算法与数据结构
b站大学白嫖来的左神数据结构课
左神用的Java授课,理解算法就行,我用Python刷题

1. 认识复杂度和简单排序算法
1.1. 时间复杂度——大O表示法:
- 常数时间的操作:如果一个操作和数据样本量无关,就叫做常数操作。
- 对一个算法时间复杂度常用大O表示法来衡量,如果一个算法进行常数操作的次数为
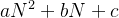 ,则该算法时间复杂度为
,则该算法时间复杂度为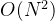 ,O表示的是上限,因此选择最高次项作为依据。
,O表示的是上限,因此选择最高次项作为依据。 - 评价两个算法的时间复杂度高低,先比较大O,相同时再看实际运行时间。
- 考虑到有一些算法的时间复杂度会根据数据场景变化,因此大O表示算法最差情况下的时间复杂度。
1.2. 选择排序:
- 将一组数据进行逐个比对,找到最小的数与第一个数交换位置,再从该组数据的第2~N个数开始反复进行,直至整组数据都为有序。
- 算法时间复杂度为
1.3. 冒泡排序:
- 将一组数据每相邻的两个数比较大小,每次将大的数放在右边,从最左边两个数开始操作直至最右边两个数,此时最右边的数为全数据中最大的数,接下来将处理后数据的第1~N-1个数反复进行,直至整组数据都为有序。
-
算法时间复杂度为
1.4. 插入排序:
- 从索引为0的数开始,对于每个数
 都去和其左边的数
都去和其左边的数  对比大小,如果小于左边的数则交换顺序,并继续和现在左边的数
对比大小,如果小于左边的数则交换顺序,并继续和现在左边的数  对比,反之停止,直至
对比,反之停止,直至  。
。 - 有点像打扑克理牌。
-
算法时间复杂度为
,但受数据状况的影响,例如数据如果原本就有序,则算法时间复杂度为
1.5. 异或运算:
- 判断两个数是否相异,异则为1,同则为0,符号为
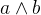 ,而0与任何数都为相异。
,而0与任何数都为相异。 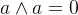 ,
, 。
。 可以提取出a的二进制最右侧第一个1.
可以提取出a的二进制最右侧第一个1.- 异或运算满足交换律和结合律。
- 异或运算等价于二进制无进位相加。
- 例题1:一个整数数组,有一个数出现了奇数次,其他数都为偶数次,请找到那个数,,要求时间复杂度,空间复杂度
 。解答:将所有数进行异或运算,由于两个相同的数异或结果为0,因此其他数的异或结果都为0,直至剩下一个数与0异或后是这个数本身,即为答案。
。解答:将所有数进行异或运算,由于两个相同的数异或结果为0,因此其他数的异或结果都为0,直至剩下一个数与0异或后是这个数本身,即为答案。 - 例题2:一个整数数组,有两个不同的数出现了奇数次,其他数都为偶数次,请找到那两个数,,要求时间复杂度,空间复杂度。解答:将所有数进行异或运算,最终得到的结果是
 ,由于a和b是不同的数,那a和b的无进位相加中一定至少有一位是1,设这个第k位为1,再将所有数据分为第k位为1和第k位为0的两组数,两组分别使用例题1的解法即可。
,由于a和b是不同的数,那a和b的无进位相加中一定至少有一位是1,设这个第k位为1,再将所有数据分为第k位为1和第k位为0的两组数,两组分别使用例题1的解法即可。
1.6 二分法
- 有序数组查找位置
- 找大于等于一个数最左侧的位置,或小于等于一个数最右侧的位置。
- 局部最小值问题:为一个无序数组找到其某一个局部最小值,先找两端,第一个数小于第二个数,或第N个数小于第N-1个数,即为局部最小值,如果都不是,则局部最小值在中间;通过二分法找到中间数,如果中间数左右时单调递增则局部最小值在左半,在左半重复算法,如果中间数左右单调递减则局部最小值在右半,在右半重复算法,如果中间数是极大值则都可。
- 算法时间复杂度为

2. 认识 的排序
的排序
2.1 递归行为
-
master公式:
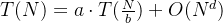 ——只能在等规模子问题的递归中计算时间复杂度,其中
——只能在等规模子问题的递归中计算时间复杂度,其中 是数据长度,也叫问题规模;
是数据长度,也叫问题规模; 是子问题规模(第一次调用自身时输入的数据长度,例如二分递归则第一次调用自身就是左半/右半的数据长度);
是子问题规模(第一次调用自身时输入的数据长度,例如二分递归则第一次调用自身就是左半/右半的数据长度); 是每个函数内调用自身的次数;
是每个函数内调用自身的次数;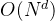 是除了调用自身以外的操作的时间复杂度。
是除了调用自身以外的操作的时间复杂度。 -
对于满足master公式的递归过程,可以用快速方法求得算法的时间复杂度:①若
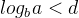 ,则算法时间复杂度为
,则算法时间复杂度为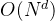 ;①若
