【Linux】进程间通信(匿名管道、命名管道、共享内存等,包含代码示例)
进程间通信
- 前言
- 正式开始
-
- 理解进程间通信
- 一些标准
- 管道
-
- 原理
- 管道演示
- 匿名管道
-
- 代码演示
- 原理
- 进程池
- 管道大小
- 命名管道
-
- 演示
- 代码
- 分配消息例子
- systemV共享内存
-
- 共享内存流程
-
- 获取key值
- shm的创建
- shm的删除
- 关联
- 去关联
- 完整流程演示
- 开始通信
- systemV 消息队列
- 基于对共享内存的理解
-
- 几个概念

前言
这篇本来应该一个月前都写了,但是有些C++的内容我前面的博客没讲,所以上一个月把C++剩余的所有博客都赶完了,以免后续要讲其他内容的时候有耽误进度,所以后面这两个月的博客应该都是linux的了。
废话不多说了。本篇主要讲了进程间通信的概念,管道(匿名和命名),systemV(主讲共享内存),以及对于进程间通信总结性的理解。
正式开始
进程间通信 — IPC。
就是用来让两个进程之间交互数据的。
其目的在于(可以先不看):
- 数据传输:一个进程需要将它的数据发送给另一个进程
- 资源共享:多个进程之间共享同样的资源。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变
我前面的博客所讲的都是单进程的,没有使用并发能力,更无法实现多进程协同。这篇就讲的是多进程间的协同。
理解进程间通信
来个例子:我前面Linux的博客中提到过管道 | ,就是让一个进程的结果交给另一个进程。
我们生活中也有管道,比如说自来水管道,天然气管道,石油管道等等,都是有入口有出口。生活中的这些管道一般都是单向传输资源的。那么类比到命令行中的 | ,也是如此。进程A通过管道向进程B单向传输数据。
以管道为例来讲讲进程间通信。
最重要的一点:
进程具有独立性(PCB,地址空间,页表等等)
正因为进程具有独立性,两个进程之间没有的相关联的地方,所以想要使得两个进程之间相互“交流”,就得让两个进程之间先建立起一种“联系”。
如何建立联系呢?
让两个进程看到同一片空间。然后让一个进程负责往这片空间中放东西,一个进程负责往这片空间中取东西。这样就建立起了联系,也就实现了两个进程的通信。
那么这块空间用什么来表示呢?
答案是内存。
把一个进程连接到另一个进程的一个数据流称为管道。
管道不能属于任何进程,由操作系统提供。
因为进程具有独立性,管道属于中间资源,任何中间资源给了某一个进程,就会导致其他进程看不到这个资源,所以说中间的资源得由操作系统来提供。
先打住,等会再细讲这些内容,先看看进程通信的标准。
一些标准
如下(后两个标准可以先不管,这里主要讲第一个):
- Linux能够原生提供的管道(至于为什么等会讲管道的时候就知道了)。管道分匿名管道和命名管道。
- System V进程间通信,用于多进程的,适用于单机通信。
- posix进程间通信,用于多线程的,适用于网络通信。
管道
原理
这里要各位比较了解Linux下的文件管理,如果不懂的同学可以看看我这篇博客:【Linux】基础文件IO、动静态库的制作和使用
这里的知识完全就是文件IO中的知识。
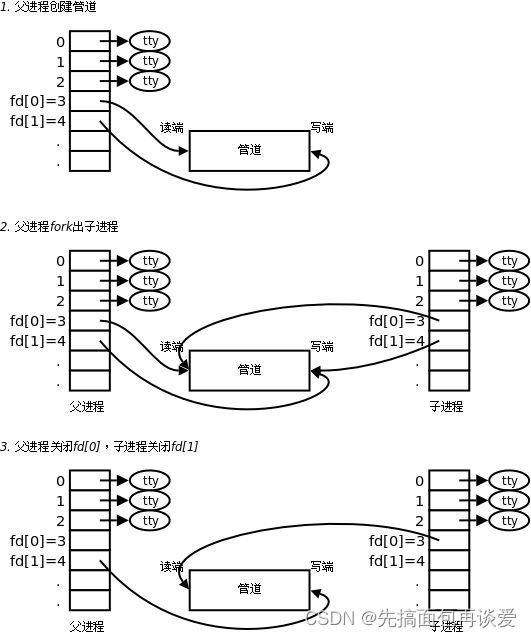
假如说此时有个进程,我们先画出这个进程的PCB、files_struct以及其打开的0、1、2文件。
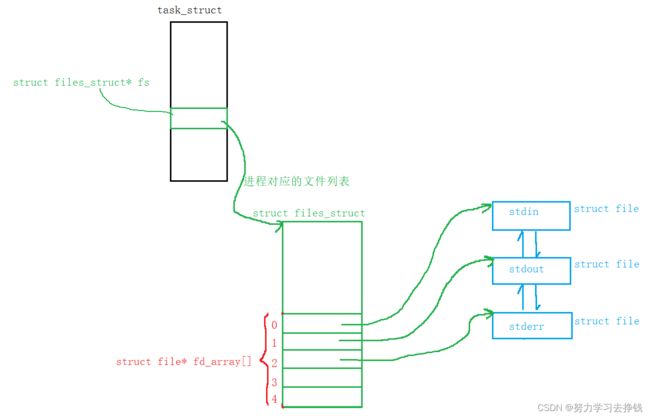
这和管道有什么关系呢?
前面说了,如果想让两个进程进行通信,就得先让两个进程看到同一份内存。
那么我们就可以让当前进程分别以读和写的方式打开一个文件:

此时再创建一个子进程,这样子进程就会继承当前进程大部分的内核数据结构,而文件对应的内核数据结构是由操作系统管理的,那么父子进程就会指向同样的文件:
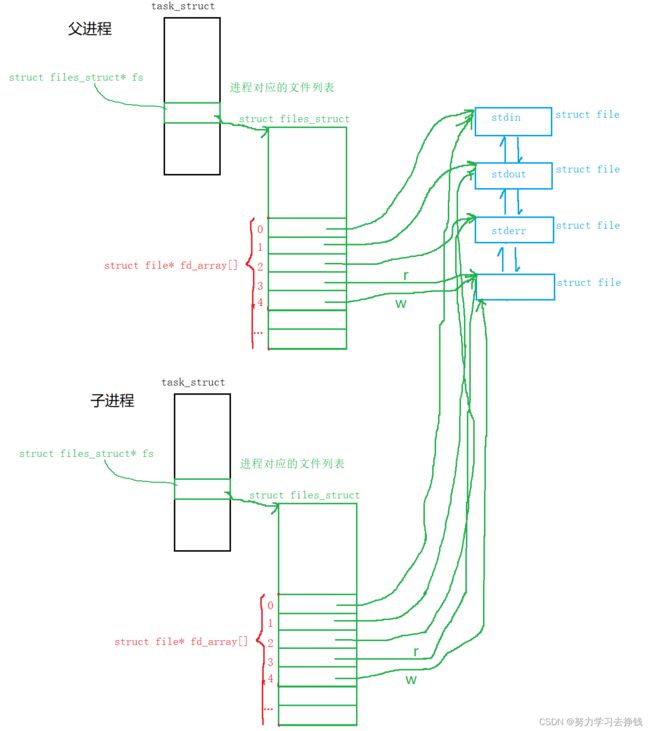
这样的话,两个进程就同时看到了一块空间,也就是一个文件。但是这里的文件和我们平时的文件优点不一样,这里的文件不会存放到磁盘上,是一个临时的文件,因为进程间通信的大部分数据是临时数据,而写入到磁盘中就使得这些数据持久化了,而且写到磁盘上的速度很慢,会降低通信的效率,所以完全没有必要写到磁盘上,纯内存级的通信方式足以,效率更高,所以不会写到磁盘上。
子进程创建完之后还要干一件事,就是让两个进程关闭各自不需要的文件,准确来说是关闭新打开文件的w或者r,比如说让父进程进行写入,就要关闭父进程的读端,让子进程读取,就要关闭子进程的写端,这样就是把一个进程的数据传给了另一个进程,当然不关的话也可实现,但是为了安全起见还是关掉的好,不然可能会因为操作不当而导致该写的进程进行了读操作等等。
父写子读,对应的图就是这样:

管道演示
前面的博客中也说过的,这里简单看一个。
who命令显示当前登录服务器的人员:

who | wc -l显示当前登录服务器
再来看个:
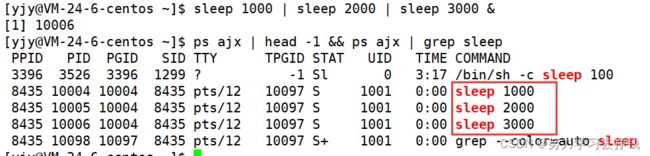
搞了三个sleep进程。
这样一个进程把数据处理再经过管道交给下一个进程就叫做进程间协同。

jobs可以看到这个后台任务在运行,为[1]号进程,fg 1将其调到前台,ctrl+c干掉就行。
就演示到这。
匿名管道
这里要讲一下pipe函数:
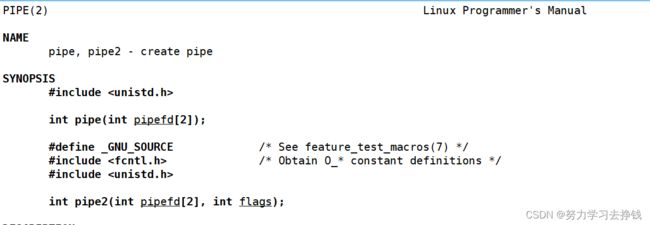
pipe就是搞一个匿名管道,也就是上面讲原理的那个过程。

