【操作系统笔记十一】进程间通信
Linux文件系统

inode 节点 (index node):给每个文件赋予一个称为 i 节点的数据结构。
inode 一开始是存储在硬盘中的,只有当文件被打开的时候,其对应的 i 节点才加载到内存中。

总结:
-
Linux 中,用户态通过读写文件的 Api 进行系统调用,在内核态中,上层是虚拟文件操作系统 VFS,它为用户态提供统一接口,屏蔽底层实现细节,VFS 层定义了底层具体的文件系统需要实现的接口,VFS 层往下对接不同的具体的文件系统如 ext4,具体的文件系统再去操作磁盘的文件块信息
-
Linux 中每个文件对应一个称为
iNode的数据结构,inode中包含了文件的元数据以及若干的块地址信息,inode一开始存储在磁盘中,当文件被打开时,inode节点会被加载到内存当中 -
每个进程的
task_struct中包含files_struct结构体,files_struct中又包含一个fd数组fd_array,fd_array中则包含对应文件的文件操作符file,file文件操作符是通过inode去读写文件的,inode中定义了inode_options,而具体的底层文件系统则实现了inode_options中定义的对应读写接口的具体方法
管道

Linux 进程间通信方式:管道、共享内存、信号量、消息队列
① 匿名管道

② 命名管道

管道的实现
一个文件可以同时被多个进程访问
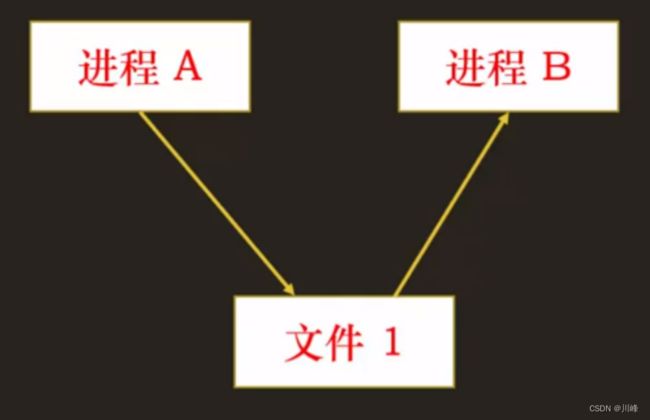
所以,我们可以使用文件来实现进程间的通信,管道就是基于文件系统来实现的。
实现进程和其子进程之间的管道通信

父进程在复制子进程时,会把父进程的相关信息全部拷贝过来,其中就包括file_struct结构体,而这个结构体中就包含了文件读写inode的两个文件描述符,一个 file_0 只读, 一个 file_1 只写,由于是复制的,所以父子进程的这俩文件描述符是指向的同一个文件的inode。
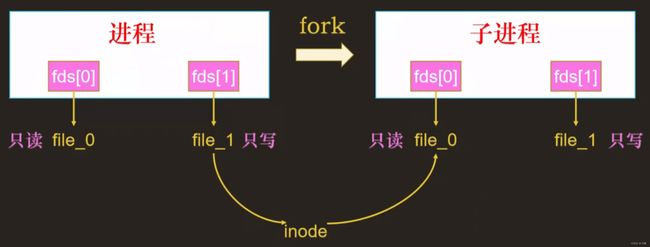
此时把父进程的 file_0 只读文件描述符 close 掉,把子进程的 file_1 只写文件描述符 close 掉,父进程只保留只写文件描述符,子进程只保留只读文件描述符,这样父进程就可以和子进程通信了(父进程只写,子进程只读,半双工)。
匿名管道的实现


匿名管道底层实现:
匿名管道通过虚拟文件系统 VFS 调用底层的 pipefs 内存文件系统,也就是说底层实现是基于 pipefs 文件系统的。
pipefs 文件系统的数据结构:https://www.processon.com/view/link/62822757e401fd36f6bcc5dd
管道在内存中的实现本质就是一段内核 buffer 内存,不同的文件操作符(一个读一个写)对这段 buffer 进行读写操作。
关于 ps -ef | grep systemd 命令背后的匿名管道的底层实现数据结构:

命名管道底层实现流程图:

总结
-
管道是基于文件系统来实现的,也就是多个进程对同一个文件进行读写来实现进程间通信
-
进程和子进程之间的管道通信:父进程在
fork子进程时,会把父进程相关信息全部拷贝过来,其中包括file_struct结构体,file_struct中包含了文件读写inode的两个文件描述符,一个file_0只读,一个file_1只写,由于是复制的,所以父子文件的这俩文件描述符是指向同一个文件的inode, 此时把父进程的file_0只读 fd 关闭掉,然后再把子进程的file_1只写 fd 关闭掉,父进程只保留只写 fd ,子进程只保留只读 fd ,这样父进程就可以和子进程进行通信了(父进程写,子进程读)。 -
匿名管道的虚拟文件系统 VFS 对应的底层文件系统实现是基于
pipefs内存文件系统 -
管道在内存中的实现本质就是一段内核 buffer 内存,不同的文件操作符(一个读一个写)对这段 buffer 进行读写操作。
-
用户态:
read/write→ 内核态 VFS:task_struct→files_struct→fd_array→fds[0]fds[1]→file0file1→file_opts→inode→pipe_inode_info→pipe_bufs
共享内存 (shared memory)
创建共享内存
shmget - allocates a System V shared memory segment
#include 参数含义:
-
key:唯一标识新创建的共享内存 -
size:共享内存的大小,向上取整成PAGE_SIZE的倍数 -
shmflg:一些标志信息IPC_CREAT:根据key判断对应的共享内存段是否存在,如果不存在,则创建;如果存在,则返回已经存在的共享内存段IPC_EXCL: 和IPC_CREAT一起用,如果已经存在key对应的共享内存 则失败读写权限信息
映射共享内存
shmat— 映射共享内存到进程的虚拟地址空间,返回映射的虚拟内存段的起始地址shmdt— 解除映射,如果成功返回 0,否则返回 -1
#include 参数含义:
shmid:共享内存的唯一标识id,即填入由shmget函数返回的值shaddr: 内存映射起始地址,如果是NULL的话,内核会分配shaflg:是一组标志位,通常为0。
注意:创建和映射共享内存操作只是在内核中维护一些数据结构,并没有真的分配物理内存。真正分配物理内存是在访问这块虚拟内存地址中的数据发生缺页异常时,由缺页异常处理程序维护进程页表中的虚拟页号和物理页号的映射关系的。
这里进程 A 和进程 B 访问的是同一块物理内存上的相同的物理页。
参考代码:
共享内存的底层原理是基于 tmpfs 文件系统:https://www.processon.com/view/link/6277c3921e085327716f5971
总结
-
共享内存的原理:不同进程的虚拟内存地址会映射到相同的物理内存上,这样两个进程通过访问同一块物理内存,达到通信的目的。(一般情况下,不同进程的虚拟地址是映射到不同物理地址的)
-
在创建共享内存时并没有真的分配物理内存,真的分配是进程在读、写数据的时候,发生缺页异常,由缺页异常处理程序分配共享内存(物理内存)的页号到进程的虚拟页表中
-
共享内存的底层原理是基于
tmpfs文件系统, Linux中一切皆文件
问题:mmap 内存映射和 shm 共享内存有什么区别?
- Linux 中的内存映射是指将一块虚拟地址内存空间和一个文件对象关联起来,以初始化这块虚拟内存的内容,文件对象可以是一个普通磁盘文件,也可以是一个匿名文件(一块只包含二进制零的物理内存)
- mmap 内存映射时,被映射的对象可以是一个磁盘文件,也可以是一个请求二进制零的匿名对象。如果是前者,在发生缺页异常时,缺页异常处理程序除了需要维护页表外,还需要将磁盘文件内容加载到物理内存中;如果是后者,则就相当于将一块物理内存和虚拟内存进行映射。
- shm 共享内存映射是直接每个进程将虚拟内存映射到同一块物理内存,不涉及到磁盘文件。shm 保存在物理内存,这样读写的速度要比磁盘要快,但是存储量不是特别大。
- 所以可以简单的认为 mmap 主要是用于映射磁盘文件的,而 shm 是直接用于映射物理内存的
- mmap 有一个好处是,把文件保存在磁盘上,当设备机器重启时,这个文件还保存了操作系统同步的映像,所以 mmap 不会丢失,但是 shm 就会丢失。
信号量
在一个进程内,多个线程同时更新共享资源,有数据并发安全问题,解决方案有:
- ① 原子操作
- ② 锁机制 - 管程
- ③ 信号量
多个进程同时更新共享内存(共享资源),也有数据安全问题,解决方案:信号量
IPC 的信号量 (semaphore)
原理思想和并发编程中的信号量是一样的,但是两者的实现完全不同:
-
IPC 的信号量实现很复杂,是在内核态中实现的,而并发编程中的信号量是在用户态实现,基于原子操作实现
-
IPC 的信号量是操作系统层面用于解决多个进程之间的共享内存并发读写问题,并发编程中的信号量用于解决同一个进程的多个线程之间的共享资源读写问题
一个是在内核态实现的,一个是应用程序代码中实现的。
参考代码:
消息队列
创建消息队列:msgget - get a System V message queue identifier
#include 参数含义:
-
key:唯一标识新创建的消息队列 -
msgflg:一些标志信息IPC_CREAT:根据key判断对应的共享内存段是否存在,如果不存在,则创建;如果存在,则返回已经存在的共享内存段IPC_EXCL:和IPC_CREAT一起用,如果已经存在key对应的共享内存,则失败读写权限信息
发送和接收消息:msgsnd, msgrcv - System V message queue operations
#include msqid: 由msgget函数返回的消息队列的标识符msgp: 消息缓冲区指针,指针指向准备发送/接收的消息msgflg: 为0表示阻塞方式,设置IPC_NOWAIT表示非阻塞方式异步接发消息msgsz: 是msgp指向的消息长度,这个长度不含保存消息类型的那个long int长整型msgtype:
等于0,那么读取消息队列中的第一条消息
大于0,那么读取消息队列中的第msgtype条消息(这里是读取类型等于msgtype的第一条消)
小于0,那么读取小于等于msgtype绝对值最小的msgtype的消息
参考代码:
int main() {
int mq_id = get_mq_id();
struct msg_buffer buffer;
printf("enter message type: ");
scanf("%d", &buffer.mtype);
printf("enter message contenit:");
scanf("%s", &buffer.mtext);
int len = strlen(buffer.mtext) + 1;
if (msgsnd(mq_id, &buffer, len, IPC_NOWAIT) == -1) {
perror("fail to send message.");
exit(1);
}
return 0;
}
#include