大数据复习----虚拟机创建~集群搭建~hadoop高可用
1.centos7创建
1.新建虚拟机
2.最好放在非系统盘的固态盘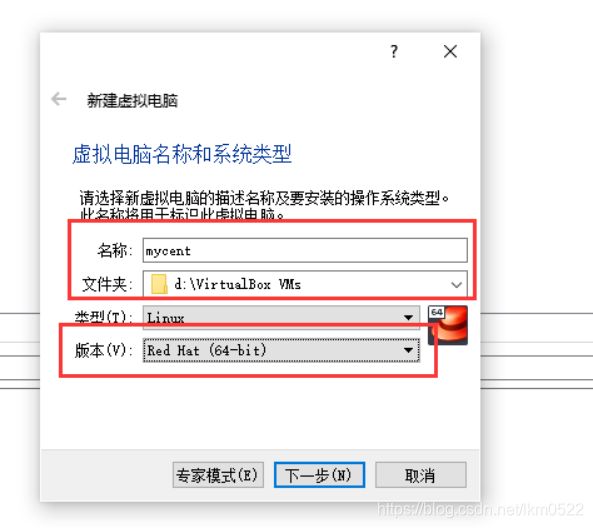
3.设置内存大小,根据自己需求
4.默认
5.默认
6.动态分配
7.最少100G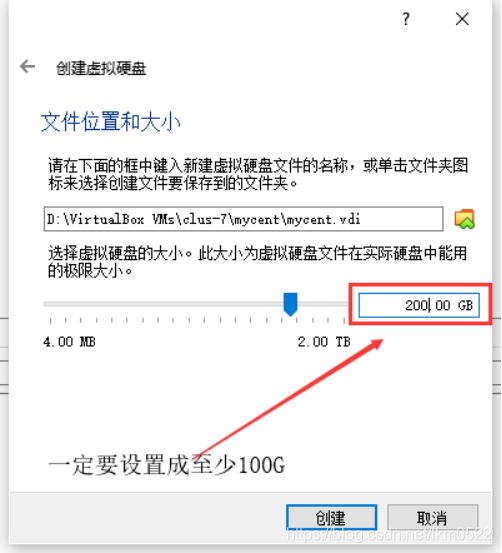
8.分组