;①若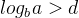 ,则算法时间复杂度为
,则算法时间复杂度为 ;①若
;①若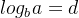 ,则算法时间复杂度为
,则算法时间复杂度为 ;
;
2.2 归并排序
- 当两个有序数组需要进行合并时,为两个数组分别设置一个指针,并创建一个空数组的独立空间,两个指针各自指向两个数组的元素a和b,当a小于b时,将a放入新数组,并将a指针右移,反之将b放入新数组,将b指针右移。
- 归并排序类似于递归行为,但是每次将左右两个子数组的归并结果返回,如此最小子数组天然有序,归并后的有序数组返回父函数再归并,循环往复直至归并原始数组的两半,原始数组排好序。
- 单个归并算法时间复杂度为,但因为开辟了新空间(外排序),空间复杂度为。
- 归并排序算法master公式为
 ,可以计算得其时间复杂度为
,可以计算得其时间复杂度为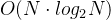 ,空间复杂度为
,空间复杂度为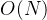 (每次递归的空间用完后可以释放)。
(每次递归的空间用完后可以释放)。 - 归并排序算法相较于上述算法的提升为:之前的算法都将一个数与其他无序的所有数比较(已经排好序的放在数组首或尾,无需比较),没有保留每次比较的信息,每次浪费了大量比较行为来找到一个数的顺序。而双指针归并方法的每一次比较都是有效的,都会为一个数找到有序的位置,因此时间复杂度得到了改进。
2.3 小和问题
- 题目:对于一个无序数组,每个数左边所有比他小的数的和为这个数的小和,求该数组的所有小和之和。例如数组[1, 3, 4, 2, 5],其小和分别为[[0], [1], [1+3], [1], [1+3+4+2]],最终结果为0+1+4+1+10=16
- 法一——两层遍历,第一层遍历每个数,第二层遍历这个数左边所有数,并判断是否小于该数,依次计算小和,算法复杂度为。
- 法二——归并排序顺便求小和:可以将问题逆向为每个数右边有多少个比他大的数,例如上述数组[1, 3, 4, 2, 5],其小和分别为[[0], [1], [1+3], [1], [1+3+4+2]],我们只需要找到比1大的数,有4个,也就是1这个数有4次参与别的数的小和,那就计1*4,如此反复可得该数组的小和之和为1*4+3*2+4*1+2*1=16,如何找到每个数右侧比他大的数的个数呢?根据上述归并排序方法,数组最终会被分为单个数并进行归并和返回,在此过程中可以记录每个右指针比左指针大的个数,一路归并到头即可得到每个数比其大的个数,如下图所示:
对于最下方的1和3,左指针在1,右指针在3,则比1大的数的个数+1,往回13和4,左指针在1时右指针在4,比1大的数+1,同时左指针移动到3,右指针在4,比3大的数+1,这样一路往上的过程中,每次比较都是有效的,并且可以准确得到每个数其右侧比他大的数的个数,并且实现了 的时间复杂度。但有注意点是,①当左右指针指的数相等时,一定要移动右指针,因为我们在为左指针的数寻找比他大的数的个数,如果此时移动左指针则会漏掉右指针右边数的信息。②归并往上的过程中需要排好序返回,因为我们需要找的是比左指针数a大的数的个数,如果数组有序,那当右指针移动到第一个大于a的数时,我们就可以停止遍历右数组,因为此时剩下的数肯定都比a大(因为有序),这样可以节省时间复杂度。
的时间复杂度。但有注意点是,①当左右指针指的数相等时,一定要移动右指针,因为我们在为左指针的数寻找比他大的数的个数,如果此时移动左指针则会漏掉右指针右边数的信息。②归并往上的过程中需要排好序返回,因为我们需要找的是比左指针数a大的数的个数,如果数组有序,那当右指针移动到第一个大于a的数时,我们就可以停止遍历右数组,因为此时剩下的数肯定都比a大(因为有序),这样可以节省时间复杂度。 - 还有另一个题目,求一个数组的所有逆序对(任选两个数为逆序,左边数大于右边数即为一个逆序对),可以用上面法二——归并排序方法,一样思路解决。
2.3 荷兰国旗问题(Partition方法)
- 题目:给定一个数组和一个数num,要求将数组中所有小于等于num的数都放在左边,所有大于num的数都放在右边,要求时间复杂度为,空间复杂度为。
- 解法:双指针遍历,指针1用于依次遍历所有元素,指针2从0开始,用于确保其左侧的数都是小于等于num的,具体操作步骤:指针1遍历整个数组,每次遍历到的元素若小于等于num,则该元素与指针2所在元素交换,同时指针2右移;若遍历到的元素大于num,则无需任何操作,继续往下遍历。该方法保证每次指针2的元素一定都会小于等于num再右移,可以实现一次遍历将数组中所有小于等于num的数都放在左边。
- 升级版题目:除了左右分开以外,如果数组中有等于num的数,需要放在中间。解法:三指针遍历,指针1遍历整个数组,指针2从0开始,用于确保其左侧的数都是小于num的,指针3从数组末尾开始,用于确保其右侧的数都是大于num的。
