论文阅读-MGTAB: A Multi-Relational Graph-Based Twitter Account DetectionBenchmark
目录
摘要
1. 引言
2. 相关工作
2.1. 立场检测
2.2.机器人检测
3.数据集预处理
3.1.数据收集和清理
3.2.专家注释
3.3. 质量评估
3.4.特征分析
4. 数据集构建
4.1.特征表示构造
4.2.关系图构建
5. 实验
5.1.实验设置
5.2.基准性能
5.3训练集大小的研究
5.4 社会图关系分析
6. 结论
7. 补充资料
7.1.特征分析
7.2. 不同 BERT 模型的影响
7.3实验细节
论文链接:https://arxiv.org/pdf/2301.01123.pdf
摘要
社交媒体用户立场检测和机器人检测方法的发展严重依赖于大规模和高质量的基准。
gap: 然而,除了注释质量低之外,现有基准通常具有不完整的用户关系,抑制了基于图的帐户检测研究。
方案:为了解决这些问题,我们提出了一个基于多关系图的 Twitter 帐户检测基准 (MGTAB),这是第一个用于帐户检测的基于图的标准化基准。
据我们所知,MGTAB 是基于该领域最大的原始数据构建的,拥有超过 155 万用户和 1.3 亿条推文。
MGTAB 包含 10,199 个专家标注用户和 7 种关系类型,保证了高质量的标注和多样化的关系。
在MGTAB中,我们提取了信息增益最大的20个用户属性特征和用户推文特征作为用户特征。
此外,我们对 MGTAB 和其他公共数据集进行了全面评估。
我们的实验发现,基于图的方法通常比基于特征的方法更有效,并且在引入多重关系时表现更好。
通过分析实验结果,我们确定了帐户检测的有效方法,并提供了该领域未来潜在的研究方向。
我们的基准和标准化评估程序可在以下网址免费获得:https://github.com/GraphDetec/MGTAB。
1. 引言
背景:(引入之前的数据集)随着互联网的不断发展,社交网络已经成为人们日常社交生活中必不可少的一部分。 Twitter 是全球访问量最大的社交网络之一,为全球数十亿用户提供在线新闻和信息交流。由于可用性,许多帐户检测基准是基于 Twitter 数据构建的 [9,15,17,47]。
介绍立场检测和机器人检测:立场检测和机器人检测是帐户检测中的基本任务。立场检测旨在检测用户对某个主题或主张的立场。它是假新闻检测 [25、31]、声明验证 [1、27] 和社交媒体舆论分析等应用中的一项关键技术。机器人检测对于检测社交媒体上的信息操纵至关重要。社交机器人是由计算机程序 [60] 操作的自动用户帐户,经常被用来滥用社交媒体平台 [10, 19] 来操纵公众舆论 [9-11, 60]。
前人方法局限性:大多数帐户检测方法仅使用社交媒体中的部分信息(例如帖子、注册信息等)进行分类。很少考虑用户之间的联系[24],这使得确保检测准确性具有挑战性。在立场检测中,沉默的用户通常不会直接发帖,而是通过行为表达他们的立场,例如关注他人和喜欢帖子 [24]。然而,大多数研究只关注活跃用户的发帖内容而忽略沉默用户[24]。需要使用社交图的特征来更好地检测沉默用户的立场 [1]。在机器人检测中,由于大多数研究忽略了机器人的社交图特征,机器人可以通过复杂的策略模拟真实用户来逃避基于特征的检测方法[10]。
最近在帐户检测方面的工作 [14、18、38] 侧重于利用用户之间的关系,与基于特征的方法相比性能有所提高。然而,现有的数据集在支持基于图的方法方面有几个缺点,如下所示:
(a) 注释质量低。以前的帐户检测数据集主要由众包进行注释,而众包工作者缺乏领域知识导致注释中出现明显的噪音 [15]。
(b) 不完整的用户关系。没有一个姿态检测数据集明确提供用户之间的图结构,只有机器人检测数据集 Cresci-15 [9]、TwiBot-20 [17] 和 TwiBot-22 [15] 包含明确的图结构。此外,Cresci-15 和 TwiBot-20 仅包含 2 种类型的用户关系,这对于基于图形的检测方法是不够的。
(c) 复杂的用户信息。社交媒体用户信息多种多样,但大多数信息对帐户检测影响不大。现有数据集缺乏基本用户信息的提取和组织,使帐户检测成为一个难题。
为了解决上述缺点,我们提出了基于多关系图的 Twitter 帐户检测基准 (MGTAB),这是一个用于立场和机器人检测的大型标准化专家注释数据集。MGTAB 包含 10,199 个由专家手动注释的用户和 400,000 个密切相关的未注释用户。此外,MGTAB 通过计算信息增益 (IG) 和用户推文特征提取了 20 个最有效的用户属性特征。最后,MGTAB 简化了社交图并构建了一个具有 7 种关系的用户网络。
本文的贡献如下:
我们介绍了 MGTAB,这是一种用于立场检测和机器人检测的大规模专家注释基准。所有注释均由专家进行,并通过交叉验证提高注释质量。与以前的数据集相比,注释质量得到了显着提高。
我们发布了第一个包含属性特征、用户推文特征和 7 种用户关系类型的标准化数据集。我们构建了一个用户级社交图,可应用于最先进的基于图的帐户检测方法,使帐户检测更简单。 MGTAB 数据集的发布将促进基于图形的帐户检测新方法的开发。
为了构建 MGTAB,我们收集了超过 155 万 Twitter 用户和 1.35 亿条推文。据我们所知,它是该领域中最大的数据。我们进行了细致的数据清洗,保留了 40 万密切相关的未标记用户,支持半监督学习与账户检测研究相结合。
我们的实验表明,在大多数情况下,基于图形的检测方法比基于特征的方法更有效。此外,我们发现,当引入多个关系时,基于图的方法的性能得到改善。结果表明,未来的研究应侧重于使用多重关系。
2. 相关工作
2.1. 立场检测
现有的立场检测方法可分为基于特征的方法和基于图的方法。
基于特征的方法。先前的研究工作 [56, 58, 62] 使用机器学习算法和深度学习方法,例如支持向量机 (SVM)、循环神经网络 (RNN) [62] 和卷积神经网络 (CNN) 来自动从大量原始数据中学习潜在特征。最近的几项工作 [31、39、40、45、57] 侧重于在立场检测中使用来自 transformers (BERT) [12] 的双向编码器表示。戈什等人 [20] 探索了基于迁移学习的立场检测,Li 等人 [39] 探索了基于 BERT 的数据增强模型。
基于图形的方法。大多数关于立场检测的研究都使用基于文本的特征 [40、47、62]。最近的一些工作表明使用用户网络图作为特征的有效性 [1, 35]。图神经网络 (GNN) [34, 55] 由于其出色的处理图信息的能力,已成为账户检测的首选模型。李等 [38] 首先通过基于 GNN 的架构实现了立场和谣言检测,可以有效地捕获用户交互特征。尽管 GNN 在立场挖掘中表现良好,但现有立场检测数据集中缺乏图结构限制了基于图的检测方法的发展。
立场检测数据集。我们在 Tab 1中总结了现有的 Twitter 立场检测数据集。 SemEval-2016 T6 数据集 [47] 是第一个用于 Twitter 立场检测的数据集,其中包含众包注释的主题推文对。 SemEval-2019 T7 [25] 包含有关 Reddit 帖子和推文中各种事件的谣言。COVID-19-Stance [23] 由手动注释的推文组成,涵盖用户对与 COVID-19 健康要求相关的四个目标的立场。COVIDLies [30]、COVMis-Stance [31] 也是与 COVID 相关的数据集。 P-STANCE [40] 是在 2020 年美国大选期间收集的政治领域的大型立场检测数据集。Conforti 等人 [7] 构建了 WT-WT,这是一个包含专家执行的推文和注释的金融数据集。穆罕默德等人[46] 提出了由目标对组成的立场数据集,这些目标对注释了高音炮对目标的姿态。