9.重命名
10.
11.
12.安装操作系统
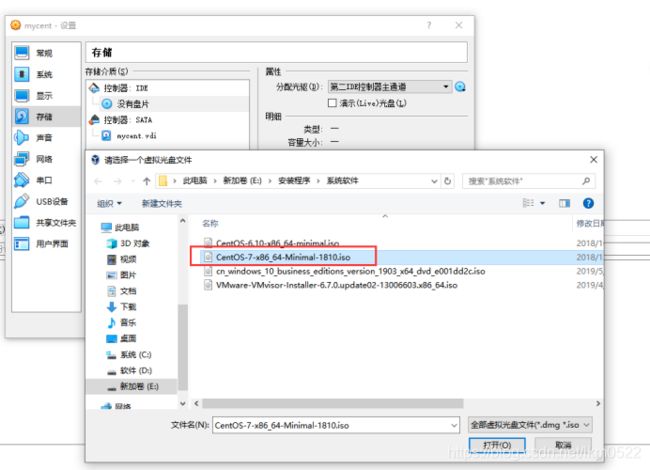
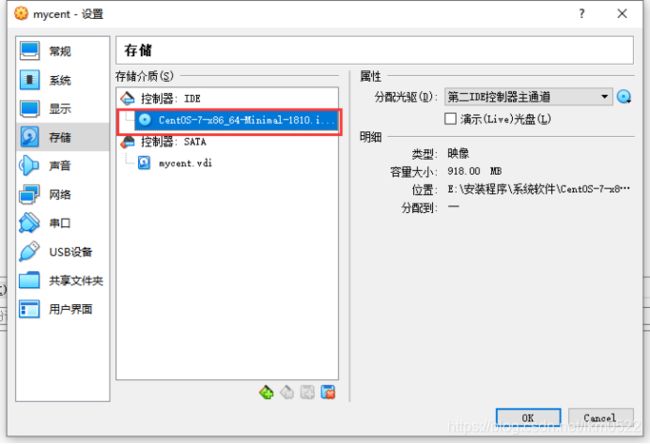
13.选择镜像
14.
15.
16.修改CPU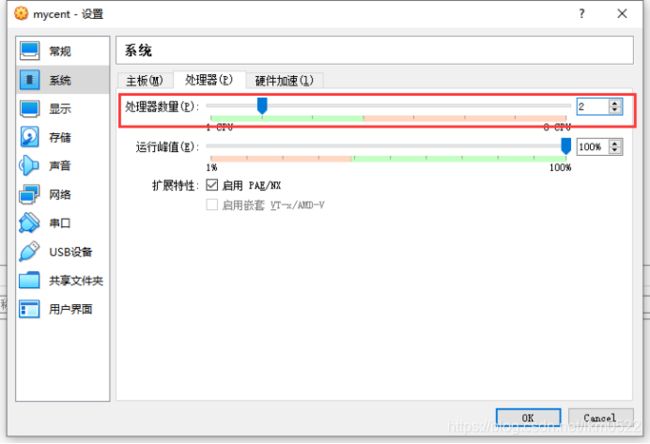
17.修改鼠标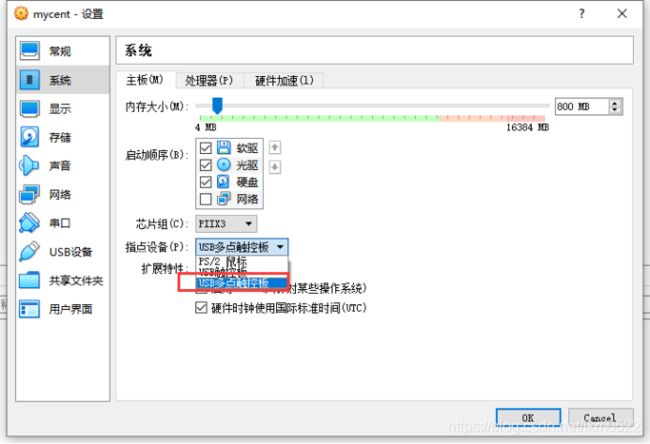
18.启动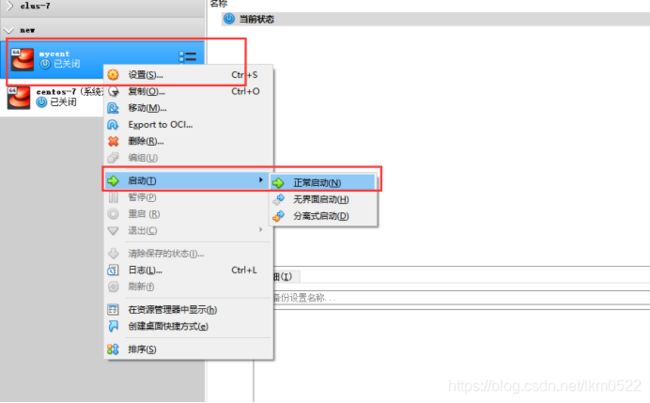
19.自由缩放
20.
21.
22.
23.设置root密码
24.重启
2. 配置网络环境
1. cd /etc/sysconfig/network-scripts/
2. ll -h
3. vi ifcfg-enp0s3
4. ONBOOT=no 改为 yes
5. reboot 重启
6. 查看ip 需要安装一个工作:(必须可以连接上外网)
yum -y install net-tools
7. ifconfig
8. 网络检查:
虚拟机是否可上公网;(www.baidu.com)(默认是可以的)
ping www.baidu.com
9. yum -y install vim 安装vim,使用更方便
10.设置Linux默认的安全组
vim /etc/selinux/config
设置为SELINUX=disabled
11. 手动创建目录,把我们解压的放到这个目录里面,不要解压到home目录中
mkdir /data 在根目录下创建data
df -h 查看存储状况
vim /etc/fstab 修改目录挂载
把 /home 修改为 /data