- 注意!:对升级版题目的解法,需要额外考虑的是:三指针遍历的方法对于指针3的处理应该是,当指针1遍历的数大于num时,交换指针1和指针3所在的数,指针3左移,但指针1不动,因为指针3换过来的数并不知道信息,应当对该数再判断一次,否则会有遗漏(例如换到指针1位置的数大于num,但此时若指针1右移则该数会被放在左边区域)。
2.4 快速排序
- 版本1:我们将前面荷兰国旗问题的双指针方法称为Partition方法,对于一个无序数组,将其最后一个数作为num,进行一次Partition操作,将数组划分为小于等于num和大于num两个部分,并将大于num区域的第一个数与最后的num交换位置,再将两个区域分别递归,直至递归的子数组长度只有1则结束。
- 版本2:和版本1不同的是,这里的Partition采用的是升级版荷兰国旗问题的Partition方法,采用三指针划分出小于num、等于num和大于num的三个区域,并分别在小于num和大于num两边进行递归。
- 前两个版本的快速排序时间复杂度为,因为快速排序最差的情况就是该数组天然有序,每次递归都会使二分失效,此时快速排序会降级为二重遍历。
- 版本3:每次不以最后一个数作为num,而是随机选择数组中的一个数,作为num并与最后一个数交换,进行上面的快速排序方法,这样避免了最差的情况——数组有序使二分失效,版本3的时间复杂度为。
3. 堆排序
3.1 完全二叉树
- 一个二叉树,从上到下、从左到右按顺序排列数字,不能跳过从上到下从左到右的顺序,则为完全二叉树。
- 对于一个完全二叉树,设每个节点的数字在原数组中索引为,则其左子节点在原数组中索引为
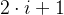 ,其右子节点在原数组中索引为
,其右子节点在原数组中索引为 ,完全二叉树的元素索引如图所示:
,完全二叉树的元素索引如图所示: 
-
堆是一种特殊的完全二叉树。
3.2 大根堆
- 对于一个完全二叉树,如果每个节点都是以它为根的子树中的最大值,或者说每个节点都比它的子孙节点大,则称为大根堆,又叫优先级队列结构,如下图所示:

- HeapInsert:对一个数组,可以构建大根堆,先按照完全二叉树的顺序将数组中元素依次加入树,在这个过程中,每次新加入的数如果大于其父节点,则与父节点交换位置(在数组中也交换),交换完后再与新的父节点对比直至小于等于当前父节点,当所有元素都加入树时,这个树称为一个大根堆。
- 当一个数组通过HeapInsert构建大根堆时,要找数组的最大值只需找根节点的数,如果要去除数组的最大值,并让剩下的元素保持大根堆结构,则可以将刚刚最后一个加入树的元素移动到根节点,并自上向下与其子节点的最大值比较,如果小于子节点最大值则与子节点交换位置,继续直至该节点移动到比其子节点都大的位置,整个树重新成为大根堆,这个过程称为Heapify。
- 同理如果构建大根堆后,如果有一个数发生了修改,则可以查看修改的新数比之前大还是小,如果大可以往上HeapInsert,如果小可以往下Heapify。
- 一个二叉树的节点数和高度之间是
 的关系,所以HeapInsert和Heapify的操作时间复杂度都是
的关系,所以HeapInsert和Heapify的操作时间复杂度都是 。
。 - 如果一次性用一整个数组构建大根堆,可以先随意将数组中元素排列为完全二叉树,再从倒数第二层的每个节点元素,对它进行Heapify,即将这个节点及下面的子树都调整为大根堆,再到上一层继续Heapify,直至根节点的Heapify完成,整个树都会成为大根堆,这个构建方式的时间复杂度为。
- 小跟堆同理,如果每个节点都是以它为根的子树中的最小值,称为小跟堆。
3.3 堆排序
- 对于一个无序数组排序问题,首先使用数值构建大根堆,此时根节点是全数组最大数,将其拿走放在数组最后的位置,并通过Heapify方法将剩下的数保持大根堆结构,用余下数组和余下大根堆重复操作,直至堆的节点数为0.
- 堆排序的时间复杂度为,额外空间复杂度。
- 扩展题目:已知一个几乎有序的数组(几乎有序指数组的每个元素距离其排好序的位置不超过k,这个k相对于数组长度N比较小),如何用合理的方法进行排序。解法:将数组前k+1个数构建小根堆,将小根堆的根放在数组的第一个位置并踢出小根堆,之后将数组第k+2个元素加入小根堆,将现在小根堆的根放在数组的第二个位置,反复进行直至小根堆为空,该方法时间复杂度为
 。
。
3.4 桶排序(不基于比较的排序)
- 计数排序:对于一个无序数组,如果存在一定的大小范围(例如数组代表员工年龄,则一般都在18~60范围内),则可以初始化一个全0向量,长度为(b-a),b和a分别代表数组元素大小的上、下限,遍历整个数组,每当遍历一个元素,则在向量中这个元素对应位置+1,最终将向量上的非0元素统计起来就好,该方法无需数组内元素的比较,时间复杂度为。
- 击数排序:对于一个数组,先看其最大数字的位数(100是三位数,12是两位数),并为其他小位数的数补0(例如最大是三位数100,则将两位数12补为012),再初始化10个桶代表0~9这10个数,依次遍历数组中所有元素并按照个位数放置入对应的桶,全部放入后再按照从0到9,先入先出的顺序把所有数拿出来重新排列为一个数组,再依次遍历数组按照十位数重复操作,再按照百位……直到最高位完成入桶出桶操作,数组便完成了排序。
