(const char* s, size_t n);//拷贝s所指向的字符串序列的第n个到结尾的字符
string(size_t n, char c);//将字符c复制n次
string(const string& str);//拷贝构造函数
string(const string& str, size_t pos, size_t len = npos);//拷贝s中从pos位置起的len个字符,若npos>字符串长度,就拷贝到字符串结尾结束如下所示:
#include
#include
using namespace std;
int main()
{
string s0 = "Hello World";
string s1(); //构造空字符串
string s2("good start");//拷贝s0所指向的字符串序列(隐式类型转换,先构造再拷贝构造,被编译器优化成直接构造)
string s3(s0,1);//拷贝s0所指向的字符串序列的第1个到结尾的字符
string s4(5, 'h');//将字符'h'复制5次
string s5(s0);//用s0拷贝构造s5
string s6(s0,2,30);//拷贝s0中从第2个位置起的30个字符,拷贝到字符串结尾就结束了
cout << "s2:" << s2 << endl;
cout << "s3:" << s3 << endl;
cout << "s4:" << s4 << endl;
cout << "s5:" << s5 << endl;
cout << "s6:" << s6 << endl;
return 0;
} 
3.string元素访问符
char& operator[] (size_t pos);//返回pos位置字符的引用,字符串可读可写,[]重载了operator[]
reference at(size_type pos);//同char& operator[],返回pos位置字符的引用,字符串可读可写#include
#include
using namespace std;
int main()
{
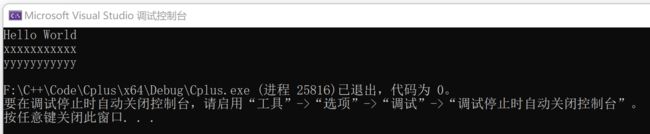
string s0 = "Hello World";
for (size_t i = 0; i < s0.size(); i++)
{
s0[i] = 'x';//使用operator[]访问字符串元素
cout << s0[i];
}
cout << endl;
for (size_t i = 0; i < s0.size(); i++)
{
s0.at(i) = 'y';//使用at访问字符串元素
cout << s0[i];
}
cout << endl;
return 0;
} 
[ ]和at的区别在于,[ ]的越界报断言错,而at的越界抛异常。
4.string迭代器
string、vector支持[ ]遍历,但是list、map等容器不支持[ ]遍历,迭代器是一种可以统一使用的遍历方式。迭代器是类似于指针。
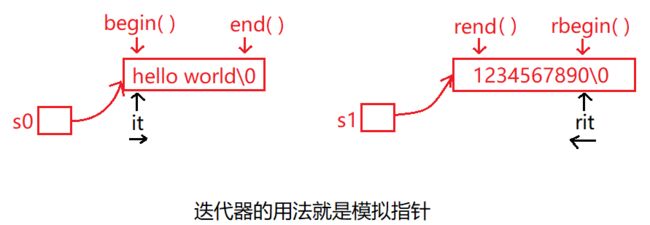
iterator begin(); //返回指向字符串第一个字符的迭代器
iterator end(); //返回指向字符串最后一个字符的下一个位置的迭代器
reverse_iterator rbegin(); //返回字符串最后一个字符的反向迭代器
reverse_iterator rend(); //返回指向字符串第一个字符之前的反向迭代器begin和end是正向迭代器,rbegin和rend是反向迭代器:
#include
#include
using namespace std;
int main()
{
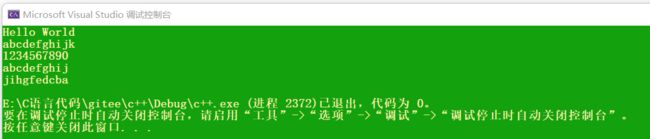
//正向迭代器
string s0 = "Hello World";
cout << s0 << endl;
string::iterator it = s0.begin();
char ch0 = 'a';
while (it != s0.end())
{
*it = ch0;
ch0++;
cout << *it;
it++;
}
cout << endl;
//反向迭代器
string s1("1234");
cout << s1 << endl;
string::reverse_iterator rit = s1.rbegin();
char ch1 = 'a';
while (rit != s1.rend())
{
//从右向左依次赋值
*rit = ch1;
ch1++;
cout << *rit;
rit++;
}
cout << endl;
cout << s1 << endl;
return 0;
} 
范围for
范围for也可以实现遍历:依次取容器中的数据赋值给e,自动判断结束
for(auto& e:s)
{}取s的值赋值给e,e是s的拷贝,因此加引用,如果不加引用,就只能对s读,不能对s写。auto是自动推导,使用方便:
for (auto& e : s1)
