用于小物体检测的切片辅助超推理SAHI实现YOLOv8推理
何为小物体检测?
在目标识别与定位的应用场景中,难免会碰到目标物在图像中的尺寸相对较小的情况,例如下图所示。这些物体通常空间范围有限、像素覆盖率较低,且由于其外观小、信噪比低,为检测任务带来较大的挑战。
小物体检测应用场景
小物体检测应用场合具体如下:
- 安保:识别和跟踪拥挤区域的小物体,以加强公共安全。
- 自动驾驶:检测行人、骑行者以及交通标志等,确保导航安全。
- 医学成像:定位医学图像中异常和病变,用于早期疾病诊断和治疗计划。
- 遥感和航空图像:识别卫星图像中的小物体,用于城市规划和环境监测。
- 工业检测:制造和生产过程中的缺陷检测及质量控制等。
- 生命科学:分析细胞结构和微生物,用于生物学和遗传学研究。
- 机器人操作:在自动化任务中准确检测小物体,实现机器人的有效操作。
为什么传统物体检测技术无法识别到小物体?
目前有多种物体检测算法,如Faster RCNN、YOLO、SSD、RetinaNet、EfficientDet等,这些模型大多数都是在COCO数据集上训练的。COCO是包含丰富物体类别和标签的大量数据集,很适用于训练物体检测器。然而,事实证明这些模型无法检测到小物体。这是为什么呢?
感受野有限
如下图所示。感受野(Receptive Field)是指在神经网络中,每个神经元对输入数据的感知范围或影响范围。它表示了一个神经元能够“看到”的输入数据的局部区域大小。
在卷积神经网络(CNN)中,感受野的大小取决于网络的结构和层次。每个卷积层通过卷积操作将输入特征图转换为输出特征图。**在这个过程中,每个输出特征图上的神经元只能感知到输入特征图上对应位置的一小部分区域。**这意味着,网络可能无法充分了解较小物体周围的上下文信息,检测器难以准确检测和定位这些物体。

特征表示的局限性
CNN在训练过程中通过学习从原始图像中提取有用信息的特征来识别物体。然而,由于网络的局限性,学习到的特征可能无法充分捕捉到较小物体的微妙而复杂的细节。这可能导致检测器无法将较小的物体与背景或其他外观相似的物体区分开来。例如下图所示。

尺度变化的影响
小物体与较大物体相比,会表现出明显的尺度变化。这种尺度上的差异可能导致较大物体组成的数据集上训练的物体检测器难以泛化到小物体上。

训练数据偏差的影响
大物体在训练数据集中普遍存在,导致模型在检测较小物体时表现不佳。由于数据集中大物体样本数量较多,较小物体的样本数量较少,使得模型对较小物体的识别能力不足。这种偏差会导致较小物体实例缺乏鲁棒性,从而降低了检测精度。根据图示散点图,可以观察到类别 "0 "的数据点明显多于类别 "1 ",进一步凸显了数据集中大型物体的偏差问题。

CNN架构的影响
由于CNN网络的特征图空间分辨率有限,对于较小的物体,在较低分辨率下,精确定位所需的细粒度细节可能会丢失或无法区分。并且,小物体可能会被其他较大物体或杂乱的背景遮挡,从而进一步加剧定位挑战。

现有的小物体检测方法
计算机视觉技术中有一些常见的可以帮助提高小物体检测性能的方法,具体如下。
图像金字塔
图像金字塔是一种常用的技术,用于处理不同尺度的物体检测。它通过下采样或上采样来创建输入图像的多个缩放版本,每个缩放版本或金字塔级别可提供不同的图像分辨率。物体检测器可在每个金字塔级别应用检测算法,以处理不同比例的物体。
如下图所示,基于图像金字塔的技术,在较低的金字塔层级搜索小物体来检测小物体,因为在较低的金字塔层级,小物体可能更突出,更容易分辨。

