专题目录
RocketMQ详解(一)原理概览
RocketMQ详解(二)安装使用详解
RocketMQ详解(三)启动运行原理
RocketMQ详解(四)核心设计原理
RocketMQ详解(五)总结提高
引子
本节参照github设计文档+源码,分析RocketMQ的核心设计原理。是本系列的核心中的核心,由于源码过于无聊,能用图说清楚的绝不用文字。从5个方面去剖析:
- 消息存储:首先明白消息如何落盘
- 通信机制:底层netty实现,RocketMQ的高效很大一部分依赖于Netty通信协议机制。
- 消息过滤:RocketMQ有别于其它MQ中间件,在Consumer端订阅消息时再做消息过滤的。
- 负载均衡:RocketMQ中的负载均衡都在Client端完成,主要可以分为Producer端发送消息时候的负载均衡和Consumer端订阅消息的负载均衡。
- 事务消息:RocketMQ采用了2PC的思想来实现了提交事务消息,同时增加一个补偿逻辑来处理二阶段超时或者失败的消息。
一、broker消息存储
本节揭露broker上消息存储的真实目录结构+存储方式。
1.1 目录、文件结构
有3个比较重要的文件:
- commitLog消息日志:消息主体以及元数据的存储主体,存储Producer端写入的消息主体内容,
- consumequeue逻辑消费队列:存储了commitLog的起始物理offset,目的是提高消息消费的性能。
- indexFile索引文件:提供了一种可以通过key或时间区间来查询消息的方法。

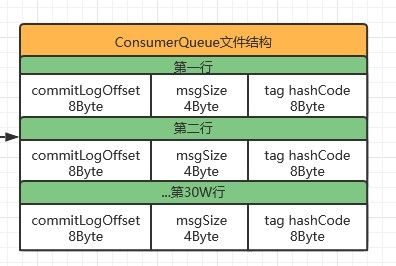
1.2 consume Queue目录结构
consumequeue文件采取定长设计,每一个条目共20个字节,分别为8字节的commitlog物理偏移量、4字节的消息长度、8字节tag hashcode,单个文件由30W个条目组成,可以像数组一样随机访问每一个条目,每个ConsumeQueue文件大小约5.72M;
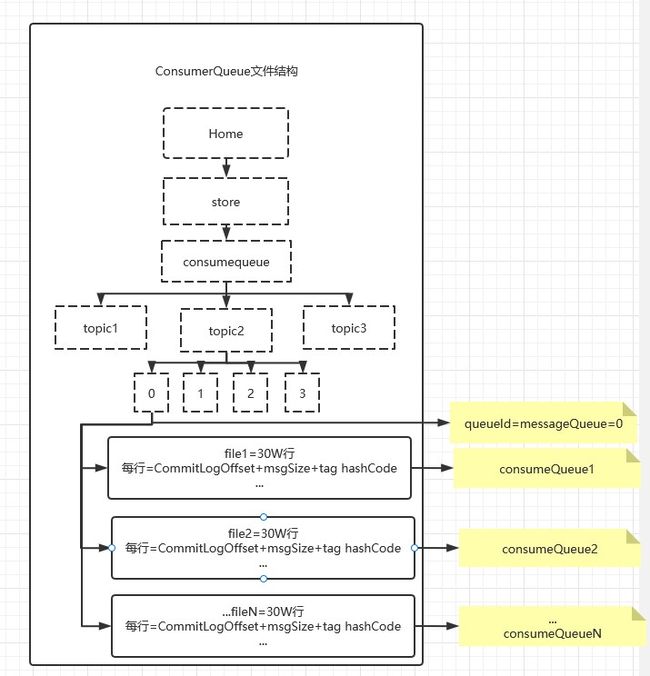
注:上图虚线框表示目录,实现框表示文件。默认一个topic对应4个queueId,即4个messageQueue。每个messageQueue文件夹下有多个consumeQueue.所以messageQueue 1:N consumeQueue(这一点官网都没说清楚,网上绝大多数博客都说不清)
1.3.消息存储整体架构图
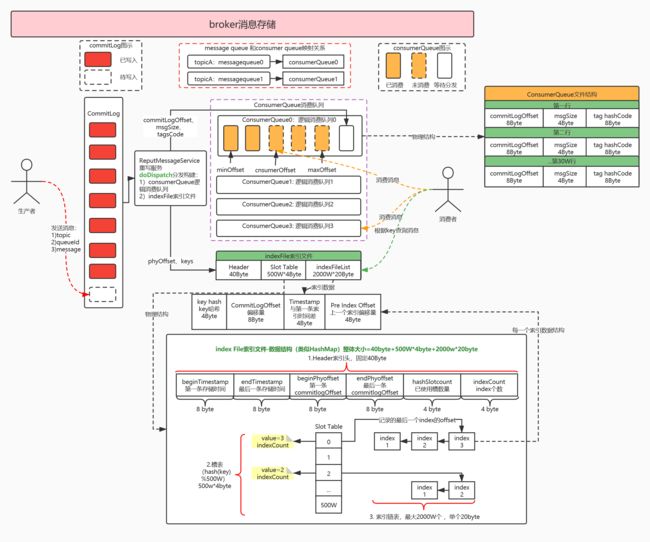
如上图(全网唯一最佳图片,优化自官方文档),RocketMQ的混合型存储结构(多个Topic的消息实体内容都存储于一个CommitLog中)针对Producer和Consumer分别采用了数据和索引部分相分离的存储结构,Producer发送消息至Broker端,然后Broker端使用同步或者异步的方式对消息刷盘持久化,保存至CommitLog中。
核心步骤:
1.首先,生产者根据topic发送消息,消息存储在commitLog中,1G一个文件。当文件满了,写入下一个文件;
2.其次,ReputMessageService重写消息服务执行2个分发操作:
1)创建ConsumerQueue逻辑消费队列:参数:commitLogOffset 物理偏移量、msgSize 消息长度、tagsCode tag哈希。可以看成是基于topic的commitlog索引文件;
2)创建IndexFile索引文件:以创建时的时间戳命名。参数:phyOffset物理偏移量(=commitLogOffset)、keys.(注意上图中每个索引数据包含4部分:key hash、commitLogOffset、timestamp diff、preIndexOffset,其中最后一个参数,官网写成了NextIndex offset,分析源码后发现是错的,slot 的值=index个数,查询时从最后一个index开始倒序查询,next index offset由此而来。例如一个槽有3个节点,3->2->1这样倒序遍历节点。在节点3中记录的就是3),
3.最后,消费者根据topic、tag拉取消息消费;根据key查询消息。
1.4 消息查询
前面分析了消息存储,顺便看一下消息查询。RocketMQ支持按照下面两种维度进行消息查询:
1.按照Message Id查询消息
RocketMQ中的MessageId的长度总共有16字节,其中包含了消息存储主机地址(IP地址和端口),消息Commit Log offset。“按照MessageId查询消息”在RocketMQ中具体做法是:
- 1)Client端从MessageId中解析出Broker的地址(IP地址和端口)和Commit Log的偏移地址后封装成一个RPC请求后通过Remoting通信层发送(业务请求码:VIEW_MESSAGE_BY_ID)。
- 2)Broker端走的是QueryMessageProcessor,读取消息的过程用其中的 commitLog offset 和 size 去 commitLog 中找到真正的记录并解析成一个完整的消息返回。
2.按照Message Key查询消息
主要是基于RocketMQ的IndexFile索引文件来实现的。结构如下图:

indexFile的具体结构,主要包含三部分:索引头Header、槽位表SlotTable(500W个槽位)、索引链表index list(2000W个索引数据),如下图:
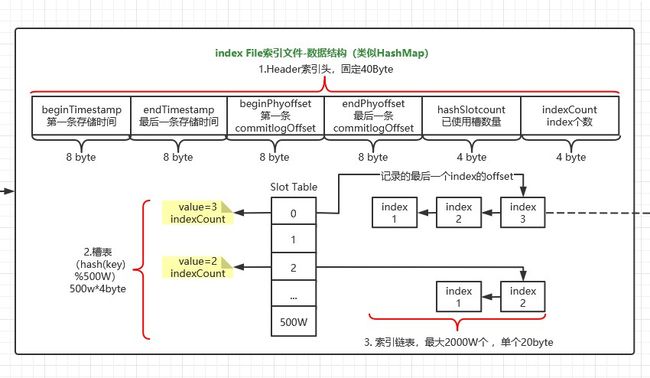
如上图所示,主要通过Broker端的QueryMessageProcessor业务处理器来查询,读取消息的过程
- 1.找槽位=40byte +hash(topic + "#" + key) %500W*4byte ,槽位值slotValue=最新插入index的位置
- 2.遍历单向链表:从slotValue找到最新index在整个索引文件中位置=40byte +500w*4byte + slotValue*20byte,然后根据单个索引文件的pre index值找到前一个索引,一直遍历下去。index数据中key hash和时间区间都满足,则匹配。添加到 List
phyOffsets(commitLog的偏移量list)中。最终根据其中的commitLog offset从CommitLog文件中读取消息的实体内容。
二、通信机制
2.1 通信架构图
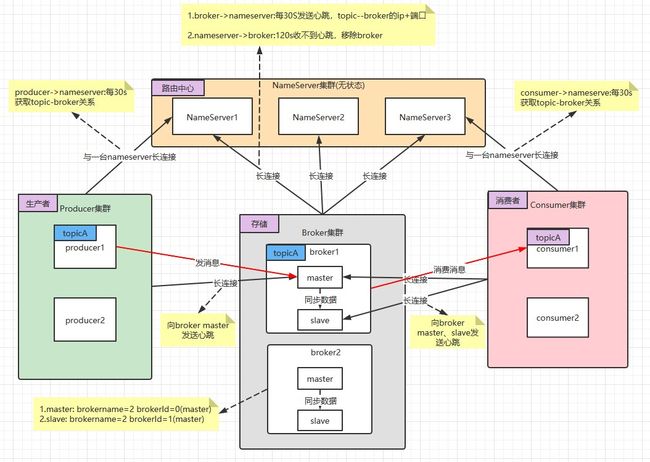
RocketMQ消息队列集群主要包括NameServer、Broker(Master/Slave)、Producer、Consumer4个角色,基本通讯流程如下:
(1) Broker启动后需要完成一次将自己注册至NameServer的操作;随后每隔30s时间定时向NameServer上报Topic路由信息。
(2) 消息生产者Producer作为客户端发送消息时候,需要根据消息的Topic从本地缓存的TopicPublishInfoTable获取路由信息。如果没有则更新路由信息会从NameServer上重新拉取,同时Producer会默认每隔30s向NameServer拉取一次路由信息。
(3) 消息生产者Producer根据2)中获取的路由信息选择一个队列(MessageQueue)进行消息发送;Broker作为消息的接收者接收消息并落盘存储。
(4) 消息消费者Consumer根据2)中获取的路由信息,并再完成客户端的负载均衡后,选择其中的某一个或者某几个消息队列来拉取消息并进行消费。
从上面1)~3)中可以看出在消息生产者, Broker和NameServer之间都会发生通信(这里只说了MQ的部分通信),因此如何设计一个良好的网络通信模块在MQ中至关重要,它将决定RocketMQ集群整体的消息传输能力与最终的性能。
为了实现客户端与服务器之间高效的数据请求与接收,RocketMQ-remoting包自定义了通信协议并在Netty的基础之上扩展了通信模块。
2.2 Remoting通信类图
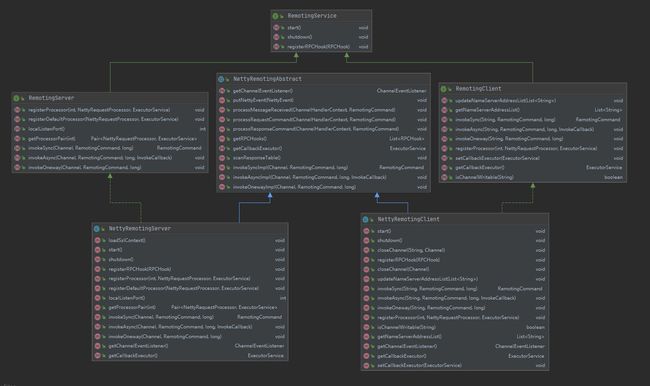
如上图所示,
RemotingService远程通信服务顶级接口:定义了启动、关闭、钩子注册3个方法。
RemotingClient远程通信客户端服务接口:继承RemotingService,拓展了获取/更新namesever地址、同步、异求、单向3种请求、注册请求处理器、添加回调执行器等方法。
RemotingServer远程通信服务端接口:继承RemotingService,拓展了注册请求处理器、获取<请求处理器,执行器>、同步、异求、单向3种请求等方法。
NettyRemotingAbstract netty远程服务抽象类:封装了获取通道事件监听器、添加netty event至执行器、处理消息接收、处理请求命令、处理返回命令、获取RPC钩子、获取回调执行器、同步、异步、单向三种请求实现方法。
NettyRemotingClient netty远程通信客户端类:继承自NettyRemotingAbstract 实现了RemotingClient接口,复写同步、异求、单向3种请求,拓展了关闭通道方法。
NettyRemotingServer netty远程通信服务端类:继承自NettyRemotingAbstract 实现了RemotingServer接口,复写同步、异求、单向3种请求。
2.3 通信流程
有三种请求方式:同步、异步、单向。其中异步最复杂,我们就分析异步通信流程,如下图:
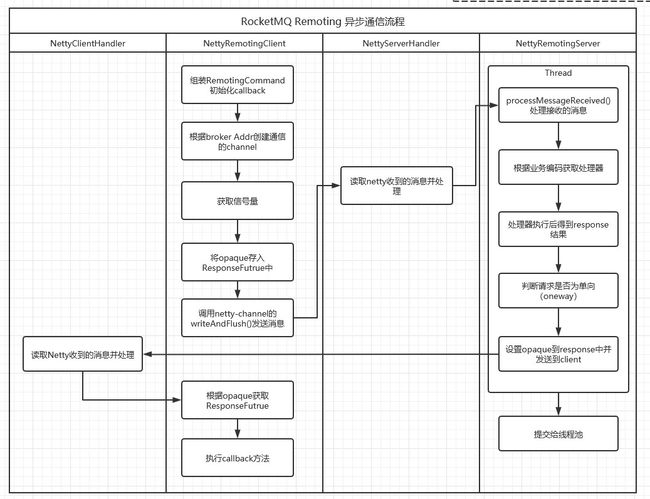
如上图所示分四大块:
1)NettyRemotingClient 【远程通信客户端】发送请求消息
2)NettyServerHandler 【服务端处理器】接收消息处理器
3)NettyRemotingServer【远程通信服务端】执行命令,发送返回消息
3)NettyClientHandler【客户端处理器】接收消息处理器
2.4 源码剖析
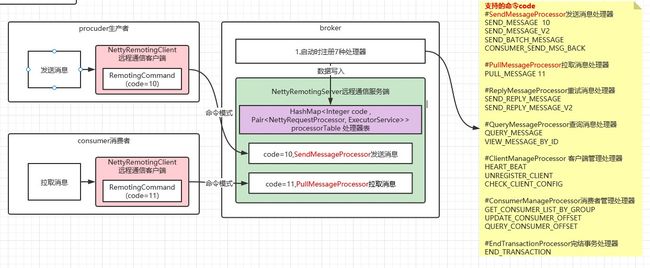
我们以【生产者发送消息给broker->broker接收->消费者从broker拉取消息消费;】这个过程来剖析完整通信流程,如下图:
2.4.1.发送消息-远程通信客户端
发送消息分同步、异步、单向三种请求类型,这里我们以异步请求为例,分析如下图:
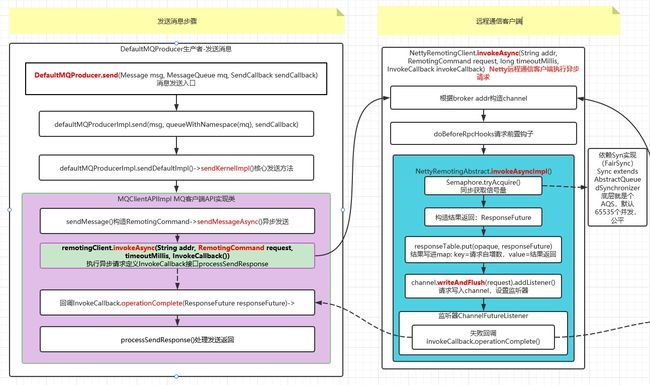
如上图所示,发送消息主流程如下:
1.DefaultMQProducer.send(): 发送消息入口
2.NettyRemotingClient.invokeAsync() :Netty远程通信客户端,执行异步请求
3.Netty 通信模块 channel.writeAndFlush(): 往通道中写数据
2.4.2 消费消息-远程通信客户端
消费消息流程需要从消费者启动开始看,consumer启动时执行了MQClientInstance.start()启动客户端实例。如下图所示:
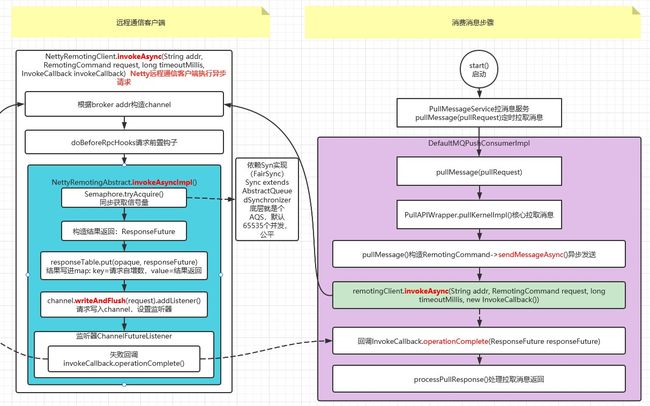
总结:
不管生产者还是消费者,通信模型一致,都是调用NettyRemotingClient远程通信客户端(RemotingClient接口)实现通信。
2.4.3 远程通信服务端(接收消息并处理)
前面第二节讲broker启动时,会执行NettyRemotingServer.start()启动远程通信服务端,内部使用ServerBootstrap类构建初始化netty channel,并自定义。
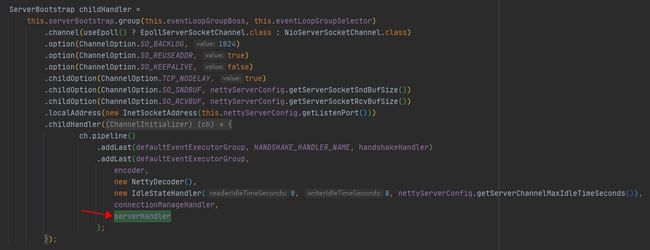
===========参数解释============
ChannelOption通道参数类中定义的参数,其中SO开头代表socket参数,TCP代表TCP参数,IP代表IP参数。
1、Integer ChannelOption.SO_BACKLOG 待处理队列长度
对应的是tcp/ip协议listen函数中的backlog参数,函数listen(int socketfd,int backlog)用来初始化服务端可连接队列,
服务端处理客户端连接请求是顺序处理的,所以同一时间只能处理一个客户端连接,多个客户端来的时候,服务端将不能处理的客户端连接请求放在队列中等待处理,backlog参数指定了队列的大小
2、Boolean ChannelOption.SO_REUSEADDR 允许覆重复使用本地地址和端口,对应于套接字(socket)选项中的SO_REUSEADDR。
比如,某个服务器进程占用了TCP的80端口进行监听,此时再次监听该端口就会返回错误,使用该参数就可以解决问题,该参数允许共用该端口,这个在服务器程序中比较常使用,
比如某个进程非正常退出,该程序占用的端口可能要被占用一段时间才能允许其他进程使用,而且程序死掉以后,内核一需要一定的时间才能够释放此端口,不设置SO_REUSEADDR就无法正常使用该端口。
3、Boolean ChannelOption.SO_KEEPALIVE 是否开启周期存活嗅探
对应于套接字(socket)选项中的SO_KEEPALIVE,设置为true,TCP会实现监控连接是否有效,当连接处于空闲状态的时候,超过了2个小时,本地的TCP实现会发送一个数据包给远程的 socket,如果远程没有发回响应,TCP会持续尝试11分钟,一直到 响应为止,如果在12分钟的时候还没响应,TCP尝试关闭socket连接。
4、Integer ChannelOption.SO_SNDBUF和ChannelOption.SO_RCVBUF 发送接收缓存区大小,默认65535
对应于套接字选项中的SO_SNDBUF,SO_RCVBUF。这两个参数用于操作接收缓冲区和发送缓冲区的大小,接收缓冲区用于保存网络协议站内收到的数据,直到应用程序读取成功,发送缓冲区用于保存发送数据,直到发送成功。
5、Integer ChannelOption.SO_LINGER 关闭时先发送数据完全
对应于套接字选项中的SO_LINGER,可以阻塞close()的调用时间,直到数据完全发送。
6、Boolean ChannelOption.TCP_NODELAY 禁止延迟发送
参数对应于套接字选项中的TCP_NODELAY,该参数的使用与Nagle算法有关,Nagle算法是将小的数据包组装为更大的帧然后进行发送,而不是输入一次发送一次,因此在数据包不足的时候会等待其他数据的到了,组装成大的数据包进行发送,虽然该方式有效提高网 络的有效负载,但是却造成了延时,而该参数的作用就是禁止使用Nagle算法,使用于小数据即时传输,于TCP_NODELAY相对应的是TCP_CORK,该选项是需要等到发送的数据量最大的时候,一次性发送数据,适用于文件传输。
=======================
上图中的最后一个参数就是NettyServerHandler继承SimpleChannelInboundHandler简单通道入站处理器,复写channelRead0方法,如下图:
1 @ChannelHandler.Sharable
2 class NettyServerHandler extends SimpleChannelInboundHandler { 3 4 @Override 5 protected void channelRead0(ChannelHandlerContext ctx, RemotingCommand msg) throws Exception { 6 processMessageReceived(ctx, msg); 7 } 8 }
最终调用processMessageReceived()处理消息接收方法。
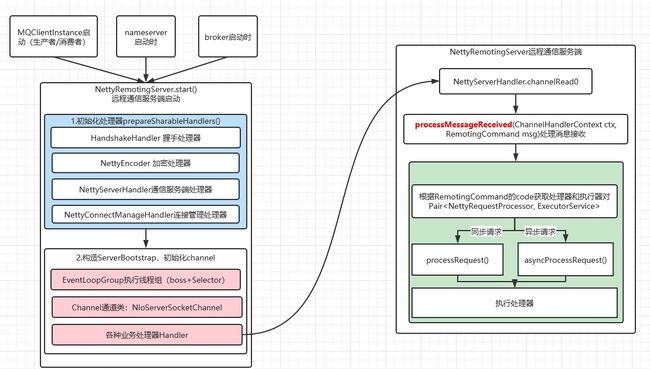
如上图所示,最终根据请求方式(同步/异步)调用processRequest()方法.处理请求。该方法实际是NettyRequestProcessor接口定义的,实现类有:SendMessageProcessor发送消息、PullMessageProcessor拉取消息,等等。
三、消息过滤
3.1 结构分析
RocketMQ是在Consumer端订阅消息时再做消息过滤的。Consumer端订阅消息是需要通过ConsumeQueue这个消息消费的逻辑队列拿到一个索引,然后再从CommitLog里面读取真正的消息实体内容,ConsumeQueue的存储结构如下,可以看到其中有8个字节存储的Message Tag的哈希值,基于Tag的消息过滤正是基于这个字段值的。
3.2 过滤方式
(1) Tag过滤方式:Consumer端在订阅消息时除了指定Topic还可以指定TAG,如果一个消息有多个TAG,可以用||分隔。其中,Consumer端会将这个订阅请求构建成一个 SubscriptionData,发送一个Pull消息的请求给Broker端。Broker端从RocketMQ的文件存储层—Store读取数据之前,会用这些数据先构建一个MessageFilter,然后传给Store。Store从 ConsumeQueue读取到一条记录后,会用它记录的消息tag hash值去做过滤,由于在服务端只是根据hashcode进行判断,无法精确对tag原始字符串进行过滤,故在消息消费端拉取到消息后,还需要对消息的原始tag字符串进行比对,如果不同,则丢弃该消息,不进行消息消费。
(2) SQL92的过滤方式:这种方式的大致做法和上面的Tag过滤方式一样,只是在Store层的具体过滤过程不太一样,真正的 SQL expression 的构建和执行由rocketmq-filter模块负责的。每次过滤都去执行SQL表达式会影响效率,所以RocketMQ使用了BloomFilter避免了每次都去执行。
四、负载均衡
RocketMQ中的负载均衡都在Client端完成,具体来说的话,主要可以分为Producer端发送消息时候的负载均衡和Consumer端订阅消息的负载均衡。
4.1 Producer的负载均衡
Producer端在发送消息的时候,会先根据Topic找到指定的TopicPublishInfo,在获取了TopicPublishInfo路由信息后,RocketMQ的客户端在默认方式下selectOneMessageQueue()方法会从TopicPublishInfo中的messageQueueList中选择一个队列(MessageQueue)进行发送消息。具体的容错策略均在MQFaultStrategy这个类中定义。这里有一个sendLatencyFaultEnable开关变量,如果开启,在随机递增取模的基础上,再过滤掉not available的Broker代理。所谓的"latencyFaultTolerance",是指对之前失败的,按一定的时间做退避。例如,如果上次请求的latency超过550Lms,就退避3000Lms;超过1000L,就退避60000L;如果关闭,采用随机递增取模的方式选择一个队列(MessageQueue)来发送消息,latencyFaultTolerance机制是实现消息发送高可用的核心关键所在。如下图:
MQFaultStrategy消息容错策略类定义如下:
1 //延迟容错开关
2 private boolean sendLatencyFaultEnable = false;
3 //延迟级别数组
4 private long[] latencyMax = {50L, 100L, 550L, 1000L, 2000L, 3000L, 15000L};
5 // 不可用时长数组,和latencyMax对应。
6 private long[] notAvailableDuration = {0L, 0L, 30000L, 60000L, 120000L, 180000L, 600000L};
selectOneMessageQueue(tpInfo,lastBrokerName)源码如下:
1 public MessageQueue selectOneMessageQueue(final TopicPublishInfo tpInfo, final String lastBrokerName) {
2 // 开启容错开关,默认不开启
3 if (this.sendLatencyFaultEnable) {
4 try {
5 // 从0开始,每个线程获取自增queue id
6 int index = tpInfo.getSendWhichQueue().getAndIncrement();
7 // 遍历messageQueueList
8 for (int i = 0; i < tpInfo.getMessageQueueList().size(); i++) {
9 // index绝对值 对 队列size 取模
10 int pos = Math.abs(index++) % tpInfo.getMessageQueueList().size();
11 if (pos < 0)
12 pos = 0;
13 MessageQueue mq = tpInfo.getMessageQueueList().get(pos);
14 // 1.不在容错队列中,或者在容错队列中但已过延迟时间,直接返回
15 if (latencyFaultTolerance.isAvailable(mq.getBrokerName()))
16 return mq;
17 }
18 // 2.都在容错队列中且有效,获取一个“不是最差”【核心算法2】的broker
19 final String notBestBroker = latencyFaultTolerance.pickOneAtLeast();
20 // 获取该broker中可写队列数
21 int writeQueueNums = tpInfo.getQueueIdByBroker(notBestBroker);
22 // 存在可写对列
23 if (writeQueueNums > 0) {
24 // 【核心算法1】:随机递增取模 选择一个queue
25 final MessageQueue mq = tpInfo.selectOneMessageQueue();
26 // 如果存在需要容错的broker
27 if (notBestBroker != null) {
28 mq.setBrokerName(notBestBroker);
29 mq.setQueueId(tpInfo.getSendWhichQueue().getAndIncrement() % writeQueueNums);
30 }
31 return mq;
32 // 没有可写的队列,直接从容错列表移除
33 } else {
34 latencyFaultTolerance.remove(notBestBroker);
35 }
36 } catch (Exception e) {
37 log.error("Error occurred when selecting message queue", e);
38 }
39 //3.在容错队列中,但没有可写队列,随机选择一个消息队列
40 return tpInfo.selectOneMessageQueue();
41 }
42 // 4.未开启容错开关,随机递增取模,获取一个和上一次不同broker的mq
43 return tpInfo.selectOneMessageQueue(lastBrokerName);
44 }
步骤总结如下:
已开启容错延迟开关(默认关闭):
1.不在容错队列中,或者在容错队列中但已过延迟时间,直接返回。
2.都在容错队列中且有效,获取一个“不是最差”【核心算法2】的broker。
3.在容错队列中,但没有可写队列,随机选择一个消息队列。
未开启容错开关:
4.随机递增取模,获取一个和上一次不同broker的mq。
这里选择messagequeue时有2个核心算法:
1)selectOneMessageQueue()多线程随机递增取模。
2)pickOneAtLeast(): 不是最差随机法 根据可用、性能、解冻时间3个维度 排序,多线程自增对前半half取模。(这里源码对象名叫notBestBroker,觉得是写反了!!!not worst还差不多)
1 public String pickOneAtLeast() {
2 final Enumeration elements = this.faultItemTable.elements();
3 List tmpList = new LinkedList();
4 while (elements.hasMoreElements()) {
5 final FaultItem faultItem = elements.nextElement();
6 tmpList.add(faultItem);
7 }
8
9 if (!tmpList.isEmpty()) {
10 // 先打乱
11 Collections.shuffle(tmpList);
12 // 再排序
13 Collections.sort(tmpList);
14
15 final int half = tmpList.size() / 2;
16 // 队列有1个元素,直接返回
17 if (half <= 0) {
18 return tmpList.get(0).getName();
19 // 多线程自增,half取模
20 } else {
21 final int i = this.whichItemWorst.getAndIncrement() % half;
22 return tmpList.get(i).getName();
23 }
24 }
25
26 return null;
27 }
其中Collections.sort底层根据FaultItem对象的Comparable接口的compareTo方法实现的(数值越大(优先级越低),compareT返回正,集合升序排序)排序后,值越小,越靠前,所以前半部分是not worst。
1 public int compareTo(final FaultItem other) {
2 // 1.可用优先,返回负值
3 if (this.isAvailable() != other.isAvailable()) {
4 // A可用,B不可用
5 if (this.isAvailable())
6 return -1;
7 // A不可用,B可用
8 if (other.isAvailable())
9 return 1;
10 }
11 // 2. 延迟小优先,返回负值
12 if (this.currentLatency < other.currentLatency)
13 return -1;
14 else if (this.currentLatency > other.currentLatency) {
15 return 1;
16 }
17 // 3. 可解除延迟时间小优先,返回负值
18 if (this.startTimestamp < other.startTimestamp)
19 return -1;
20 else if (this.startTimestamp > other.startTimestamp) {
21 return 1;
22 }
23
24 return 0;
25 }
4.2 Consumer的负载均衡
在RocketMQ中,Consumer端的两种消费模式(Push/Pull)都是基于拉模式来获取消息的,pull需要手动实现拉取消息,push只需要实现消费监听器。实际底层都是pull。
consumer的负载均衡目标:Consumer端需选择从Broker端的哪一个消息队列中去获取消息。即Broker端中多个MessageQueue分配给同一个ConsumerGroup中的哪些Consumer消费。
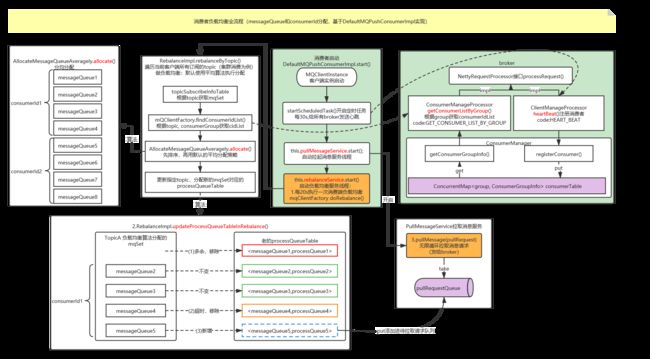
4.2.1 Consumer端的心跳包发送
在Consumer启动后,会通过定时任务不断地向所有Broker实例发送心跳包(包含:消息消费分组名称、订阅关系集合、消息通信模式和客户端id的值等信息)。Broker端在收到Consumer的心跳消息后,会将它维护在ConsumerManager的本地缓存变量:
- ConcurrentMap
consumerTable。 - ConcurrentMap
4.2.2 负载均衡的核心类RebalanceImpl
在Consumer实例启动MQClientInstance实例时,启动RebalanceService(每隔20s执行一次)
1 @Override
2 public void run() {
3 log.info(this.getServiceName() + " service started");
4
5 while (!this.isStopped()) {
6 this.waitForRunning(waitInterval);-->20s
7 this.mqClientFactory.doRebalance();
8 }
9
10 log.info(this.getServiceName() + " service end");
11 }
最终调用的是RebalanceImpl类的rebalanceByTopic()方法,该方法是实现Consumer端负载均衡的核心。这里,rebalanceByTopic()方法会根据消费者通信类型为“广播模式”还是“集群模式”做不同的逻辑处理。这里主要来看下集群模式下的主要处理流程:
1 private void rebalanceByTopic(final String topic, final boolean isOrder) {
2 switch (messageModel) {
3 case BROADCASTING: {
4 // 广播模式,直接获取mqSet
5 Set mqSet = this.topicSubscribeInfoTable.get(topic);
6 if (mqSet != null) {
7 // 直接更新
8 boolean changed = this.updateProcessQueueTableInRebalance(topic, mqSet, isOrder);
9 if (changed) {
10 this.messageQueueChanged(topic, mqSet, mqSet);
11 log.info("messageQueueChanged {} {} {} {}",
12 consumerGroup,
13 topic,
14 mqSet,
15 mqSet);
16 }
17 } else {
18 log.warn("doRebalance, {}, but the topic[{}] not exist.", consumerGroup, topic);
19 }
20 break;
21 }
22 case CLUSTERING: {
23 // 获取该Topic主题下的mq集合
24 Set mqSet = this.topicSubscribeInfoTable.get(topic);
25 // 向Broker端发送获取该消费组下消费者Id列表的RPC通信请求(Broker端基于前面Consumer端上报的心跳包数据而构建的consumerTable做出响应返回,业务请求码:GET_CONSUMER_LIST_BY_GROUP);
26 List cidAll = this.mQClientFactory.findConsumerIdList(topic, consumerGroup);
27 if (null == mqSet) {
28 if (!topic.startsWith(MixAll.RETRY_GROUP_TOPIC_PREFIX)) {
29 log.warn("doRebalance, {}, but the topic[{}] not exist.", consumerGroup, topic);
30 }
31 }
32
33 if (null == cidAll) {
34 log.warn("doRebalance, {} {}, get consumer id list failed", consumerGroup, topic);
35 }
36
37 if (mqSet != null && cidAll != null) {
38 List mqAll = new ArrayList();
39 mqAll.addAll(mqSet);
40 // mqList、clientIdList升序排序
41 Collections.sort(mqAll);
42 Collections.sort(cidAll);
43 // 实际上是平均策略AllocateMessageQueueAveragely
44 AllocateMessageQueueStrategy strategy = this.allocateMessageQueueStrategy;
45
46 List allocateResult = null;
47 try {
48 // 核心方法:使用平均算法执行分配,得到当前客户端ID分配的mqList
49 allocateResult = strategy.allocate(
50 this.consumerGroup,
51 this.mQClientFactory.getClientId(),
52 mqAll,
53 cidAll);
54 } catch (Throwable e) {
55 log.error("AllocateMessageQueueStrategy.allocate Exception. allocateMessageQueueStrategyName={}", strategy.getName(),
56 e);
57 return;
58 }
59 // 去重
60 Set allocateResultSet = new HashSet();
61 if (allocateResult != null) {
62 allocateResultSet.addAll(allocateResult);
63 }
64 // 更新指定topic下分配新的mqSet对应的processQueueTable
65 boolean changed = this.updateProcessQueueTableInRebalance(topic, allocateResultSet, isOrder);
66 if (changed) {
67 log.info(
68 "rebalanced result changed. allocateMessageQueueStrategyName={}, group={}, topic={}, clientId={}, mqAllSize={}, cidAllSize={}, rebalanceResultSize={}, rebalanceResultSet={}",
69 strategy.getName(), consumerGroup, topic, this.mQClientFactory.getClientId(), mqSet.size(), cidAll.size(),
70 allocateResultSet.size(), allocateResultSet);
71 this.messageQueueChanged(topic, mqSet, allocateResultSet);
72 }
73 }
74 break;
75 }
76 default:
77 break;
78 }
79
- 从RebalanceImpl实例的本地缓存变量—ConcurrentMap
> topicSubscribeInfoTable中,获取该Topic下的消息消费队列集合(mqSet); - 根据topic和consumerGroup为参数调用mQClientFactory.findConsumerIdList()方法向Broker端发送获取该消费组下消费者Id列表的RPC通信请求(Broker端基于前面Consumer端上报的心跳包数据而构建的consumerTable做出响应返回,业务请求码:GET_CONSUMER_LIST_BY_GROUP);
- 先对Topic下的消息消费队列、消费者Id排序,然后用消息队列的平均分配算法,计算出待拉取的消息队列。这里的平均分配算法,类似于分页的算法,将所有MessageQueue排好序类似于记录,将所有消费端Consumer排好序类似页数,并求出每一页需要包含的平均size和每个页面记录的范围range,最后遍历整个range而计算出当前Consumer端应该分配到的记录(这里即为:MessageQueue)。
- updateProcessQueueTableInRebalance(): 更新指定topic下分配新的mqSet对应的processQueueTable.如下图:
1 /**
2 * 更新指定topic下分配新的mqSet对应的processQueueTable
3 * @param topic 主题
4 * @param mqSet 分配到的去重mq set
5 * @param isOrder 是否顺序消费
6 * @return 返回boolean true:有变化 false:无变化
7 */
8 private boolean updateProcessQueueTableInRebalance(final String topic, final Set mqSet,
9 final boolean isOrder) {
10 boolean changed = false;
11 // 当前已分配关系:迭代器
12 Iterator> it = this.processQueueTable.entrySet().iterator();
13 // 遍历,移除本地废弃的/超时的mq
14 while (it.hasNext()) {
15 Entry next = it.next();
16 MessageQueue mq = next.getKey();
17 ProcessQueue pq = next.getValue();
18 // 指定topic
19 if (mq.getTopic().equals(topic)) {
20 // 1.新的mqSet不包含这个老的mq,移除
21 if (!mqSet.contains(mq)) {
22 pq.setDropped(true);
23 // 更新broker端mq的offset ;移除consumer端,废弃的。
24 if (this.removeUnnecessaryMessageQueue(mq, pq)) {
25 // 移除consumer端processQueueTable中废弃的
26 it.remove();
27 changed = true;
28 log.info("doRebalance, {}, remove unnecessary mq, {}", consumerGroup, mq);
29 }
30 //2.包含,且拉取超时(距离上次拉取超过2分钟),移除
31 } else if (pq.isPullExpired()) {
32 switch (this.consumeType()) {
33 // pull 直拉模式 蹦出
34 case CONSUME_ACTIVELY:
35 break;
36 // push 持续拉取 执行移除操作
37 case CONSUME_PASSIVELY:
38 pq.setDropped(true);
39 // 更新broker端mq的offset ;移除consumer端,超时的。
40 if (this.removeUnnecessaryMessageQueue(mq, pq)) {
41 // 移除consumer端processQueueTable中废弃的
42 it.remove();
43 changed = true;
44 log.error("[BUG]doRebalance, {}, remove unnecessary mq, {}, because pull is pause, so try to fixed it",
45 consumerGroup, mq);
46 }
47 break;
48 default:
49 break;
50 }
51 }
52 }
53 }
54
55 List pullRequestList = new ArrayList();
56 // 遍历待分配mqSet
57 for (MessageQueue mq : mqSet) {
58 // 3.新增的mq,构建pq
59 if (!this.processQueueTable.containsKey(mq)) {
60 // 如果要求有序 且 获取锁失败,跳入下个循环
61 if (isOrder && !this.lock(mq)) {
62 log.warn("doRebalance, {}, add a new mq failed, {}, because lock failed", consumerGroup, mq);
63 continue;
64 }
65 // 移除旧的offsetTable
66 this.removeDirtyOffset(mq);
67 // 构造新的pq
68 ProcessQueue pq = new ProcessQueue();
69 // 获取下一个offset
70 long nextOffset = this.computePullFromWhere(mq);
71 if (nextOffset >= 0) {
72 // 添加进已分配表processQueueTable(不包含put,包含get)
73 ProcessQueue pre = this.processQueueTable.putIfAbsent(mq, pq);
74 // 不为空,说明mq已经存在
75 if (pre != null) {
76 log.info("doRebalance, {}, mq already exists, {}", consumerGroup, mq);
77 // 为空,说明添加成功,构造pullRequest添加进pullRequestList
78 } else {
79 log.info("doRebalance, {}, add a new mq, {}", consumerGroup, mq);
80 PullRequest pullRequest = new PullRequest();
81 pullRequest.setConsumerGroup(consumerGroup);
82 pullRequest.setNextOffset(nextOffset);
83 pullRequest.setMessageQueue(mq);
84 pullRequest.setProcessQueue(pq);
85 pullRequestList.add(pullRequest);
86 changed = true;
87 }
88 } else {
89 log.warn("doRebalance, {}, add new mq failed, {}", consumerGroup, mq);
90 }
91 }
92 }
93 // 4.转发拉取请求队列
94 this.dispatchPullRequest(pullRequestList);
95
96 return changed;
97 }
98
如上图,主要流程总结如下:
1.迭代processQueueTable,过滤:
- 1)新的mqSet不包含这个老的mq,移除
- 2)包含,且拉取超时(距离上次拉取超过2分钟),移除
2.遍历待分配mqSet,有新增的MessageQueue:
- 1)移除旧的
- 2)new 一个新的 ProcessQueue。
- 3)获取MessageQueue对应的下一个offset。
- 4)把<新的mq,新的pq>添加进processQueueTable。
- 5)构造pullRequest, dispatchPullRequest()将PullRequest放入PullMessageService服务线程的阻塞队列pullRequestQueue中,待该服务线程取出后向Broker端发起Pull消息的请求。
五、事务消息(半消息事务)
Apache RocketMQ在4.3.0版中已经支持分布式事务消息,这里RocketMQ采用了2PC的思想来实现了提交事务消息,同时增加一个补偿逻辑来处理二阶段超时或者失败的消息,如下图所示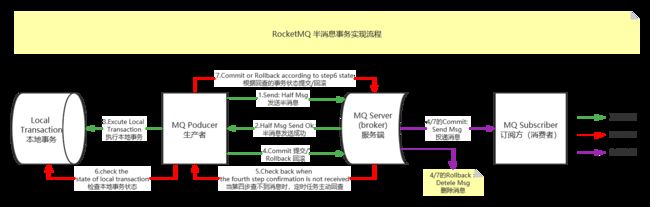
5.1 流程
上图说明了事务消息的大致方案,其中分为两个流程:正常事务消息的发送及提交、事务消息的补偿流程。
1.事务消息发送及提交:
(1) 发送消息(half消息)。
(2) 服务端响应消息写入结果。
(3) 根据发送结果执行本地事务(如果写入失败,此时half消息对业务不可见,本地逻辑不执行)。
(4) 根据本地事务状态执行Commit或者Rollback(Commit操作生成消息索引,消息对消费者可见)。
2.补偿流程:
(5) 对没有Commit/Rollback的事务消息(pending状态的消息),定时任务从服务端发起一次“回查”。
(6) Producer收到回查消息,检查回查消息对应的本地事务的状态。
(7) 根据本地事务状态,重新Commit或者Rollback。
其中,补偿阶段用于解决消息Commit或者Rollback发生超时或者失败的情况。
5.2 设计
采用2PC两阶段设计:
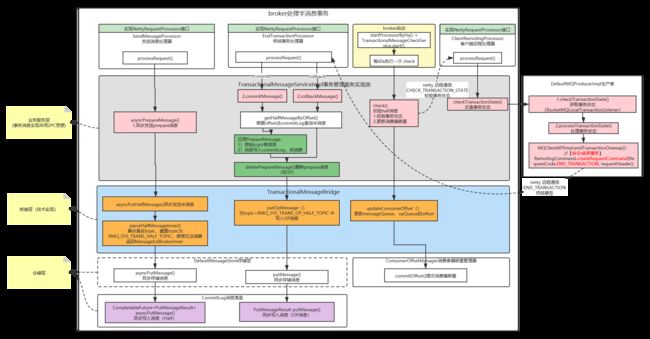
1.一阶段:Prepared阶段(预备阶段)
1)发送half消息,备份原消息的主题与消息消费队列,然后改变topic=RMQ_SYS_TRANS_HALF_TOPIC。消费者不可见。
2.二阶段:Commit和Rollback操作(确认阶段)
Commit:需要让消息对用户可见;
Rollback:需要撤销一阶段的消息。对于Rollback,本身一阶段的消息对用户是不可见的,其实不需要真正撤销消息。
RocketMQ引入了Op消息的概念,用Op消息标识事务消息已经确定状态(Commit或者Rollback)。如果一条事务消息没有对应的Op消息,说明这个事务的状态还无法确定(可能是二阶段失败了)。引入Op消息后,事务消息无论是Commit或者Rollback都会记录一个Op操作。Commit相对于Rollback只是在写入Op消息前创建Half消息的索引(可以被消费者消费到)。
3.Op消息的存储和对应关系
RocketMQ将Op消息写入到全局一个特定的Topic中通过源码中的方法—TransactionalMessageUtil.buildOpTopic();这个Topic是一个内部的Topic(像Half消息的Topic一样),不会被用户消费。Op消息的内容为对应的Half消息的存储的Offset,这样通过Op消息能索引到Half消息进行后续的回查操作。对应关系如下图:
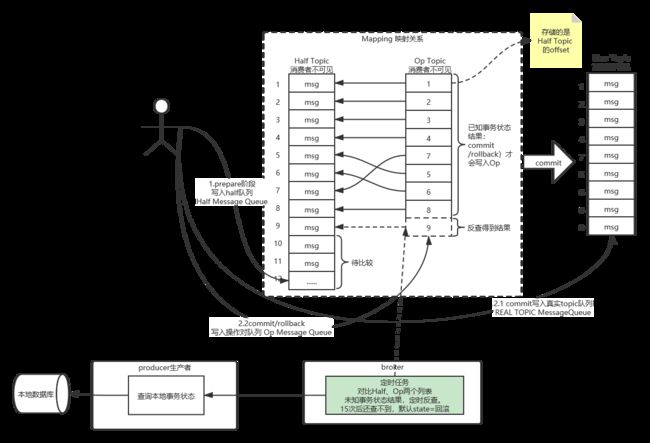
4.Half消息的索引构建
在执行二阶段Commit操作时,需要构建出Half消息的索引。一阶段的Half消息由于是写到一个特殊的Topic,所以二阶段构建索引时需要读取出Half消息,并将Topic和Queue替换成真正的目标的Topic和Queue,之后通过一次普通消息的写入操作来生成一条对用户可见的消息。所以RocketMQ事务消息二阶段其实是利用了一阶段存储的消息的内容,在二阶段时恢复出一条完整的普通消息,然后走一遍消息写入流程。
5.如何处理二阶段失败的消息?
如果在RocketMQ事务消息的二阶段过程中失败了,例如在做Commit操作时,出现网络问题导致Commit失败,那么需要通过一定的策略使这条消息最终被Commit。RocketMQ采用了一种补偿机制,称为“回查”。Broker端对未确定状态的消息发起回查,将消息发送到对应的Producer端(同一个Group的Producer),由Producer根据消息来检查本地事务的状态,进而执行Commit或者Rollback。Broker端通过对比Half消息和Op消息进行事务消息的回查并且推进CheckPoint(记录那些事务消息的状态是确定的)。
值得注意的是,rocketmq并不会无休止的的信息事务状态回查,默认回查15次,如果15次回查还是无法得知事务状态,rocketmq默认回滚该消息。
=======参考==========
https://github.com/apache/rocketmq/blob/master/docs/cn/design.md
RocketMQ之消息查询IndexFile(四)