12. 关闭防火墙
查看服务运行的状态;
systemctl status firewalld
查看已经安装的服务列表;
systemctl list-unit-files
停止防火墙;
systemctl stop firewalld
禁止防火墙随机启动。
systemctl disable firewalld
13. 想让真实机连接虚拟机;不通,需要配置;(再单独的增加一块网卡),叫host-only
关机 init 0
增加网卡:
右键虚拟机,设置,找到网络,点击网卡2,启用网络连接,
选择连接方式(仅主机(Host-Only)网络),
OK完成。
14. 配置静态IP
- 一定要保证当前的目录为;
/etc/sysconfig/network-scripts
- 要把ifcfg-enp0s3复制一份为ifcfg-enp0s8;
cp ifcfg-enp0s3 ifcfg-enp0s8
- 修改ifcfg-enp0s8;
BOOTPROTO=static
# name和device都是enp0s8;(凭啥?因为先是动态获取,通过ifconfig查看出来的)
NAME=enp0s8
# 所有的网卡uuid不能重复
UUID=60188808-40f9-45d5-83af-4822aadc4711
DEVICE=enp0s8
ONBOOT=yes
# 配置我的ip地址(静态的)
IPADDR=192.168.56.110
- 重启网络服务,每次修改ifcfg开头的文件都要重启网络服务;
service network restart
15. 永久性的修改主机名称,重启后能保持修改后的。
hostnamectl set-hostname review1
或者手动修改etc/hosts
16.reboot 重启;
查看主机名;
hostname
查看防火墙;
systemctl status firewalld
看看修改成功没有,修改成功之后,基本配置完成,关机,拍摄快照,
备份,万一虚拟机坏了,可以方便恢复。
3. 使用客户端远程连接服务器
1. 客户端
Xshell+xftp
secureCRT
Putty
2.在Windows中C:\Windows\System32\drivers\etc目录下,
修改hosts文件,
添加192.168.56.110 review
3. 要记住用户名和密码,方便下次使用哦
4. 搭建集群四台
1.创建好一台新的虚拟机,且配置好网络,静态IP之后,进行复制四台虚拟机,我的是之前发布的博客有教程哦
分别打开修改静态IP。
vim /etc/sysconfig/network-scripts/ifcfg-enp0s8
修改四台IP
192.168.56.111
192.168.56.112
192.168.56.113
192.168.56.114
分别重启网络服务,service network restart
2.编辑hosts文件
vim /etc/hosts
192.168.56.111 cent7-1
192.168.56.112 cent7-2
192.168.56.113 cent7-3
192.168.56.114 cent7-4
3.配置免密钥
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
[hadoop官网设置指导](https://hadoop.apache.org/docs/r3.2.1/hadoop-project-dist/hadoop-common/SingleCluster.html)
- 下载插件,把Linux文件下载到Windows
yum -y install lrzsz
sz 文件名 下载文件Windows
rz -y 选择文件 上传文件到Linux
4. sz ./.ssh/authorized_keys
把四台虚拟机的authorized_keys文件复制到一个里面
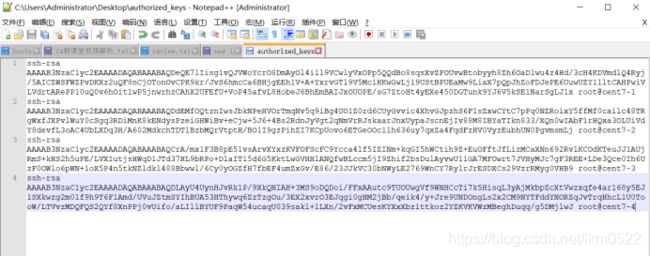
cd ./.ssh
rz -y 选择authorized_keys上传
5.配置完免密之后一定要在四台Linux上敲一遍,
ssh cent7-1 yes 一定一定一定不要忘记 Ctrl + D 登出!登出!登出!继续下一个
ssh cent7-1 yes
ssh cent7-2 yes
ssh cent7-3 yes
ssh cent7-4 yes

