Apriori算法-关联规则算法
Apriori 算法的示意图:
交易ID |
商品ID列表 |
T100 |
I1,I2,I5 |
T200 |
I2,I4 |
T300 |
I2,I3 |
T400 |
I1,I2,I4 |
T500 |
I1,I3 |
T600 |
I2,I3 |
T700 |
I1,I3 |
T800 |
I1,I2,I3,I5 |
T900 |
I1,I2,I3 |
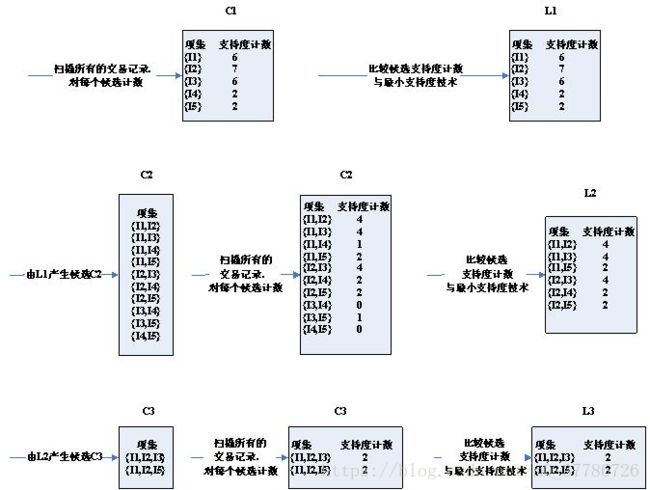
Apriori算法较为简单:只需要明白两个概念就好:
1)支持度:
每次交易的所有商品为一个集合设位Y={.....},X为二元集合,计算X的支持度,则需遍历每个集合Y,查找Y中是否含有与X相同的子集,如果有,则其支持度计数加1,直到得到其最后的支持度F(Xn);在所有X集合的基础上建立集合Z,Z为三元集合,含有3个商品元素,同样遍历所有商品记录,计算Z所对应的支持度、
2)置信度:我们需要为候选集的选择建立个条件,即为它的阈值,支持度阈值或置信度的阈值,可由支持度计算得出,计算出某商品会在某个商品子集的概率分布。
代码实现如下:
"""
Description : Simple Python implementation of the Apriori Algorithm
使用方法;
$python apriori.py -f DATASET.csv -s minSupport -c minConfidence
说明:-f 对应的是数据文件 -s 对应的是最小支持度 -c 对应的是最小置信度
$python apriori.py -f DATASET.csv -s 0.15 -c 0.6
"""
import sys
from itertools import chain, combinations
from collections import defaultdict
from optparse import OptionParser
def subsets(arr):
""" Returns non empty subsets of arr"""
return chain(*[combinations(arr, i + 1) for i, a in enumerate(arr)])
def returnItemsWithMinSupport(itemSet, transactionList, minSupport, freqSet):
"""calculates the support for items in the itemSet and returns a subset
of the itemSet each of whose elements satisfies the minimum support"""
_itemSet = set()
localSet = defaultdict(int)
for item in itemSet:
for transaction in transactionList:
if item.issubset(transaction):
freqSet[item] += 1
localSet[item] += 1
for item, count in localSet.items():
support = float(count)/len(transactionList)
if support >= minSupport:
_itemSet.add(item)
return _itemSet
def joinSet(itemSet, length):
"""Join a set with itself and returns the n-element itemsets"""
return set([i.union(j) for i in itemSet for j in itemSet if len(i.union(j)) == length])
def getItemSetTransactionList(data_iterator):
transactionList = list()
itemSet = set()
for record in data_iterator:
transaction = frozenset(record)
transactionList.append(transaction)
for item in transaction:
itemSet.add(frozenset([item])) # Generate 1-itemSets
return itemSet, transactionList
def runApriori(data_iter, minSupport, minConfidence):
"""
run the apriori algorithm. data_iter is a record iterator
Return both:
- items (tuple, support)
- rules ((pretuple, posttuple), confidence)
"""
itemSet, transactionList = getItemSetTransactionList(data_iter)
freqSet = defaultdict(int)
largeSet = dict()
# Global dictionary which stores (key=n-itemSets,value=support)
# which satisfy minSupport
assocRules = dict()
# Dictionary which stores Association Rules
oneCSet = returnItemsWithMinSupport(itemSet,
transactionList,
minSupport,
freqSet)
currentLSet = oneCSet
k = 2
while(currentLSet != set([])):
largeSet[k-1] = currentLSet
currentLSet = joinSet(currentLSet, k)
currentCSet = returnItemsWithMinSupport(currentLSet,
transactionList,
minSupport,
freqSet)
currentLSet = currentCSet
k = k + 1
def getSupport(item):
"""local function which Returns the support of an item"""
return float(freqSet[item])/len(transactionList)
toRetItems = []
for key, value in largeSet.items():
toRetItems.extend([(tuple(item), getSupport(item))
for item in value])
toRetRules = []
for key, value in largeSet.items()[1:]:
for item in value:
_subsets = map(frozenset, [x for x in subsets(item)])
for element in _subsets:
remain = item.difference(element)
if len(remain) > 0:
confidence = getSupport(item)/getSupport(element)
if confidence >= minConfidence:
toRetRules.append(((tuple(element), tuple(remain)),
confidence))
return toRetItems, toRetRules
def printResults(items, rules):
"""prints the generated itemsets sorted by support and the confidence rules sorted by confidence"""
for item, support in sorted(items, key=lambda (item, support): support):
print "item: %s , %.3f" % (str(item), support)
print "\n------------------------ RULES:"
for rule, confidence in sorted(rules, key=lambda (rule, confidence): confidence):
pre, post = rule
print "Rule: %s ==> %s , %.3f" % (str(pre), str(post), confidence)
def dataFromFile(fname):
"""Function which reads from the file and yields a generator"""
file_iter = open(fname, 'rU')
for line in file_iter:
line = line.strip().rstrip(',') # Remove trailing comma
record = frozenset(line.split(','))
yield record
if __name__ == "__main__":
optparser = OptionParser()
optparser.add_option('-f', '--inputFile',
dest='input',
help='filename containing csv',
default=None)
optparser.add_option('-s', '--minSupport',
dest='minS',
help='minimum support value',
default=0.15,
type='float')
optparser.add_option('-c', '--minConfidence',
dest='minC',
help='minimum confidence value',
default=0.6,
type='float')
(options, args) = optparser.parse_args()
inFile = None
if options.input is None:
inFile = sys.stdin
elif options.input is not None:
inFile = dataFromFile(options.input)
else:
print 'No dataset filename specified, system with exit\n'
sys.exit('System will exit')
minSupport = options.minS
minConfidence = options.minC
items, rules = runApriori(inFile, minSupport, minConfidence)
printResults(items, rules)
参考文章:
https://blog.csdn.net/androidlushangderen/article/details/43059211
https://github.com/asaini/Apriori/edit/master