零基础Linux_7(进程)冯诺依曼结构+操作系统原理+进程的概念和基本操作
目录
1. 冯诺依曼结构
1.1 冯诺依曼结构的概念
1.2 内存存在的意义
1.3 运算器和控制器
2. 操作系统(OS)
2.1 了解管理
2.2 先描述再组织
2.3 操作系统的管理
3. 进程初识和基本操作
3.1 进程的概念
3.2 查看进程
3.3 结束进程
3.4 获取进程标识符
3.5 fork创建子进程
本章完。
1. 冯诺依曼结构
1.1 冯诺依曼结构的概念
百度百科:
冯·诺依曼结构也称普林斯顿结构,是一种将程序指令存储器和数据存储器合并在一起的存储器结构。程序指令存储地址和数据存储地址指向同一个存储器的不同物理位置,因此程序指令和数据的宽度相同,如英特尔公司的8086中央处理器的程序指令和数据都是16位宽。
数学家冯·诺依曼提出了计算机制造的三个基本原则,即采用二进制逻辑、程序存储执行以及计算机由五个部分组成(运算器、控制器、存储器、输入设备、输出设备),这套理论被称为冯·诺依曼体系结构。
冯诺依曼结构是我们常见的计算机,如电脑、笔记本或服务器大部分都遵守的一个架构体系。

- 输入设备:键盘 | 话筒 | 摄像头 | 磁盘 | 网卡 | 写字板 ...
- 输出设备:显示器 | 音响 | 打印机 | 磁盘 | 网卡 | 显卡 ...
- 中央处理器(CPU):运算器 + 控制器 + 其他(寄存器)。
- 存储器:内存
图中的存储器指的就是内存。
不考虑缓存情况,这里的 CPU 能且只能对内存进行读写,不能访问外设(输入或输出设备),外设想要输入或输出数据,也只能写入内存或者从内存中读取。
所有设备都只能和内存打交道。
1.2 内存存在的意义
为什么冯诺依曼体系结构是这样的?
上面的讲的内存似乎很重要,内存是什么?为什么冯诺依曼体系中要存在 "内存" 这样的东西?
百度百科:
内存(Memory)是计算机的重要部件,也称内存储器和主存储器,它用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。它是外存与CPU进行沟通的桥梁,计算机中所有程序的运行都在内存中进行,内存性能的强弱影响计算机整体发挥的水平。只要计算机开始运行,操作系统就会把需要运算的数据从内存调到CPU中进行运算,当运算完成,CPU将结果传送出来。
内存的运行决定计算机整体运行快慢。
内存条由内存芯片、电路板、金手指等部分组成。

在计算机体系结构中,不同部分的材料不同,性能也不同,其中,
- 访问速度是:CPU和其内部的寄存器 >> 储存器(内存) >> 外设(磁盘/SSD>光盘>磁带)。
这是的关系是远大于,它们的速度并不是在一个量级的,比如CPU是纳秒级别的,存储器是微秒级别的,而外设是毫秒级别的。
站在我们刚刚展出的冯诺依曼体系结构来看,就是 "输入设备" 是最快的,"输出设备" 是最慢的。存储器是适中的,如果我们此时不考虑内存的存在:
先让输入设备接收用户输入,如果用户不输入,或者输入设备在接受用户期间,
我们的 CPU 是属于闲置状态的,当 CPU 把数据拿到之后再进行计算还得写,写完后还得刷。CPU 把数据计算完再交给输出设备,交给它时速度非常慢,可能还要给用户展示。
总体来说,就是输入设备非常快,运算器和输出是非常慢的。
当CPU需要一个数据,这个数据在外设和储存器中都有,如果从外设中拿需要1毫秒,从存储器中拿需要1微秒,CPU会选择从存储器中拿这个数据。
当CPU需要传出一个数据,如果直接给外设的话,也是需要1毫秒,而给存储器的话只要1微秒,CPU同样会选择将数据给存储器,然后存储器怎么处理这个数据CPU就不再管了。
可以看到,CPU直接和储存器进行数据交互,相比于直接和外设进行数据交互能够节省很多的时间。(这里就是和木桶原理(短板原理)类似)
题外话:木桶原理(短板原理)大家都知道,我个人认为在高中确实是这样的,但是到了大学我们就可以把桶斜着放了:
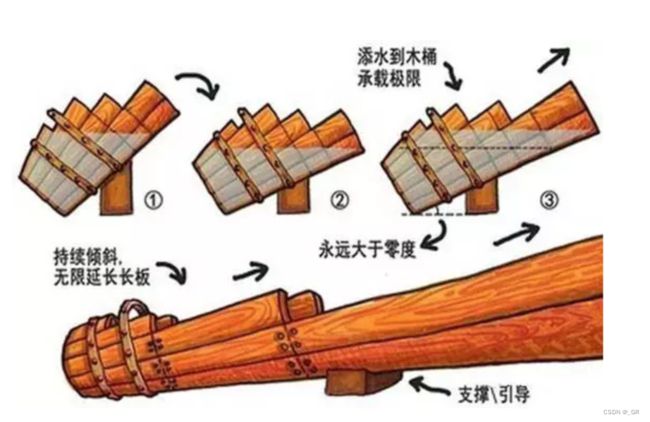
“新木桶原理”强调发挥长板的优势、避开短板的不足,但底板的坚固是前提。一个单位“长短板”同时存在的情形比较多,工作中除了扬长补短外,还需时刻把“底板”扎实固牢。
回到一开始的问题:
存储器最大的价值:输入设备在输入数据时不是把数据直接交给 CPU 的,而是把数据先从外设交给存储器,再将存储器当中的数据再被 CPU 读取,CPU 计算完后再将数据写回存储器,再由内存刷新回输出设备。因此在整个计算机体系当中,内存是属于数据层面上的核心地位。
数据角度:外设不和 CPU 直接交互,而是和内存交互。(CPU 也是如此)
内存在我们看来,就是体系结构的一个大的缓存,适配外设和 CPU 速度不均的问题的。
成本角度:寄存器 >>内存 >>磁盘 (外设)
内存的意义:使用较低的钱的成本,能够获得较高的性能。
因为内存的存在,我们现在可以用不多的钱买上一台性价比不错的电脑,这就是内存的最大价值。" 我们自己写的软件,编译好之后,要运行,必须先加载到内存。"
为什么?因为这是体系结构决定的,如果不加载到内存 CPU 没办法执行的。
所以我们自己编好的软件加载到内存,这是体系结构决定的,
当你在启动时,还没有执行程序时,你的数据其实已经预加载到内存当中了。
1.3 运算器和控制器
我们先来看 运算器,运算器主要承担了运算的工作。
计算机的计算种类无非两种:① 算数计算 ② 逻辑计算
加减乘除取模这一些就算算数计算,逻辑与逻辑或逻辑反这些就是逻辑计算。
在人的计算世界中,计算其实就是算账、算数。
人会推理一些东西,这实际上就是逻辑。
所以计算机的计算和人的计算,无外乎就是这两种。
看看控制器:
虽然我们一直在说外设不和 CPU 在数据上交互,但并不代表它们之间没有交互。
比如输入设备把数据输入完后,中央处理器如何知道数据已经读取完了?
数据也不是一定 100% 能装载进来,如果没有装载进来呢?CPU 是不是就要和外设交互一下?所以中央处理器还需要有协调数据流向,什么时候流,流多少的问题。
这,实际上就是由 控制器 来控制外设的。几乎所有的硬件,只能被动地完成某种功能,不能主动地完成,一般都是要配合软件完成的。
总结:所有的外设在数据层面上不和 CPU 接轨,直接和内存处理。CPU 读数据直接从内存中读数据,处理完数据后的结果再刷新到内存。对我们来说,实际上计算机为了提升整体性能,也加了许多其他的优化策略,比如寄存器和缓存等。
2. 操作系统(OS)
我们在《零基础Linux_4(shell命令和权限)》里讲到了操作系统的初识:
百度百科:操作系统(英语:Operating System,缩写:OS)是一组主管并控制计算机操作、运用和运行硬件、软件资源和提供公共服务来组织用户交互的相互关联的系统软件程序。根据运行的环境,操作系统可以分为桌面操作系统,手机操作系统,服务器操作系统,嵌入式操作系统等。
操作系统是人与计算机之间的接口,也是计算机的灵魂。
得到了软件操作硬件的结论。
操作系统包括:
内核(进程管理,内存管理,文件管理,驱动管理)
其他程序(例如函数库,shell 程序等)
定位:在整个计算机软硬件架构中,操作系统的定位是一款纯正的 "搞管理" 的软件。管理的目的:① 对上:提供一个良好稳定的运行环境 ② 对下:管理好软硬件资源。
而我们此篇要重点谈论的就是 "管理",什么叫做管理?如何理解?
2.1 了解管理
在整个计算机软硬件架构中,操作系统的定位是:一款纯正的“搞管理”的软件。
一个人在做一件事的时候应该是先决策再执行的。
如今天我打算晚上跟朋友一起开黑,这就是决策。
晚上吃完饭你很喊朋友上号,然后一起开黑去了,这就是执行。
这就是 决策过程 和 执行过程 ,虽然决策和执行在我们人身上似乎是混合体的,我决策我执行。但是计算机中,为了能够做更好的功能解耦,决策和执行实际上是可以分离开来的。
"有人负责决策,也有人负责执行。"
举个学校的例子,校长做决策,辅导员去执行。校长连我的面都不见,如何管理我呢?
管理你要和你打交道,要和你见面吗?他是怎么做到的?
管理:不是对管理对象进行直接管理,而是只要拿到管理对象的所有的相关数据,我们对数据的管理,就可以体现对人的管理。
比如:"在公司中,你之前负责的模块经你手自己处理了大半年,模块的效率比之前翻了十倍一百倍,领导就知道你一定是做出成绩来了,如果你在公司里什么都没写,什么有效数据都没有产出,领导就认为你什么都没干,所有管理最终都要落实到对数据做管理。"
这是我又有一个问题了,如果你说它连我的面就不见,他又是如何拿到我的数据的呢?
又是如何对我做出决策的呢?
2.2 先描述再组织
对管理的进一步理解:人认识世界的方式 —— 人是通过属性认识世界的。
一切事物都可以通过抽取对象的属性,来达到描述对象的目的。
这就是C++里的一切皆对象。
继续刚才的例子,如果你自己就个是个当过程序员的校长,你想管理学校的同学,
那么就可以抽取所有同学的属性,描述对应的同学,我们知道 Linux 内核代码是由C语言写的。那么C语言中有没有一种数据类型,能够达到描述某种对象的功能?它就是struct
struct student
{
//学生的各种信息
struct student* next;
struct student* prev;
};如此一来,对学生的管理,就变成了对链表的增删查改。然后我们在有头插、尾插的各种方法。现在如过我想找到考试成绩最好的学生,只需要遍历整个链表,找到那个学生的结点即可。再比如,学校的挂科率太高了,要整治一下这个问题,我们就执行一个排序算法,以绩点排序。按升序排列,找到若干名排在前面的绩点低的学生,再通过自带的信息联系到辅导员,进行管理。
管理的本质:对数据做管理 -> 对某种数据结构的管理,管理的核心理念 —" 先描述,再组织。"
- 描述:用 struct 结构体
- 组织:用链表或其他高效的数据结构
2.3 操作系统的管理
- 操作系统的定义:操作系统是一个进行软硬件资源管理的软件。
由于CPU不和外设直接打交道,只和存储器直接打交道,所以存储器注定会很忙。比如,要准备读取哪个外设的数据来让CPU执行,又有哪部分代码需要CPU来执行,CPU处理后的结果在什么时候写到外设,等等。
由于任务这么多,又这么繁杂,还需要合理的安排,而存储器就是用来存放数据的,这里的数据范围很广。所以就需要一个专业的人来管理这些数据,进行合理的安排。而这个人就是操作系统,操作系统在整个体系中就是管理者。
- 操作系统存在的意义:通过合理管理软硬件资源,为用户提供良好的执行环境。
操作系统这个管理者管理的内容主要有四大块,进程管理,文件管理,内存管理,驱动管理。
而它管理这些软硬件资源是通过管理数据来实现的,硬件的数据又是通过驱动程序这个执行者来获取到的。拿硬件管理来举例:

操作系统将使用结构体对象将这些硬件管理起来,结构体中放的就是硬件的各种属性信息。
为了方便管理这些数据,将结构体对象使用链表管理起来。
软件资源也是类似的,只是结构体名为tast_struct,具体内容在后面的进程中本喵会详细讲解。
结论: 系统在管理资源的时候,都会先描述,再组织。
对于Linux操作系统,由于是用C语言写的,所以描述就是用struct结构体来记录资源的属性,然后用链表或者其他高效的数据结构组织起来,方便管理,一般而言,都是用的链表结构。
用户是位于操作系统之上的,用户的所有需求都是操作系统来完成的,如果用户直接与操作系统进行交互,对于操作系统来说不安全,如果用户在操作系统中乱操作,会导致系统崩溃。对于用户来说,需要对操作系统非常了解才能够直接操作它,成本会非常高,而且也不便于操作。于是操作系统便提供了一些调用接口来供用户使用,这些接口和我们平时调用的函数是一个意思,只是此时是系统接口,操作的是系统。
- 系统调用:系统提供的接口称为系统调用接口,俗称系统调用。
计算机的软硬件体系结构示意图:

用户可以通过shell指令来进行系统调用,比如ls指令,在屏幕上打印出当前目录下的文件。
还有一些库函数,比如printf,cout,sanf,cin等等,都是通过系统调用来与硬件进行交互。
系统调用不仅仅只有硬件,还包括许多软件,比如getpid()就是一个系统结构,它是用来查看系统中进程的pid的,也就是用来查看内存中程序的标识的。这些都是操作系统给我们提供的服务。
操作系统为什么要给我们提供服务呢?
因为计算机和操作系统设计出来就是为了给人提供服务的。
printf/cout 向显示器打印,显示器是硬件,所谓的打印,本质就是将数据写到硬件。
你自己的 C 程序,有资格向硬件写入吗?你是没有资格这么做的。
如何提供服务?
操作系统不相信任何人的,不会直接暴露自己的任何数据结构,代码逻辑,其他数据相关的细节。想做系统是通过系统调用的方式,对外提供接口服务的。
Linux 操作系统是用C语言写的,这里所谓的 "接口",本质就是C函数。
我们学习系统编程,本质上就是学习这里的系统接口。
系统调用和库函数:
在开发角度,操作系统对外会表现为一个整体,但是会暴露自己的部分接口,供上层开发使用,这部分由操作系统提供的接口,叫做系统调用。
系统调用在使用上,功能比较基础,对用户的要求相对也比较高,所以,有心的开发者可以对部分系统调用进行适度封装,从而形成库,有了库,就很有利于更上层用户或者开发者进行二次开发。
3. 进程初识和基本操作
进程是一个运行起来的程序。
这句话在很多教科书上出现,但是这说了跟没说一样,什么是运行起来的程序呢,
跑或没跑?跑起来的程序,和没跑起来的程序?我们不放首先来思考一个问题:程序是文件吗?
程序是文件,文件在磁盘。
本篇一开始讲的冯诺依曼体系,磁盘就是外设,和内存与 CPU 打交道,它们之间有数据交互。你的程序最后要被 CPU 运行,所以要运行起来必须先从磁盘外设加载到内存中。
因此,当可执行文件被加载到内存中时,该程序就成为了一个进程。
3.1 进程的概念
操作系统中可能存在多个进程吗?
答案是操作系统里面可能同时存在大量的进程。
既然如此,那操作系统要不要将所以后的进程管理起来呢?
当然要,不要不就乱套了?当前想调用哪个进程,想让哪个进程占用 CPU 资源,
想执行哪个资源,数据一大你不管怎么行?所以我们刚才再次讲解了操作系统管理的概念:
被管理对象的管理本质上是对数据的管理。那么 对进程的管理,本质上就是对进程数据的管理。所以还是那句话 —— 我们需要 先描述再组织。
所以,当一个程序加载到内存时,操作系统做的不仅仅只是把代码和数据加入到内存,
还要管理进程,创建对应的数据结构。我们讲的是 Linux 操作系统,
Linux 操作系统的内核是 C 语言写的,所以我们管理进程,就要先描述再组织,
那描述一个事物我们当然是要用struct
// Process Ctrl Block
struct task_struct
{
进程的所有属性数据
};在操作系统中,我们把描述进程的结构体称为 PCB (Process Ctrl Block) 。
task_struct:PCB的一种
在Linux中描述进程的结构体叫做task_struct。 task_struct是Linux内核的一种数据结构,
它会被装载到RAM(内存)里并且包含着进程的信息
task_ struct内容分类(这里先过一遍):
标示符: 描述本进程的唯一标示符,用来区别其他进程。
状态: 任务状态,退出代码,退出信号等。
优先级: 相对于其他进程的优先级。
程序计数器: 程序中即将被执行的下一条指令的地址。
内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
上下文数据: 进程执行时处理器的寄存器中的数据[休学例子,要加图CPU,寄存器]。
I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
其他信息。
在很多教材中,会把 PCB 称为 进程控制块。
为什么每个进程都要有PCB呢 (task_struct)?
因为操作系统要管理我们的进程,想要管理就必须要 "先描述再组织" 。
为什么我们的 task_struct 每个进程都要有呢?
因为这是为了管理进程而描述进程所设计的结构体类型,将来当有一个进程加载到内存时,
操作系统在内核中一定要为该进程创建 task_struct 结构体变量,
并且要将该变量链入到全局的链表当中。要删掉一个进程,实际上就是遍历所有的链表结点,把对应进程的 PCB和代码都释放掉,这就叫对链表做管理。
最终你会发现,操作系统对进程的管理,最终变成了对链表的增删查改。
什么是进程?目前为止我们可以总结成:进程 = 可执行程序 + 该进程对应的内核数据结构
(以前一瞬间输出的hello world是一个进程,还有下面死循环输出的是一个一直在运行的进程)
3.2 查看进程
我们先创建一个linux_7目录,然后在里面创建 mytest.c 文件(在这之前先写一个Makefile),然后vim写上一个死循环,每隔1秒就打印一句话:

生成 mytest 可执行文件后,使用 ldd 和 file 去查看:
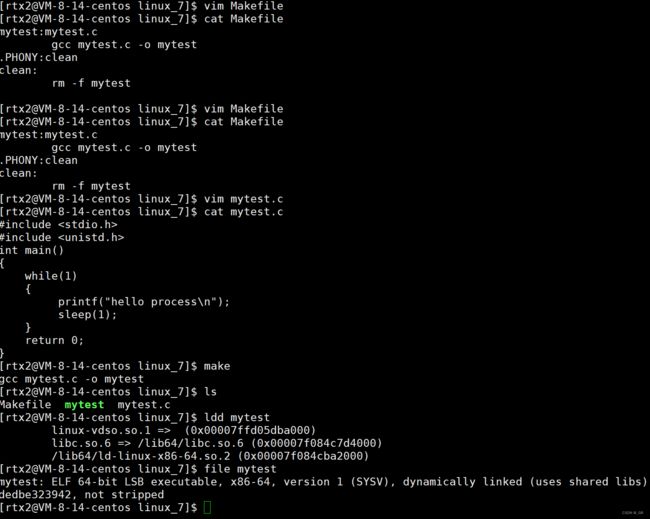 看到executable 是可执行文件,它就是在磁盘上放着。
看到executable 是可执行文件,它就是在磁盘上放着。
而我们使用的是云服务器,所以不是在你自己电脑的磁盘上,而是在云服务器的磁盘上放着。
这里把鼠标移到有绿点的GR_C将SSH窗口复制一个,然后垂直分割,一个用来查看进程的运行如上图上边框,一个用来查看进程信息:

接下来我们在右边 ./mytest 去运行mytest,此时这个程序就变成了一个进程:

查看进程,法一:(有很多方法,但最常用的是这种)
- 指令:ps ajx | grep 进程名(这里先记住这样用就行)
- 功能:显示进程的简要信息,只有这条指令的话会显示很多进程的信息
- 组合:使用管道(|)组合其他指令来查看指定进程的信息
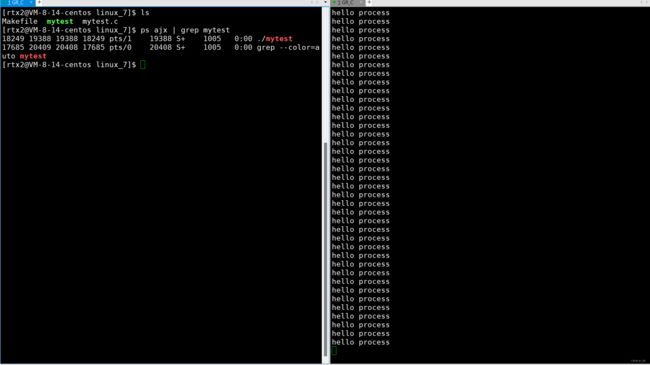
有俩个进程信息被显示出来,一个是mytest我们要查看的,另一个是grep指令,因为要用到grep和管道配合过滤出我们要的进程,所以grep指令也是在运行的,也是一个进程。
- 指令:ps ajx | head -1 && ps ajx | grep 进程名
- 功能:将多个指令组合在一起,显示出进程的信息
- 解释:
- ps ajx 是查看所有进程
- head -1 是显示进程信息显示的第一行,也就是抬头
- grep 进程名 是表示过滤掉其他,只显示这个进程
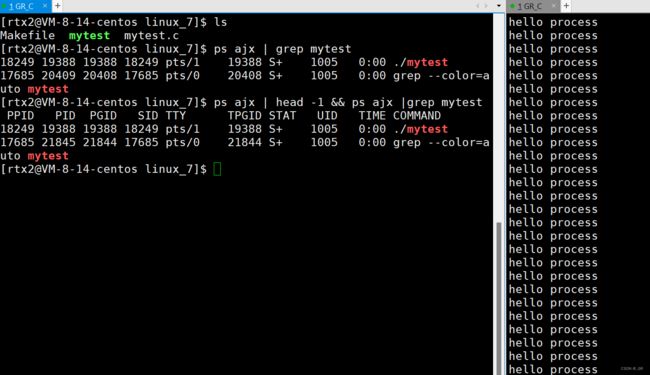
注意到这个./mytest的PID是19388
还有一种方法来查看进程,这个只需要了解即可。
查看进程,法二:
- 指令:ls /proc
- 功能:查看系统上当前运行的进程,proc是专门用来放进程的文件。

我们使用第一种方法查看进程信息时,有一个PID值,这个值是一个进程的唯一标识符,可以看到,在proc中同样有PID值为19388的进程。
注意: PID是一个进程的唯一标识符,是用来识别一个进程的。
3.3 结束进程
结束进程,法一:
- 在键盘上按Ctrl C就结束了一个正在运行的进程(这里在右边Ctrl C)

此时正在运行的进程就结束掉了,只有在前台运行的进程才能使用这种方法结束。
结束进程,法二:
- 指令 kill -9 进程PID
- 功能:杀掉PID值对应的进程
我们再运行右边的程序,这里进程PID变成了23963

这种方法不仅可停止前台运行的进程,而且使用Ctrl + C不能停止的后台进程也可以停止。
3.4 获取进程标识符
- 系统调用接口:getpid()
- 功能:获得当前进程的PID
- 系统调用接口:getppid()
- 功能:获取父进程的PID
想要查看进程 pid和ppid,一定是这个进程得运行起来,先查man手册一下,man getpid:

在右边,vim mytest.c,在代码中使用系统调用,来获得当前进程的PID和父进程的PID。
(PID值其实就是一个整型数据,使用%d打印即可)

:wq保存退出,make 然后./mytest:

将运行的进程结束掉,然后再运行:
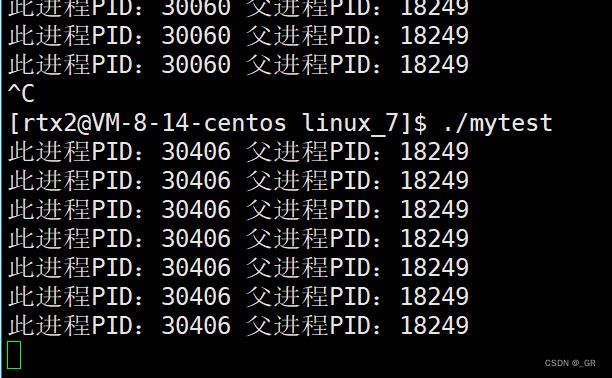
将运行的进程结束掉,然后再运行,发现此进程的PID值变了,但是父进程的PID值没有变。
当一个进程结束以后,操作系统就会将它的PCB杀掉,此时内存中就没有这个进程的信息了,原本PID标识的就是另一个运行的进程了。当这个进程再次加载到内存中运行后,就会操作系统会创建新的PCB来维护它,所以它的PID值就变了。
这里的父进程相当于我们以前讲的王婆,每次登录都有一个不一样的王婆(bash),复习:

此时如果你在左边把右边的父进程 kill -9 18249 删掉,那么右边的输入指令和回车等都会乱掉(或者直接退出登录):

左边的不会乱是因为(每次登录都有一个不一样的bash)父进程PID不一样。
(上面就说明bash(王婆),也是一个进程,你登录的时候系统就会给你创建一个进程)
(操作系统本身也是一个死循环,因为操作系统也是一个软件,这里有个印象就行)
3.5 fork创建子进程
- 系统调用接口:fork()
- 功能:在执行完fork以后,存在俩个进程,一个父进程一个子进程。
通过man指令来查看fork:

作用是创建一个子进程,头文件是unistd.h,返回值是pid_t,往下拉看到:
![]()
子进程创建成功,返回值有俩个:
一个是子进程的PID,这个值给父进程,还有一个值是0,这个值给子进程。子进程创建失败,返回-1给父进程。
和我们之前调用函数完全不同,之前任何函数的返回值只能是一个,fork的返回值居然有俩个。
创建一个test_fork.c文件写点代码,看看会发生什么:

运行结果:

运行了两次?
现在我们再来验证一下返回值的问题,我们把返回值给打印出来:
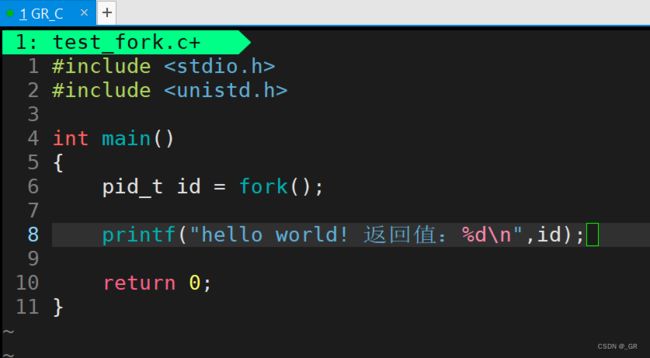

- 同一个 id 值,使用打印,没有修改,却打印出来了不同的值?为什么?这合理吗?
- fork 如何做到会有不同的返回值?
(这部分知识我们将在进程地址空间中讲解)
怎么验证他创建的是子进程而不是父进程?刚才前面学的:


所以,原本是一个父进程,fork之后先打印的是父进程的pid和ppid,返回值是子进程的pid4560,给新创建的子进程的返回值是0。
C语言中, if 和 else 可以同时执行吗?
C语言中,有没有可能两个以上的死循环同时运行?


我们发现,这两块代码是可以同时执行的。
原因:fork 之后,父进程和子进程会共享代码,一般都会执行后续的代码。这也是为什么刚才的 printf 会打印两次的原因。fork 之后,父进程和子进程返回值不同,所以可以通过不同的返回值去判断,让父子执行不同的代码块。
父进程返回子进程的 pid,给子进程返回 0,为什么?
父进程必须有标识子进程的方案,fork 之后给父进程返回子进程的 pidpid。子进程最重要的是要知道自己被创建成功了,因为子进程找父进程的成本非常低。
如果想获取,直接 getppid() 即可。
为什么 fork 会返回两次?
fork 函数,OS syscall call,fork 之后,OS 做了什么?是不是系统多了一个进程?
task_struct + 进程代码和数据
task_struct + 子进程的代码和数据
子进程的 task_struct 对象内部的数据基本是从父进程继承下来的。子进程执行代码,计算数据的,子进程的代码从哪里来呢?
和父进程执行同样的代码,fork 之后,父子进程代码共享,而数据要各自独立!父进程代码共享,让不同的返回值,让不同的进程执行不同的代码。
我们在系统调用后,fork 本质是系统多了一个子进程,也就多了一个 task_struct,
该进程控制块会几乎继承父进程,代码父子进程共享,但数据是各自私有的。
fork 的时候是要执行很多创建代码的逻辑的,最终 fork 会有两个返回值,
一定是它曾经返回了2次,因此一定会调用,return pid。
调用一个函数,当这个函数准备 return 的之后,那么这个函数的核心功能完成了吗?
当我们函数准备执行 return 的时候,函数的核心功能已经完成:
① 子进程已经被创建了
② 将子进程放入运行队列最后,return 是代码吗?是的!所以当我们走到 return 时父进程有了,
子进程也已经在运行队列了,fork 后代码共享,
父子进程当然会执行后续被共享的 return 代码。
因此,父进程执行一次 return,子进程执行一次 return,最后就是两个返回值了。
"以后凡是说进程,必须先想到进程的 task_struct "
后面,系统的讲进程创建里会讲到fork(第9篇),还有进程退出,等待,替换(第10篇)。
本篇完。
下一篇:零基础Linux_8(进程)操作系统进程状态和Linux进程状态+进程优先级。