我们介绍了 MGTAB,这是第一个带有用户网络图的立场检测数据集。 MGTAB 的大规模高质量标注将促进用户立场检测的发展。此外,MGTAB 提供了研究立场检测中基于图的方法的机会。
2.2.机器人检测
现有的机器人检测方法可分为基于特征的方法和基于图的方法。
基于特征的方法。基于特征的方法从用户的元数据中提取和设计特征,然后使用传统的分类器进行机器人检测。早期作品 [9, 53] 使用简单的特征,例如关注者数量、朋友数量、推文数量和创建日期等。一些研究使用了更复杂的特征,例如基于社会关系的特征 [11, 59]。还有一些研究使用用户推文的特征 [29, 53]。对于提取的用户特征,许多研究 [3、29、33、48、52] 使用机器学习算法进行机器人检测。 Adaboost (AB) [28]、随机森林 (RF) [6]、决策树 (DT) [42] 和 SVM [5] 都已应用于机器人检测。然而,机器人可能会根据为检测而设计的特征更改注册信息,以规避基于特征的检测方法[10, 15]。
基于图的方法。基于图的方法比基于特征的方法更有效 [15]。SATAR [16] 是基于特征特用户的社交图以特征工程的方式构建的。Gnn可以从复杂的关系中获得潜在的表征。受 GNN 成功的启发,Alhosseini 等人 [2] 首先尝试使用图形卷积神经网络 (GCN) [34] 进行垃圾邮件机器人检测,有效利用 Twitter 帐户的图形结构和关系。郭等[26] 对称地结合 BERT 和 GCN,利用基于文本和图形的特征。最近的一些研究 [4、14、18、49] 调查了社交图中的多重关系。 BotRGCN [18] 通过用户网络构建异构图,并将关系图卷积网络应用于机器人检测。RGT [14] 使用关系图转换器来模拟异构社交图中用户之间的交互。然而,受机器人检测数据集中缺乏关系的限制,以往的研究只使用了两种类型的关系,朋友和追随者。在社交图中使用多重关系用于机器人检测的技术仍未探索。机器人检测数据集。尽管专家注释的质量最高,但由于成本高,只有 Varol-icwsm 被专家完整注释。
大多数数据集都是通过众包进行注释的,而其他数据集是使用基于帐户行为、元数据过滤器或其他更复杂程序的自动化技术创建的。我们总结了现有的机器人检测数据集,如表2所示。