{
e += 1;
}
cout << s1 << endl;
5.string插入和拼接
(1)string插入
①在字符串末尾插入
void push_back (char c); //向字符串末尾追加一个字符②在指定位置插入
string& insert(size_t pos, const string& str);//插入字符串拷贝
string& insert (size_t pos, const char* s);//插入c形式的字符串
string& insert (size_t pos, const char* s, size_t n);//将字符串s的前n个字符插到pos位置#include
#include
using namespace std;
int main()
{
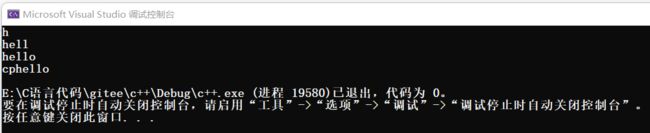
string s0("");
s0.push_back('h');//s0尾插h
cout << s0 << endl;
string s1("ell");
s0.insert(1, s1);//在下标为1的位置插入s1的拷贝
cout << s0 << endl;
s0.insert(4, "o");//在下标为4的位置插入字符串o
cout << s0 << endl;
s0.insert(0, "cplusplus",2);//在下标为0的位置插入"cplusplus"的前2个字符
cout << s0 << endl;
return 0;
} 
(2)字符串拼接
①使用append进行拼接
string& append (const string& str); //向字符串对象末尾追加字符串
string& append (const char* s);//向字符串末尾追加字符
string& append(size_t n, char c);//向字符串末尾追加n个相同字符#include
#include
using namespace std;
int main()
{
string s0("");
s0.append("hello");//将hello追加到s0末尾
cout << s0 << endl;
string s1 = " world";
s0.append(s1);//s0.append(s1.begin().s1.end());//将字符串s1追加到s0末尾
cout << s0 << endl;
s0.append(3, '!');//想s0末尾追加3个!
cout << s0 << endl;
//用+=追加很方便,比append更常用
s0 += '!';
s0 += " yes";
string s2 = " it is.";
s0 += s2;
cout << s0 << endl;
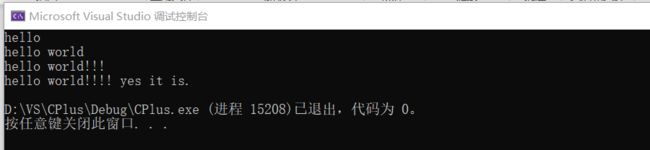
} 
②使用全局函数operator+拼接
string operator+ (const string& lhs, const string& rhs);//拼接lhs和rhs#include
#include
using namespace std;
int main()
{
string s1 = "cplusplus";
string s2 = ".com";
string s3 = s1 + s2;
cout << s3 << endl;
return 0;
} 
6.string删除
string& erase (size_t pos = 0, size_t len = npos);//从第pos个位置开始删除len个字符,pos缺省为0#include
#include
using namespace std;
int main()
{
string s0 = "cplusplus.com";
s0.erase(2, 2);
cout << s0 << endl;
s0.erase(2, 100);//len超过字符串长度也不会报错,npos为-1,转换成无符号数为4294967295,100远远小于这个数,因此不会报错
cout << s0 << endl;
unsigned int a = - 1;
printf("%u", a);
return 0;
} 
7.string容量
(1)求字符串个数
size_t size() const;//size()求字符串中有效字符的个数
size_t length() const;//length()求字符串中有效字符的个数size( )和length( )没有区别
#include
#include
using namespace std;
int main()
{
string s1;
cout << s1.size() << endl;
cout << s1.length() << endl;
return 0;
} 
(2)判空
bool empty() const;//判断字符串是否为空 string s1;
cout << s1.empty() << endl;