5. 安装Zookeeper
1.在cent7-1,cent7-2,cent7-3,这三台装Zookeeper

2.先装好一个(不能完全装完);
解压tar包
tar -xzvf zookeeper-3.4.13.tar.gz
# 改名
mv apache-zookeeper-3.6.1-bin/ zookeeper-3.6.1
cp zoo_sample.cfg zoo.cfg
修改配置文件(conf/zoo.cfg);
修改:
dataDir=/data/zookeeper/data/
添加:
# 集群的配置
# server.随机起(zk自己识别的名字)=主机名:端口1:端口2
server.1=cent7-1:2888:3888
server.2=cent7-2:2888:3888
server.3=cent7-3:2888:3888
3.将zookeeper从cent7-1同步到cent7-2,和cent7-3;
# 一定要在/data/zookeeper下面;当前目录下面得有zookeeper
scp -r zookeeper-3.6.1/ cent7-2:`pwd`
scp -r zookeeper-3.6.1/ cent7-3:`pwd`
4.一定要在zoo.cfg配置文件中data目录下面创建一个myid;
myid文件中填写的是zookeeper自己为服务器起的别名。
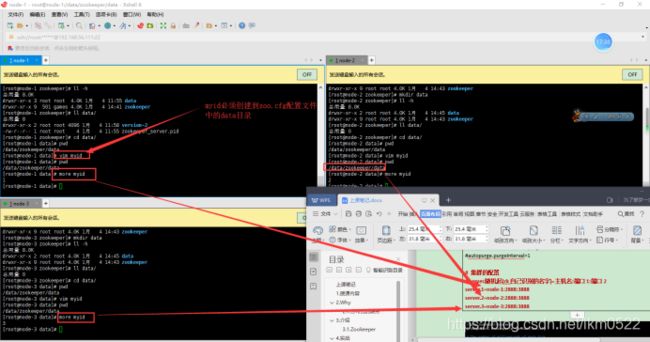
5.测试zookeeper
安装jdk,yum -y install jdk-8u251-linux-x64.rpm
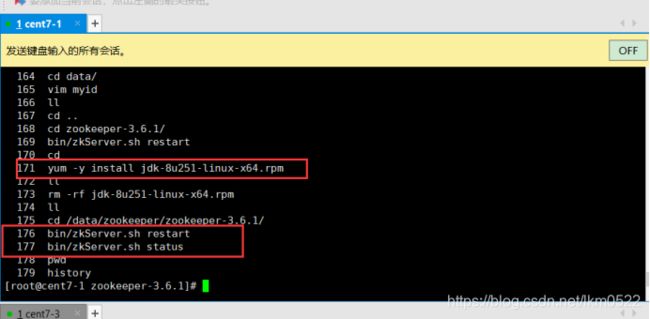
6. cd /data/zookeeper/zookeeper-3.6.1/
bin/zkServer.sh restart
bin/zkServer.sh status

6. 搭建hadoop高可用
1.hadoop集群分配。

2. 要安装一个软件(zookeeper使用的)(Centos7)
hadoop:高可用切换不成功,安装"fuser"命令;
yum -y install psmisc
![]()
3. 四台机器一起操作,进入/data目录, mkdir hadoop
先在一台机器上(node7-1)操作,然后分发
rz -y hadoop-3.2.1.tar.gz 找到windows中的hadoop包
tar -zxvf hadoop-3.2.1.tar.gz
cd hadoop-3.2.1
du -h share/doc/ share/doc/官方文档,占内存,删除
rm -rf share/doc/
- 分配到其他三台机器上
scp -r hadoop-3.2.1/ cent7-2:`pwd`
scp -r hadoop-3.2.1/ cent7-3:`pwd`
scp -r hadoop-3.2.1/ cent7-4:`pwd`
6.1:建议:
建议把配置文件保存下来,方便下次使用!!!

6.2:配置hadoop-env.sh
执行命令 bin/hadoop 报下面的错误,
ERROR: JAVA_HOME is not set and could not be found.
因为没有配置java环境变量,尽量不要配置环境变量,环境变量是一堆路径的集合,
比如环境路径中有一堆重复的sh文件(spark,hive,hadoop它们的start-all.sh),
那到底要执行哪个.sh文件呢,全部配置之后,哪个文件在前面先执行那个.sh文件,
所以说环境变量,除非某个软件要求你配置,比如hadoop要求配置JAVA_HOME,
如果不要求的话,不建议配置环境变量,无非就是敲命令的时候敲一个绝对路径,
虽然麻烦,但是安全呀。
编辑文件 etc/hadoop/Hadoop-env.sh 添加一些参数如下:
export JAVA_HOME=/usr/java/jdk1.8.0_251-amd64/
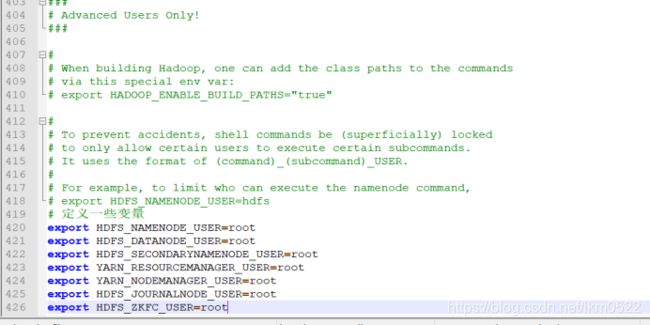
再在最下面添加启动用户变量:
# 定义一些变量
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
查看java安装目录:
whereis java
ll /usr/bin/java
ll /etc/alternatives/java