Caverlee [36] 由honeypot帐户吸引的bot帐户,经过验证的人类帐户及其最重要的推文组成。Varol-icwsm [22] 数据集由从不同 Botometer 分数十分位数 [54] 采样的手动标记的 Twitter 帐户组成。在 Gilani-17 [21] 中,Twitter 帐户根据关注者数量分为四类。除此之外,Midterm-18 [61]、Cresci-17 [10]、Botometer-feedback [60]、Cresci-stock [8]、Cresci-rtbust [44]、Kaiser [50] 也是机器人检测数据集,具有各种注释方法和信息完整性。
尽管有很多机器人检测数据集,但很少有具有图结构的。只有三个公开可用的机器人检测数据集提供社交图:Cresci-15 [9]、TwiBot-20 [17] 和 TwiBot-22 [15]。 Cresci-15和TwiBot-20仅包含朋友和追随者两种关系,难以支持基于多关系图检测的研究。在 TwiBot-22 中,使用 1,000 个手动标记的帐户来训练模型以获取剩余帐户的标签,从而导致标签偏差。我们提出的 MGTAB 完全由专家注释,有 7 种关系。与大多数以前的数据集相比,它具有更大的规模、更高质量的注释和更丰富的关系。
3.数据集预处理
3.1.数据收集和清理
我们采用广度优先搜索 (BFS) 获取 MGTAB 的用户网络,该用户网络基于选择 100 个密切参与 2021 年在线事件讨论的种子帐户。我们为每个用户收集了 10,000 条最新推文,足以用于帐户检测。收集的数据总共包含 1,554,000 名用户和 135,450,000 条推文。我们首先去除噪声数据和异常节点来构建一个紧凑的图。具体来说,没有追随者或朋友的用户被删除。然后我们丢弃与目标在线事件不密切相关的用户,最终保留了 410,199 个帐户和超过 4000 万条推文。
3.2.专家注释
我们邀请了 12 位具有十年以上工作经验的机器人检测和立场检测专家,对用户姿态进行人工标注,判断是否为机器人。为了进一步提高注释质量,每个 Twitter 用户都由九个注释者独立标记,并且所有用户的注释都是通过多数投票获得的。这些立场被标记为三类:中立、反对和支持,这些类别被标记为两种类型:人类和机器人。整个数据集的注释大约花了四个月的时间。注释标签的分布如表3所示。 继TwiBot-20之后,我们使用剩余的400,000个未标记用户作为半监督学习方法研究的支持集。