滑动窗口方法
该方法通过在图像上以不同位置和比例滑动固定大小的窗口来进行物体检测。在每个窗口位置,物体检测器应用分类模型来确定窗口内是否存在目标对象。通过考虑不同的窗口大小和位置,检测器可以有效地搜索图像中的小物体。然而,滑动窗口方法的计算成本可能很高,特别是在处理大图像或多尺度时。因为需要在整个图像上滑动窗口,并对每个窗口进行分类模型的推理,这样会消耗大量的计算资源和时间。

多尺度特征提取
多尺度提取方法以多种分辨率处理图像或应用具有不同感受野的卷积层,通过在不同尺度下处理图像,可以获取不同分辨率的特征图。这些特征图包含了来自不同尺度的上下文信息和细节信息,从而能够更好地捕捉场景中的小型和大型物体。
这种方法有助于保留与检测小物体相关的细粒度细节。

数据增强
数据增强是计算机视觉领域中常用的一种技术,可以通过生成额外的训练样本来增强小物体的检测性能。数据增强的方法包括随机裁剪、大小调整、旋转、翻转、引入人工噪声等,这些增强方法可以帮助创建数据集的变化,使得检测器能够学习小物体的鲁棒特征。此外,
增强技术还可以模拟不同的物体尺度、视角和遮挡等,通过引入这些变化,检测器可以更好地推广到现实世界的场景中,具有更好的泛化能力。
迁移学习
迁移学习是将从大规模数据集(例如ImageNet)的预训练模型中学到的知识应用于对象检测任务。预训练模型,尤其是使用深度卷积神经网络(CNN)架构的模型,可以捕获丰富的分层特征,这对于小物体的检测非常有帮助。
通过在目标数据集上微调预训练模型,物体检测器可以快速适应新的检测任务,并更好地检测小物体。
小目标检测-切片辅助超推理SAHI
SAHI(Slicing Aided Hyper Inference)是一种专为小物体检测而设计的尖端pipeline,采用了切片辅助推理和微调技术,彻底改变了物体的检测方式。
SAHI的独特之处在于它能够与任何物体检测器无缝集成,无需繁琐的微调,并在不影响性能的情况下快速应用,为小物体检测带来了重大的突破。
对Visdrone和xView数据集进行的令人难以置信的实验评估展示了 SAHI 无与伦比的有效性。在不对检测器本身进行任何修改的情况下,SAHI将FCOS的AP提高了6.8% ,将VFNet提高了5.1% ,将TOOD检测器提高了5.3% 。
不仅如此,SAHI还引入了突破性的切片辅助微调技术,进一步提升了检测精度。通过对模型进行微调,SAHI使得FCOS的AP累积增益飙升至惊人的12.7%,VFNet提高了13.4%,TOOD检测器更是提高了14.5%。
切片辅助微调
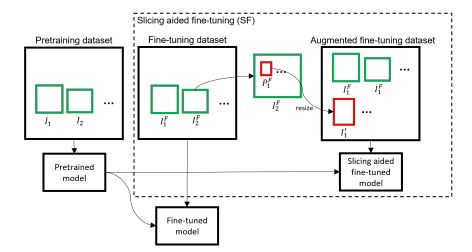
Detectron2、MMDetection 和YOLOv8等主流的目标检测框架在ImageNet和MS COCO等广泛使用的数据集上提供预训练的权重。预训练可以使用较少量的数据集和较短的训练持续时间对模型进行有效的微调,而无需使用大量数据集从头开始训练。通常用于预训练的数据集可能由低分辨率图像组成,而且相对较大的物体可能占据了图像的很大一部分。预先训练的模型在类似的输入上表现良好,但在先进无人机和监控摄像头捕获的高分辨率图像中检测小物体时可能会遇到一些困难。这是因为预训练模型通常在低分辨率图像上进行训练,而高分辨率图像中的小物体可能相对较小,并且可能受到图像质量、视角、遮挡等因素的影响。因此,预训练模型可能无法很好地适应这些特定的场景和小物体检测需求。 为了克服这一限制,提出了一种通过从微调数据集图像中提取补丁来增强数据集的方法,可以改善小物体检测性能。
如下图所示。针对每个图像,采取了将其分割成尺寸为M和N的重叠块的方法。其中,M和N的维度是从预定义范围[Mmin, Mmax]和[Nmin, Nmax]中选择的超参数。在微调过程中,这些补丁会调整大小,同时保持纵横比。调整大小的补丁会创建增强图像,旨在增加对象与原始图像相比的相对大小。此外,在微调过程中还使用了原始图像。这种对原始图像的利用有助于有效地检测大型物体。通过结合使用调整大小的补丁和原始图像,模型可以学习到适应不同尺度的物体,并提高对大型物体的检测能力。
切片辅助超推理
如下图所示,在推理过程中采用了切片法,最初,原始图像被划分为尺寸为M×N的重叠块。随后,在保持纵横比的同时调整每个补丁的大小,再将独立的对象检测前向传递应用于每个重叠的补丁。此外还可以使用原始图像执行可选的完整推理步骤来检测较大的物体。最后,使用非极大值抑制(NMS)将重叠块的预测结果以及结果(如果适用)合并回原始图像大小。在NMS过程中,交并集(IoU) 比率高于预定义匹配阈值的框被视为匹配。对于每次匹配,检测概率低于阈值的结果将被丢弃。这确保了仅保留最置信且不重叠的检测。