大概功能就是那个进程调用就让这个进程以读写方式打开同一个文件,我们不需要指定文件名,因为文件是纯内存级的。如果创建文件成功了就返回0,如果失败了就返回-1,并且设置错误码。
pipe中用到了一个输出型参数,是一个数组pipefd,这里面存放的就是对应打开文件的读端和写端,pipefd[0]就是读端,pipefd[1]就是写端。
代码演示
#include 上方代码中只有子进程向屏幕打印,父进程每隔一秒向管道文件中写入数据,而子进程一直在文件中读取数据,已得到信息就会直接打印到屏幕上。
写入的一方fd没有关闭,读取的一方,如果有数据,就读,没有数据就等。
写入的一方fd关闭, 读取的一方,read会返回0,表示读到了文件的结尾。
比如说这里父进程1没关的时候,子进程一直在等,父进程一写入就读;父进程的1关了之后,子进程read返回0,此时控制子进程不要再读了,直接关掉pipefd[0]就行。
运行起来:
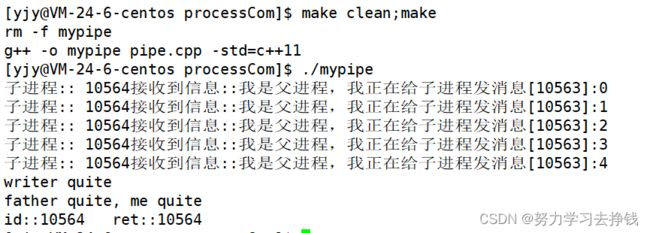
上方的代码就是基于管道的原理写出的。
自问自答一下。
问:为什么不能定义一个全局的变量buffer来作为缓冲区进行通信?这个buffer父子进程不是都会拿
到吗?父子进程的数据是私有的,因为有写时拷贝的存在,改了父进程的buffer不会影响到子进程的buffer,子进程的buffer还是原来的buffer,所以就没办法进行通信。
管道的特点:
- 管道是用来让具有血缘关系(父子、兄弟)的进程进行进程间通信的,常用于父子通信。
兄弟进程是因为一个父进程打开多个匿名管道时就会使得多个子进程之间也可进行通信,但是不常用。 - 管道让进程间协同,提供了访问控制。
.
.
上面的代码就是一个很好的体现。管道是一个文件,是可以被写满的,所以读取的时候要有访问控制,不能说一直写但是很久才读一次,这样就会出现管道被写满的情况,这里演示一下:
.
.
我把代码稍微改改,子进程中缓冲区大小改为1024 * 8,每隔5秒才读一次,然后让父进程不sleep,直接写,并附带上一句count的打印:

可以看到,父进程先把管道写满了,count到了1138,然后子进程此时等了5秒,读取,打印了一堆东西,都是管道中的,而且还有很多没有读完。而且中间父进程穿插着打印了count::1139(我没有截上)。显示器也是一个文件,父子进程同时往显示器写入的时候就会抢着打印,这就是缺乏访问控制,这也是为什么我之前讲进程控制的时候说没有控制条件不能确定父子进程打印的先后顺序。 - 管道提供的是面向流式的通信服务——面向字节流
写入次数与读取次数没有直接关系,如写10次1次读完,写1次分10次读完,这就是流式服务,需要定制协议来进行数据区分,但是现在没法讲这个,以后再说。 - 管道是基于文件的,打开的文件生命周期是基于进程的,那么管道的生命周期也就是基于进程的。
当只剩一个进程打开了一个文件时,该进程关闭,对应文件描述符关闭,文件也就随之关闭,管道是当父子进程都退出时就直接释放。 - 管道是单向通信的,就是半双工通信的一种特殊情况。
半双工就是是指要么在接收信息,要么在发送信息。在某一时刻来判断,比如正常聊天时一个人说,一个人听,这就是半双工。还有全双工,就是某一时刻既可以发送又可以接收,比如吵架的时候两个人各吵各的,但是吵的同时还听着对方的信息。
管道的四种情况:
- 写慢,读快,管道没有数据时就必须等待,对应最初的代码。
- 写快,读慢,写满不能再写
- 写关闭,读继续,直接读到文件结尾,返回0
- 读关闭,写继续,os终止写进程
演示下第四个,子进程代码先改:

然后运行起来就是:

可以看到虽然这里父进程还是往管道中写了内容,但是这些也是在子进程关闭读端之前写的,因为打印也是会有时间消耗的,在关闭前子进程打印了两句话,打印后就子进程就关闭读端了,关闭了读端之后os就强制终止进程了。所以这里没有了后续那么多的count。
原理
虽说匿名管道是纯内存级别的,但是其在内核中,我们无法直接访问,所以就需要用到fd来访问内核中的数据。

上面的代码中,大致流程如下:

在文件描述符角度-深度理解管道:
看待管道,就如同看待文件一样,管道的使用和文件一致,迎合了“Linux一切皆文件思想”:

上面的数据页就指的是匿名管道在内存中的空间。
进程池
再来个匿名管道的扩展。
进程池,简单讲一下。让一个进程打开多个匿名管道,然后对应的匿名管道创建出子进程,然后让父进程向随机向某个匿名管道中写入数据,再让那个管道对应的子进程接收数据,把数据想像成任务,父进程发送任务,子进程接收任务,这样就是一个简单的进程池。简单画个图:
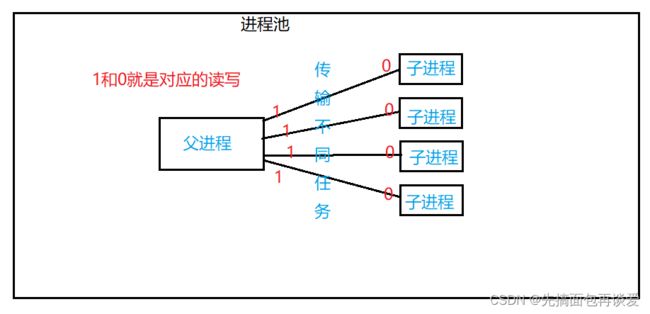
代码如下:
四个任务函数
#include主要逻辑
#include"command.hpp"
#define PROCESS_NUM 5 // 进程池中子进程数量
void writeCommand(pid_t pid, int fd, int command)
{
// 下达命令,即在管道中写入数据
int ret = write(fd, &command, sizeof(command));
if(ret == -1)
{
perror("write");
exit(2);
}
cout << "父进程[" << getpid() << "]向子进程[" << pid << "]下达命令(" << command_menu[command] << ")成功,对应fd为:" << fd << endl;
}
int readCommand(int fd, int& quit)
{
// 子进程读取命令
int command;
int ret = read(fd, &command, sizeof(command));
if(ret == -1)
{
perror("read");
exit(3);
}
else if(ret == 0)
{
quit = 1;
return -1;
}
assert(ret == sizeof(command));
return command;
}
int main()
{
// 进来先加载commands和commandMenu
load();
vector<pair<pid_t, int>> slots;
for(int i = 0; i < PROCESS_NUM; ++i)
{
int pipefd[2] = {0};
int ret = pipe(pipefd);
assert(ret == 0);
(void)ret;
// 打开的每一个匿名管道都要创建对应的子进程
pid_t id = fork();// 创建子进程
if(id == -1)
{
perror("fork");
exit(1);
}
if(id == 0) // 子进程
{
// 子进程进行读取,关掉写端
close(pipefd[1]);
// 子进程不断接收命令并执行
while(true)
{
int quit = 0;
int command = readCommand(pipefd[0], quit);
if(quit == 1)
break;
if(command >= 0 && command < commands.size())
{
commands[command]();
}
else
{
cout << "命令非法" << endl;
}
}
// 接收不到命令后再退出
exit(0);// exit会自动关闭文件描述符,不必手动关
}
// 父进程进行写入,关闭读端
close(pipefd[0]);
// 存储键值对(pid : fd)
slots.push_back(pair<pid_t, int>(id, pipefd[1]));
}
// 让生成的随机数更随机一点
srand((unsigned int)time(nullptr) ^ getpid());
// 父进程不断下达命令
while(true)
{
// 选择哪一个子进程执行命令
int childProcess = rand() % slots.size();
// 选择哪个命令,这里为了测试就搞成随机的,也可以搞成先打印命令菜单,然后再选择命令
int command = rand() % commands.size();
// 下达命令
writeCommand(slots[childProcess].first, slots[childProcess].second, command);
// 休息一秒钟,继续下达
sleep(1);
}
// 命令下达完毕,关闭写端
for(int i = 0; i < slots.size(); ++i)
{
close(slots[i].second);
}
// 等待子进程退出
for(int i = 0; i < PROCESS_NUM; ++i)
{
waitpid(-1, nullptr, 0);
}
return 0;
}
不细讲了,该注释的都注释了,有问题的私我就行。
管道大小
man 7 pipe查看:

上面写了在2.6.11版本前,一个管道大小为一页,一页就是4096字节。但在这个版本之后管道文件大小变为了65536字节。
我来写一个代码测试一下我当前的管道大小是多少:
int main()
{
// 创建匿名管道
int pipefd[2] = {0};
int n = pipe(pipefd);
assert(n == 0); // 确定返回值为0,打开了文件,否则就是打开失败
(void)n; // 这里是为了防止警告未使用的变量n
// 创建子进程
pid_t id = fork();
assert(id != -1); // 保证子进程一定创建成功
if (id == 0) // 子进程
{
// 读,关闭写端1
close(pipefd[1]);
while(1);// 子进程保持啥也不干,不退出就行
exit(0); // 子进程退出,会自动关闭子进程的文件描述符并清空缓冲区
}
// 父进程写入,关闭读端0
close(pipefd[0]);
string str = "我是父进程,我正在给子进程发消息";
int count = 1;
while (true)
{
char c;
// 用字符流插入到send_buff中
write(pipefd[1], &c, 1); // 这里不能用sizeof,不然会多写内容
cout << "count::" << count++ << endl;
}
// 通信结束,关闭父进程文件描述符1
close(pipefd[1]);
// 等待子进程退出
pid_t ret = waitpid(id, nullptr, 0);
cout << "id::" << id << " ret::" << ret << endl;
assert(ret > 0); // 确保成功等待子进程
(void)ret; // 与上方n同理
return 0;
}
测试:
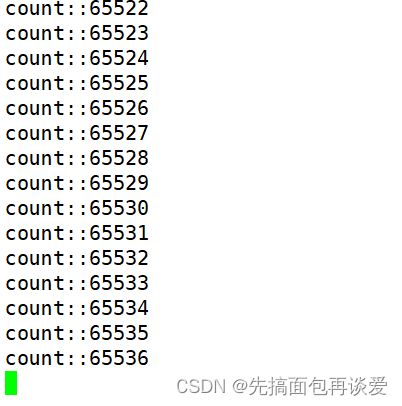
就是65536,也就是说我的linux版本是2.6.11之后的,也可以用uname -r来看一下我的版本:

命名管道
前面说了,而匿名管道是用来让拥有血缘关系的进程来进行通信的。
而这里的命名管道是用来让不相关的进程进行通信的。但原理是一样的,还是让两个进程看到同一份资源,这份资源也是文件,但是这个文件在磁盘上有文件名,那么也就有其路径,是可以被打开的,但是大小为0,也就是说两个进程通信的数据不会被写到磁盘上,这一点和匿名管道还是很像的,当两个进程同时打开这个文件时就可以通过该管道文件的路径看到同一份资源。
命令行上可以用mkfifo来创建一个管道文件:
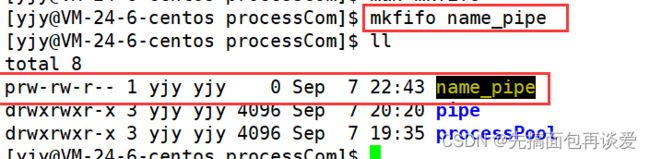
可以看到文件类型那里是p,也就是pipe,管道文件。fifo就是first in first out,文件里面就是先入先出的,先写入的东西先被读取。
命令行上的命令也是进程,所以我这里就通过命令行来先简单演示一下命名管道的通信。
演示
演示前要说一下,命名管道独有特性:
若一进程以只写方式打开管道文件,则阻塞,知道该管道文件被任意进程以读的方式打开;
若一进程以只读方式打开管道文件,则阻塞,知道该管道文件被任意进程以写的方式打开;
因为一个管道如果不构成同时读写,就不存在进程间的通信,也就没必要开缓冲区。
所以说我先向管道文件中写:
直接就卡这了,也就是阻塞,在等待另一个进程对该文件进行读取:

这样就打印出来了。
再来看,写一个命令行脚本,间隔一秒循环写入:

还是先卡住了,读取:

就会直接打印到另一个会话框当中,其实这也相当于是一种重定向,从管道文件中重定向到显示器这个文件中。
当我们终止掉读端进程后,因为写端执行的循环脚本是由命令行解释器bash执行的,所以此时bash就会被操作系统杀掉,我们的云服务器也就退出了:

前面也是说过了,当读端的进程退出后,写端的进程也就没有必要继续写下去了,os会将其强制退出,所以这里直接退出云服务器了。
想删除管道文件的话,可以用rm,也可用unlink:
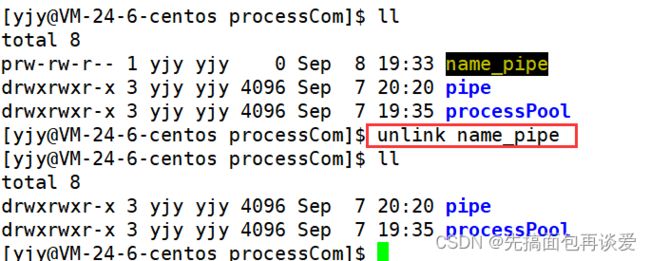
其实普通文件也可以用unlink,只不过rm用的更多点。
但是我们可不是想要通过手动的这样mkfifo创建管道文件和删除管道文件,我们想要的是代码,所以这里就写一个代码的例子。
代码
首先就是用啥创建管道文件:
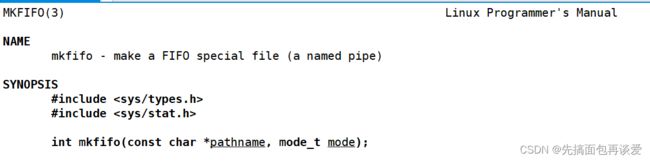
还是mkfifo,不过这里的mkfifo不是命令行上的了,而是一个函数。
两个参数。
第一个参数是你想要创建的管道文件的文件名是啥。
第二个参数是你创建出来的管道文件的权限是什么。权限我就不细讲了,不懂的同学看这篇:【linux】对于权限的理解
返回值:成功创建返回0,失败返回-1并设置errno。
这个mkfifo就介绍完了,下面来说一个demo的思路。
首先,我要搞两个进程,所以两个.cpp文件,然后让一个文件中创建管道文件并进行读取,再让另一个文件打开管道文件进行写入。
这两个.cpp文件肯定有很多共有的头文件,所以我就再写一个comm.hpp来表示共同的头文件。
然后就没啥好说的了,代码如下:
我将这两个.cpp文件分为服务端和客户端,客户端负责发消息,服务端负责接收消息。
服务端
#include"comm.hpp"
int main()
{
// 修改一下权限掩码,方便等会确定生成的管道文件的权限
cout << umask(0) << endl;
// 创建管道文件
if(mkfifo(str, 0666) < 0)
{
// 创建文件失败
perror("mkfifo");
exit(1);
}
Log("server create fifo", Debug);
// 正常文件操作
int fd = open(str, O_RDONLY);
if(fd == -1)
{
// 打开文件出错,打印日志
Log("open fail", Error);
exit(2);
}
// 文件读取
char buf[SIZE];
while(true)
{
int ret = read(fd, buf, sizeof(buf) - 1);
if(ret > 0)
{
buf[ret] = 0;
cout << "server get mesg::" << buf << endl;
}
else if(ret == 0)
{
Log("read over", Debug);
exit(3);
}
else
{
Log("read error", Debug);
exit(4);
}
}
// 关闭文件描述符
close(fd);
return 0;
}
客户端:
#include"comm.hpp"
int main()
{
// client不需要创建文件,直接打开文件进行写入就行
// 正常文件操作
int fd = open(str, O_WRONLY);
if(fd == -1)
{
// 打开文件出错,打印日志
Log("client open fail", Error);
exit(1);
}
Log("client open file sucess", Debug);
// 进行写入
while(true)
{
string str;
cout << "client send mesg::";
cin >> str;
ssize_t ret = write(fd, str.c_str(), str.size());
if(ret == -1)
{
Log("client write fail", Error);
exit(2);
}
}
return 0;
}
共同引用的文件
#pragma once
#include当server端运行起来的时候会创建一个管道文件,然后等待client端写入:
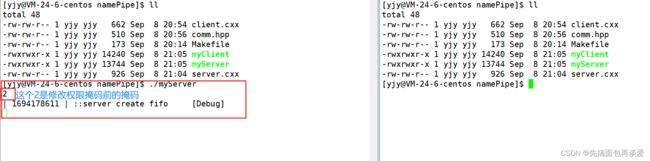
当client端打开文件时,server端开始接收:

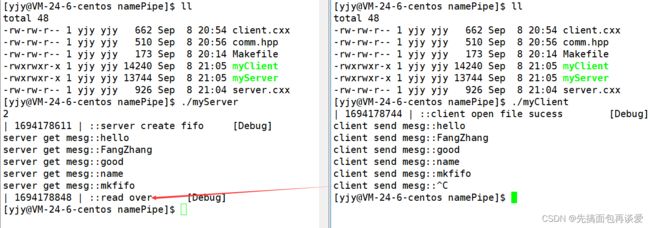
当client端关闭时,server端读到文件末尾,也就随之退出:
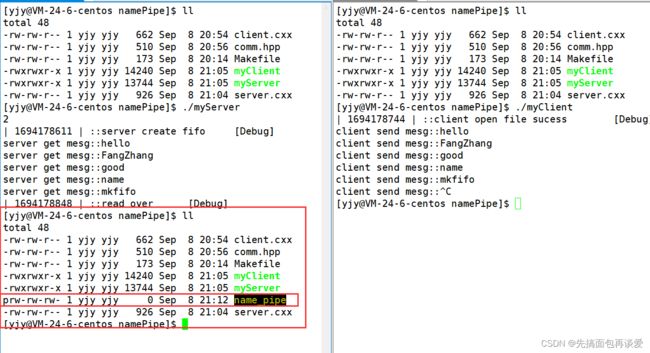
再看一下生成的管道文件:
这就是命名管道的一个简单样例。
上面的client和server这两个进程是没有血缘关系的两个进程,这也就是匿名管道要解决的,让不想关的进程进行通信。
分配消息例子
我们也可以通过命名管道来实现和上面匿名管道类似的进程池的功能,但是也不应该叫进程池了,但原理还是很类似的。
跟刚刚演示的大差不差,只不过是让server端多几个子进程来分配任务。
只改了server端,代码如下:
#include"comm.hpp"
void readMesg(int fd)
{
// 文件读取
char buf[SIZE];
while(true)
{
int ret = read(fd, buf, sizeof(buf) - 1);
if(ret > 0)
{
buf[ret] = 0;
cout << "childProcess[" << getpid() << "] get mesg::" << buf << endl;
}
else if(ret == 0)
{
Log("read over", Debug);
exit(3);
}
else
{
Log("read error", Debug);
exit(4);
}
}
}
int main()
{
cout << umask(0) << endl;
// 创建管道文件
if(mkfifo(str, 0666) < 0)
{
// 创建文件失败
perror("mkfifo");
exit(1);
}
Log("server create fifo", Debug);
// 正常文件操作
int fd = open(str, O_RDONLY);
if(fd == -1)
{
// 打开文件出错,打印日志
Log("open fail", Error);
exit(2);
}
// 创建几个子进程来进行读取
int processNum = 3;
for(int i = 0; i < processNum; ++i)
{
pid_t id = fork();
if(id == 0)
{
Log("child process readMesg", Debug);
readMesg(fd);
}
}
for(int i = 0; i < processNum; ++i)
{
waitpid(-1, nullptr, 0);
}
// 关闭文件描述符
close(fd);
return 0;
}
运行效果如下,子进程抢着接收:

写入退出,子进程读取也就退出:

就不细讲啥了。
systemV共享内存
原理也跟管道差不多,都是让两个进程看到同一份资源,但是这里不再是原生文件了,而是操作系统专门提供的一种通信方式,也就是直接让两个进程在内存中看到同块空间,其实也就类似于匿名管道那样,不过是不再是文件了,而是操作系统直接提供的内核结构。
看图:
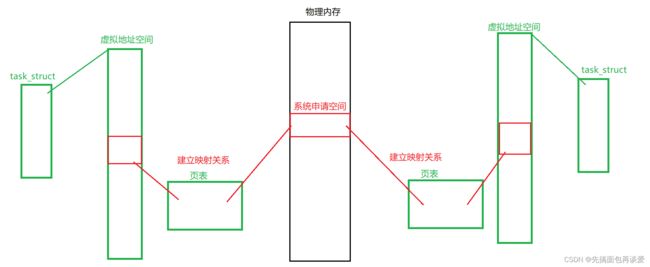
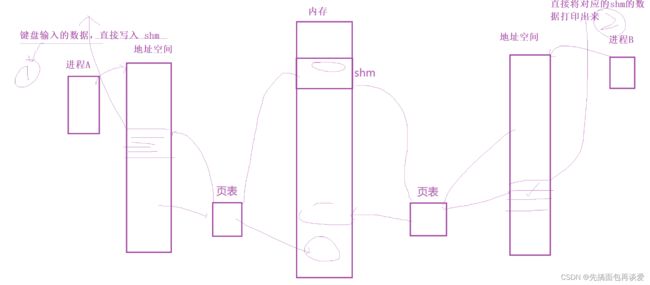
创建共享内存的时候,os先在内存中开空间,然后将该块空间的地址通过页表映射到两个进程的共享区(堆和栈之间)中,当两个进程想要进行读写操作时,通过相对地址就能找到这块申请的空间。所以一共分为两步,第一步是os申请空间,第二步是建立映射关系。释放共享内存的时候只要先去掉映射再释放申请的空间就行了。
共享内存只属于操作系统,不属于任何进程,是由操作系统单独提供的内核结构,而且是专门为了进程间通信而提供的。
一对进程通信就要开一块共享内存,当多对进程通过共享内存进行通信时,就会产生很多的共享内存,共享内存一多,操作系统就得要将共享内存管理起来,还是先描述再组织的方法。所以说共享内存不仅仅是一块空间,还包括了对应的内核数据结构。
共享内存 = 共享内存块 + 对应的共享内存的内核数据结构
概念就先将这些,下面说怎么做。
共享内存流程
我们需要通过一个函数来搞共享内存:

这个函数介绍的就是申请一块systemV共享内存块。
先说一下返回值,返回值返回的是你所想要的共享内存的标识符,这个标识符就类似于文件描述符fd,我们对文件进行操作的时候就是通过fd,同理,我们想对共享内存进行操作就要通过这个共享内存的标识符。这个返回的整数就称之为共享内存的用户层标识符。
来挨个说一下参数。
先说shmflg
这个参数表示你要以什么方式创建共享内存。
有两个选项:IPC_CREATE 和 IPC_EXCL单独使用IPC_CREATE,如果想创建的共享内存已经有了,就返回已有的共享内存的标识符,如果没有,就创建一个共享内存并返回新创建的共享内存的标识符。
.
.
但是这里单用IPC_CREATE的缺点就是不知道得到的标识符对应的共享内存是新创建的还是旧的。单独使用IPC_EXCL没有意义,不讨论。
IPC_CREATE和IPC_EXCL合并使用,就是或起来(IPC_CREATE | IPC_EXCL),产生的效果就是如果底层共享内存不存在的话就创建一个并且返回标识符,如果存在就创建失败并设置错误码errno。
.
.
那么这个选项就能保证返回成功一定是一个全新的shm(shared memory,即共享内存)。
再来说size,其实就是你要创建的shm的大小。
这里有一个PAGE_SIZE,其实前面过道大小那里也提到过了,一页大小就是4096字节。
创建shm时,建议size是PAGE_SIZE的整数倍,因为不是整数被时,操作系统会开一个整数倍的空间大小,也就是说当size是4097时,就会开到4096 * 2,但是size是4097,也就是说用户需要的是4097个字节,那么os只会提供4097个字节,剩余的4095个字节无法访问,这样就会导致这些字节被浪费掉。所以说size要给4096的整数倍。
获取key值
最后说第一个参数key
.
要通信的双方进程,怎么能保证二者能够看到同一块shm呢?
就通过的是key,key是几不重要,重要的是只要这个key在系统中唯一就行了,让server和client端使用同一个key,就能看到同一块共享内存。
.
而key怎么生成呢?
通过一定的算法规则,库中有一个专门的函数来搞key值,就是ftok:
ftok可以将一个路径和一个项目标识符转换成key值。只要pathname和proj_id相同就能产生相同的key值。其实就跟哈希的思想差不多。我们先用代码看看:

// client和server都用这个
#define PATH "./" // 这里的路径一定要保证有权限访问
#define PROJ_ID 1234
key_t key = ftok(PATH, PROJ_ID);
// 返回值key_t类型其实就是int
.
可以看到一模一样。这样就能让两个进程访问到同一块shm了。能看到这个数还是很随机的。
那么共享内存整个流程大致分为5步。
- 获取key值
- 创建共享内存
- 进程与共享内存建立映射
- 进程与共享内存去掉映射
- 删除共享内存
其中第三步之后,就可以让进程进行通信操作了。通信完毕再去映射,删shm。
那么下面就用代码来演示。
头文件:
#pragma once
#includeshm的创建
先来点简单的:
// 获取key值
key_t key = ftok(PATH, PROJ_ID);
Log("server create key success", Debug);
// server端创建出新的shm
int shmid = shmget(key, SIZE, IPC_CREAT | IPC_EXCL);
if(shmid == -1)
{
Log("server shmget fail", Error);
exit(1);
}
Log("server shmget sucess", Debug);
sleep(10);//这里休眠10秒,方便等会观察。
Log("server quit", Debug);
上面的代码中会创建一个共享内存,然后休眠server端休眠10秒后就会退出,我们可以用ipcs -m来查看当前系统中shm的信息:

当前还未执行。
我们来一个循环打印的:
server运行:
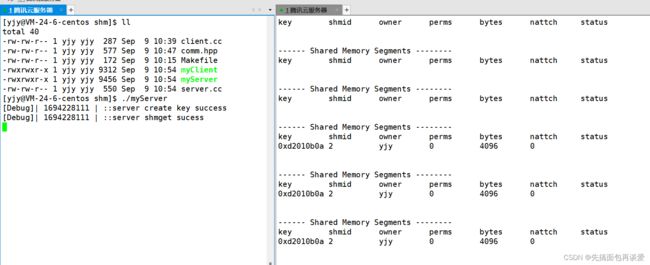
右侧会话框中显示创建了一个shm。key值和shmid等会我们自己打印出来看看,拥有者是yjy,perms是权限的意思,大小是4096字节,nattch表示连接到共享内存的的进程数,perms和nattch等会说。
status表示共享的状态(不显示则为正常使用)。
但是如果我们server端退出后,shm仍然未被删除:
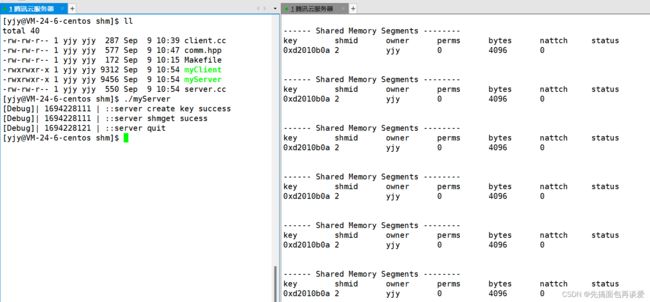
因为systemV的ipc资源生命周期是随内核的,也就是说,你不手动释放或者不重启系统,这块内存是永远存在的。
shm的删除
可以用ipcrm -m shmid来手动删除shm:
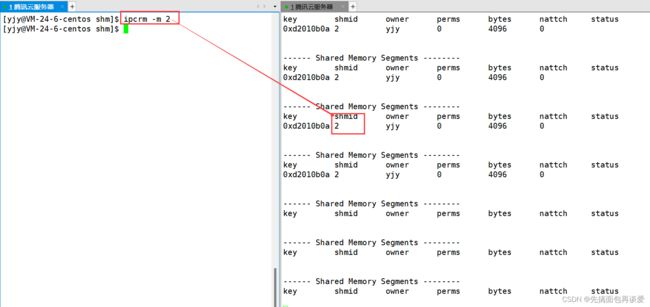
这里看到,删除用的是shmid,而非key值,前面也说了,对shm的操作用shmid。
但是如果只能手动删的话,有点麻烦,我们可以在代码中删除,用shmctl:

第一个参数shmid,表示所控制共享内存的用户级标识符。
第二个参数cmd,表示具体的控制动作。
说三个:
IPC_STAT 获取共享内存的当前关联值,此时参数buf作为输出型参数
IPC_SET 在进程有足够权限的前提下,将共享内存的当前关联值设置为buf所指的数据结构中的值
IPC_RMID 删除共享内存段
第三个参数buf,用于获取或设置所控制共享内存的数据结构。
前面说过,共享内存不光是一块内存,还包含了内核数据结构,我们这里可以通过buf来获取到shm对应的内核数据结构,但是这里我只是为了删除,给成nullptr就好。
代码如下:
string deToHex(int key)
{
// 将十进制转为十六进制
char buf[20];
snprintf(buf, sizeof(buf), "0x%x", key);
return buf;
}
int main()
{
// 获取key值
key_t key = ftok(PATH, PROJ_ID);
Log("server create key success", Debug);
cout << "key ::" << deToHex(key) << endl; // 将key值以16进制打印
// server端创建出新的shm
int shmid = shmget(key, SIZE, IPC_CREAT | IPC_EXCL);
if(shmid == -1)
{
Log("server shmget fail", Error);
exit(1);
}
Log("server shmget sucess", Debug);
cout << "shmid ::" << shmid << endl;
sleep(5);
// server删除shm
if(shmctl(shmid, IPC_RMID, nullptr) == -1)
{
Log("server del shm fail", Error);
exit(2);
}
Log("server del shm success", Debug);
// 进程退出
Log("server quit", Debug);
return 0;
}
运行:
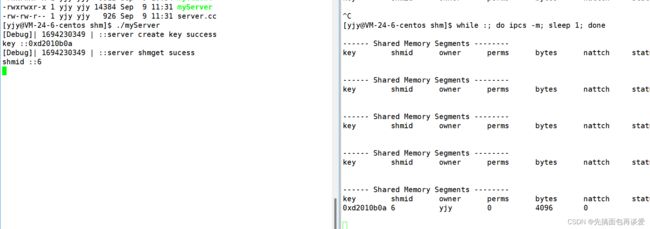
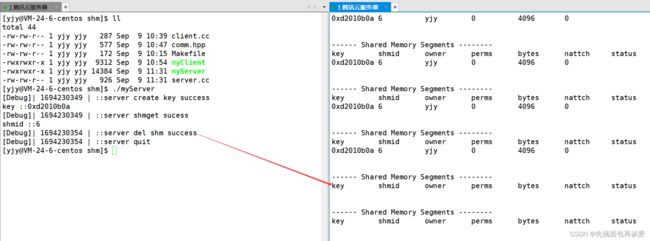
很成功。
五步,已完成三步:
- 获取key值
- 创建共享内存
- 进程与共享内存建立映射
- 进程与共享内存去掉映射
- 删除共享内存
125已经完成。
然后来说映射。
还是函数,shmat和shmdt,先说两个单词。attach和detach,分别是关联和脱离。和函数对应。
关联
shmat:

shmid不说了。
shmaddr是shm的地址,如果给nullptr的话就让操作系统自动找shmid对应的shm的地址,如果给的是shm的地址操作系统就按照这个地址来。
shmflg是文件打开方式,给0就行,就是默认以读写方式将进程与shm挂接。
返回值是进程虚拟地址空间中进程对应挂接的shm的地址。
如果失败了返回(void*)-1并设置errno。
去关联
再来说detach

直接给地址就行了,成功返回0,失败返回-1。
代码:
#include"comm.hpp"
string deToHex(int key)
{
char buf[20];
snprintf(buf, sizeof(buf), "0x%x", key);
return buf;
}
int main()
{
// 获取key值
key_t key = ftok(PATH, PROJ_ID);
Log("server create key success", Debug);
cout << "key ::" << deToHex(key) << endl;
// server端创建出新的shm
int shmid = shmget(key, SIZE, IPC_CREAT | IPC_EXCL | 0666);
// 这里要给创建出来的shm权限,不然映射的时候会出问题,对应perms
if(shmid == -1)
{
Log("server shmget fail", Error);
exit(1);
}
Log("server shmget sucess", Debug);
cout << "shmid ::" << shmid << endl;
sleep(5);
// server端与创建出的shm建立映射
char* shmaddr = (char*)shmat(shmid, nullptr, 0);
if(shmaddr == (char*)-1)
{
Log("server attach fail", Error);
exit(3);
}
Log("server attach success", Debug);
sleep(5);
// ipc
//server端与shm去掉映射
if(shmdt(shmaddr) == -1)
{
Log("server detach fail", Error);
exit(4);
}
Log("server detach success", Debug);
sleep(5);
// server删除shm
if(shmctl(shmid, IPC_RMID, nullptr) == -1)
{
Log("server del shm fail", Error);
exit(2);
}
Log("server del shm success", Debug);
// 进程退出
Log("server quit", Debug);
return 0;
}
这里运行起来大概就是,先创建shm,再映射,然后去映射,最后删除shm:
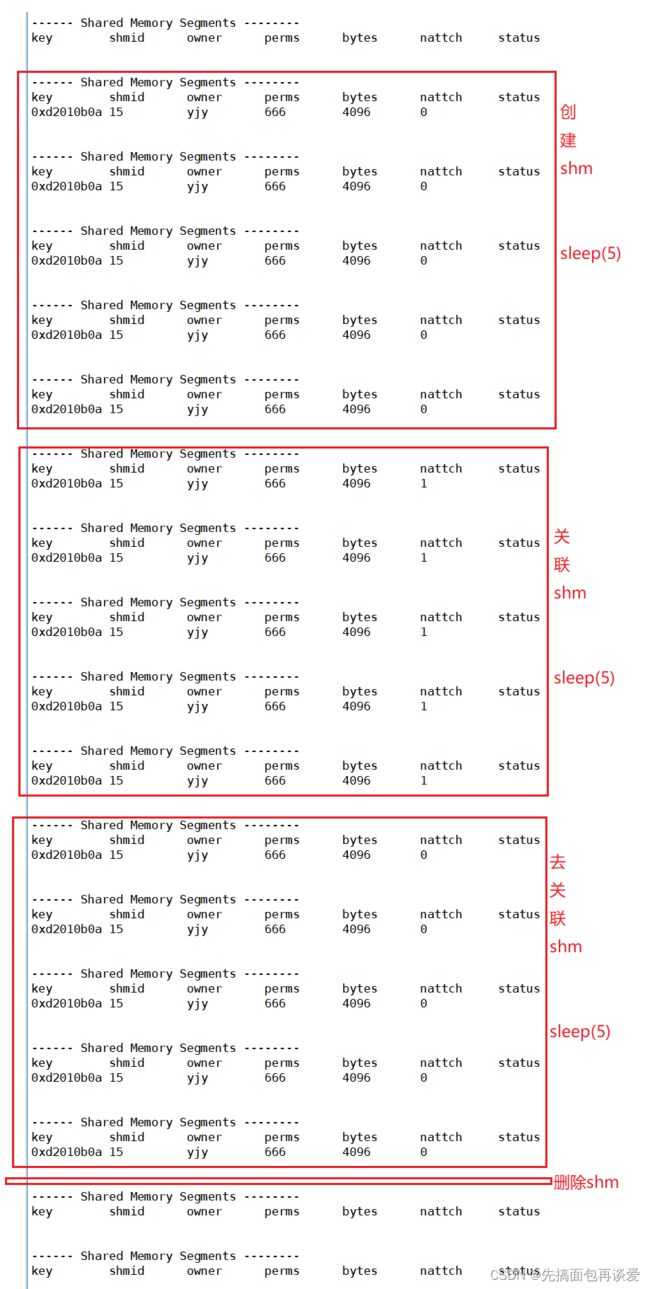
上面perms的权限就是0666,也就是创建shm的时候或上的数字。
然后这就是server端通信的大概逻辑,中间还没写通信内容,那么client端也大差不差,有两个地方需要改一下,一个就是client端不需要再创建shm了,直接获取shm即可,另一个就是client端不能删除shm,因为client端只负责用shm,没有删除shm的权利,删除shm的权利在server端,就像链表的迭代器一样。
完整流程演示
代码:
client代码
#include"comm.hpp"
int main()
{
// 获取key值
key_t key = ftok(PATH, PROJ_ID);
Log("client create key success", Debug);
cout << "client key ::" << deToHex(key) << endl;
// client无需再创建shm,直接获取shmid即可
int shmid = shmget(key, SIZE, IPC_CREAT | 0666);
if(shmid == -1)
{
Log("client get key fail", Error);
exit(1);
}
Log("client get key success", Debug);
cout << "client shmid::" << shmid << endl;
sleep(5);
// client端与创建出的shm建立映射
char* shmaddr = (char*)shmat(shmid, nullptr, 0);
if(shmaddr == (char*)-1)
{
Log("client attach fail", Error);
exit(2);
}
Log("client attach success", Debug);
sleep(5);
// client端与shm去掉映射,不必删除映射
if(shmdt(shmaddr) == -1)
{
Log("client detach fail", Error);
exit(3);
}
sleep(5);
Log("client detach success", Debug);
Log("client quit", Debug);
return 0;
}
server代码
#include"comm.hpp"
int main()
{
// 获取key值
key_t key = ftok(PATH, PROJ_ID);
Log("server create key success", Debug);
cout << "key ::" << deToHex(key) << endl;
// server端创建出新的shm
int shmid = shmget(key, SIZE, IPC_CREAT | IPC_EXCL | 0666);// 这里要给创建出来的shm权限,不然映射的时候会出问题
if(shmid == -1)
{
Log("server shmget fail", Error);
exit(1);
}
Log("server shmget sucess", Debug);
cout << "shmid ::" << shmid << endl;
sleep(5);
// server端与创建出的shm建立映射
char* shmaddr = (char*)shmat(shmid, nullptr, 0);
if(shmaddr == (char*)-1)
{
Log("server attach fail", Error);
exit(3);
}
Log("server attach success", Debug);
sleep(5);
// ipc
//server端与shm去掉映射
if(shmdt(shmaddr) == -1)
{
Log("server detach fail", Error);
exit(4);
}
Log("server detach success", Debug);
sleep(5);
// server删除shm
if(shmctl(shmid, IPC_RMID, nullptr) == -1)
{
Log("server del shm fail", Error);
exit(2);
}
Log("server del shm success", Debug);
// 进程退出
Log("server quit", Debug);
return 0;
}
server和client一块运行:

正确的。
开始通信
上面的代码就是完整的一套shm的流程,我故意把中间通信的过程留下来了,就是为了在这里讲。
首先,shm和匿名管道一样,也是纯内存级别的,但是二者有一点不一样的地方,匿名管道是在内核空间中的,对应虚拟地址空间的3~4G;shm是在用户空间中的,对应虚拟地址空间的0~3G,更准确的来说是在堆和栈中间的共享区,所以这个位置的数据我们普通用户是可以直接访问的。就像malloc一样,申请的空间在堆上,我们可以用指针来访问堆上的数据,malloc返回的是void*类型的,但是一般我们都要强转成我们想要的类型,而上面共享内存代码示例中的shmget就和malloc很像,shmget返回的也是void*类型的,我们也可以像指针那样直接访问shm中的数据。
故共享区中的共享内存,双方进程如果想要通信,直接进行内存级的读和写即可。
我前面讲的pipe、fifo都要通过read,write这样的系统调用接口来进行通信,因为双方进程的通信是通过文件来进行的,而文件在内核空间中是有特定的数据结构的,这些结构就由操作系统来亲自维护,也就是说这些数据是在3~4G这个范围之内的,所以用户无权直接进行访问,必须通过系统调用接口。
前面shm流程中,获取key值、创建共享内存、挂接、去关联、删除共享内存都属于让不同的进程看到同一份资源。当我们挂接成功后,就能获得到shm在共享区中的起始地址,而且shm的大小已经确定为SIZE,所以只需要在这个范围之内进行操作即可,就类似与我们malloc了一块地址并在这块地址中进行操作,因为我上面的代码中将shmget的返回值控制为了char*,我就将这块空间当做字符串来用了,当然你也可以按照其他类型来看,比如返回值强转为int*返回的指针解引用一次就能访问4个字节。。。
那么现在就来写代码,直接像指针那样访问就行了,先来说Server端:

就是ipc这里,shmaddr就是shm的地址,还要说一点,共享内存被创建之后会默认将空间中的内容全部置为0。
把所有的sleep去掉,加上这个:

光运行server端:
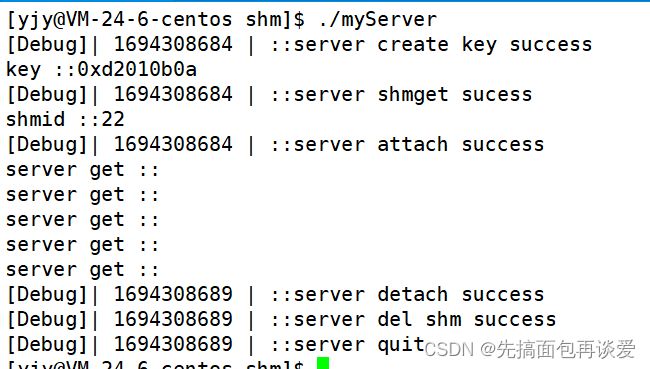
可以看到就算没有另一个进程向shm中写入数据,Server端也会直接读取信息,就是因为这里是用户空间中的,普通用户可以直接访问,而且默认初始化的是’\0’,所以就直接打印了空字符串。
然后再来说client,也是把sleep都关掉,建立映射之后再进行通信,先来个简单的代码:
client端:
// ipc
for(char c = 'a'; c < 'f'; ++c)
{
snprintf(shmaddr, SIZE, "hello server, I'm client, my pid::%d, send char::%c", getpid(), c);
sleep(1);
}
// 写入完毕,输入quit让server端结束读取
strcpy(shmaddr, "quit");
server端:
// ipc
while(true)
{
// 接收到 quit 就退出
if(strcmp(shmaddr, "quit") == 0) break;
printf("server get ::%s\n", shmaddr);
sleep(1);
}
运行起来就是:
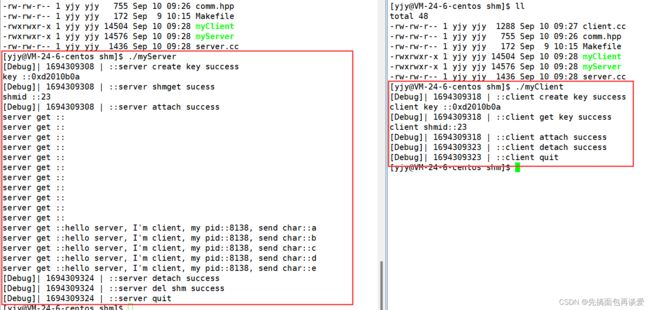
可以看到,就算前面client端还没有进行写入,server端就已经开始读取了,打印的都是空字符串,而后面client端开始写入了,server端依旧正常读取。
再改一下client:
// ipc
for(char c = 'a'; c < 'f'; ++c)
{
shmaddr[c - 'a'] = c;
sleep(1);
}
// 写入完毕,输入quit让server端结束读取
strcpy(shmaddr, "quit");