(3)容量
size_t capacity() const;//返回所分配内存的字节数 string s1("cplusplus.com");
cout << s1.size() << endl;
cout << s1.capacity() << endl;capcity( )比size( )大,要给'\0'留空间:

(4)调整字符串大小
只调整字符串大小,不填充内容
void resize (size_t n);//将字符串大小调整为n个字符的长度,默认插入字符'\0',32位机器一般为4的倍数,64位机器一般为8的倍数,一般按2倍去调整 string s1("cplusplus.com");
s1.resize(20);
cout << s1.size() << endl;
cout << s1.capacity() << endl;
F10-调试-窗口-监视,在resize之前,size为13个字节,13个字节全部都是有效字符:

resize之后,size为20个字节, 且新增的空间全部赋值为'\0' :

②调整字符串大小,并将增加的空间内容初始化成给定字符
void resize (size_t n, char c);//将字符串大小调整为n个字符的长度,初始化新增空间的内容为c string s1("cplusplus.com");
s1.resize(20, 'c');
cout << s1 << endl;
s1.resize(6);
cout << s1 << endl;监视:执行完s1.resize(20, 'c');后:
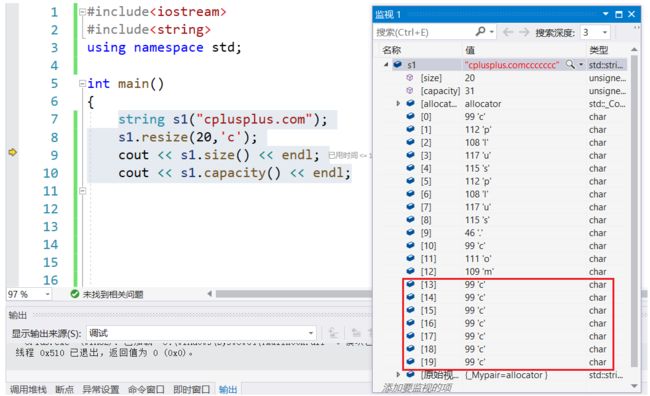
执行完s1.resize(6);后:

(5)调整字符串容量
void reserve (size_t n = 0);//调整容量,缺省容量为0 string s1("cplusplus.com");
s1.reserve(20);
cout << "size:" << s1.size() << endl;
cout << "capacity" << s1.capacity() << endl;
s1.reserve(50);
cout << "size:" << s1.size() << endl;
cout << "capacity" << s1.capacity() << endl;第二次reserve 之后的容量变成了63,是第一次reserve之后容量的2倍:
 用一个循环查看如何增容:
用一个循环查看如何增容:
#include
#include
using namespace std;
int main()
{
string s1;
int oldCapacity = s1.capacity();
for (char ch = 0; ch < 127; ch++)
{
s1 += ch;
if (oldCapacity != s1.capacity())
{
cout << "增容:" << oldCapacity << "->" << s1.capacity() << endl;
oldCapacity = s1.capacity();
}
}
cout << s1 << endl;
return 0;
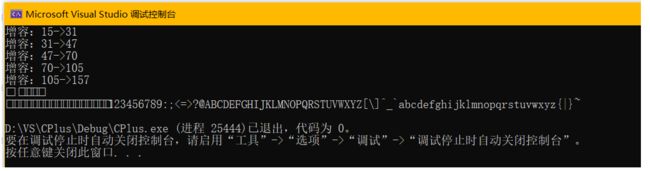
} 
如果一开始使用reserve就把容量调整为127,发现reserve没有增容:
#include
#include
using namespace std;
int main()
{
string s1;
s1.reserve(127);
int oldCapacity = s1.capacity();
for (char ch = 0; ch < 127; ch++)
{
s1 += ch;
if (oldCapacity != s1.capacity())
{
cout << "增容:" << oldCapacity << "->" << s1.capacity() << endl;
oldCapacity = s1.capacity();
}
}
cout << s1 << endl;
return 0;
} 监视:


如果一开始使用resize将容量调整为127,发现增容了:
#include
#include
using namespace std;
int main()
{
string s1;
s1.resize(127);
int oldCapacity = s1.capacity();
for (char ch = 0; ch < 127; ch++)
{
s1 += ch;
if (oldCapacity != s1.capacity())
{
cout << "增容:" << oldCapacity << "->" << s1.capacity() << endl;
oldCapacity = s1.capacity();
}
}
cout << s1 << endl;
return 0;
} 监视:


为什么reserve( )没有增容,而resize( )增容了?