3.3. 质量评估
其余三位专家独立随机抽取 10% 的标注用户进行标注质量评价。我们平均获得了 95.4% 的立场准确度和 97.8% 的机器人准确度。这远高于之前发布的使用众包的立场检测数据集获得的准确度(报告的准确度,以百分比表示,范围从 63.7% 到 79.7%)[7]。此外,与 TwiBot-20 [17] 和 TwiBot-22 [15] 的 80% 和 90.5% 准确率相比,我们 97.8% 的机器人准确率显着提高了注释质量。
3.4.特征分析
我们随机选择了 2000 个标记用户来分析检测特征的有效性。我们分析了不同方面的特征,包括创建时间、好友数、名称长度等。在 [9] 之后,我们使用信息增益 (IG) 来衡量特征对预测类的信息量。它可以非正式地定义为由给定属性值的知识引起的熵的预期减少。
用Y表示用户的类别,H(Y)表示Y的熵,y为Y的值,y∈{y1,y2,.. . . , yK}。在立场检测中,K 为 3,在机器人检测中,K 为 2。

H (Y | X)表示给定特征 X 时的 H (Y) ,该特征 X 可通过以下方法计算出来:

其中 x 是 X 的值,x ∈ Φ。 IG(X; Y)表示Y得到特征X后类别信息增加(不确定性减少):

IG 越大的特征包含越多的检测信息。根据特征的类型,我们将特征分为布尔型和数值型特征,布尔型特征取真值或假值。除创建时间外,数字特征取对数。然后将数据按照值域均匀划分为K个区间,统计每个区间的样本数,然后利用离散值计算IG。在本文中,K 设置为 51。
用户立场特征。首先去除具有相同分布的特征,然后计算用户特征的IG以获得具有前10个IG的布尔和数值特征用于bot检测。布尔和数值特征分别以 IG 的降序显示在图 1 和图 2 中。

分析了前 3 个 IG 的布尔和数字特征: 默认配置文件:大多数持反对立场的用户更喜欢使用默认配置文件。默认配置文件侧边栏边框颜色:大多数持有反对立场的用户更喜欢使用默认配置文件的侧边栏边框颜色。默认配置文件侧边栏填充颜色:大多数持有相反立场的用户更喜欢使用默认配置文件的侧边栏颜色。创建于:大多数持有相反立场的用户都是最近创建的。 statues count:立场相反的用户在地位较低的用户中所占比例较大。收藏数:收藏数较低的用户中,反对的较多。
用户机器人功能。进行与上述相同的处理,以获得用于机器人检测的前 10 个 IG 的布尔和数值特征。布尔和数值特征分别以 IG 的降序显示在图 3 和图 4 中。

