Chewy 2023年9月 面经和题目以及总结
Chewy 整体的感觉来看应该是对 OA 的结果比较看重的公司。
如果你的 OA 没有运行结果,哪怕你是再说得天花乱坠,思路再好,他们可能都会以你的 OA 程序运行没有运行结果而告诉你的水平达不到他们公司的预期 Mark 而拒绝你进行下一步。
本轮 Chewy 的面试时间是 1 个小时,其实主要是 2 个部分。
第一部分
第一部分主要就是你的项目经验了,你在你的公司是干什么的,你在项目中有什么问题啥的。
其实这个我都认为全靠掰扯,因为所有的公司在项目上多多少少都会有点问题,完全没有问题的应该非常少,可能甚至说就是另类。
比如说 CI/CD 的问题,对中小信息系统,比如说数据 Lock 表的问题,滥用消息服务器的问题。
如果你真是大学才毕业,那这些问题可能你真的就只是听说过,并没有真正遇到过,所以这个地方不是那么好掰扯。
如果你真有过什么项目经验,这个就太好说了,随便拿几个自己做过的项目掰扯下都能说好久。
比如说,我们项目的 CI/CD 集成缓慢导致 bug 给重复覆盖的情况比比皆是。
在这里需要注意下,参加你面试的人可能会对你的说过的名词扣一下,会根据你的表述问一些具体深入的问题。
这个时候你需要小心点,如果不是自己真正做过的,如果不是自己有经验的,只是你自己听过的一些名词的话,别乱说。
因为你在后面会因为你说的这些名词解释不清。
代码
这个地方就是有意思的地方了。
我一直认为的是思路远远比结果更重要,对我自己的组员我自己的要求也是你不仅仅要有自己的思路,同时你的思路也应该能够被其他人理解。
更重要的是简单,也许有时候复杂的问题只需要简单的解决办法,可能你并不需要把自己绕晕的数据结构。
偷懒,我就不把题目全部写下来了。

请参考上面的题目,其实题目的难度不大的,多是字符串处理方面。
要解决这个题目,需要的知识:
- 据规范化处理,只保留字符。
- 数据结构 HashMap, List
- 数据结构遍历
- 字符串处理
- 数据输出
从上面来看是不是内容还是比较多的。
我的思路是:首先完成规范化处理,然后把规范化处理后的结果按照我们希望的格式放入到数据结构中,最后对放入的数据结构进行处理后输出。
删除不需要的字符
在这个地方,我们需要对不需要的字符进行删除。
这个地方需要用到正则表达式。什么?你不会用?
哈哈,这就对了,正常人不 Google 下都不会用。
好在和我面试的人给了正则表达式给我,删除不需要的字符,保留空格。
同时需要注意的是,上面的所有输出都是小写字符,因此我们还需要对大写小写字符进行转换,这个可以在构建 Map 的时候完成,省得这里还多一次循环。
实际上的代码如下:
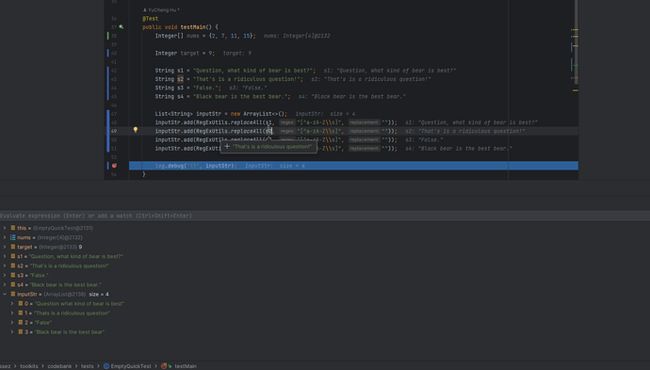
String s1 = "Question, what kind of bear is best?";
String s2 = "That's is a ridiculous question!";
String s3 = "False.";
String s4 = "Black bear is the best bear.";
List inputStr = new ArrayList<>();
inputStr.add(RegExUtils.replaceAll(s1, "[^a-zA-Z\\s]", "").toLowerCase());
inputStr.add(RegExUtils.replaceAll(s2, "[^a-zA-Z\\s]", "").toLowerCase());
inputStr.add(RegExUtils.replaceAll(s3, "[^a-zA-Z\\s]", "").toLowerCase());
inputStr.add(RegExUtils.replaceAll(s4, "[^a-zA-Z\\s]", "").toLowerCase());
程序输出如下:
构建数据结构
在数据结构构建上面,我们应该需要的是使用 Map 了。
因为我们需要首先知道有多少个字符我们要输出,对吧。
这个就是 Map 的 Key,那么 Map 的 Value 是什么呢?
根据输出来看,我们用 bear 这个单词出现了 3 次,分别在第一句话和第 4 句话里面。
那我们这个 map 怎么用?
被带沟里去了。
我就是在这里被带沟里面去了,我其实最开始想使用的是最简单的数据结构来做的,Map 的 Key 是 String ,Value 是 List,在 List 里面是字符串,这样我就有足够的数据知道我自己要干什么了。
面试的人在这里提醒了下是不是可以用 2 个 Map。
当然这里可以用 2 个 Map 的。
第一个 Map 的 Key 还是字符串,但是第二个 Map 的是 key 是整数,Value 也是整数,第一个整数是当前字符串在那个句子里面,第二个整数是在句子中的位置。
这种数据定义其实也非常明确的。
问题不在数据定义这里,问题在你最后的数据构造,因为你有了 Map 里面还有 Map 在获取值的时候容易把自己绕晕了。
结果我在这里花了 30 多分钟调试错误,后来我放弃了,我直接用我自己的第一套方案。
代码如下:
for (int i = 0; i < inputStr.size(); i++) {
String words = inputStr.get(i);
List wordsList = List.of(StringUtils.split(inputStr.get(i)));
for (int j = 0; j < wordsList.size(); j++) {
String word = wordsList.get(j);
List inStr = new ArrayList<>();
if (wordsMap.get(word) != null) {
inStr = wordsMap.get(word);
}
inStr.add((i + 1) + "#" + (j + 1));
wordsMap.put(word, inStr);
}
}
程序输出如下:

参加我面试的人在这里已经疯了。
他说从来没有见过这样输出的。
我说,这个很正常呀,我构建一个 List,上面用数字表示当前这个词所在句子的位置和在句子中的单词位置。
因为位置都是标记,所以通常都为整数,这个地方是不会那么容易抛出空对象异常的,同时上面的文本还表意,很容易定位问题。
格式化输出
这个地方我已经没有时间做了。
因为开始折腾用 2 个 HashMap 已经搞了老久了,其实到这里已经超过时间了。
可能面试的人也想帮我吧,他说你有时间吗?
如果你有时间的话我们可以继续的。
因为,可能他知道没有运行结果,公司是不会进行下一步的,所以他问了 2 次我有时间吗?他可以一起。
我自己可能觉得到这里其实输出也非常容易了,后期的格式化输出大概率情况就是排序和遍历,没有太多的实际价值,同时还要遍历 Map,我就在这里简单说了下思路。
参与面试的人,应该也容易理解了。
我觉得这个不就是面试的意义吗?说清楚思路,至于最后的格式化输出真的很重要吗?
现在已经是后话了,那么我还是贴下格式化输出的代码吧。
TreeMap> countMap = new TreeMap<>(Collections.reverseOrder());
for (Map.Entry> stringListEntry : wordsMap.entrySet()) {
Integer wordCount = stringListEntry.getValue().size();
List wordsList = new ArrayList<>();
if (countMap.get(wordCount) != null) {
wordsList = countMap.get(wordCount);
}
wordsList.add(stringListEntry.getKey());
countMap.put(wordCount, wordsList);
}
for (Map.Entry> integerListEntry : countMap.entrySet()) {
List outputList = integerListEntry.getValue();
for (int i = 0; i < outputList.size(); i++) {
List sList = wordsMap.get(outputList.get(i));
log.debug("{}[{}:{}]", outputList.get(i),integerListEntry.getKey(),sList.stream().distinct().collect(Collectors.toList()));
}
}
程序输出结果如下:

总结
这个题目看起来比较简单,数据结构设计也不复杂。
但是问题一大堆,到处都是坑。
属于典型的学院派玩法,比如说输出,要倒序,那么你在构建 map 的时候要么倒序插入,要么插入后再排序。
因为顺序有关系,所以你还不能用 HashMap,只能用 TreeMap。
我们在这里倒序插入了: TreeMap
List 重复数据去重。在最后输出的时候需要重复数据去重,你可以用最笨的 List,但是没有办法用 HashSet,因为 Set 无序,去重可能还需要保留顺序,那么就可以考虑用 Java 8 后期版本使用的 Stream。
现在考虑下,也就是为什么他们要求满足最后的输出结果了,因为后面输出哪里还会调用一些 Java 用的 API。
说思路,这个题真的不难,最后格式化输出哪里需要对数据结构进行一些调整。
但是,在没有 IDEA 环境下跑这个题目还是有点难度的,尤其是在 30 分钟内完成,如果你对 Map 的 API 不熟悉,对遍历不熟悉,对排序不熟悉,对正则表达式不熟悉,对 Print 输出不熟悉的话,我们觉得要完成还是有难度。
这种题目貌似考察点非常多,但是更多有点考察一个茴字有多少种写法那种,如果你是比较注重逻辑,比较注重思路的人,这种题目通常答不好。
对注重思路的人来说,更多的是数据怎么存,怎么调整,具体怎么输出那大部分是工具类干的事情,无非就是把输出搬来搬去罢了。
完整的代码如下,如果你使用的是纯 Java 的话,下面代码可能你还跑不起来,因为我们还用了一些第三方的类。
String s1 = "Question, what kind of bear is best?";
String s2 = "That's a ridiculous question!";
String s3 = "False.";
String s4 = "Black bear is the best bear.";
List inputStr = new ArrayList<>();
inputStr.add(RegExUtils.replaceAll(s1, "[^a-zA-Z\\s]", "").toLowerCase());
inputStr.add(RegExUtils.replaceAll(s2, "[^a-zA-Z\\s]", "").toLowerCase());
inputStr.add(RegExUtils.replaceAll(s3, "[^a-zA-Z\\s]", "").toLowerCase());
inputStr.add(RegExUtils.replaceAll(s4, "[^a-zA-Z\\s]", "").toLowerCase());
HashMap> wordsMap = new HashMap<>();
for (int i = 0; i < inputStr.size(); i++) {
String words = inputStr.get(i);
List wordsList = List.of(StringUtils.split(inputStr.get(i)));
for (int j = 0; j < wordsList.size(); j++) {
String word = wordsList.get(j);
List inStr = new ArrayList<>();
if (wordsMap.get(word) != null) {
inStr = wordsMap.get(word);
}
inStr.add(""+(i + 1));
wordsMap.put(word, inStr);
}
}
TreeMap> countMap = new TreeMap<>(Collections.reverseOrder());
for (Map.Entry> stringListEntry : wordsMap.entrySet()) {
Integer wordCount = stringListEntry.getValue().size();
List wordsList = new ArrayList<>();
if (countMap.get(wordCount) != null) {
wordsList = countMap.get(wordCount);
}
wordsList.add(stringListEntry.getKey());
countMap.put(wordCount, wordsList);
}
for (Map.Entry> integerListEntry : countMap.entrySet()) {
List outputList = integerListEntry.getValue();
for (int i = 0; i < outputList.size(); i++) {
List sList = wordsMap.get(outputList.get(i));
log.debug("{}[{}:{}]", outputList.get(i),integerListEntry.getKey(),sList.stream().distinct().collect(Collectors.toList()));
}
}
总体评价
对面试整体评价来说,感觉还是非常轻松愉快的。
面试体验不差,甚至说面试体验还比较好。虽然最后没有进入下一轮,招聘专员也非常礼貌的回信告诉我了原因,就是因为最后的代码部分没有达到他们的预期,他们的预期是完全完成。
除了这个地方有点让人感觉不好之外,其他都还是不错的。
对才毕业的学生,或者经常刷题的同学来说这个应该还是比较容易实现的。
对于小组长或者项目经理来说,通常就比较困难,因为对这些人更多的是给项目成员一些思路,然后帮助大家进行实现,因为经验丰富,通常对项目中可能出现的情况有些预期,避免大家入坑。
这里的问题在于,不是这些人写不好代码,只是这些人可能写起来更慢,说时候有时候还不如一个才毕业的同学写一些具体的东西写得快,还真是这样的。
比如说,Java 8 提供的 Stream 去重,如果你真不是在第一线天天写的话,可能你需要更长的时间才能调试完成上面的代码。
整体来说,可能 Chewy 公司要求的地方不一样吧,对 Sr 或者 PM ,他们可能要求是也能和一线码农一样非常快并且好的写完代码。
能做到吗?我觉得是可以的,只是这样真的意义大吗?
另外,他们喜欢用在线的调试代码工具,他们并不喜欢使用分享屏幕的方式查看应聘者的屏幕,可能因为在我们当前的项目中,我们更多的是通过屏幕分享的方式。
因为通过屏幕分享,大家可以知道我的思路,更主要的对方也可以用他们自己喜欢的 IDE。
对于我面试其他人的时候,有题目吗?会有的,我会提供选项的,参加我面试的人可以选择 Web 方式在上面直接说,也可以通过屏幕分享的方式在计算机上表达任何他们的想法。
甚至他们都可以用白板在计算机上画都可以。没有局限性的思想才能让大家更好的互相了解。
又是一家刷题都不知道自己要刷什么的公司。
Chewy 2023年9月 面经和题目以及总结 - 求职路上 - iSharkFly