这是因为+=操作符实在字符串末尾插入,执行完s1.reserve(127);之后,size是0:

数据个数为0,+=直接往字符串中挨个插入。
而执行完s1.resize(127);之后,size是127:
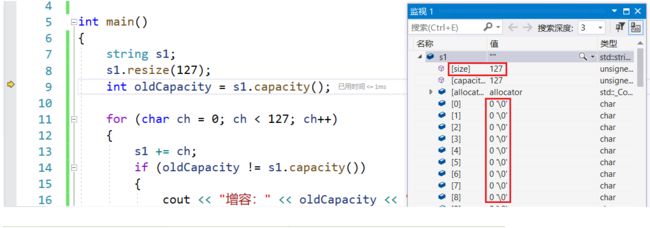
resize( )给前127个位置插入了'\0',数据个数已经是127了,+=从第128位置向后插入,而第128位置需要增容,所以resize( )第一次增容的位置是从128开始的(因为127位置存放的是'\0'),先增了64个字节,再增了95个字节。
对于不同平台的增容,每次所增容量不一定相同,因为它们的底层如何实现增容,不同的平台实现不同,linux的增容就和VS不同:
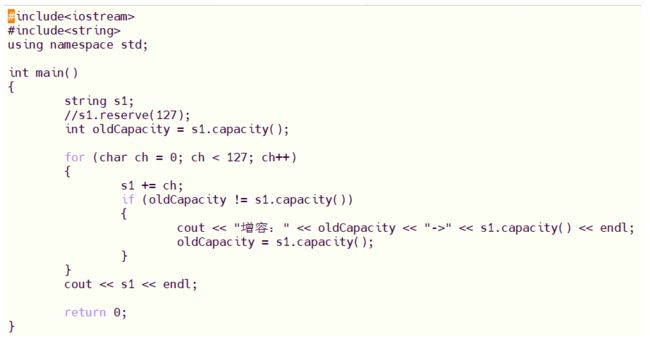
8.string字符串操作
(1)获取c形式字符串
const char* c_str() const;//将 const string* 类型 转化为 const char* 类型#include
#include
using namespace std;
int main()
{
string s1("cplusplus");
s1.resize(30);
s1 += "!!!";
string s2 = s1.c_str();
cout << s1.size() << endl;
cout << s2.size() << endl;
return 0;
} 监视:s1 resize之后,在末尾插入"!!!",需要重新开空间:

而s1的c形式字符串,遇到第一个'\0'就截止了:
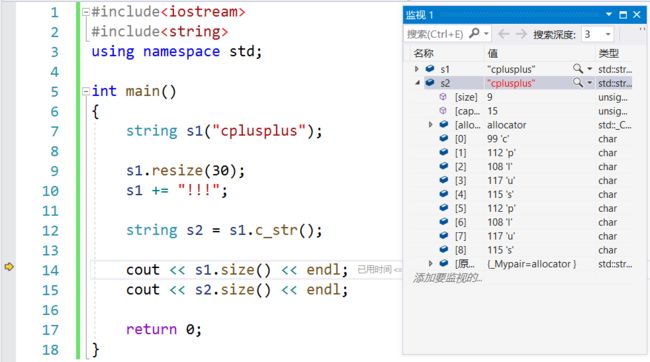

(2)查找
size_t find(const string & str, size_t pos = 0) const;//返回在给定字符串中查找字符串str第一次出现的位置
size_t find(const char* s, size_t pos = 0) const;//返回在给定字符串中从下标为pos的位置开始查找字符串s第一次出现的位置
size_t find(const char* s, size_t pos, size_t n) const;//返回在给定字符串中从下标为pos的位置开始查找字符串s的前n个字符第一次出现的位置
size_t find(char c, size_t pos = 0) const;//返回在给定字符串中从下标为pos的位置开始查找字符c第一次出现的位置#include
#include
using namespace std;
int main()
{
string s1("cplusplus.co");
cout << s1.find("lu") << endl;//返回在s1中查找字符串"lu"第一次出现的位置
cout << s1.find("lu", 3) << endl;//返回在s1中从下标为3的位置开始查找字符串"lu"第一次出现的位置
cout << s1.find('.', 3) << endl;//返回在s1中从下标为3的位置开始查找字符"."第一次出现的位置
cout << s1.find("com", 3, 2) << endl;//返回在s1中从下标为3的位置开始查找字符串"com"的前2个字符第一次出现的位置
//取出文件名的后缀
string filename = "main.cpp";
size_t pos = filename.find('.');
if (pos != string::npos)
{
string buff(filename, pos);
cout << buff << endl;
}
return 0;
} 
(3)查找子串
string substr (size_t pos = 0, size_t len = npos) const;//截取给定字符串中从第pos个位置开始的len个长度的字符成员函数const修饰的是*this,本质是保护成员变量在函数体内不会被改变,相当于this指向的对象成员被保护,不能修改。
#include
#include
using namespace std;
//获取域名
string getDomain(const string& url)
{
size_t pos = url.find("://");
if (pos != string::npos)
{
size_t start = pos + 3;
size_t end = url.find('/', start);
if (end != string::npos)
{
return url.substr(start, end-start);
}
else
{
return string();//返回一个匿名对象
}
}
else
{
return string();
}
}
//获取协议名
string getProtocal(const string& url)
{
size_t pos = url.find("://");
if (pos != string::npos)
{
return url.substr(0, pos);
}
else
{
return string();
}
}
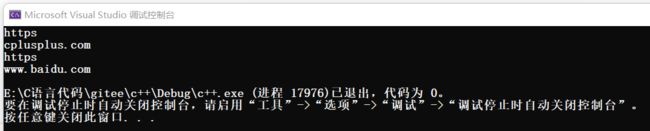
int main()
{
//获取URL中的域名和协议名