分析了前 3 个 IG 的布尔和数字特征: 有 url:大多数机器人都有空 URL 内容。默认配置文件:与人类相比,机器人倾向于使用默认配置文件。默认个人资料图片:大多数具有默认背景图片的用户都是机器人。关注者朋友比率:机器人通常通过相互关注来增加关注者数量,这导致关注者朋友比率较小。列出的计数:机器人属于比人类用户更多的公共列表。描述长度:为了伪装成人类用户,机器人倾向于比人类更频繁地填写帐户描述,并且描述更长。
我们的实验表明,所选择的特征比以前的文献 [18、33、61] 中提取的特征更有效,详情见第7.1节。
4. 数据集构建
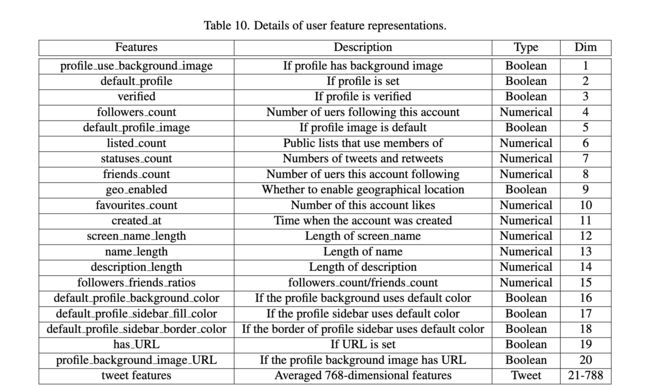
4.1.特征表示构造
我们将用户属性特征和用户推文特征连接起来作为用户特征表示,![]() 。用户特征表示的详细信息显示在表10中。
。用户特征表示的详细信息显示在表10中。

属性特征提取。用户属性特征是根据第 3.4 节中的分析获得的。将选取的数值特征通过Z-score归一化,得到数值特征![]() 的表示。对选取的布尔特征进行数值化处理,其中True和False分别用1和0代替,得到布尔特征
的表示。对选取的布尔特征进行数值化处理,其中True和False分别用1和0代替,得到布尔特征![]() 的表示。用户属性特征的表示是通过连接
的表示。用户属性特征的表示是通过连接![]() 和
和![]() 获得的,
获得的,![]() 。
。
推文特征提取。推文包含54种语言,其中英语出现频率最高,比例为73.6%。更多详细信息,请参见第 17.1节。 非英语语言的统计数据如图 5 所示。使用单语言预训练 BERT 模型对多语言推文进行良好编码并不容易。

因此,我们使用多语言 BERT LaBSE [13] 来提取推文特征。具体来说,我们使用 LaBSE 对用户推文进行编码。我们对所有推文的表示求平均以获得用户推文![]() 的表示。由 LaBSE 编码的有效性的演示显示在第7.2节中。
的表示。由 LaBSE 编码的有效性的演示显示在第7.2节中。
4.2.关系图构建
复杂的社交图结构,包括用户、推文、主题标签、URL 等多个实体,使得基于图的帐户检测成为一个复杂的问题。由于用户级检测关注的焦点是用户。最近提出的基于异构图 [4、14、18、49] 的最先进的检测方法仅使用用户之间的关系。因此,我们通过在构建社交图时仅保留用户作为节点来简化社交网络图,如图 6 所示。对于其他类型的实体,仅使用它们构建用户之间的关系。