同样的,server端一直在读,不管client写不写。因为用户空间可以随便访问。
来点结论:
结论一:
只要通信双方使用shm,一方直接向共享内存中写入数据,另一方就可以立马看到对方写入的数据,所以共享内存是所有进程间通信的方式中速度最快的,不需要过多的拷贝,因为不需要讲数据交给操作系统。
来画个图看看:
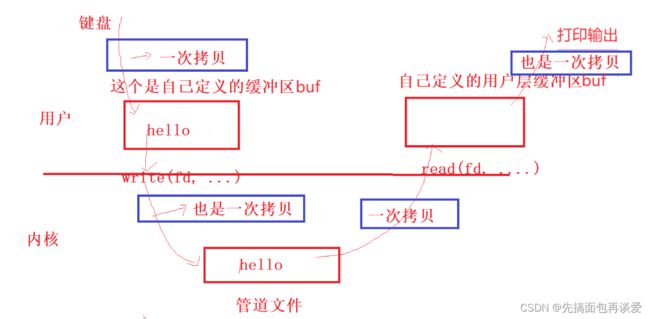
上面至少4次拷贝,说至少是因为如果光是系统级接口的话,最少要经过系统级别的缓冲区的,如果用到语言了,还要经过语言级别的缓冲区,那就拷贝的更多了。
但如果用shm的话:
最多经过两次拷贝就行了,一次是从输入缓冲区中写到shm中,一次是从shm搞到输出缓冲区中。
比如说我们可以这样:
client代码:
// ipc
while(true)
{
write(1, "client #", 8);
ssize_t ret = read(0, shmaddr, SIZE - 1);
if(ret > 0)
{
// 这里n-1是为了去掉键盘输入的\n
shmaddr[ret - 1] = 0;
if(strcmp(shmaddr, "quit") == 0) break;
}
}
然后把server端的printf改为write就好。

结论二:
共享内存缺乏访问控制,管道是满了写端阻塞,空了读端阻塞,shm就是为了让我们能进行快速通信而设立的,所以未提供任何的控制策略,不管client端怎样,server端一直都在读,读取端并不会因为写入方是否写入而影响到本身的读取操作,甚至说读方和写方压根都不知道对方的存在。
.
但这样就会带来并发问题,比如说没写端消息还没写完读端就给读走了,那么读端读取到的信息就不全,也就是写端和读端的数据不一致,从而导致后续操作上的错误。
.
来个栗子,比如说你是一个男生,一个跟你不熟的女生给你发消息说“我们结婚吧”,但五秒钟后人家说“对不起,发错了”,此时若你只看到前面那句话后就扔掉手机,直接开车去买花亲手送到人家家门口,但是你路上没有看消息,都到跑到人家门口了然后人家说跟你根本就不熟,人家女生脸一红跑回到家中直接打开小红书就开始家人们谁懂啊,此时对方可是版本t0级的英雄,请问面对这种情况你又该如何应对?
.所以说,两个进程的访问控制还是很有必要的,消息不全会导致后续操作上的问题,那么如果我们想进行访问控制呢?
.
可以通过管道来实现。
讲一下思路,有一点智能指针的思想。
用一个全局的类对象来实现,这个类构造函数中创建一个命名管道,析构函数中删除命名管道。在程序加载的时候会自动构建全局的变量,那么这个全局的对象也就会创建出来,此时就会调用该类的构造函数,对应的就会创建出管道文件,程序退出的时候,全局变量会被释放,自动调用析构函数,也就自动删除掉管道文件了。
再提供四个结构,对应文件的操作,分别是打开文件、关闭文件、发送读取信号、接收读取信号。
然后在通信的过程中,先让server端创建文件,然后server端和client端都打开文件,通信结束后都关闭文件。
server端通信的时候先等待client端发送信号,server端接收到信号后再进行读取。
client端通信时先从键盘中读取,然后再发送信号,当接收到quit时就关闭fd,此时对应的server端为读端,就会自动退出。
代码如下:
comm.hpp
#pragma once
#includeclient.cpp
#include"comm.hpp"
int main()
{
// 获取key值
key_t key = ftok(PATH, PROJ_ID);
Log("client create key success", Debug);
cout << "client key ::" << deToHex(key) << endl;
// client无需再创建shm,直接获取shmid即可
int shmid = shmget(key, SIZE, IPC_CREAT | 0666);
if(shmid == -1)
{
Log("client get key fail", Error);
exit(1);
}
Log("client get key success", Debug);
cout << "client shmid::" << shmid << endl;
//sleep(5);
// client端与创建出的shm建立映射
char* shmaddr = (char*)shmat(shmid, nullptr, 0);
if(shmaddr == (char*)-1)
{
Log("client attach fail", Error);
exit(2);
}
Log("client attach success", Debug);
// client 通信前写打开文件
int fd = OpenFifo(FIFO_PATH, WRITE);
// ipc
while(true)
{
// 先进行写入
write(1, "client #> ", 10);
int ret = read(0, shmaddr, SIZE - 1);
if(ret > 0)
{
shmaddr[ret - 1] = 0;
}
// 写入完毕再让server端读取,发送信号
SendSignal(fd);
// 接收到quit时就退出
if(strcmp(shmaddr, "quit") == 0)
{
Log("client quit", Debug);
break;
}
}
// 退出后关闭文件
CloseFifo(fd);
// client端与shm去掉映射,不必删除映射
if(shmdt(shmaddr) == -1)
{
Log("client detach fail", Error);
exit(3);
}
//sleep(5);
Log("client detach success", Debug);
Log("client quit", Debug);
return 0;
}
server.cpp
#include"comm.hpp"
// 直接创建全局对象,生成管道文件
fifoCD fifo;
int main()
{
// 获取key值
key_t key = ftok(PATH, PROJ_ID);
Log("server create key success", Debug);
cout << "key ::" << deToHex(key) << endl;
// server端创建出新的shm
int shmid = shmget(key, SIZE, IPC_CREAT | IPC_EXCL | 0666);// 这里要给创建出来的shm权限,不然映射的时候会出问题
if(shmid == -1)
{
Log("server shmget fail", Error);
exit(1);
}
Log("server shmget sucess", Debug);
cout << "shmid ::" << shmid << endl;
// sleep(5);
// server端与创建出的shm建立映射
char* shmaddr = (char*)shmat(shmid, nullptr, 0);
if(shmaddr == (char*)-1)
{
Log("server attach fail", Error);
exit(3);
}
Log("server attach success", Debug);
// sleep(5);
// 通信前打开管道文件
int fd = OpenFifo(FIFO_PATH, READ);// server读
// ipc
while(true)
{
// 读信息前先等待client发信号
getSignal(fd);
// 接收到信号才能读
printf("client read:: %s\n", shmaddr);
if(strcmp(shmaddr, "quit") == 0)
{
Log("server quit", Debug);
break; // 接收到quit就退出
}
}
// 退出后关闭文件
CloseFifo(fd);
//server端与shm去掉映射
if(shmdt(shmaddr) == -1)
{
Log("server detach fail", Error);
exit(4);
}
Log("server detach success", Debug);
//sleep(5);
// server删除shm
if(shmctl(shmid, IPC_RMID, nullptr) == -1)
{
Log("server del shm fail", Error);
exit(2);
}
Log("server del shm success", Debug);
// 进程退出
Log("server quit", Debug);
return 0;
}
演示一下:
共享内存就讲到这里,下面说说消息队列。
systemV 消息队列
一样的原理,消息队列就是在内存中搞一个先进先出的队列来让两个进程进行通信,但是是一个早已过时的计数,这里就不再多讲了。说几个接口就行。
上面的shm其实也是比较不推荐的通信方式了,因为systemV这套IPC机制与现在的主流的高性能服务器之间的兼容性并不好,所以systemV IPC已经很少被使用了。
就说几个接口:msgget、msgctl、msgsnd、msgrcv。
看着是不是很眼熟。其实就和shm中的接口用法差不多的。
msgget
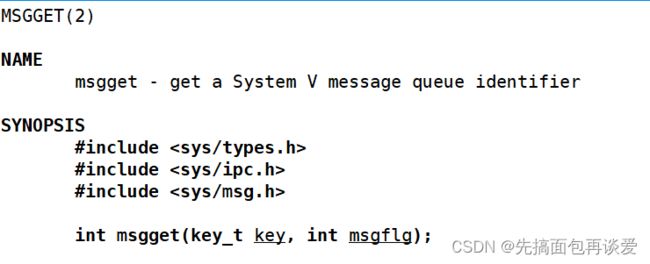
也是返回一个标识符,不过是消息队列的标识符。其实这些都是和文件描述符一样的功能,但是和文件中的操作完全是两套接口,不能很好的兼容后续网络服务,所以就很少用。
key值也是那个key值。
msgflg也是IPC_CREATE和IPC_EXCL。
就不演示了。
消息队列也是内存 + 内核数据结构。
msgctl
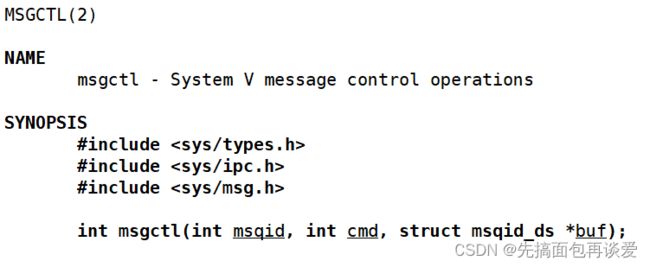
也是和shmctl一样。不懂得就回头重新看一下shmctl吧。
msgsnd
msgsnd是用来发送数据的,也就是写入方。
细节就不讲了。
msgrcv