使用SAHI技术对YOLOv8进行推理
这里使用预训练的YOLOv8-S模型进行推理。
准备工作
安装最新版本的torch、sahi 和 ultralytics 库
pip install -U torch sahi ultralytics
导入所需的模块和函数
import os
os.getcwd()
# arrange an instance segmentation model for test
from sahi.utils.yolov8 import (
download_yolov8s_model,
)
from sahi import AutoDetectionModel
from sahi.utils.cv import read_image
from sahi.utils.file import download_from_url
from sahi.predict import get_prediction, get_sliced_prediction, predict
from IPython.display import Image
下载YOLOv8模型的权重文件
# download YOLOV5S6 model to 'models/yolov5s6.pt'
yolov8_model_path = "models/yolov8s.pt"
download_yolov8s_model(yolov8_model_path)
# download test images into demo_data folder
download_from_url('https://raw.githubusercontent.com/obss/sahi/main/demo/demo_data/small-vehicles1.jpeg', 'demo_data/small-vehicles1.jpeg')
download_from_url('https://raw.githubusercontent.com/obss/sahi/main/demo/demo_data/terrain2.png', 'demo_data/terrain2.png')
创建对象检测模型
使用AutoDetectionModel 类从预训练的YOLOv8模型创建一个对象检测模型。
detection_model = AutoDetectionModel.from_pretrained(
model_type='yolov8',
# YOLOv8模型的路径
model_path=yolov8_model_path,
# YOLOv8模型的路径
confidence_threshold=0.3,
# 设备类型。
# 如果您的计算机配备 NVIDIA GPU,则可以通过将 'device' 标志更改为'cuda:0'来启用 CUDA 加速;否则,将其保留为'cpu'
device="cpu", # or 'cuda:0'
)
执行切片推理
要执行切片推理,我们需要指定切片的参数。在这里,我们将使用256x256大小的切片,并设置重叠比例为0.2。并根据输入图像的大小设置slice_height’、‘slice_width’、‘overlap_height_ratio’、‘overlap_width_ratio’ 。这主要是一个试错过程,因为没有最适合所有类型图像的默认值。随着切片数量的增加,需要更多的计算能力。这绝对是CUDA加速最有帮助的地方。
result = get_sliced_prediction(
"demo_data/small-vehicles1.jpeg",
detection_model,
slice_height = 256,
slice_width = 256,
overlap_height_ratio = 0.2,
overlap_width_ratio = 0.2
)
可视化预测对象
result.export_visuals(export_dir="demo_data/")
Image("demo_data/prediction_visual.png")
预测结果
预测结果以sahi.prediction.PredictionResult的形式返回,可以通过以下方式访问对象预测列表:
object_prediction_list = result.object_prediction_list
object_prediction_list[0]

ObjectPrediction对象也可以转换为COCO标签格式:
result.to_coco_annotations()[:3]