显式关系提取。对于关注者、朋友、提及、回复和引用等显式关系,用户之间的联系直接从他们的关系中构建。基于上述关系构建的边均为有向边,如表 14所示。

隐式关系构建。我们还提取了用户之间的 2 种隐式关系:URL 共现和话题共现。特别地,用户节点 和
和 之间的共现关系可以通过实体共现的概率来确定,其权重通过平均逐点互信息(PMI)计算:
之间的共现关系可以通过实体共现的概率来确定,其权重通过平均逐点互信息(PMI)计算:
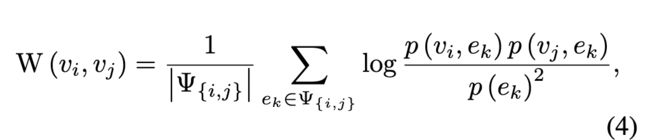
( 介绍PMI:PMI这个指标通常用来衡量两个事物之间的相关性,比如两个词,其原理很简单,公式:![]()
概率论中如果x和y不相关,则![]() , 如果两者相关性越大,则
, 如果两者相关性越大,则![]() 就比
就比![]() 大,则PMI也就越大;
大,则PMI也就越大;
log 取自信息论中对概率的量化转换;)
其中 Ψ{i,j} 表示 vi 和 vj 共有的实体集。计算PMI时使用![]() 近似
近似![]() ,其中
,其中![]() 表示的实体列表长度。最后,我们获得了包含 410,199 个节点和超过 1 亿条边的 MGTAB 异构图。
表示的实体列表长度。最后,我们获得了包含 410,199 个节点和超过 1 亿条边的 MGTAB 异构图。
5. 实验
5.1.实验设置
数据集。在立场检测中,我们根据我们提出的基准 SemEval-2016 T6 [47] 和 SemEval-2019 T7 [25] 评估模型。在机器人检测中,除了我们提出的基准之外,我们模型还评估了 4 个公开可用的机器人检测数据集:Cresci-17 [10]、Cresci-15 [9]、TwiBot-20 [17] 和 TwiBot-22 [15]。根据[15, 17],我们对所有数据集进行 7:2:1 随机划分作为训练、验证和测试集。
基线。我们使用具有竞争力和最先进的姿态检测和机器人检测方法,包括:Adaboost 分类器 (AB) [28]、决策树 (DT) [42]、随机森林 (RF) [6]、支持向量机 ( SVM)[5]、图卷积网络(GCN)[34]、图注意力网络(GAT)[55]、异构图变换器(HGT)[32]、简单异构图神经网络(S- HGN) [43],使用关系图卷积网络 (BotRGCN) [18] 和关系图转换器 (RGT) [14] 进行机器人检测。
5.2.基准性能
我们评估数据集的基线,并在 Tab5 中展示它们的检测精度和 F1 分数。 所有超参数都列在第7.3 节,可进行复现。