string url1 = "https://cplusplus.com/reference/string/string/rfind/";
cout << getProtocal(url1) << endl;
cout << getDomain(url1) << endl;
string url2 = "https://www.baidu.com/";
cout << getProtocal(url2) << endl;
cout << getDomain(url2) << endl;
return 0;
} 
(4)反向查找
size_t rfind(const string & str, size_t pos = npos) const;//从右向左在给定字符串中查找字符串str第一次出现的位置
size_t rfind(const char* s, size_t pos = npos) const;//从右向左在给定字符串中下标为pos的位置开始查找字符串s第一次出现的位置
size_t rfind(const char* s, size_t pos, size_t n) const;//从右向左在给定字符串中从下标为pos的位置开始查找字符串s的前n个字符第一次出现的位置
size_t rfind(char c, size_t pos = npos) const;//从右向左在给定字符串中从下标为pos的位置开始查找字符c第一次出现的位置#include
#include
using namespace std;
int main()
{
string url1 = "https://cplusplus.com/reference/string/string/rfind/";
cout << url1.rfind(':') << endl;
return 0;
} 
9.string字符串比较
分为字符串对象和字符串对象比较、字符串对象和字符串比较、字符串和字符串对象比较:
bool operator== (const string& lhs, const string& rhs);
bool operator== (const char* lhs, const string& rhs);
bool operator== (const string& lhs, const char* rhs);
bool operator!= (const string& lhs, const string& rhs);
bool operator!= (const char* lhs, const string& rhs);
bool operator!= (const string& lhs, const char* rhs);
bool operator< (const string& lhs, const string& rhs);
bool operator< (const char* lhs, const string& rhs);
bool operator< (const string& lhs, const char* rhs);
bool operator<= (const string& lhs, const string& rhs);
bool operator<= (const char* lhs, const string& rhs);
bool operator<= (const string& lhs, const char* rhs);
bool operator> (const string& lhs, const string& rhs);
bool operator> (const char* lhs, const string& rhs);
bool operator> (const string& lhs, const char* rhs);
bool operator>= (const string& lhs, const string& rhs);
bool operator>= (const char* lhs, const string& rhs);
bool operator>= (const string& lhs, const char* rhs);#include
#include
using namespace std;
int main()
{
string s1 = "cplusplus";
string s2 = ".com";
cout << (s1 == s2) << endl;
cout << (s1 == "cplusplus.com") << endl;
cout << ("cplusplus.com" == s2) << endl;
return 0;
} 
三、string OJ题
1.仅仅反转字母 OJ链接
分析:
(1)发现示例中的字符串,如果是字母就交换,如果不是字母就不做操作,可以用while循环,直到找到都是字母的字符才交换
(2)要判断字符串中,每个字符是不是字母,用函数来判断
class Solution {
public:
//判断字符是不是字母
bool IsLetter(char ch)
{
if((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z'))
{
return true;
}
else
{
return false;
}
}
string reverseOnlyLetters(string s) {
if(s == "")
{
