Flink1.14 Source概念入门讲解与源码解析
目录
Flink Source概念
Source
Source源码
getBoundedness()
createReader(SourceReaderContext readerContext)
createEnumerator(SplitEnumeratorContext enumContext)
SplitEnumerator restoreEnumerator(SplitEnumeratorContext enumContext, EnumChkT checkpoint) throws Exception,>
SimpleVersionedSerializer getSplitSerializer()
SimpleVersionedSerializer getEnumeratorCheckpointSerializer()
总结
参考
Flink Source概念
Flink的Source主要是由3个核心部分组成:Splits,SplitEnumerator,SourceReader。
- Split:split是数据源的一部分切片数据,source端将数据进行切片分发,可以并行去读取数据,而split就是一个切片粒度,一般每一次每个slot读取一个split进行处理。
- SplitEnumerator:SplitEnumerator是一个单例只产生在JobManager中,产生split切片并且分发给sourceReader(TM里面),主要负责负载均衡,维持等待中的split的积压平衡,并且分发split给source Reader。
- SourceReader:请求split文件并且进行处理,sourceReader是并行运行在TM的source算子中,并且产出并行的时间流/记录流。
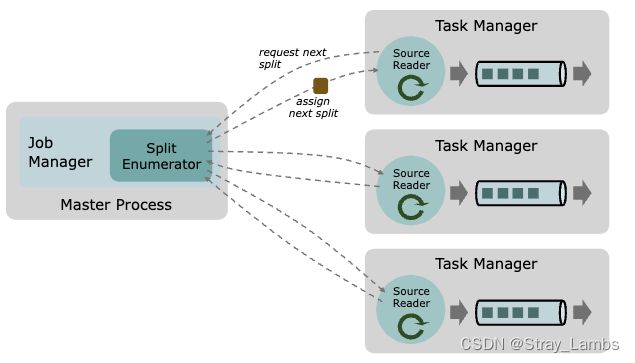
(放一下官网的图。。。)
Flink作为批流一体的架构,Data Source API支持数据文件是无界流或者是有界批文件。
对于有界批文件来说,enumerator会产生一系列的split文件,并且每一个split文件明确是有限大小的;而对于无界流来说,则有两种情况 1)splits文件是无限的 2)enumerator不断的产生新的split文件
具体说明一下:
有界文件
Source数据源存在一个URI/Path路径,并且有固定的format去明确如何解析文件。
- 一个split切片是一个文件,或者是多个文件(一个区域内)。
- SplitEnumerator会列出目录下所有的文件,当下一个reader需要split切片文件的时候,就会将下一个split发送过去,一旦所有的文件全部发送完成,那么就会发出一个 NoMoreSplits 的标志。
- SourceReader请求一个split切片,然后读取解析得到的split文件,如果没有更多的split文件后,即收到了 NoMoreSplits 那么就会停止读取。
有界Kafka
同理,只不过每一个split是一个明确的topic分区的end offset。一旦sourceReader达到了end offset,就会完成这个split文件的读取。当所有的split文件完成后,sourceReader就会结束。
无界文件流
无界的情况下,将永远不会产生 NoMoreSplits 的标志,会周期性监控URI/Path路径下是否会产生新的文件。一旦产生了新文件则会生成新的split切片并分发给可用的sourcereaders。
无界Kafka
Source数据源是一个Kafka的Topic文件,或者是一系列Topic/Topic正则。
- Split切片文件是一个Kafka的Topic分区。
- SplitEnumerator会连接broker,列出所有订阅的topic分区。enumerator能有选择的重复去发现订阅了的topics新增的分区数据。
- sourcereader读取分配的split文件(topics 分区)并不会有一个end标志,所以reader永远也不会有end的情况。
Source
在1.14-1.15版本的时候source api是一个工厂模式的接口,用于创建以下的组件。
- Split Enumerator
- Source Reader (在1.16版本之后变为通过SourceReaderFactory接口实现)
- Split Serializer
- Enumerator Checkpoint Serializer
除此之外,Source 还提供了 Boundedness 的特性,从而使得 Flink 可以选择合适的模式来运行 Flink 任务。
Source 实现应该是可序列化的,因为 Source 实例会在运行时被序列化并上传到 Flink 集群。
Source源码
接下来看看source的源码
import org.apache.flink.annotation.Public;
import org.apache.flink.core.io.SimpleVersionedSerializer;
import java.io.Serializable;
/**
* The interface for Source. It acts like a factory class that helps construct the {@link
* SplitEnumerator} and {@link SourceReader} and corresponding serializers.
*
* @param The type of records produced by the source.
* @param The type of splits handled by the source.
* @param The type of the enumerator checkpoints.
*/
// 在flink1.16之后,source的接口变为public interface Source extends SourceReaderFactory
@Public
public interface Source extends Serializable {
/**
* Get the boundedness of this source.
*
* @return the boundedness of this source.
*/
Boundedness getBoundedness();
/**
* Creates a new reader to read data from the splits it gets assigned. The reader starts fresh
* and does not have any state to resume.
*
* @param readerContext The {@link SourceReaderContext context} for the source reader.
* @return A new SourceReader.
* @throws Exception The implementor is free to forward all exceptions directly. Exceptions
* thrown from this method cause task failure/recovery.
*/
SourceReader createReader(SourceReaderContext readerContext) throws Exception;
/**
* Creates a new SplitEnumerator for this source, starting a new input.
*
* @param enumContext The {@link SplitEnumeratorContext context} for the split enumerator.
* @return A new SplitEnumerator.
* @throws Exception The implementor is free to forward all exceptions directly. * Exceptions
* thrown from this method cause JobManager failure/recovery.
*/
SplitEnumerator createEnumerator(SplitEnumeratorContext enumContext)
throws Exception;
/**
* Restores an enumerator from a checkpoint.
*
* @param enumContext The {@link SplitEnumeratorContext context} for the restored split
* enumerator.
* @param checkpoint The checkpoint to restore the SplitEnumerator from.
* @return A SplitEnumerator restored from the given checkpoint.
* @throws Exception The implementor is free to forward all exceptions directly. * Exceptions
* thrown from this method cause JobManager failure/recovery.
*/
SplitEnumerator restoreEnumerator(
SplitEnumeratorContext enumContext, EnumChkT checkpoint) throws Exception;
// ------------------------------------------------------------------------
// serializers for the metadata
// ------------------------------------------------------------------------
/**
* Creates a serializer for the source splits. Splits are serialized when sending them from
* enumerator to reader, and when checkpointing the reader's current state.
*
* @return The serializer for the split type.
*/
SimpleVersionedSerializer getSplitSerializer();
/**
* Creates the serializer for the {@link SplitEnumerator} checkpoint. The serializer is used for
* the result of the {@link SplitEnumerator#snapshotState()} method.
*
* @return The serializer for the SplitEnumerator checkpoint.
*/
SimpleVersionedSerializer getEnumeratorCheckpointSerializer();
}
我们一个一个函数来看,毕竟一堆看上去确实感觉挺头疼的。。。。
getBoundedness()
主要是返回数据源是否有界,返回类型是Boundedness的枚举类,值只有两个BOUNDED 和 CONTINUOUS_UNBOUNDED。
具体的接口实现有四类(后面的实现都是有四类,这边只讲fileSource相关的,就不会过多介绍了。。。)
public abstract class AbstractFileSource
implements Source>, ResultTypeQueryable {
@Override
public Boundedness getBoundedness() {
return continuousEnumerationSettings == null
? Boundedness.BOUNDED // 有界
: Boundedness.CONTINUOUS_UNBOUNDED; // 无界
}
}
public class DorisSource implements Source, ResultTypeQueryable {
public Boundedness getBoundedness() {
return this.boundedness;
}
}
public class HybridSource implements Source {
public Boundedness getBoundedness() {
return ((HybridSource.SourceListEntry)this.sources.get(this.sources.size() - 1)).boundedness;
}
}
public class NumberSequenceSource
implements Source<
Long,
NumberSequenceSource.NumberSequenceSplit,
Collection>,
ResultTypeQueryable {
@Override
public Boundedness getBoundedness() {
return Boundedness.BOUNDED;
}
} 其中,continuousEnumerationSettings主要的作用是设置轮询时间,多久去对于无界的文件进行扫描。
createReader(SourceReaderContext readerContext)
创建一个全新的source reader去读取分配给到它的splits文件,不包含任何状态恢复,返回接口SourceReader。在flink1.16的版本中已经放在了SourceReaderFactory接口中实现。
// abstractFileSource中的实现
@Override
public SourceReader createReader(SourceReaderContext readerContext) {
// fileSourceReader是一种读取方式,从FileSourceSplit中读取记录
return new FileSourceReader<>(
readerContext, readerFormat, readerContext.getConfiguration());
} 其中,readerContext是Flink运行时source的上下文;readerFormat是BulkFormat
createEnumerator(SplitEnumeratorContext enumContext)
为这个source创建新的SplitEnumerator,开始一个新的input。
@Override
public SplitEnumerator> createEnumerator(
SplitEnumeratorContext enumContext) {
final FileEnumerator enumerator = enumeratorFactory.create();
// read the initial set of splits (which is also the total set of splits for bounded
// sources)
final Collection splits;
try {
// TODO - in the next cleanup pass, we should try to remove the need to "wrap unchecked"
// here
splits = enumerator.enumerateSplits(inputPaths, enumContext.currentParallelism());
} catch (IOException e) {
throw new FlinkRuntimeException("Could not enumerate file splits", e);
}
return createSplitEnumerator(enumContext, enumerator, splits, null);
} 其中,enumerator是由FileEnumerator工厂类产生的,这个类主要任务是找到所有需要读取的文件,切分它们成为FileSourceSplit。并且遍历路径的同时会过滤文件(如果有文件不想要读取可以通过名称进行过滤),决定是否切分文件为多个split,如何去切分的。
splits = enumerator.enumerateSplits(inputPaths, enumContext.currentParallelism());这里则是进行切分split,里面的函数实现主要是通过递归进行遍历path。顺便提一嘴,具体实现是接口FileEnumerator的具体实现NonSplittingRecursiveEnumerator类。
@Override
public Collection enumerateSplits(Path[] paths, int minDesiredSplits)
throws IOException {
final ArrayList splits = new ArrayList<>();
for (Path path : paths) {
final FileSystem fs = path.getFileSystem();
final FileStatus status = fs.getFileStatus(path);
addSplitsForPath(status, fs, splits);
}
return splits;
}
private void addSplitsForPath(
FileStatus fileStatus, FileSystem fs, ArrayList target)
throws IOException {
if (!fileFilter.test(fileStatus.getPath())) {
return;
}
// 判断是文件还是目录,如果是文件则转化为source split去读取。
// 比如hdfs的话,就会去获取datanode的host
if (!fileStatus.isDir()) {
convertToSourceSplits(fileStatus, fs, target);
return;
}
final FileStatus[] containedFiles = fs.listStatus(fileStatus.getPath());
for (FileStatus containedStatus : containedFiles) {
// 递归遍历文件目录
addSplitsForPath(containedStatus, fs, target);
}
} 最后createSplitEnumerator这个函数则是去根据是有界数据还是无界数据进行划分,如果无界数据存在alreadyProcessedPaths也会直接去划分split,如果alreadyProcessedPaths为空,才会去周期性的监控路径是否产生新文件。(后续再讲。。。)
private SplitEnumerator> createSplitEnumerator(
SplitEnumeratorContext context,
FileEnumerator enumerator,
Collection splits,
@Nullable Collection alreadyProcessedPaths) {
// cast this to a collection of FileSourceSplit because the enumerator code work
// non-generically just on that base split type
@SuppressWarnings("unchecked")
final SplitEnumeratorContext fileSplitContext =
(SplitEnumeratorContext) context;
final FileSplitAssigner splitAssigner = assignerFactory.create(splits);
if (continuousEnumerationSettings == null) {
// bounded case
return castGeneric(new StaticFileSplitEnumerator(fileSplitContext, splitAssigner));
} else {
// unbounded case
if (alreadyProcessedPaths == null) {
alreadyProcessedPaths = splitsToPaths(splits);
}
return castGeneric(
new ContinuousFileSplitEnumerator(
fileSplitContext,
enumerator,
splitAssigner,
inputPaths,
alreadyProcessedPaths,
continuousEnumerationSettings.getDiscoveryInterval().toMillis()));
}
}
@SuppressWarnings("unchecked")
private SplitEnumerator> castGeneric(
final SplitEnumerator>
enumerator) {
// cast arguments away then cast them back. Java Generics Hell :-/
return (SplitEnumerator>)
(SplitEnumerator) enumerator;
}
private static Collection splitsToPaths(Collection splits) {
return splits.stream()
.map(FileSourceSplit::path)
.collect(Collectors.toCollection(HashSet::new));
} SplitEnumerator restoreEnumerator(SplitEnumeratorContext enumContext, EnumChkT checkpoint) throws Exception
主要是通过一个checkpoint去恢复一个枚举器。最后调用的函数与createEnumerator只是多了一个checkpoint.getAlreadyProcessedPaths()参数传递。
@Override
public SplitEnumerator> restoreEnumerator(
SplitEnumeratorContext enumContext,
PendingSplitsCheckpoint checkpoint) {
final FileEnumerator enumerator = enumeratorFactory.create();
// cast this to a collection of FileSourceSplit because the enumerator code work
// non-generically just on that base split type
@SuppressWarnings("unchecked")
final Collection splits =
(Collection) checkpoint.getSplits();
return createSplitEnumerator(
enumContext, enumerator, splits, checkpoint.getAlreadyProcessedPaths());
}
SimpleVersionedSerializer getSplitSerializer()
主要是为source splits创建一个序列化器,在splits从enumerator到reader的时候或者是当reader进行checkpoint的时候执行。
@Override
public SimpleVersionedSerializer getSplitSerializer() {
return FileSourceSplitSerializer.INSTANCE;
}
@PublicEvolving
public final class FileSourceSplitSerializer implements SimpleVersionedSerializer {
public static final FileSourceSplitSerializer INSTANCE = new FileSourceSplitSerializer(); SimpleVersionedSerializer getEnumeratorCheckpointSerializer()
获取SplitEnumerator checkpoint的序列化器,用于处理SplitEnumerator#snapshotState()方法返回的结果
@Override
public SimpleVersionedSerializer>
getEnumeratorCheckpointSerializer() {
return new PendingSplitsCheckpointSerializer<>(getSplitSerializer());
} 以上就是Source的接口的所有方法,主要包含创建 SourceReader 、 SplitEnumerator 和对应get序列化器的方法。
总结
目前可以看出,Souce接口的更新,其实是因为Flink在1.12之前将批处理任务与流处理任务分为两种实现模式。
在底层实现中
DataSet API中Source对应的核心借口是InputFormat,功能上主要有三点:
- 描述输入的数据如何被划分为不同的InputSplit,继承于 INputSplitSource
- 描述如何从单个InputSplit读取记录,具体包括如何打开一个分配到的InputSplit,如何从这个INputSplit读取一条记录,如何得知记录已经读完和如何关闭这个Inputsplit
- 描述如何获取输入数据的统计信息(比如文件的大小、记录的数目)
1、3两点主要会被JobManager/JobMaster在调度Exection时使用,而第2点读取数据功能则会在运行时被TaskManager使用。
DataStream API中 Source 对应的核心接口为 SourceFunction 以及 SourceContext。前者直接继承 Function 接口与 Operator 交互,负责通用的状态管理(比如初始化或取消);后者代表运行时的上下文,负责与单条记录级别的数据的交互。此外还有其他一些辅助类型的类或接口。
运行时,Source 主要通过 SourceContext 来控制数据的输出。从 SourceContext 接口的方法即可以看出,Source 在接受到数据后的主要工作有以下几点:
- 从外部摄入数据或者生成数据,输出到下游
- 为数据生成 Event Time Timestamp(仅在 Time Characteristic 为 Event Time 时有用)
- 计算 Watermark 并输出(仅在 Time Characteristic 为 Event Time 时有用)
- 当暂时不会有新数据时将自己标记为 Idle ,以避免下游一直等待自己的 Watermark
综上所述,之前的 Source 接口并不能很好的满足批流一体的发展,所以在 FLIP-27中选择重构Source接口,新接口的核心是通过 SplitEnumerator 和 SplitReader,前者负责发现和分配 Split、触发 Checkpoint 等管理工作,后者负责 Split 的实际读取处理。此外,新增 Operator 间的通信机制(复用大部分现有的 RPC 机制),让 Source Subtask 之间可以协调完成 Event Time 对齐等新特性。最后, SplitReader 底层封装了通用的线程模型,相比之前的 SourceFunction 大大简化了 Source 的实现。
参考
漫谈 Flink Source 接口重构 | 时间与精神的小屋
Flink 源码之新 Source 架构 - 简书
数据源 | Apache Flink