(基线方法在数据集上的性能。在评估期间使用最常用的关注者和朋友关系。每个基线用不同的种子进行五次,我们报告平均性能和标准差。 “/”表示数据集不包含支持基于图的方法的用户关系。最佳和次佳结果以粗体和下划线突出显示。)
我们观察到基于图的方法比基于特征的方法表现更好,所有前 3 名模型都是基于图的。此外,很明显可以观察到异构 GNN 的性能优于同构 GNN。我们推测这是因为异构 GNN 足以捕获用户之间的多重关系。RGT 可以模拟异构RGT可以模拟用户之间的异构影响,在大多数数据集上实现最佳性能。更好地利用边缘的权重和方向是未来潜在的研究方向。
5.3训练集大小的研究
我们选择每 10% 的标记用户作为测试和验证集。然后,我们利用不同比例的标记用户作为训练集,从 10% 增加到 80%图 7 显示了不同训练集下的基于图的模型性能。
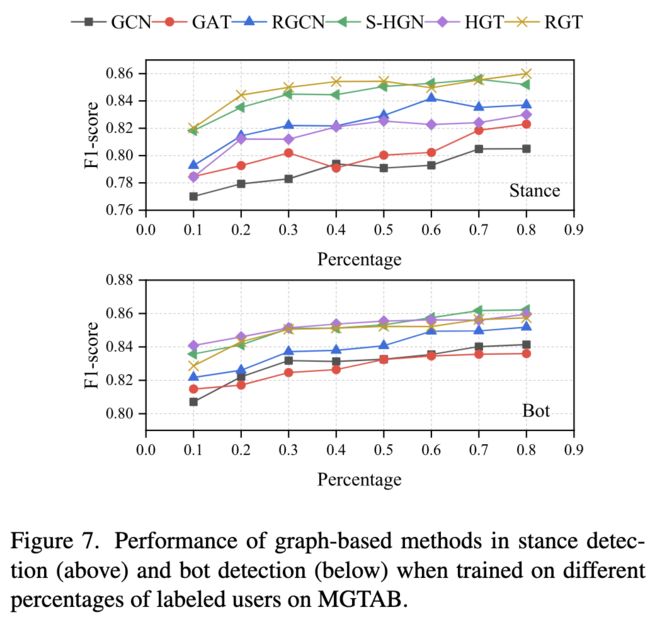
在不同的训练集下,异构 GNN 的性能优于同构 GNN。这种现象与第5.2节中的结果一致。
随着更多注释数据的使用,所有检测模型都变得更加有效。现有的帐户检测方法通常受到监督并依赖于大量标记数据。 MGTAB 的大规模有助于训练更好的检测模型。此外,MGTAB 还提供了 400,000 个未标记用户来支持半监督帐户检测方法的研究。据我们所知,MGTAB 在帐户检测领域拥有最多的未标记用户。
5.4 社会图关系分析
在本节中,我们分析了在 MGTAB 中使用各种关系的影响。除了单一关系,我们还尝试使用多重关系.我们随机进行1:1:8的分区作为训练、验证和测试集。这个分区在7.1节和7.2节的所有实验中共享。
表6 说明了当使用更多关系时,基于图形的帐户检测方法表现更好。这一趋势表明,未来对帐户检测的研究应侧重于更好地利用用户之间的多种关系。此外,我们观察到话题共现在所有关系中表现最差。我们怀疑这是因为标签共现是高度随机的,两个不相关的用户可能会出现话题共现。虽然MGTAB为URL和话题共现关系提供了边缘权重,但现有的基于图的帐户检测模型不能充分利用它们,导致性能较差。

(使用不同关系的基于图的检测方法在 MGTAB 上的准确性。每个基线用不同的种子进行五次,我们报告平均性能和标准差。最佳结果以粗体突出显示)
6. 结论
我们介绍了 MGTAB,这是一个用于姿态检测和机器人检测的大规模数据集。我们使用专家注释和多数投票来确保高质量的注释。为了构建标准化数据集,我们选择了 20 个信息增益最高的用户特征,这些特征在实验中被证明是最有效的。我们提取了 7 种用户之间的关系,并简化了复杂的 Twitter 网络。与之前的数据集相比,MGTAB 可以更好地支持基于图的账户检测方法的研究。我们的实验发现,基于图形的方法通常比基于特征的方法更有效,并且在引入多重关系时表现更好。
7. 补充资料
7.1.特征分析
特征的信息增益。在用户立场检测中具有前 10 IG 的布尔和数值特征及其 IG 显示在表7中。
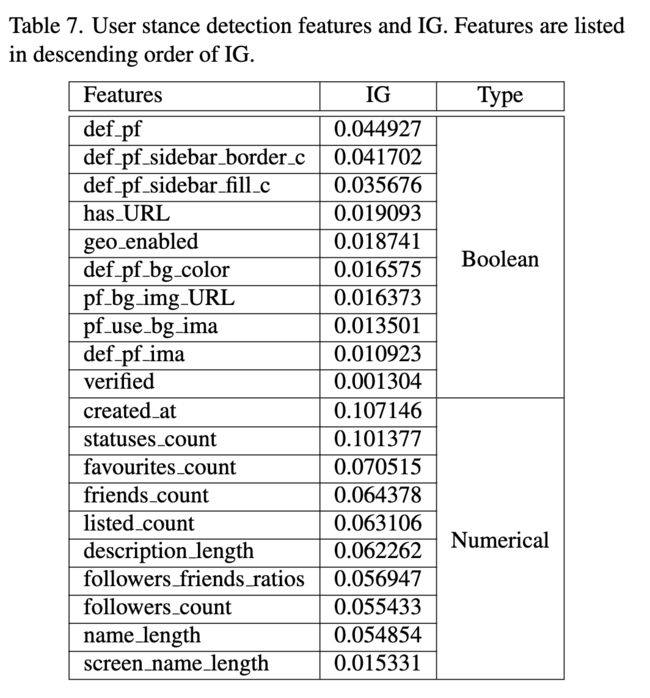
表8显示了机器人检测中排名前10的 IG 及其 IG 的布尔特征和数值特征。