- 击数排序相比于计数排序,无需数字要有明确范围,但是数组元素必须要有位数/进制概念。
- 击数排序也可以用二进制、三进制等处理数字,几个进制就要用几个桶,但是进制数较小则位数会增加。
- 改进版击数排序:对于一个无序数组,先用一个count向量统计其个位数出现的次数,此时count向量索引为 位置的数代表了数组中个位为 的数的个数,再从count第二个数开始依次累加上一个数,此时count向量索引为 位置的数代表了数组中个位小于等于 的数的个数,再初始化一个和原数组相同长度的help数组,从右往左遍历原数值,看其个位数在count对应的值,如果这个数个位为,而
![count[i]=j](http://img.e-com-net.com/image/info8/4c093df2bd274298896f8074de355e4d.png) ,则将这个数放在help数组的位置,同时令
,则将这个数放在help数组的位置,同时令![count[i]=j-1](http://img.e-com-net.com/image/info8/ec815eb2f4644c728ca27a15c29a4446.png) ,继续向左遍历,直至遍历结束,这个方法相当于击数排序的一次入桶出桶操作,再继续十位、百位等。
,继续向左遍历,直至遍历结束,这个方法相当于击数排序的一次入桶出桶操作,再继续十位、百位等。 
| 排序稳定性:对于一个无序数组,部分相等的数值在经历排序算法后,其相对次序是否可以保持不变,定义为算法稳定性。例如数组 [0, 1, 0] 经历排序后为 [0, 0, 1],其中第一个0和第二个0的相对位置在排序后依然保持不变,则称这个算法是稳定的。 在实际应用中排序算法的稳定性是很重要的,例如商品推荐排序,原本的商品是根据评分进行排序的,其价格是无序的,现在要对其价格进行排序,而且需要保证相同价格的商品内部依然是根据评分排序的,这样用户首先看到的便是物美价廉的商品,此时则需要用到稳定排序算法。 |
|
| 稳定的排序算法 | 冒泡排序、插入排序、归并排序(需要先拷贝左半才能满足稳定性,且小和问题的改进算法是不稳定的)、桶排序 |
| 不稳定的排序算法 | 选择排序、快速排序、堆排序 |
| 目前没有找到时间复杂度以下,同时又稳定的排序。 |
|
排序算法总结
| 时间复杂度 | 空间复杂度 | 稳定性 | |
| 选择排序 | |
|
× |
| 冒泡排序 | |
|
√ |
| 插入排序 | |
|
√ |
| 归并排序 | |
√ | |
| 快速排序 | × | ||
| 堆排序 | |
× | |
| 在多数排序任务中,对稳定性没有要求,空间复杂度要求不高时,优先使用快速排序,因为其时间代价在同大O复杂度算法中的实际测试结果是最好的。 | |||
| 对于空间复杂度要求较高的任务可以使用堆排序。 | |||
| 对于稳定性有要求的任务可以使用归并排序。 | |||
| 通常可以见到一些快速排序的改进算法,快速排序的每次递归会判断当前数组长度,长度较小时直接使用插入排序并返回,因为快速排序的常数代价较大,当数组长度很长时优势明显,但长度较短时插入排序这样常数代价很小的算法更有优势。 |
|||
坑:
- 归并算法的空间复杂度可以变为(内部缓存法),但是会丢失稳定性,还不如用堆排序。
- 所谓的“原地归并排序”并不靠谱,会使时间复杂度变为,还不如用冒泡排序。
- 快速排序可以做到稳定性,但是会使空间复杂度变为,还不如用归并排序。
- 有一道题目,把奇数放在数组左边,偶数放在数组右边,还要求原始的相对次序不变(稳定的快速排序),空间复杂度低于,碰到这个问题直接怼面试官。
4. 链表
4.1. 单链表荷兰国旗问题
- 题目:给定一个单链表和一个数num,要求将链表所有节点进行分组重排序,从左往右先是小于num的所有节点,后是等于num的所有节点,最后是大于num的所有节点。
- 法一:可以遍历整个链表,将其值取出来放进数组,再对数组进行Partition,最后把结果放回链表,该方法时间、空间复杂度均为。
- 法二:初始化六个变量,分别是SmallHead,SmallTail,EqualHead,EqualTail,BigHead,BigTail,用一个指针遍历链表。当遇到第一个值小于num的节点时,令SmallHead和SmallTail都等于该节点,而每遇到一个新的值小于num的节点,就令现在的SmallTail指向该节点,并更新为该节点。对等于num的节点和大于num的节点分别作相同的操作更新EqualHead,EqualTail和BigHead,BigTail,当遍历完链表时便得到了三个链表,将其首尾拼接即可。该方法时间复杂度为,而空间复杂度降低至。
4.2. 随机单链表克隆问题
- 题目:给定一个单链表,链表中节点除了有下一个节点的指向以外,还有一个随机指向,克隆该链表包括其所有指向关系。
- 法一:先遍历所有节点,为每个节点克隆一个相同值的新节点(不包含指向关系),同时用一个哈希表存储新-旧节点的对应关系(key是旧节点,value是新节点),再遍历一遍所有旧节点,将指向关系克隆到新节点(例如节点①->节点②,则遍历到节点①时可将其新节点①' 指向 Map(节点②)=新节点②' )。该方法时间、空间复杂度均为。