msgrcv是用来接收数据的,也就是读取方。
可以看到这里消息队列的接口和文件的那套接口不兼容,但是linux下一切皆文件,我们更期望所有的操作都能通过文件来进行。这也是systemV用的较少的原因。
上面共享内存中用ipcs -m来查看共享内存的信息,ipcrm -m来删除某个共享内存。
消息队列中是用ipcs -q来查看消息队列的信息,ipcrm -q来删除某个消息队列。
还有一个是systemV信号量,用ipcs -s查看,用ipcrm -s来删除。
关于信号量的部分这里不讲,后面多线程的博客中我再来详谈。
但是还要讲一点概念性的知识的。
基于对共享内存的理解
下面是一些纯理论的知识,各位同学耐住性子看看。
为了让进程间通信,首先要让两个不同的进程看到同一份资源,因为进程具有独立性,看不到同一份资源,不同进程间的数据就无法交互,之前讲的所有的通信方式,匿名管道、命名管道、共享内存和没有讲的消息队列,本质上都是优先解决一个问题,即让不同的进程看到同一份资源。
匿名管道通过派生子进程来实现;命名管道通过相同路径的文件来实现;共享内存、消息队列、信号量通过key值来实现。
但是让不同的进程看到同一份资源也带来个一些时序问题。
两个进程在调度的时候是由操作系统随机去调度的,OS在调度的时候可能一些进程正在写,写了一半另一个进程就来读了,比如说共享内存,没有加任何访问控制的时候,两个进程对于shm可以随便访问,client端刚写一部分server端就读走了,此时就容易出现数据不一致的问题。
管道感觉不到这个问题是因为管道底层自动帮我们做了同步和互斥处理,但是shm没有。关于同步和互斥等会再说。
几个概念
一:
我们把多个线程(执行流)看到的公共资源叫做临界资源。
比如上面的 匿名管道、命名管道、共享内存、消息队列等,就都可以叫做临界资源。
二:
把自己进程中访问临街资源的代码叫做临界区。
看图:
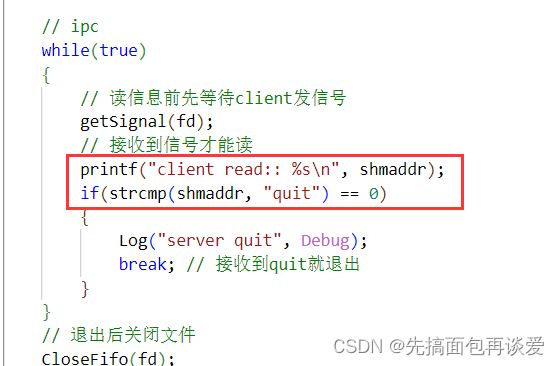
这是server端的代码,其中我用红色框起来的两行代码中,都访问到了shmaddr,也就是共享内存的地址,也就是都访问到了临界资源,而这两行代码就叫做临界区。
访问到临界资源的代码就叫做临界区。
多个执行流互相运行的时候互相干扰,主要是我们不加保护的访问了同样的资源(临界资源),在非临界区多个执行流是互不影响的。
三:
为了更好的进行临界区的保护,可以让多执行流在任何时刻都只能有一个进程进入临界区,此即互斥。就是必须让一个执行流访问玩资源了才能让另一个执行流继续访问此资源。
这个概念等多线程了会再详谈,此处就讲一下概念即可。
互斥,举一个我们生活中的例子。
假如说有一个VIP放映厅,这个放映厅中只有一个座位,每场电影只能由一个人来观看,当有多个人都想看同一场电影的时候就会出现一个人看,剩余人等的情况,那个人看完后才能让下一个人来看。显而易见,这样的效率是比较低的。当然我们现实生活中也不会这样做。
上面是多个执行流互斥。
那么能不能同一时刻让多个执行流进入同一个临界区呢?
可以的。但是先讲例子。
还是电影院,正常生活中,一个放映厅中是不太可能只有一个座位的,这样老板不得亏死。一个放映厅一般都是一二百个位置。我们看电影前要先买票,票上的位置就决定了我们坐的位置,只要买了票就一定是有你的座位的。当然,买票的本质就是对座位的预定机制。
再来说回执行流,当多个执行流访问同一块临界资源时,可将临界资源进行拆分,不同的执行流访问临界资源的不同位置,这样就能让多个执行流同步的访问到临界资源,这里拆分的临界资源就相当于是座位,来提供给不同的执行流来坐。看图:

每一个执行流想要进入临界资源,访问临界资源中的一部分,不能让进程直接去使用临界资源(不能让用户直接去电影院中占座位),你得先申请信号量(得先买票)。
信号量本质是一个类似于计数器的东西。
申请信号量有两层含义
- 申请信号量首先是让信号量计数器- -,也就是买一张票少一张票。
- 只要申请信号量成功,临界资源内部一定会给你预留了想要的资源中的一种,此即预定机制。
所以多执行流访问临界资源的时候就是先生请信号量,让信号量--,资源减少,申请好后执行流去执行自己的临界区的代码来访问临界资源,最后释放信号量,信号量计数器就++。
信号量本质上是一个计数器,那么是否能用一个整数来表示信号量呢?比如说int n = 10。
不能,因为父子进程用一个全局变量,写时拷贝,二者的n就不再是一个n了。
那么假如让多个进程看到同一个全局变量呢?也就是把n放在共享内存里,大家都申请信号量让n--。
也是不可以的。比如说client端和server端两者申请信号量,二者都要n--,c和s是两个进程,进程在运行的时候要经过CPU来调度,而CPU执行n--要分为三步:
- 将内存中的数据家遭到CPU内的寄存器中(读指令)
- n--(分析&&执行指令)
- 将CPU修改完毕的n写回内存(写回结果)
而CPU的寄存器只有一套,被所有的执行流共享,但寄存器里的数据是属于每一个执行流的,属于该执行流的上下文数据。进程在CPU上跑要进行上下文保护和上下文回复,但是进程在CPU上什么时候跑结束是不能确定的,也就是说执行流在执行的时候任何时刻都可能被切换。比如说n等于5时,由于server端执行的时间比较长正好在CPU上跑到第二步结束,但是此时时间片结束了,n变成了4,变成上下文数据保存到了server端的上下文数据中还未写回到内存中;client端,第一次读取到的还是内存中的5,但是执行的时间比较短,在一个时间片中完美执行了一次,那么n就--了一次,而且也写回到了内存中,那么此时内存中n就为4,后面又来了两执行流让n减了两次,那么此时n在内存中就减成了2。然后换到server端执行的时候是按照其上下文数据来继续执行的,也就是n为4又回来了,进行第三步,把4直接覆盖到了2上面,此时内存中的n就由2变成了4,这样就出问题了。n本来只能减两次,现在能减4次了。也就是说还能申请4次信号量,但显然这样是不对的。
如果n--能改为只有一步操作的话就不会出现这样的问题,一步指只有一行汇编代码,但实际上并不是,只有一行汇编的操作,具有原子性。
四:
原子性是指要么不做,要么做完,没有中间态。
这里n--,client端有中间状态4,故n--就没有原子性。
讲了这么多理论的知识,只需要先简单记住:
信号量是一个计数器,其原理上是对临界资源的预定机制。
申请信号量就是要让计数器--,对应的即信号量的P操作,这个操作必须是原子的。
释放信号量就是要让计数器++,对应的即信号量的V操作,这个操作必须是原子的。
信号量是操作系统设计的,其本身就是原子的,所以不必担心。
到此结束。。。