return s;
}
size_t begin = 0;
size_t end = s.size()-1;
while(begin < end)
{
//从左边找字母
while((!IsLetter(s[begin])) && (begin < end))
{
begin++;
}
//从右边找字母
while((!IsLetter(s[end])) && (begin < end))
{
end--;
}
swap(s[begin],s[end]);
//迭代
begin++;
end--;
}
return s;
}
};2.字符串里面最后一个单词的长度 OJ链接
分析:
(1)由于cin和scanf一遇到空格就断开了,所以不能接收完整的字符串,getline( )遇到换行才会终止,因此用getline( )来接收
(2)求最后一个单词长度,就要找出从右向左第一个空格的位置,这个位置到字符串末尾的距离就是最后一个单词的长度
#include
#include
using namespace std;
int main()
{
string s;
//接收多行输入
while(getline(cin,s))
{
size_t pos = s.rfind(' ');//从右向左找出第一个空格的位置
if(pos != string::npos)
{
cout << s.size() - 1 - pos < 3.验证回文串 OJ链接
分析:
(1)从示例来看,字母和数字都要进行判断,因此要检查字符是否为字符或数字
(2)忽略大小写,那么可以将大写全部转为小写或小写全部转为大写进行判断
(3)如果对称位置的字符相等,并不能说明一定是回文串,继续迭代;如果不相等,那一定不是回文串
class Solution {
public:
//判断字符是不是字母或数字
bool IsLetterOrNumber(char ch)
{
if((ch >= 'a' && ch <= 'z')
|| (ch >= 'A' && ch <= 'Z')
|| (ch >= '0' && ch <= '9'))
{
return true;
}
else
{
return false;
}
}
bool isPalindrome(string s) {
if(s == "")
{
return true;
}
//将大写全部转为小写
for(auto& ch:s)
{
if(ch >= 'A' && ch <= 'Z')
{
ch += 32;
}
}
//迭代下标定义为int,如果为无符号size_t型,那么当迭代时,end--的如果结果为-1时,-1的无符号数为4294967295,begin一定小于end会再次进入while(begin < end)循环,导致无限循环
int begin = 0;
int end = s.size()-1;
while(begin < end)
{
//从左边找字母
while((!IsLetterOrNumber(s[begin])) && (begin < end))
{
begin++;
}
//从右边找字母
while((!IsLetterOrNumber(s[end])) && (begin < end))
{
end--;
}
if( s[begin] == s[end] )
{
//迭代
begin++;
end--;
}
else
{
return false;
}
}
return true;
}
};4.字符串相加 OJ链接
分析:
(1)相加计算,从低位开始按位相加,迭代就要从字符串末尾向前迭代
(2)相加结果>9就产生进位,下一次相加时,要加上进位
(3)如果将对应位相加结果使用insert依次插入,可以指定插入位置,每次在最前面插入,那么低位相加结果就在低位,高位相加结果就在高位,最后的结果就不需要逆置
如果将对应位相加结果使用+=拼接起来,那么低位相加结果就在高位,高位相加结果就在低位,最后的结果就需要逆置
class Solution {
public:
string addStrings(string num1, string num2) {
int end1 = num1.size() - 1;
int end2 = num2.size() - 1;
string retStr;
int next = 0;//进位
while(end1 >= 0 || end2 >= 0)
{
int val1 = 0;
if(end1 >= 0)
{
val1 = num1[end1] - '0';
end1--;
}
int val2 = 0;
if(end2 >= 0)
{
val2 = num2[end2] - '0';
end2--;
}
int ret = val1 + val2 + next;
if(ret > 9)
{
ret -= 10;
next = 1;
}
else
{
next = 0;
}
retStr.insert(0,1,'0'+ ret);
//retStr += ('0' + ret);//如果不使用insert,而用+=,那么结果就需要逆置
}
if(next == 1)
{
retStr.insert(0,1,'1');//如果不使用insert,而用+=,那么结果就需要逆置
//retStr += '1';
}
//reverse(retStr.begin(),retStr.end());//如果不使用insert,而用+=,那么结果就需要逆置
return retStr;
}
};