特征有效性分析。用户特征表示的详细信息显示在表10中。文献中提出的许多工作都解决了帐户检测的不同特征。为了进一步证明本文提取的特征的有效性,使用从不同文献[18,33,61]设计的属性特征来比较不同模型在最常用的朋友和追随者关系下的性能[18 ].在实验中,我们只使用了属性特征,结果如表11所示。

7.2. 不同 BERT 模型的影响
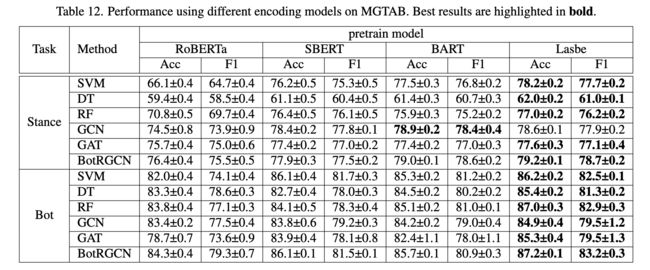
MGTAB 数据集中包含的 54 种语言如表 9 所示。为了证明使用 LaBSE [13] 编码的有效性,在本节中,我们采用四种预训练的编码模型,LaBSE、RoBERTa [41]、SBERT [51]和 BART [37] 对用户推文进行编码。
使用上述模型对用户的所有推文进行编码的结果显示在表12中。 与其他模型相比,使用 LaBSE 的检测性能更好。我们推断这是因为在使用英语预训练模型对多语言文本进行编码时会引入噪声。LABSE可以将不同语言的文本编码到一个共享的嵌入空间中,更适合于收集到的多语言文本。
7.3实验细节
实验设置。在本文中,对于所有的 GNN 模型,我们堆叠 2 层 GNN 和两个全连接层,中间 GNN 层的输入和输出维度是一致的,分别为 64、128 或 256。我们使用 ReLU 作为激活函数并将学习率设置为 0.0001 到 0.01。此外,辍学率在 0.3 到 0.5 之间。我们在 GAT 中将注意力头的数量设置为 8。我们在 RGT 中将 transformer attention heads 和 semantic attention heads 的数量设置为 4。 S-HGN中β为0.05,其余保持默认。我们使用 Adam 优化器对所有 GNN 模型进行了 300 轮训练。对于机器学习模型,AB 和 RF 的估计器数量分别设置为 50 和 100。我们在配备 9 个 TITAN RTX GPU 的服务器上运行了所有实验。
数据集处理。对于 SemEval-2016 T6 [47],我们提取了 IG 的 20 个最大特征:正面词的数量,负面词数、正面情绪数、负面情绪数、名词词频、代词词频、动词词频、形容词词频、特殊符号数、问号数、大写词数、引用词数、转发计数、提及计数、URL 数量、hastags 熵、hashtags 数量和大写 hashtags 数量。对于 SemEval-2019 T7 [25],该特征是使用 RoBERTa [41] 提取的。对于 TwiBot-20 [17],我们遵循 [18] 进行数据集处理和特征提取。对于 Cresci-15 [9]、Cresci-17 [10] 和 TwiBot-22 [15],我们按照 [15] 进行数据集处理和特征提取。