再上传到Linux中;
尝试以下命令:
bin/hadoop
6.3:配置core-site.xml
配置文件是参考的 官方文档,可以点击看看!
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 核心的hdfs协议访问方式
董事会
-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://jh</value>
</property>
<!-- 所有hadoop的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/data/hadoop-${user.name}</value>
</property>
<!-- 告诉hadoop,zookeeper放哪了 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>cent7-1:2181,cent7-2:2181,cent7-3:2181</value>
</property>
</configuration>
6.4: 配置hdfs-site.xml
配置文件是参考的 官方文档,可以点击看看!
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 副本数;默认3个 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 权限检查 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- dfs.namenode.name.dir:namenode的目录放的路径在hadoop.tmp.dir之上做了修改
file://${hadoop.tmp.dir}/dfs/name
dfs.datanode.data.dir:namenode的目录放的路径在hadoop.tmp.dir之上做了修改
file://${hadoop.tmp.dir}/dfs/data
-->
<!-- 为nameservice起一个别名
董事会
-->
<property>
<name>dfs.nameservices</name>
<value>jh</value>
</property>
<!-- 董事会的成员 -->
<property>
<name>dfs.ha.namenodes.jh</name>
<value>nn1,nn2</value>
</property>
<!-- 配置每一个攻事会成员
每一个配置的时候得有rpc(底层),http(上层==网页)
-->
<property>
<name>dfs.namenode.rpc-address.jh.nn1</name>
<value>cent7-1:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.jh.nn1</name>
<value>cent7-1:9870</value>
</property>
<!-- 第二个成员 -->
<property>
<name>dfs.namenode.rpc-address.jh.nn2</name>
<value>cent7-2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.jh.nn2</name>
<value>cent7-2:9870</value>
</property>
<!-- journalnode:负责hadoop与zk进行沟通 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://cent7-2:8485;cent7-3:8485;cent7-4:8485/jh</value>
</property>
<!--下面的配置文件官网(QJM)
https://hadoop.apache.org/docs/r3.2.1/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
--!>
<!-- 哪个类决定了自动切换
哪个namenode是活着的(active)
-->
<property>
<name>dfs.client.failover.proxy.provider.jh</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- journal的存储位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop/data/journal/</value>
</property>
<!-- 大哥挂了,自动切换到二哥上
启动故障转移
-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- (ssh免密码登录) -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
</configuration>
6.5:配置mapred-site.xml
配置文件是参考的 官方文档,可以点击看看!
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 一旦启动了yarn,建议换成必须设置最大内存 -->
<property>
<name>mapreduce.map.memory.mb</name>
<value>200</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx200M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>200</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx200M</value>
</property>
</configuration>
6.6:配置mapred-site.xml
配置文件是参考的 官方文档,可以点击看看!
<?xml version="1.0"?>
<configuration>
<!-- 配置yarn -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn开启ha -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- yarn董事会的名字 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>jh-yarn</value>
</property>
<!-- 董事会列表 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- hostname,webapp-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>cent7-1</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>cent7-1:8088</value>
</property>
<!-- 第二台 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>cent7-2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>cent7-2:8088</value>
</property>
<!-- zookeeper -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>cent7-1:2181,cent7-2:2181,cent7-3:2181</value>
</property>
</configuration>
6.6:配置works
这里面放的都是小弟!!!
cent7-2
cent7-3
cent7-4
7. 配置完毕,开始分发
scp -r hadoop-3.2.1/ cent7-2:`pwd`
scp -r hadoop-3.2.1/ cent7-3:$PWD
scp -r hadoop-3.2.1/ cent7-4:`pwd`