- 法二:法一中重要的一步是用哈希表来存储新旧节点的对应关系,带来了空间复杂度,可以用旧节点指向新节点的方法代替哈希表,降低空间复杂度,最后再分离出新链表。
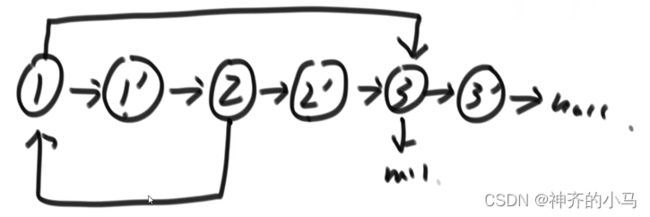
4.3. 两个单链表相交的一系列问题
- 题目1:判断一个单链表是否有环。解法1:遍历链表,同时用哈希表记录每次遍历到的节点,若出现重复则说明有环,且第一个重复的节点便是入环节点。解法2:快慢指针,快指针一次走2步,慢指针一次走1步,如果遍历完之前快慢指针相遇,则有环(有环是遍历不完的,因此一定会相遇),当相遇时将快指针重置到链表头并设定为慢指针,此时两个指针都一次走一步,下一次两个指针相遇时一定在入环节点(数学可证明,略),此方法可以替代哈希表,将空间复杂度降至。
- 题目2:给定一个两个有环或无环的单链表,判断它们是否有相交部分(共用节点),如果有则返回第一个相交节点。解法:先判断两个链表是否有环(参考题目1),①如果两个无环链表,直接判断两个链表末尾节点是否公用,是则相交,若相交则同时遍历两个链表,短链表从头遍历,长链表从长度差值位置开始遍历(例如两个链表一个100,一个80,则前者从20开始,后者从0开始遍历),即可找到第一个相交节点;②一个有环一个无环,则一定不相交;③两个有环链表,如果两个链表的入环节点相同,则在入环前就相交,此时可以用①的方法找到第一个相交节点,否则不相交或是入环后才相交,可以从链表1的入环节点往下遍历,如果在下一次回到原位之前可以遇到链表2的入环节点,则两链表相交,第一个相交节点既可以是链表1的入环节点,也可以是链表2的入环节点。
5. 二叉树
5.1. 二叉树的遍历
5.1.1. 递归遍历
- 编写一个函数,对二叉树的一个节点操作,并接着调用自身两次,分别传入该节点的左子节点和右子节点,当遍历到None时结束此条递归;
- 因为编写函数时可以修改顺序,例如先调用自身传入左子节点,再对自身节点进行操作,再调用自身传入右子节点,诸如此类修改会使递归遍历的顺序不同,根据这个顺序将递归遍历分为先序、中序和后序遍历;
- 先序:先操作自身,再左,最后右;中序:先左,再操作自身,最后右;后序:先左,再右,最后操作自身;
5.1.2. 非递归遍历
- 先序遍历:
- 首先创建一个空栈,将二叉树的根节点压入栈中;
- 开始循环,每次循环重复以下两个步骤:
- 将栈顶节点弹出,对其进行操作;
- 将该节点的右左子节点分别压入栈中(如果有)(注意一定要先右后左,这样根据栈后进先出特性,之后先弹出的就是左子节点);
- 如果某一刻栈为空则停止循环;
- 如果把压入栈的顺序改为先左后右,就变成了另一种先序(头右左);
- 后序遍历:
- 如果按照头右左的方法遍历,同时再初始化一个收集栈,每次将弹出的栈放入收集栈,遍历过程不对收集栈做弹出操作,当遍历结束以后再依次全部弹出和操作,就变成了后序(左右头);
- 中序遍历:
- 一开始把树的所有左边界压入栈(从根节点压入,然后其左节点,然后左节点的左节点,直至None);
- 开始循环,每次循环重复以下步骤:
- 弹出栈顶节点并操作,同时将该节点的右子节点压入栈(如果有),且如果右子节点不是叶而是另一棵子树,则同第一步将其左边界依次压入栈再进行后续循环;
5.1.3. 广度(宽度)优先遍历
-
创建一个队列,先将根节点放入队列;
-
进行循环,每次从队列中弹出一个节点,进行操作,并将其左、右子节点放入队列,反复进行;
-
当队列为空时结束循环。
5.2. 二叉树相关概念及其判断实现
5.2.1. 相关概念
- 搜索二叉树:对每一棵子树,都满足其左子树的值都比其小,右子树的值都比其大,则称为搜索二叉树,这种树一般没有重复元素值;
- 完全二叉树:一棵树要么是满的,要么不满的层也是从左往右依次排列的;
- 满二叉树:顾名思义全满子节点的二叉树,这种树的节点数 和最大深度
 满足
满足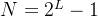 ;
; - 平衡二叉树:对于任何一棵子树,其左子树高度和右子树高度差不超过1;
5.2.2. 判断方法
- 搜索二叉树:
- 对二叉树进行中序遍历,每次遍历到的节点打印其值,最终如果得到的是有序(升序)数组,则一定是搜索二叉树;
- 也可以对每个节点进行递归,只要其有子树,就返回其子树的最大值、最小值,再将左子树最大值和该节点比较,将右子树最小值和该节点比较,如果不满足则返回不是搜索二叉树,反之返回左子树最小值和右子树最大值;
- 上面这个递归套路可以用于一切树形动态规划的问题,从左子树和右子树分别收集信息,再和节点综合得到新的信息并返回;
- 完全二叉树:对二叉树进行宽度优先遍历,如果发现任意节点有右子节点而无左节点,则不是完全二叉树;同时如果发现任意节点的左右子节点不双全(缺少右子节点或者左右都缺),则后续的所有节点都是叶节点,否则不是完全二叉树;
- 满二叉树:
- 可以遍历两次节点,得到最大深度和节点数,计算是否满足公式;
- 也可以用递归套路,轻松得到最大深度和节点数,从下面叶节点收集最大深度信息,以及左右子树节点个数,将节点个数相加再加一,往上返回;
- 平衡二叉树:使用递归返回左右子树的高度,并计算高度差,如果超过1则直接终止递归,返回不是平衡二叉树的结果,反之则将左右子树的高度最大值+1并返回;
5.3. 递归套路
- 在5.2.2. 搜索二叉树中讲到的方法,可以解决很多难题;
- 题目:给定两个节点,找到其最低公共祖先。解法:从子树中收集信息,如果左右子树存在这两个节点,则返回该节点,停止递归;
- 题目:为一个树中每个节点找到其中序遍历的后继节点。解法:开始直接判断该节点是否有右子树;如果某个节点有右子树,则右子树的最左节点即为其后继节点,如果没有的话则向上返回信息,每往上一层判断是否为上一层节点的右子树,是的话再往上,不是的话直接返回上一层节点;同时如果这个节点是整棵树的最右边界,则其没有右子节点且一路返回到根节点也一直是上一层的右子树,此时返回None。
5.4. 对折折痕问题
- 将一张纸反复对折,每次会出现
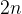 条新折痕,
条新折痕, 是对折次数,这些折痕有凹的有凸的,可以用满二叉树记录这个凹凸的规律;
是对折次数,这些折痕有凹的有凸的,可以用满二叉树记录这个凹凸的规律; 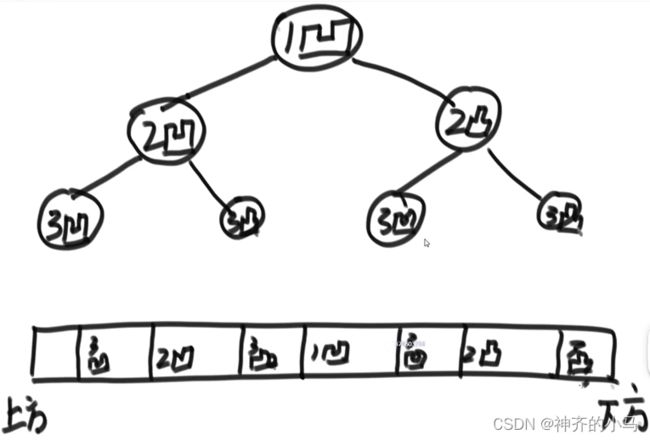
- 如上图所示,第层节点是第次对折出现的新折痕,而将该树进行中序遍历即可得到纸上折痕的顺序,可见每个节点左侧子节点都是凹,右侧子节点都是凸;
- 这个二叉树可以存在于脑海中,因为每个节点子节点都是左凹右凸,因此仅仅通过递归即可打印全部节点的顺序,而无需生成一个真实的二叉树再进行遍历,如此可以释放空间。
5.5. 树形DP
- 对于一棵树的动态规划问题,通常情况要对于任意一个节点,选择是否对这个节点进行操作,这个是否操作的决策将有若干约束,最终寻找收益最大化的决策方案;
- 同样可以使用递归套路,从左右子树的递归结果中收集信息,但不同的是每次递归要考虑两个决策,要对该节点操作和不要对该节点操作,并根据约束计算两种决策情况下左右子树递归的结果,最终将两种情况各自最优结果返回;
- 例题:打家劫舍问题,小偷发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为 root ,除了 root 之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果两个相连的房子同时被打劫,房屋将自动报警。给定二叉树的
root。返回 在不触动警报的情况下 ,小偷能够盗取的最高金额 。class Solution: def rob(self, root: Optional[TreeNode]) -> int: def dfs(node: Optional[TreeNode]) -> (int, int): if node is None: # 边界条件 return 0, 0 # 没有节点,怎么选都是 0 l_rob, l_not_rob = dfs(node.left) # 递归左子树 r_rob, r_not_rob = dfs(node.right) # 递归右子树 rob = l_not_rob + r_not_rob + node.val # 选 not_rob = max(l_rob, l_not_rob) + max(r_rob, r_not_rob) # 不选 return rob, not_rob return max(dfs(root)) # 根节点选或不选的最大值
6. 图
6.1 图的表达和生成
6.1.1. 邻接表
- 以点集作为单位,表示直接相连的点;
- 可以表示有向图也可以表示无向图;
- 方便对有权图进行表达;
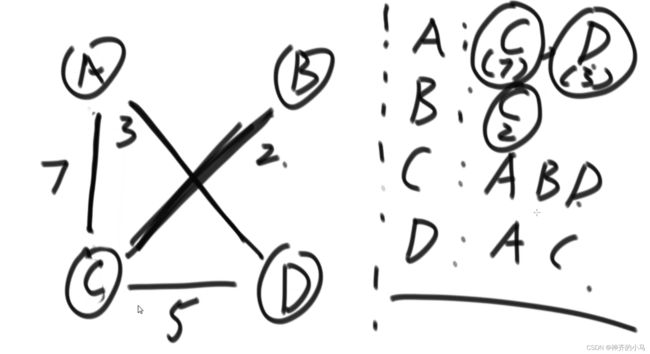
6.1.2. 邻接矩阵
- 用一个矩阵
 表示每两个点的距离,
表示每两个点的距离,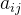 表示 节点到 节点的距离;
表示 节点到 节点的距离; - 无权图距离均为1(可达)、0(与自己的距离)或无穷(不可达),有权图则将1改为对应权值;
- 同样可以表示有向图也可以表示无向图;

6.1.3. 左神推荐结构
- 首先定义图中的节点结构:
- 节点有value,代表这个点的唯一标识;
- 节点有入度inDegree和出度outDegree,代表这个节点入边个数和出边个数,对于无向图,所有节点入度等于出度;
- 节点有下个节点集nexts,作为一个list记录了所有的从该节点出发,可以到达的下一个节点;
- 节点有出边集edges,作为一个list记录了所有从该节点出发的边;
- 再定义图中的边,包含边的权重,以及from节点和to节点;
- 用一个哈希表存储所有的点,同时依次存储每个点的值、入度、出度、下个节点集和出边集;
class Edge:
def __init__(self, value=1, fromNode=None, toNode=None):
self.value = value
self.fromNode = fromNode
self.toNode = toNode
class GraghNode:
def __init__(self, value, inDegree=0, outDegree=0, nexts=[], edges=[]):
self.value = value
self.inDegree = inDegree
self.outDegree = outDegree
self.nexts = nexts.copy()
self.edges = edges.copy()
def printNode(self):
nextValue = []
for x in self.nexts:
nextValue.append(x)
print(f'节点值为{self.value},入度{self.inDegree},\
出度{self.outDegree},后续节点{nextValue}')
6.1.4. 左神推荐技巧
- 考试中图的考察不多(大概三个公司会有一道),但是每一道从头撸都比较费功夫,建议提前用一种数据结构熟练所有题,在考试中直接将题目给出的图的数据结构(可能五花八门)转为自己的专属结构,再套用题目的解法即可;
6.2. 图的遍历算法
6.2.1. 宽度优先遍历
- 算法流程(利用一个队列来实现):
- 首先从源节点开始,依次按照宽度将节点放进队列;
- 放进一个点后,则需要把队列顶端的节点弹出,并进行处理;
- 每弹出一个点,则需要把该弹出节点的所有没进过队列的邻接点放入队列(可以用一个set 实现),并循环进行该步操作;
- 直至队列变空;
6.2.2. 深度优先遍历
- 算法流程(利用一个栈来实现):
- 首先从源节点开始,依次按照深度将节点放进栈;
- 放进一个点后,则需要把栈顶端的节点弹出,并进行处理;
- 每弹出一个点,则需要把该弹出节点的下一个没进过队列的邻接点放入队列(可以用一个set 实现),并循环进行该步操作;
- 直至栈变空;
6.3. 拓扑排序算法
- 拓扑排序:当一些事件之间相互有依赖关系时(即必须要完成一个节点才能进行下一步),此时可以将这两个事件建立为图中的节点,并将前序事件指向后续后续事件,这样构成了一个拓扑排序图(必须是有向图);
- 解法:从拓扑排序图中解出依赖关系的方法:
- 首先找到入度为0的节点,这些节点只有指向其他的路径,没有其他路径指向它,那这个事件一定没有前提,只会成为其他事件的前提;
- 找到上一步所有入度为0的节点后,将其全部压入列表,再从图中去除这些节点,及其所发出的路径;
- 经过去除,拓扑排序图变成了一个新的结构,再重复上述两步,将后面找到并去除的节点都依次压入列表,直到全部节点都被去掉,列表便是排序结果(同级事件相互顺序可以调换,拓扑排序本质上是对事件的时间优先级进行排序,有一些前提必须先完成才能做后面的事,因此相同级别的前提事件可以调换顺序来进行);
6.4. 最小生成树算法
6.4.1. 最小生成树的概念
- 对于一个图,如果其为无向连通图(每两个节点都有至少一条路径可达,这条路径可以有若干条边),且可以保证现有所有边的权值之和最小,则被称为最小生成树;
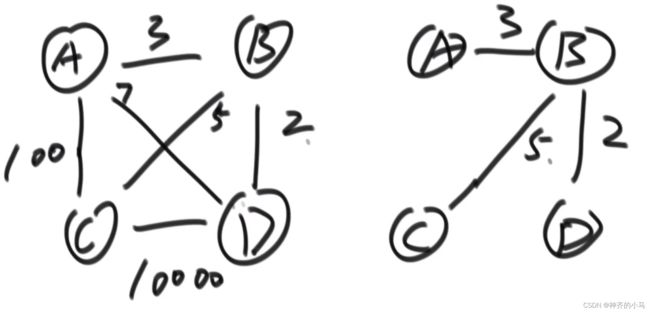
6.4.2. K算法(Kruscal)
- 算法思路:
- 对于一个已有的无向图,其连通性存在冗余,则可以将其所有边都去除,再从权值最小的边开始复原;
- 每次观察复原后,图中会不会出现一个环,如果出现则删除这个边(不复原);
- 具体实现:
- 首先将所有节点分别放入一个空集合,也就是创建N个各不相同的集合,每个集合存放一个节点;
- 从权值最小的边开始,这个边连接的是A和B两个节点,则需要从所有集合中查找A所在的节点和B所在的节点,如果不是同一个,则说明无环,可以复原这个边,否则不行,再找下一个权值最小的边;
- 如果复原了一个边,则将其两边节点所在的集合拼起来成一个并集(并集内的所有节点就相互可达了);
- 完成二三步后对下一个最小权值的边重复;
6.4.3. P算法(Prim)
- 算法思路:
- 同样对于一个无向图,首先从任意一个节点出发,将这个节点连接的所有边都激活,并在激活的边中选择一个权值最小的,并通过这个边移动到另一端的节点,继续激活新节点连接的所有边,并从所有已激活的边中寻找权值最小的边,循环往复直至所有节点都被遍历;
- 被选择的边必须满足:
- 不能是已经走过的路径;
- 这个边必须要能到达一个新的,没有被遍历过的节点;
- 具体实现:
- 从一个节点出发,将该节点放入一个集合,将其连接的所有边放入小根堆;
- 从小根堆中所有边找到一个权值最小的边,判断其是否可以到达一个新节点,即集合中不存在的节点,如果不能则继续找下一个权值最小的边,直至找到;
- 将当前节点重置为那个找到的边可以移动到的新节点,并将其放入集合,将其所有边放入小根堆,将刚刚走过的边从小根堆中删除(不删除也可以,因为其两边的节点都是已经遍历过的,因此后续也会被排除,但是这样会增加常数级时间复杂度);
- 重复二三步,直至没有边可以达到新节点;
6.5. Dijkstra算法(单元最短路径算法)
- 问题描述:对于一个无向图,给定一个起点,要求返回其到达其他所有节点的最短路径(路径总权值最小);
- 解法:采用一种动态规划、逐步优化的思想:
- 先初始化一个数组,其第一个元素为0,代表起点到其自身的最短路径为0,其他元素为无穷;
- 从数组中找到最小值所在的节点,即起点自身,然后查找该最小节点所连接的边,选择其中一条边,判断这个选择是否可以让数组中某个元素值变小(存在更短的路径到达这个节点);
- 重复第二步直至这个最小节点的所有边都被遍历完,然后在剩下的节点中寻找值最小的节点,继续重复第二步;
- 反复第三步,且除了第一次判断起点以外,但每一次这个最小节点判断其边是否会让其他值变小时,是通过这个最小节点自身的值和边的权值相加,作为一个新路径,如果这个新路径比该边另一端的节点值小时,更新其值(找到了新的最短路径);
- 直至所有节点都被遍历完,算法停止,此时返回这个数组就是结果;
- 该算法只适用于无向图,且没有权值为负数的边;
7. 前缀树
- 定义:将一个字符串按次序,将其每个字符都定义一个路径(边),遍历所有字符串,即可得到一棵前缀树;

- 结构:经典结构将内容放在路径上,节点为空,但实际中为了方便功能实现,通常可以将一些信息加入节点,例如(左神推荐)每个节点有个pass和一个end两个参数,每当一条路(一个字符串)经过了这个节点,就将这个节点pass+1,如果字符串在这里终结,则将这个节点end+1;
- 通过pass和end两个参数,可以非常方便进行一些功能化查询,例如在上面的示意图中查找是否有 'bc' 这个字符串,就可以从头节点开始,查找 'b' ,有 'b' 再查找 'c' ,查看 'c' 后面的节点end值,就可以知道 'bc' 被加入了几次;
- 再例如查找 'ab' 为前缀的字符串个数,只要从头结点开始,查找 'a' ,有 'a' 再查找 'b' ,再查看 'b' 后面节点的pass值,就可以知道有多少条路从头出发,经过了 'ab' ,即为 'ab' 为前缀的字符串个数;
- 根节点的pass值即为总的字符串个数,根节点的end代表空字符串个数;
- 删除:需要删除一个字符串时,首先要查询该字符串是否存在,若存在则开始删除,方法就是从头结点开始沿途的pass值都-1,最后路末端节点end-1,若pass值减为了0则删除末端的路径和节点;
8. 贪心算法
8.1. 会议安排案例
- 问题:现在有一个会议室和一堆会议,会议给出了开始和结束时间,但相互之间可能会有时间冲突,如何在这个会议室安排下尽可能多的会议;
- 解法:可以使用贪心算法求解,但贪心选取的指标很重要,在这个问题中可以选择会议结束时间作为贪心指标(越早结束越优先被安排);
8.2. 矛盾
- 对于一个问题,我们选取了某个指标进行贪心探索,但这个指标是否合适?贪心算法得到的局部最优解是否逼近了全局最优解?这个矛盾我们是不清楚的;
- 对于上述的问题,可以通过数学方法严格证明局部最优解是否等于全局最优解,但通常情况下没有这个时间精力;
- 可以简单实现一个不依赖贪心算法的策略,例如暴力枚举法,找到最优方案作为标杆,用对数器比较不同指标的贪心策略哪个最接近标杆;
8.3. 哈夫曼编码问题
- 问题:现有一根金条,总长度为60,有三个人需要分这根金条,长度分别为10,20,30,每次切一刀,所需的成本都是被切金条的长度;
- 例如,先切一刀分为10和50,花费成本为切之前的60,再切一刀为20和30,花费成本又多了切之前的50,共110;
- 另一种方案,先切一刀为30和30,花费60,再切一刀为10和20,花费成本为30,共90,优于上面的方案;
- 解法:每次将最小的两个相加,并从总体中切出来,例如上面的例子,最小的两个是10和20,因此需要切的第一刀就是10+20=30;
- 这个问题所用到的解法即为哈夫曼编码,一开始将所有的数放进小根堆,每次弹出堆顶(最小)的两个数,相加,再将相加的结果放回小根堆,直至小根堆只剩一个数时结束,返回沿途所有的成本累加;
8.4. 跳跃问题
- 问题:

- 解答:用贪心方法不断更新最远可到达距离
class Solution: def canJump(self, nums) : max_i = 0 #初始化当前能到达最远的位置 for i, jump in enumerate(nums): #i为当前位置,jump是当前位置的跳数 if max_i>=i and i+jump>max_i: #如果当前位置能到达,并且当前位置+跳数>最远位置 max_i = i+jump #更新最远能到达位置 return max_i>=i
N. 小技巧
N.1 快慢指针
- 当题目要需要找到数组/链表/字符串中点,或需要遍历一半的数组/链表/字符串时(例如回文),可以用两个指针,快指针一次走两步,慢指针一次走一步,当快指针走完时,慢指针便到达了中点。
- 当数组/链表/字符串长度为偶数时,可以用快慢指针走的次序控制慢指针停在两个中点中的前一个或后一个。
N.2 字符串拼接计算字典序
- 两个字符串拼接,计算拼接后的字段序时,可以将这个问题转化为纯数学运算,例如可以将字母根据字典序转换为26进制数,例如‘ba’ 视为2 1,则 ‘ba’ + ‘b’ = 2 1 * 26^(len(b)) + 2,也就是26进制计算;