复习pandas导入外部数据、切片,练习子图、图表元素设置(中国大学数据集)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
一、实验要求
二、相关文件
三、使用 Jupyter工具导入项目步骤
四、实验内容
1.导入pandas numpy模块并读取文件 中国大学数据集.csv , 显示前topn行
2. 绘制不同类型学校数量的散点图
3.#绘制省份大学数量的统计直方图(hist)
4.创建一个1x2 的子图, 第一个子图绘制公或民办不同办学性质学校数量的柱状图
5.在1x2的子图上分别 绘制北京市和湖北省 公或民办 学校数量比例的饼图
五、总结
一、实验要求
本次实验主要目的如下:
- 复习pandas导入外部数据、切片;
- 练习子图、图表元素设置;
- 结合实际案例数据联系多种图表的绘制;
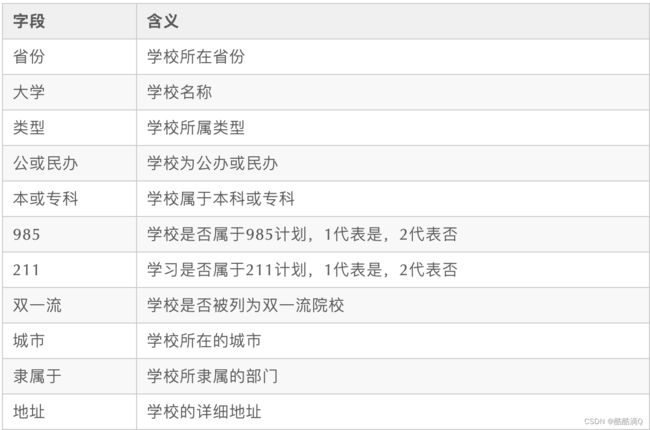
本次实验使用的数据集为 中国大学数据集, 该数据集每条数据字段含义如下:
二、相关文件
链接:https://pan.baidu.com/s/1CeCEVQYwn5E0NK4JcJfjtQ
提取码:kkdq
三、使用 Jupyter工具导入项目步骤
1.菜单栏中找到Anaconda Prompt (Anaconda3),点击运行

2.输入: cd 指定项目的文件夹路径
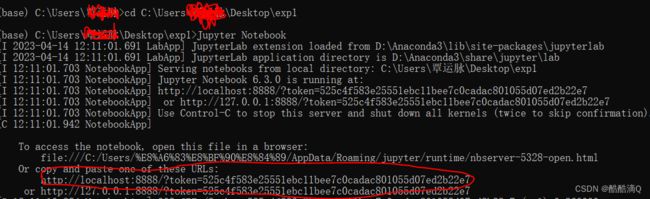
3.启动项目: Jupyter Notebook
4.复制倒数第一个链接到网页访问。
四、实验内容
注:以下实验内容,如果是使用Jupyter工具编写,一定要从第一个开始运行到下一个,避免出现未定的的变量;如果使用其它的python编译器,一定要补充相应的模块和数据的定义。
1.导入pandas numpy模块并读取文件 中国大学数据集.csv , 显示前topn行
# 导入pandas numpy模块并读取文件 中国大学数据集.csv , 显示前topn行
# todo
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
whc_id = 629
topn = whc_id % 43
path='中国大学数据集.csv'
data = pd.read_csv(path,sep=',')
h=data.head(topn)
print(h)

2. 绘制不同类型学校数量的散点图
要求: 横轴标签为省市、纵轴标签为大学数量。横轴的刻度要用省市名称
# 绘制不同类型学校数量的散点图
# 要求: 横轴标签为省市、纵轴标签为大学数量。横轴的刻度要用省市名称
t_col=data['省份'].value_counts()
#print(t_col.values)
y=t_col.values
x=[i for i in range(len(t_col))]
label=list(t_col.index)
#print(x)
plt.rcParams['font.sans-serif']='SimHei'
plt.scatter(x,y)
plt.xlabel('省份')
plt.ylabel('大学数量')
plt.xticks(x,label,rotation=90)
plt.title('各省份大学数量')
plt.show()
# 提示: 可以使用Series.value_counts()
# 样例如下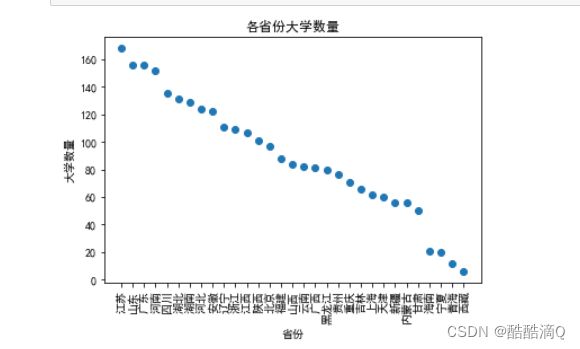
3.#绘制省份大学数量的统计直方图(hist)
# 绘制省份大学数量的统计直方图(hist)
path='中国大学数据集.csv'
data = pd.read_csv(path,sep=',')
t_col=data['省份'].value_counts()
y=t_col.values
plt.figure(2)
plt.hist(y)
plt.ylabel('频数')
plt.xlabel('省份大学数量')
plt.title('省份大学数量的统计直方图')
plt.show()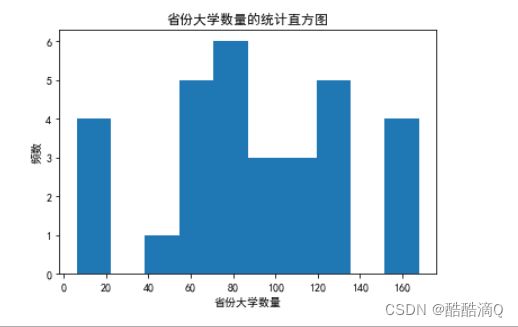
4.创建一个1x2 的子图, 第一个子图绘制公或民办不同办学性质学校数量的柱状图
要求有图例,横轴刻度为对应字符串(公办、民办、中外合作办学)
# 第二个子图绘制本科专科学校数量的柱状图, 要求有图例, 横轴刻度为对应字符串(本科、专科)
# 分值: 30
# 创建一个1x2 的子图, 第一个子图绘制公或民办不同办学性质学校数量的柱状图,要求有图例,横轴刻度为对应字符串(公办、民办、中外合作办学)
# 第二个子图绘制本科专科学校数量的柱状图, 要求有图例, 横轴刻度为对应字符串(本科、专科)
import matplotlib.pyplot as plt
import pandas as pd
# 读取数据集
data = pd.read_csv('中国大学数据集.csv', encoding='utf-8')
# 统计不同类型学校数量
type_counts = data['公或民办'].value_counts()
type_names = type_counts.index.tolist()
type_values = type_counts.values.tolist()
# 创建第一个子图
plt.subplot(1, 2, 1)
plt.rcParams['font.sans-serif']='SimHei'
plt.bar(type_names, type_values)
plt.title('办学性质')
plt.xlabel('办学性质')
plt.ylabel('学校数量')
plt.legend(['公办', '民办', '中外合作办学'])
# 统计本科专科学校数量
edu_counts = data['本或专科'].value_counts()
edu_names = edu_counts.index.tolist()
edu_values = edu_counts.values.tolist()
# 创建第二个子图
plt.subplot(1, 2, 2)
plt.rcParams['font.sans-serif']='SimHei'
plt.bar(edu_names, edu_values)
plt.title('本专分布')
plt.xlabel('学历类型')
plt.ylabel('学校数量')
plt.legend(['本科', '专科'])
plt.show()

5.在1x2的子图上分别 绘制北京市和湖北省 公或民办 学校数量比例的饼图
# 分值: 20
# 在1x2的子图上分别 绘制北京市和湖北省 公或民办 学校数量比例的饼图
import matplotlib.pyplot as plt
import pandas as pd
# 读取数据集
data = pd.read_csv('中国大学数据集.csv', encoding='utf-8')
#print(df)
# 按省份和办学性质进行过滤,得到北京市公、民办学校数量
bj_public_count = len(data[(data['省份']=='北京') & (data['公或民办']=='公办')])
bj_private_count = len(data[(data['省份']=='北京') & (data['公或民办']=='民办')])
# 按省份和办学性质进行过滤,得到湖北省公、民办学校数量
hb_public_count = len(data[(data['省份']=='湖北') & (data['公或民办']=='公办')])
hb_private_count = len(data[(data['省份']=='湖北') & (data['公或民办']=='民办')])
# 绘制饼图
labels = ['公办', '民办']
# 创建第一个子图
plt.subplot(1, 2, 1)
plt.pie([bj_public_count, bj_private_count], labels=labels, autopct='%1.2f%%')
plt.title('北京市公或民办学校数量比例的饼图')
# 创建第二个子图
plt.subplot(1, 2, 2)
plt.pie([hb_public_count, hb_private_count], labels=labels,autopct='%1.2f%%')
plt.title('湖北省公或民办学校数量比例的饼图')
plt.show()

五、总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了复习pandas导入外部数据、切片,练习子图、图表元素设置,结合实际案例数据联系多种图表的绘制。