8. 启动集群
8.1:先启动zookeeper
bin/zkServer.sh restart
8.2:启动journalnode
sbin/hadoop-daemon.sh start journalnode(过时了)
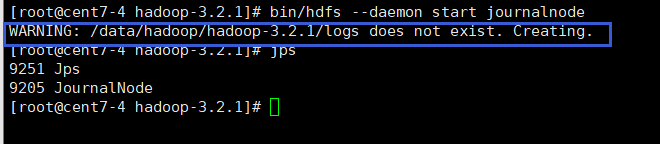
bin/hdfs --daemon start journalnode
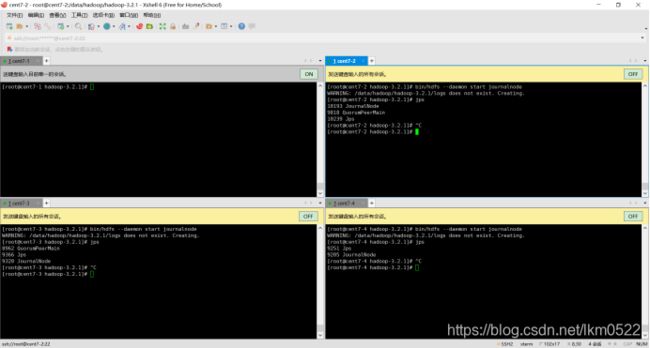
如果journalnode启动报错,就去该目录下查看日志(/data/hadoop/hadoop-3.2.1/logs)
8.3:启动namenode
- 格式化namenode,在其中任何一台namenode上格式化(cent-1)
bin/hdfs namenode -format
- 把刚才格式化后的元数据拷贝到另外一个namenode上(将cent-拷贝到cent-2)
- 一定要进入到/data/hadoop/data中
scp -r hadoop-root/ cent7-2:`pwd`
- 启动刚刚格式化的namenode :(cent-1)
sbin/hadoop-daemon.sh start namenode
bin/hdfs --daemon start namenode

- 在没有格式化的namenode上执行:(cent-2)
bin/hdfs namenode -bootstrapStandby
有个选项,Y确定

- 启动第二个namenode(cent-2)
sbin/hadoop-daemon.sh start namenode
bin/hdfs --daemon start namenode

- 在其中一个节点上初始化zkfc(cent-1))(一定要启动zookeeper)
bin/hdfs zkfc -formatZK
- 重新启动hdfs
sbin/stop-all.sh
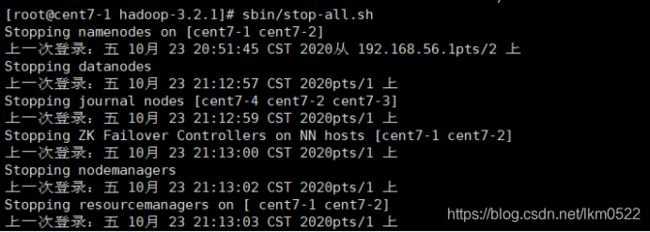
sbin/start-dfs.sh


访问网页 cent7-1:9870 cent7-2:9870


- 测试高可用
- 停止active的namenode,自动切换;
kill -9
bin/hdfs --daemon stop namenode
杀死之后再启动,看效果!
kill -9 16058
bin/hdfs --daemon start namenode



8.6:停止所有进程,测试高可用Yarn
sbin/stop-all.sh
sbin/start-all.sh
官方文档找到的 官方代码 进行测试hadoop

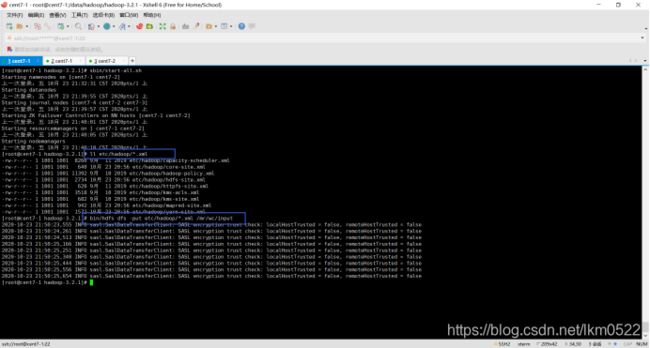
8.7:上传文件到hdfs
bin/hdfs dfs -put etc/hadoop/*.xml /mr/wc/input
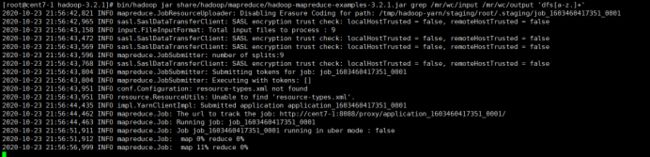
8.8:bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep /mr/wc/input /mr/wc/output 'dfs[a-z.]+'
8.9: