代码随想录刷题-链表-移除链表元素
文章目录
-
- 链表理论基础
-
- 单链表
- 双链表
- 循环链表
- 其余知识点
- 移除链表元素
-
- 习题
- 我的解法
- 虚拟头结点解法
链表理论基础
单链表
单链表是一种常见的线性数据结构,它由一系列节点组成,每个节点包含了一个数据元素和一个指向下一个节点的指针。单链表的第一个节点称为头节点,最后一个节点称为尾节点,尾节点的指针指向空地址。
单链表的优点是插入和删除操作比较快速,时间复杂度为O(1),而查找操作则需要遍历整个链表,时间复杂度为O(n)。
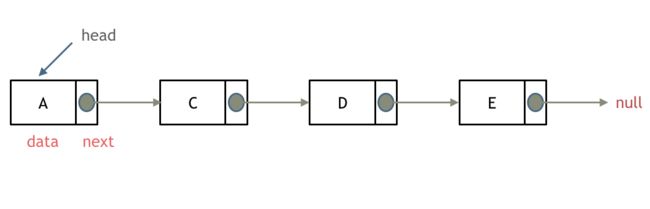
代码如下:
struct ListNode {
int val; // 节点上存储的元素
ListNode *next; // 指向下一个节点的指针
ListNode(int x) : val(x), next(NULL) {} // 节点的构造函数(C++11的初始化列表(initializer list)语法)
};
在实现单链表时,需要注意以下几点:
- 在插入和删除节点时,要注意更新链表中相邻节点的指针。
- 在使用完节点后,需要手动释放节点占用的内存,以避免内存泄漏的问题。
- 遍历链表时,需要使用循环结构,直到指针指向空地址。
双链表
双链表中每个节点包含了一个数据元素和两个指针,分别指向前一个节点和后一个节点。双链表与单链表相比,多了一个指向前一个节点的指针,可以更方便地进行双向遍历和节点的插入和删除操作。
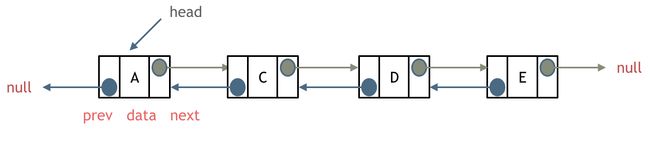
在C++中,可以用以下结构体定义一个双链表的结点:
struct ListNode {
int val; // 存储的元素值
ListNode* prev; // 指向前一个节点的指针
ListNode* next; // 指向后一个节点的指针
ListNode(int x) : val(x), prev(nullptr), next(nullptr) {} // 构造函数
};
循环链表
循环链表是一种特殊的链表,它的最后一个节点的下一个节点指向第一个节点,形成一个环状。循环链表可以分为单向循环链表和双向循环链表两种。
在单向循环链表中,每个节点只有一个指针,指向下一个节点。最后一个节点的指针指向第一个节点。
在双向循环链表中,每个节点有两个指针,一个指向前一个节点,一个指向后一个节点。第一个节点的前一个节点指向最后一个节点,最后一个节点的后一个节点指向第一个节点。
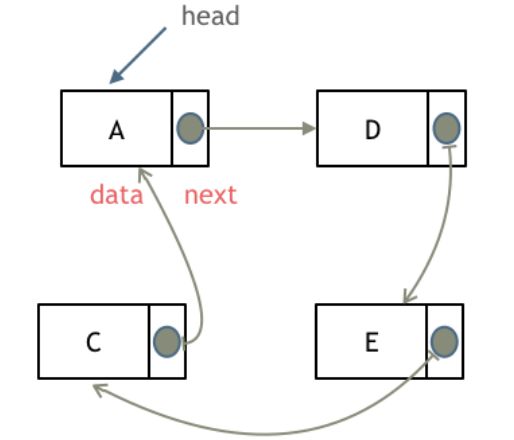
循环链表的优点是可以方便地实现循环遍历,因为可以从最后一个节点回到第一个节点。同时,循环链表可以解决链表中的“尾指针”问题,即在链表的末尾添加节点时不需要遍历整个链表查找最后一个节点。
但是,循环链表的缺点是实现起来比较复杂,需要特别处理最后一个节点的指针。同时,循环链表的节点数量比较难以控制,容易造成内存泄漏或者死循环等问题。
以下是一个单向循环链表的结构体:
struct ListNode {
int val;
struct ListNode *next;
};
struct CircularLinkedList {
ListNode *head;
ListNode *tail;
int size;
};
其中,ListNode代表链表的一个节点,包含一个整数val和一个指向下一个节点的指针next。CircularLinkedList代表循环链表,包含一个指向头节点的指针head、一个指向尾节点的指针tail和链表中节点的数量size。
其余知识点
删除元素如下所示:
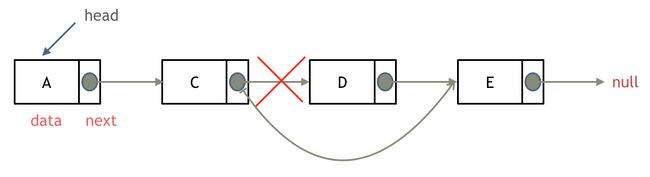
添加节点如下所示:
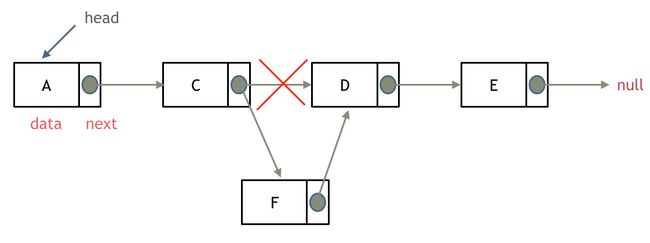
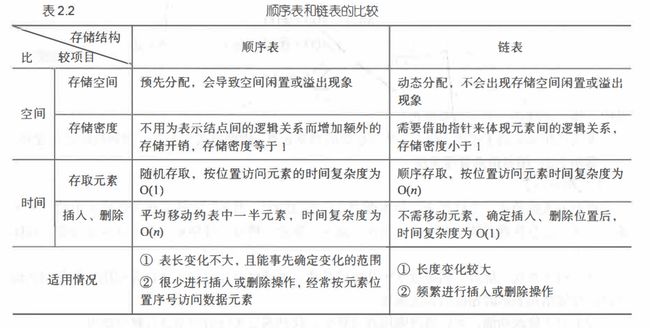
与顺序表对比如下:
移除链表元素
本节对应代码随想录中:代码随想录,讲解视频:LeetCode:203.移除链表元素_哔哩哔哩_bilibili
习题
题目链接:203.移除链表元素- 力扣(LeetCode)
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回新的头节点。
示例 1: 输入:head = [1,2,6,3,4,5,6], val = 6 输出:[1,2,3,4,5]
示例 2: 输入:head = [], val = 1 输出:[]
示例 3: 输入:head = [7,7,7,7], val = 7 输出:[]
我的解法
思路:循环判断临时指针的下一个节点值是否等于 val,等于的话就让临时指针的下一个节点指向为临时指针的下下个节点,否则就让临时指针指向下一个节点(相当于遍历)。但是这种方法是判断的下一个节点,因此要单独判断头结点的情况,同时注意要使用 while 而不是 if,因为用 if 有可能删了等于 val 的头结点,下一个节点依然等于 val。
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
// 处理特殊情况
if (head == nullptr){
return nullptr;
}
// 判断首个元素等于val的情况
while(head->val == val){
head = head->next;
// 如果head已经是nullptr说明已经没元素了,直接返回nullptr
if(head == nullptr){
return nullptr;
}
}
ListNode* temp = head;
// 判断的是temp的下一个元素,因此上面要加上判断首个元素的情况
while (temp->next != nullptr) {
// 如果下一个元素值为val,则让temp的下一个元素等于下下个元素
if(temp->next->val==val){
temp->next=temp->next->next;
}else{
// 否则temp等于下一个元素(相当于遍历单链表)
temp = temp->next;
}
}
return head;
}
};
- 时间复杂度:O(n)。这段代码中使用了一个while循环来遍历单链表,每次循环中都会判断当前节点的下一个节点是否需要删除,循环的次数是单链表的长度n,因此时间复杂度是O(n)。
- 空间复杂度:O(1)。这段代码中只使用了常量级别的额外空间,因此空间复杂度是O(1)。
需要注意的事项:
- 注意在 C++中删除节点后要用
delete手动删除这个节点的内存空间
虚拟头结点解法
上面我用的解法,由于头结点和其余节点情况不一致(头节点前面没有元素,用 next 的方式无法判断头结点),所以需要单独判断头结点。而我们可以在头结点前面加上一个虚拟节点,指向头节点,这样虚拟节点的 next 就指向了头节点,从而实现头结点和其余节点处理逻辑达到一致。
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
ListNode* dummyHead = new ListNode(0); // 设置一个虚拟头结点
dummyHead->next = head; // 将虚拟头结点指向head,这样方面后面做删除操作
ListNode* cur = dummyHead; // 临时指针
while (cur->next != NULL) {
if(cur->next->val == val) {
ListNode* tmp = cur->next;
cur->next = cur->next->next;
delete tmp; // 别忘了删除内存
} else {
cur = cur->next;
}
}
head = dummyHead->next; // 返回的是虚拟头节点的下一个节点(原始的头节点)
delete dummyHead;
return head;
}
};
- 时间复杂度:O(n)。这段代码中使用了一个while循环来遍历单链表,每次循环中都会判断当前节点的下一个节点是否需要删除,循环的次数是单链表的长度n,因此时间复杂度是O(n)。
- 空间复杂度:O(1)。这段代码中只使用了常量级别的额外空间,因此空间复杂度是O(1)。